
記住我









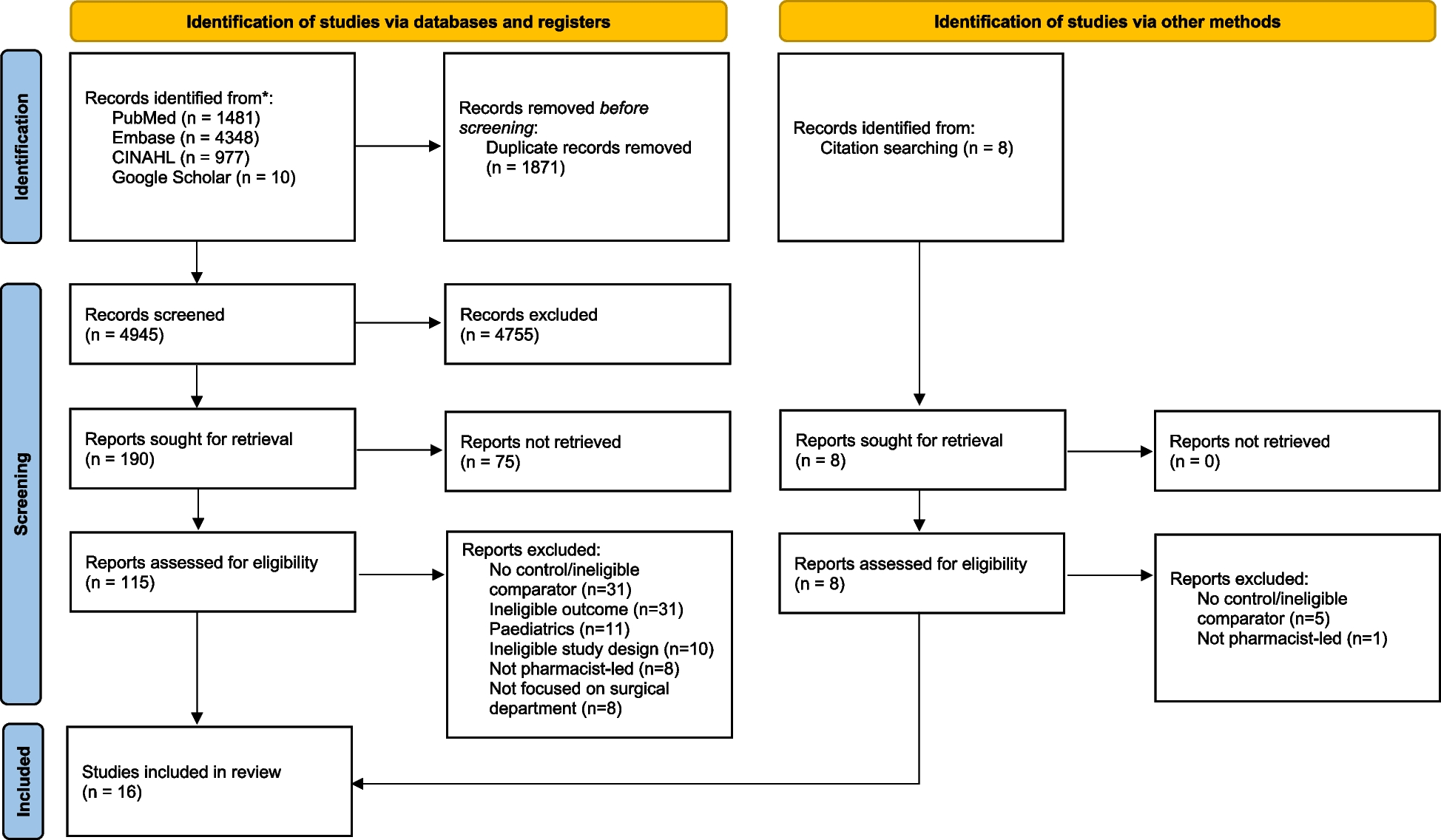
After duplicate removal, 574 potentially relevant studies were identified from all searched sources, 510 of which were subsequently excluded at the title and abstract screening stage (Fig. 1). Of the 64 full-text papers (including 5 conference abstracts or proceedings) assessed for eligibility, 40 were excluded for not fulfilling one or more inclusion criteria, as reported for each individual study in Additional file 3. Twenty-four studies were included in the systematic review, including 161,524 patients [19, 33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55]. None of the screened conference abstract or proceedings met the inclusion criteria; consequently, only full-length papers were included in the systematic review. Based on the criteria described in the “ Materials and methods” section, after evaluating DOR within unique combinations of data sources, a total of 36 algorithms were extracted from the 24 included studies.
Fig. 1
Flow diagram of the study selection process based on PRISMA guidelines
Characteristics of included studiesTable 2 outlines the characteristics of the 24 studies, published over three decades, from 1993 to 2022, and based on data from 1985 to 2018. Nine (38%) came from the USA, 8 (33%) from Canada, 6 (25%) from EU countries, and 1 (4%) from Australia.
Table 2 Characteristics of the included studies with respect to the sample used to assess diagnostic accuracy of the algorithms (i.e., internal or external validation)Study designThere were 14 cross-sectional, 8 longitudinal, and 2 case–control studies.
Population included in the studiesSix studies (25%) included a general population recruited from primary or outpatient settings, and four additional studies (17%) were derived from the same population but were limited to subgroups: veterans (three studies, of which one included only hypertensive subjects) and patients with chronic obstructive pulmonary disease (COPD, one study). Eleven studies (46%) included hospitalized patients only, and the remaining 3 (13%) included hospitalized patients with other cardiac conditions (acute myocardial infarction, n = 1; atrial fibrillation, n = 1; undergoing coronary angiography, n = 1). Age varied from a reported mean or median of 52.0 years to 81.5 years, with two studies including people from the age of 40, one from the age of 50, and three from the age of 60–66 years. Four studies did not report any information on age. The percentage of females varied greatly, from 0 to 63.7%, with three studies not reporting information on sex composition of included subjects.
Target conditionHF was the target disease in 21 studies (88%). Incident HF, advanced HF, and HF with LVSD each were the target disease in a singular study.
Reference standardTwenty studies (83%) reviewed clinical records to determine the presence of HF (reference standard). Of the remaining four studies, two were based on HF registries, one on medical evaluation, and one on a clinical research cardiology database. Details about the different definitions of HF adopted for the reference standard evaluation are reported in Supplementary Table S1 in Additional file 4. Only one study (4%) published in 2021 adopted the current globally accepted definition of HF [34]. Five studies (21%) referred to different versions of the ESC guidelines, three studies (13%) to the Framingham guidelines, three to other published and referenced definitions, three reported criteria used to define HF in the study without reference to a guideline, and nine (37%) stated that the diagnosis was established by a physician.
Index testHospital discharge data were included in 23 algorithms (64%) in 19 studies, always using codes from the ICD coding system, in its different versions (4 algorithms used only ICD-10, 3 used ICD-10 or −9, 15 used ICD-9, and 1 used ICD from 8 to 10). Eight algorithms (22%) in seven studies included outpatient diagnostic codes (one algorithm used ICD-10 or −9, and the rest used ICD-9 only). Drug prescription or dispensation databases were included in five algorithms (14%) in three studies, using either ATC or unspecified coding. Three algorithms (8%) in two studies included diagnostic and/or treatment information from a primary care database. One algorithm (3%) included emergency services data, and another one used exemption from co-payments. Fifty-five percent of algorithms (n = 20) were based on a single data source, 28% on two types of data, and 17% on three. Further details on the developed algorithms and types of included data are reported in Supplementary Table S2 in Additional file 4.
HF prevalenceExcluding studies performed on subjects positive to the index test only (where the population prevalence cannot be assessed), reported HF prevalence in the population from which the validation sample was derived ranged from 2.9 to 65.0% overall. The median prevalence of HF in the validation sample was 5.6% (range 2.9–9.8%) in the 6 studies on general population and of 13.7% (9.3–100%) in the 8 studies including hospitalized patients.
Reporting of diagnostic accuracy measuresFor the 6 studies (103,018 patients, 14 extracted algorithms) that were performed in the general outpatient population, the sensitivity ranged from 24.8 to 97.3%, and the specificity ranged from 35.6 to 99.5% (Table 3, Fig. 2). For the 8 studies including hospitalized patients and fully assessing diagnostic accuracy (14,957 patients, 10 algorithms extracted), the sensitivity ranged from 29.0 to 96.0%, and the specificity ranged from 65.8 to 99.2% (Table 4, Fig. 3). The 3 studies that only included a sample of subjects who were positive for the algorithm (2964 patients, 3 algorithms extracted) presented PPVs ranging from 82.0 to 99.5% (Table 4, Supplementary Fig. S1 in Additional file 4). The diagnostic accuracy measures of the remaining 7 studies (40,585 patients, 9 algorithms) are reported in Supplementary Table S3, Supplementary Fig. S2, and Supplementary Fig. S3 in Additional file 4. The studies including veterans (n = 2) and hypertensive veterans (n = 1) in the general population had a sensitivity ranging from 74 to 87% and a specificity ranging from 74.8 to 100%. The study with individuals with COPD (n = 1) using data from a primary care database reported a sensitivity of 93.1% and a specificity of 90.8% for the best algorithm. The three studies including hospitalized patients with acute myocardial infarction (n = 1), atrial fibrillation (n = 1), or undergoing coronary angiography (n = 1) reported sensitivities from 36.0 to 81.8% and specificities from 59.3 to 95.7%.
Table 3 Diagnostic accuracy results — general populationFig. 2
Forest plots of sensitivity and specificity — studies on general population (see Table 3 for further details). N, total number; T + , algorithm positives; HF + , with heart failure
Table 4 Diagnostic accuracy results — hospitalized patientsFig. 3
Forest plots of sensitivity and specificity — studies including hospitalized patients (see Table 4 for further details). N, total number; T + , algorithm positives; HF + , with heart failure
Assessment of biasStudy qualitySeventeen out of 24 studies (71%) were judged to be at high or unclear risk of bias in at least 1 domain. Patient selection was the domain with the highest percentage of studies at high risk of bias (eight studies, 33%), with one additional study having an unclear risk of bias (see Fig. 4 and Supplementary Table S4 in Additional file 4). Two studies did not include a random sample of patients: one randomly sampled patients but only among primary care physicians accepting to participate in the study [34], and the other chose to enrol patients presenting in a particular week [19]. Four studies applied inappropriate exclusions, discarding subgroups of subjects that would have been more difficult to diagnose correctly [35, 40, 47, 48]. Finally, two studies employed a case–control design [36, 38]. Concerning the reference standard domain, four studies (17%) were affected by verification bias: in three studies, only index test-positive subjects were verified with the reference standard [41, 43, 44], allowing to estimate PPV only; in the fourth one, only subjects positive to a pre-screening received the reference standard assessment, thus artificially increasing prevalence [50]. Three studies (13%) also had an unclear risk of bias in this domain, as no enough information on how the reference standard was performed was present [42, 45, 49]. No risk of bias was detected concerning the index test domain. Issues were present in the flow and timing domain for seven studies (29%), where not all sampled patients received the reference standard [36, 37, 41, 43, 44, 49, 50, 50], mainly because the clinical records were not available for some patients. Also, in one of these studies, not all patients received the same reference standard [50], and in another one, not all patients were included in the final analysis [49].
Fig. 4
Risk of bias (left panel) and applicability concerns (right panel) summary percentages across included studies, assessed and reported using the QUADAS-2 tool
ApplicabilityWhen evaluating applicability, patient selection was once again the most critical domain, with 38% of studies (n = 9) raising applicability concerns because of how and where subjects were recruited: in a second-level hospital [38], only nonelective hospital admissions [41], subjects affected by a particular comorbidity [34, 42, 45, 49], or veterans only [19, 47, 48]. Poor reporting issues were found, especially concerning patient selection. One study did not report the number of patients with the target disease.
Publication biasIn this systematic review, we included in the Deeks’ funnel plot 27 out of 36 (75%) algorithms, for which it was possible to fully reconstruct the 2 × 2 table and calculate both the DOR and ESS. The funnel plot of these algorithms was substantially symmetric, and the regression test of asymmetry had a nonsignificant value (p-value = 0.99), indicating no evidence of a potential publication bias (Fig. 5).
Fig. 5
Deeks’ funnel plot to assess potential publication bias. The plot is substantially symmetric indicating no evidence of publication bias (regression test of asymmetry p-value = 0.99)
留言 (0)