

記住我
Spiking neural networks (SNNs) are considered the third generation of artificial neural networks (ANNs) (Maass, 1997). The biologically plausible network architectures, learning principles, and neuronal or synaptic types of SNNs make them more complex and powerful than ANNs (Hassabis et al., 2017). It has been reported that even a single cortical neuron with dendritic branches needs at least a 5-to-8-layer deep neural network for finer simulations (Beniaguev et al., 2021), whereby non-differential spikes and multiply-disperse synapses make SNNs powerful on tools for spatially-temporal information processing. In the field of spatially-temporal information processing, there has been much research progress significant amounts of research into SNNs for auditory signal recognition (Shrestha and Orchard, 2018; Sun et al., 2022) and visual pattern recognition (Wu et al., 2021; Zhang M. et al., 2021).
This paper highlights two fundamental elements of SNNs and the main differences between SNNs and ANNs: specialized network design and learning principles. The SNNs encode spatial information using fire rate and temporal information using spike timing, providing hints and inspiration that SNNs can integrate into visual and audio sensory data.
For the network architecture, specific cognitive topologies developed via evolution are highly sparse and but efficient in SNNs (Luo, 2021), whereas equivalent ANNs are densely recurrent. Many researchers attempt have tried to understand the biological nature of efficient multi-sensory integration by focusing on the visual and auditory pathways in biological brains (Rideaux et al., 2021). These structures are adapted for some specific cognitive functions, e.g., efficient actions. For example, an impressive sparse network filtered from the C. Elegans connectome can outperform other dense networks during reinforcement learning of the Swimmer task. Some biological discoveries can further promote the research development of structure-based artificial operators, including but not limited to lateral neural interaction (Cheng et al., 2020), the lottery hypothesis (Frankle and Carbin, 2018), and meta structure of network motif (Hu et al., 2022; Jia et al., 2022). ANNs using these structure operators can then be applied in different spatial or temporal information processing tasks, such as image recognition (Frankle et al., 2019; Chen et al., 2020), auditory recognition, and heterogeneous graph recognition (Hu et al., 2022). Furthermore, when only focusing on the learning of weight, the weight agnostic neural network (Gaier and Ha, 2019; Aladago and Torresani, 2021) is a representative of the methods that only train the connections instead of weights.
For the learning principles, SNNs are more tuned affected by learning principles from biologically plausible plasticity principles, such as spike-timing dependent plasticity (STDP) (Zhang et al., 2018a), short-term plasticity (STP) (Zhang et al., 2018b), and reward-based plasticity (Abraham and Bear, 1996), instead of by the pure multi-step backpropagation (BP) (Rumelhart et al., 1986) of errors in ANNs. The neurons in SNNs will be activated once the membrane potentials reach their thresholds, which makes them energy efficient. SNNs have been successfully applied on to visual pattern recognition (Diehl and Cook, 2015; Zeng et al., 2017; Zhang et al., 2018a,b, 2021a,b), auditory signal recognition (Jia et al., 2021; Wang et al., 2023), probabilistic inference (Soltani and Wang, 2010), and reinforcement learning (Rueckert et al., 2016; Zhang D. et al., 2021).
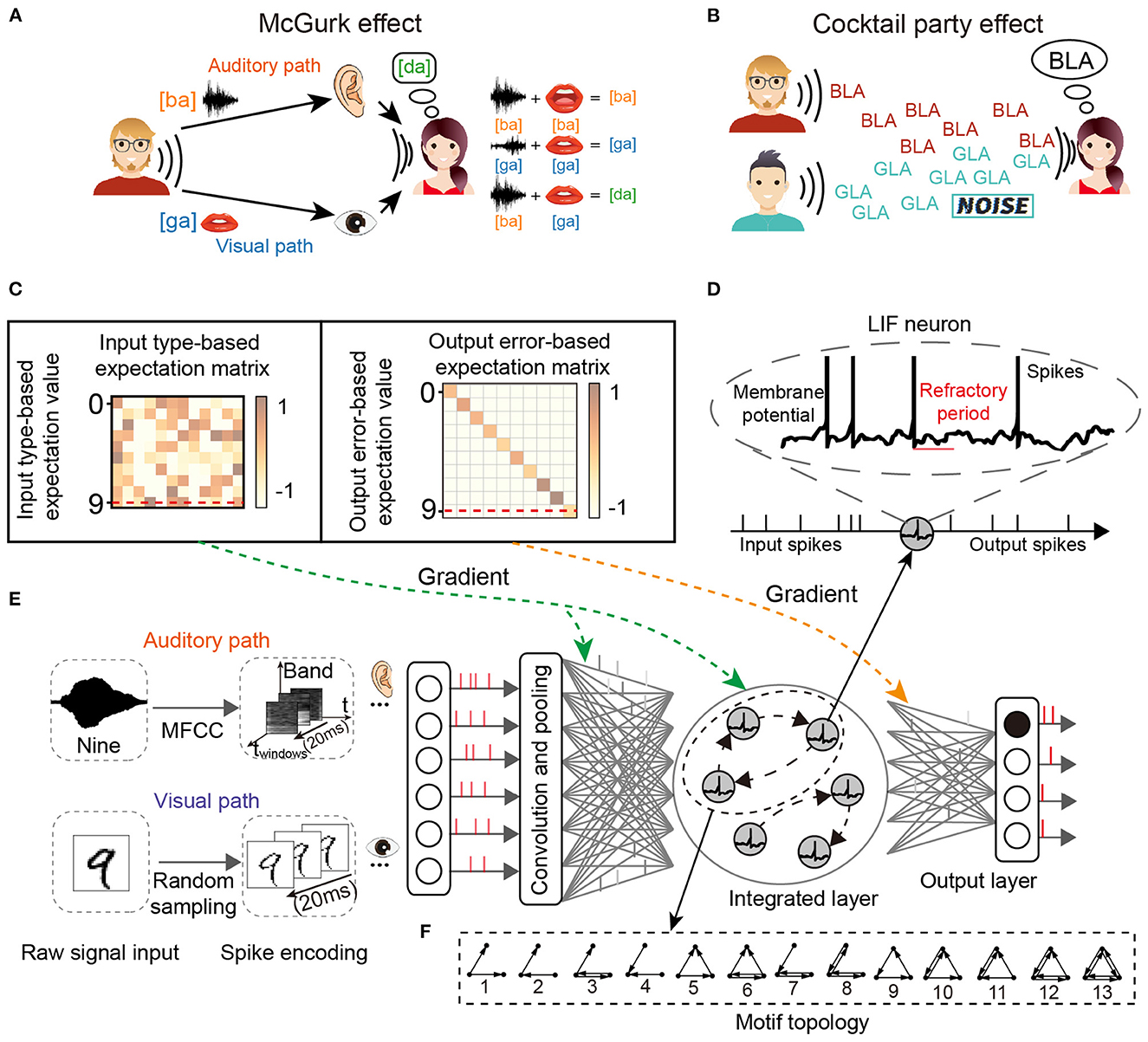
For the two classic cognitive phenomena, the cocktail party effect describes the phenomenon that in a high-noise environment (e.g., noise from the environment or other speakers), the listener learns to filter out the background noise (including music noise and sounds from other speakers) and concentrate on only the target speaker, as shown in Figure 1A. The McGurk effect introduces the concept that the voice may be misclassified when the auditory stimulus conflicts with visual cues. A classic example of the McGurk effect describes how the new concept [da] can be generated by the integration of specific auditory input [ba] and visual cues [ga], as shown in Figure 1B.
Figure 1. The network structure for multi-sensory integration and two cognitive phenomena. (A) McGurk effect. New concepts arise when the receiver receives different audio-visual input information. (B) Cocktail party effect. When the receiver's brain focuses on one speaker, it filters out the sounds and noise from others. (C) Input and output transformation matrix of reward learning. (D) The spiking neuron has a variable membrane potential. (E) The M-SNN network for single-sensory or multi-sensory integration tasks. (F) The example of 3-node Motifs.
This work focuses on the key characteristics of SNNs in information integration, categorization, and cognitive phenomenon simulation. We analyzed Motifs (Milo et al., 2002) in SNNs to reveal the essential functions of key meta-circuits in SNNs and biological networks and then used Motif structures to build loop modules in SNNs. Furthermore, a Motif-topology improved SNN (M-SNN) is proposed for simulating cocktail party effects and McGurk effects. To the best of our knowledge, we are the first to solve the problem using combinations of highly abstract Motif units. The following are the primary contributions of this paper:
• Networks with specific spatial or temporal types of Motifs can improve the accuracy of spatial or temporal classification tasks compared with networks without Motifs, making the multi-sensory integration easier by integrating two types of Motifs.
• We propose a method to mix different Motif structures and use them to simulate cognitive phenomena, including cocktail party effects and McGurk effects. In addition, the Motif topologies are critical, and networks with Motifs could effectively simulate these two effects (higher accuracy and better cognitive phenomenon simulation). (We specifically picked the MNIST and TIDigits datasets to simulate audio-visual inputs due to the lack of audio-visual-consistent datasets for classification testing.)
• During the network training process for various simulation experiments, the M-SNN can achieve a lower training computational cost than other SNNs without using Motif architectures. This result demonstrates that the M-SNN can achieve more human-like cognitive functions at a lower computational cost with the help of prior knowledge of multi-sensory pathways and biologically inspired reward learning methods.
The remaining parts are grouped as follows: Section 2 reviews the research about on the architecture, learning paradigms, and two classic cognitive phenomena. Section 3 describes the pattern of Motifs, the SNN model with neuronal plasticity, and learning principles. Section 4 verifies the convergence, the advantage of M-SNN in simulating cognitive phenomena, and the computational cost. Finally, a short conclusion is given in Section 5.
2. Related worksFor the architecture, the lateral interaction of neural networks, the lottery hypothesis, and the network motif circuits are novel operators in structure research. In the research on lateral interaction, most studies have taken the synapse as the basic unit, including the lateral interaction in the convolutional neural network (Cheng et al., 2020) or that in the fully connected network (Jia et al., 2021). However, these methods take synaptic connections as the basic unit and only consider learning effective structures without considering meta-structure composition.
Network motifs (Milo et al., 2002; Prill et al., 2005) use primary n-node circuit operators to represent the complex network structures. The feature of the network (e.g., visual or auditory pathways) could be reflected by the number of different Motif topologies, which is called Motif distribution. To calculate the Motif distribution, the first Motif tool is mfinder, which implements the algorithm of full enumeration (randomly picking the edges from the graph and counting the probability of n-node subgraphs). Then the FANMOD (Wernicke and Rasche, 2006) was introduced as a more efficient tool for finding reliable network motifs.
For learning paradigms, there are many methods have been proposed, such as the ANN-to-SNN conversion (i.e., directly training ANNs and then equivalently converting to SNNs; Diehl et al., 2015), proxy gradient learning (i.e., replacing the non-differential membrane potential at firing threshold by an infinite gradient value; Lee et al., 2016), and the biological-mechanism inspired algorithms [e.g., the SBP (Zhang et al., 2021a) which was inspired by the synaptic plasticity rules in the hippocampus, the BRP (Zhang et al., 2021b), which was inspired by the reward learning mechanism, and the GRAPES, that inspired by the synaptic scaling (Dellaferrera et al., 2022)]. Compared to other learning algorithms, biologically inspired algorithms are more similar to the process of how the human brain learns.
For the cocktail party effect, many effective end-to-end neural network models have been proposed (Ephrat et al., 2018; Chao et al., 2019; Hao et al., 2021; Wang et al., 2021). However, the analysis of why these networks work is very difficult since the functional structures in these black-box models are very dense without clear function diversity. As a comparison, the network motif constraint in neural networks might resolve this problem to some extent, which until now and as far as we know, however this has not yet been well-introduced.
For the McGurk effect, only a limited number of research papers have discussed the artificial simulation of it, partly caused by the simulation challenge, especially on the conflict fusion of visual and auditory inputs (McGurk and MacDonald, 1976; Hirst et al., 2018), e.g., self-organized mapping (Gustafsson et al., 2014).
3. Methods 3.1. Spiking dynamicsThe leaky integrated-and-fire (LIF) neuron model is biologically plausible and is one of the simplest models to simulate spiking dynamics. It includes non-differential membrane potential and the refractory period, as shown in Figure 1D. The LIF neuron model simulates the neuronal dynamics with the following steps.
First, the dendritic synapses of the postsynaptic LIF neuron will receive presynaptic spikes and convert them to a postsynaptic current (Isyn). Second, the postsynaptic membrane potential will be leaky or integrated, depending on its historical experience. The classic LIF neuron model is shown as the following Equation (1).
τmdVtdt=-(Vt-VL)-gEgL(Vt-VE)+IsyngL, (1)where Vt represents the dynamical variable of membrane potential with time t, dt is the minimal simulation time slot (set as 0.01ms), τm is the integrative period, gL is the leaky conductance, gE is the excitatory conductance, VL is the leaky potential, VE is the reversal potential for excitatory neuron, and Isyn is the input current received from the synapses in the previous layer. We set values of conductance (gE, gL) to be 1 in our following experiments for simplicity, as shown in Equation (3).
Third, the postsynaptic neuron will generate a spike once its membrane potential Vt reaches the firing threshold Vth. At the same time, the membrane potential V will be reset as the reset potential Vreset, shown as the following Equation (2).
if (Vt>Vth){Vt=VresetTref=T0, (2)where the refractory time Tref will be extended to a larger predefined T0 after firing.
In our experiments, the three steps for simulating the LIF neurons were integrated into the Equation (3).
CdVi,tdt=g(Vi,t-Vrest)(1-Si,t)+∑j = 1NWi,jXj,t, (3)where C is the capacitance parameter, Si,t is the firing flag of neuron i at timing t, Vi,t is the membrane potential of neuron i at timing t, Vrest is the resting potential, and Wi,j represents the synaptic weight between the neuron i and j.
3.2. Motif topologyThe n-node (n ≥ 2) meta Motifs have been proposed in past research. Here, we use the typical 3-node Motifs to analyze the networks, which have been widely used in biological and other systems (Milo et al., 2002; Shen et al., 2012; Zhang et al., 2017). Figure 1F displayed all 13 varieties of 3-node Motifs. In previous studies, network topology had been transformed into parameter embeddings in the network (Liu et al., 2018). In our SNNs, the Motifs were used by the Motif masks and then applied into the recurrent connection at the hidden layer. The typical Motif mask is a matrix padded with 1 or 0, where 1 and 0 represent the connected and non-connected pathways, respectively. We introduce the Motif circuits into the hidden layer, and the Motif mask in the r-dimension hidden layer l at time t is represented as the Mtr,l as shown in Equation (4). As shown in Figure 2, we show some examples of Motifs (Figure 2A) and their corresponding Motif masks (Figure 2B). The Motif masks are generated by binary square matrices where only one (with connection) and zero (without connections) values are designed.
Mtr,l=[f(m1,2)⋯f(m1,r)⋮⋱⋮f(mr,1)⋯f(mr,r)], (4)where f(·) is the indicator function. Once the variable in f(·) satisfies the conditions, the function value would be set as one; otherwise, zero. mi,j, (i, j = 1, ⋯r) are elements of synaptic weight Wtr,l.
Figure 2. Schematic diagram of an example for integrating Motif masks. (A) Schematic for Motifs of the M-SNN. (B) Schematic for Motif masks of the M-SNN.
The network motif distribution is calculated by counting the occurrence frequency of network motif types. We enumerate every 3-node assembly (including Motifs and other non-Motif types) and only count the 13-type 3-node connected subgraphs of Motifs with the help of FANMOD (Wernicke and Rasche, 2006). In order to integrate the Motifs learned from different visual and auditory datasets, we propose a multi-sensory integration algorithm by integrating Motif masks with different types learned from visual or auditory classification tasks. Hence, the integrated Motif connections have both visual and auditory network patterns, as shown in Figure 2. Equation (5) shows the integrated equation with visual and auditory Motif masks.
Mtr,l=Mtr,l(s)∪Mtr,l(t), (5)where Mtr,l(s) is the spatial mask that learned from the visual dataset, Mtr,l(t) is the temporal mask that learned from the auditory dataset, and Mtr,l is the integrated mask. “∪” means the OR operation for every element of the visual Motif mask and auditory Motif mask.
For forming the network motifs in SNN, the Motif mask is used to mask the lateral connections in the neural network. The lateral and sparse connections between LIF neurons are usually designed to generate network-scale dynamics. As shown in Figure 1E, we design a four-layer SNN architecture, containing an input layer (for pre-encoding visual and auditory signals to spike trains), a convolutional layer, a multi-sensory integration layer, and a readout layer. The synaptic weights are adaptive while the Motif masks are not. The membrane potentials in the hidden multi-sensory-integration layer are updated by both feed-forward potential and recurrent potential, shown in the following Equation (6):
{Si,t=Si,tf+Si,trVi,t=Vi,tf+Vi,trCdVi,tfdt=g(Vi,t−Vrest)(1−Si,t)+∑j=1NWi,jfXj,tCdVi,trdt=∑j=1NWi,jrSi,t·Mtr,l, (6)where C is for capacitance, Si,t is the firing flag of neuron i at time t, Si,tf and Si,tr are the firing flags of neuron i in the feedforward process and recurrent process, respectively, Vi,t denotes the membrane potential of neuron i at timing t, which includes feed-forward Vi,tf and recurrent Vi,tr, Vrest is the resting potential, Wi,jf is the feed-forward synaptic weight from the neuron i to the neuron j, and Wi,jr is the recurrent synaptic weight from the neuron i to the neuron j. Mtr,l is the mask incorporating Motif topology to further alter feed-forward propagation further. The historical information is saved in the forms of recurrent membrane potential Vi,tr, where spikes are created after the potential reaches a firing threshold, as illustrated in Equation (7).
{Vi,tf=Vreset,Si,tf=1 if(Vi,tf=Vth)Vi,tr=Vreset,Si,tr=1 if(Vi,tr=Vth)Si,tf=1 if(t−tsf<τref,t∈(1,T1))Si,tr=1 if(t−tsr<τref,t∈(1,T2)), (7)where Vi,tf, Vi,tr, Si,tf, and Si,tr are introduced in the previous Equation (6). Vreset is the reset membrane potential. τref is the refractory period. tsf is the previous feed-forward spike timing and tsr is the previous recurrent spike timing. T1 and T2 are time windows.
3.3. Neuronal plasticity and learning principleWe use three key mechanisms during network learning: neuronal plasticity, local plasticity, and global plasticity.
Neuronal plasticity emphasizes spatially-temporal information processing by considering the inner neuron dynamic characteristics (Jia et al., 2021), different from traditional synaptic plasticities such as STP and STDP. The neuronal plasticity for SNNs approaches the biological network and improves the learning power of the network. Rather than being a constant value, the firing threshold is set by an ordinary differential equation shown as follows:
dai,tdt=(α-1)ai,t+β(Stf+Str), (8)where Stf is the input spikes from the feed-forward channel. Str is the input spikes from the recurrent channel. ai,t is the dynamic threshold, which has an equilibrium point of zero without input spikes or -βα-1 with input spikes Sf + Sr from the feed-forward and recurrent channels. Therefore, the membrane potential of adaptive LIF neurons is updated as follows:
CdVi,tdt=g(Vi,t-Vrest)(1-Stf-Str)+∑j = 1NWi,jXj,t-γai,t, (9)where the dynamic threshold ai,t is accumulated during the period from the resetting to the membrane potential firing and finally attains a relatively stable value ai,t*=β1-α(Stf+Str). Because of the −γai,t, the maximum firing threshold could reach up to Vth + γai,t.
We set α = 0.9 to guarantee that the coefficient of ai,t is −0.1, β = 0.1 to ensure that the spike has the same weight as ai,t, and set γ to the common value of 1. Accordingly, the stable at*=0 for no input spikes, at*=1 for one input spike, and at*=2 for input spikes from two channels. When ai,t<(Stf+Str), the threshold ai,t will increase, otherwise, the threshold ai,t will decrease. It is clear that the threshold will change in the process of the neuron's firing, and as the firing frequency of the neuron increases, the threshold will also elevate, or vice versa.
For local plasticity, the membrane potential at the firing time is a non-differential spike, so local gradient approximation (pseudo-BP) (Zhang et al., 2021b) is usually used to make the membrane potential differentiable by replacing the non-differential part with a predefined number, shown as follows:
Gradlocal=∂Si,t∂Vi,t={1if(|Vi,t−Vth|<Vwin)0else, (10)where Gradlocal is the local gradient of membrane potential at the hidden layer, Si,t is the spike flag of neuron i at time t, Vi,t is the membrane potential of neuron i at time t, and Vth is the firing threshold. Vwin is the range of parameters for generating the pseudo-gradient. This approximation makes the membrane potential Vi,t differentiable at the spiking time between an upper bound of Vth + Vwin and a lower bound of Vth − Vwin.
For global plasticity, we used reward propagation, which has been proposed in our previous work (Zhang et al., 2021b). As shown in Figure 1C, the gradient of the hidden layer in training is generated from the input type-based expectation value and output error-based expectation value by transformed matrix (input type-based expectation matrix and output error-based expectation matrix), respectively, then the gradient signal will be directly given to all hidden neurons without layer-to-layer backpropagation, shown as follows:
{GradRl=Brandf,l·Rt−hf,lGradRL
留言 (0)