
記住我







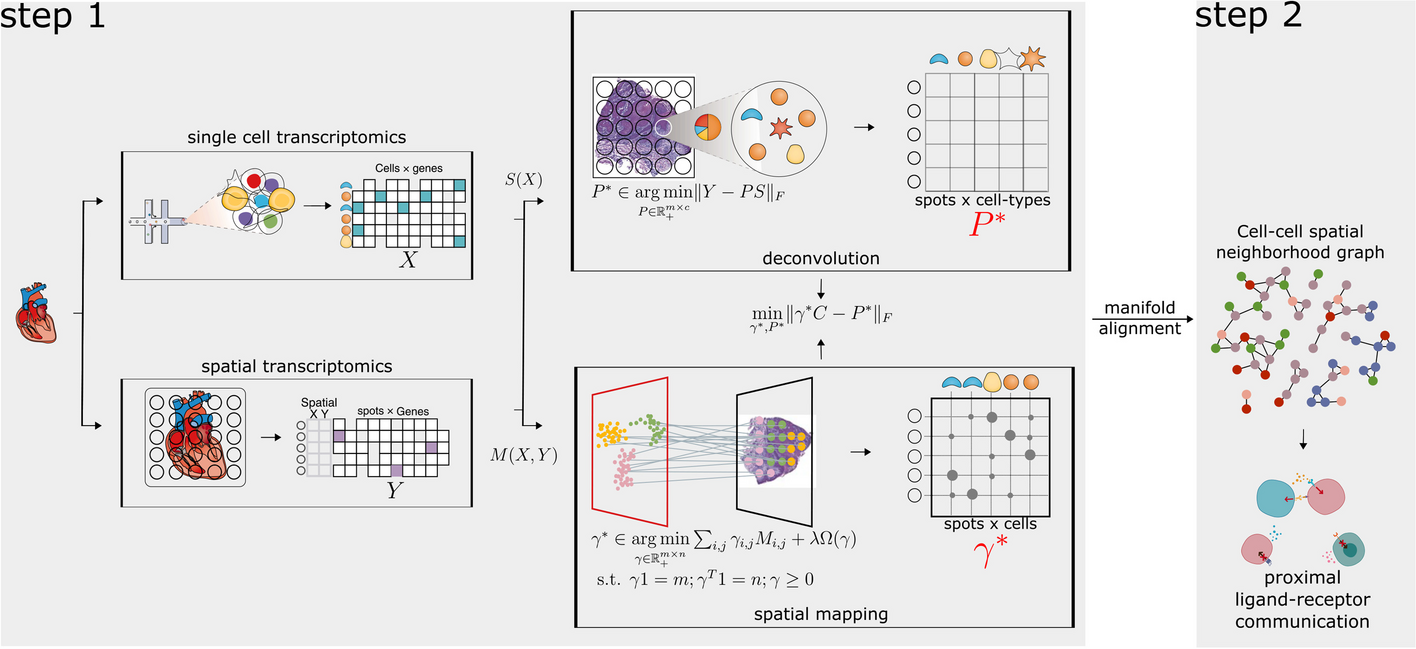
SDePER is built upon the combination of a conditional variational autoencoder (CVAE) [34] and a graph Laplacian regularized regression model (GLRM). The CVAE component aims to remove platform effects and the GLRM component aims to estimate cell-type compositions at each spot based on cell-type-specific signatures from reference scRNA-seq data with considerations of sparsity and spatial correlation of cell-type compositions between neighboring spots in the tissue. Based on the estimated cell-type proportions, the imputation of cell-type compositions and gene expression at unmeasured locations in refined spatial maps with higher resolution is performed using a nearest neighbor random walk.
Conditional variational autoencoder for platform effect adjustmentThe CVAE model [34] considers the two technology platforms, i.e., reference scRNA-seq and ST, as two conditions. The loss function of CVAE is defined as
$$\text=-KL(_(}|},c)\boldsymbol|\left|_\left(}\right)\right)+ }_}}\left(\text\left(_\left(}|},c\right)\right)\right),$$
where \(}\) represents the gene expression profile, \(c\) is the conditional variable, \(}\) is the latent embedding in the latent space, \(_\) is the encoder parameterized by \(\phi\) to embed samples into the latent space, \(_(})\) is the prior distribution of latent embedding \(}\) defined as the standard Gaussian distribution \(\mathcal(0, })\), \(_(}|},c)\) is the decoder parameterized by \(\omega\) to generate gene expression data given the latent embedding \(}\) and conditional variable \(c\), and KL is the Kullback-Leibler divergence function. The CVAE loss function is optimized using Adam [51], which will learn \(_(}|},c)\), \(_(}|},c)\) and \(}\) from the data.
Since CVAE assumes a Gaussian distribution for data under both conditions, it is critical for the data under the scRNA-seq condition to cover a similar spectrum of cell-type proportions as the ST data. However, the reference scRNA-seq data only has data with one single-cell type, whereas each spot in the ST data can have cells from multiple cell types. To make the training data under the two conditions have a similar spectrum of cell-type compositions, pseudo-spot data are generated from the reference scRNA-seq data to provide a wide spectrum of cell-type compositions for the input under the scRNA-seq condition. For each pseudo-spot, we randomly select a set of cells from reference scRNA-seq data and calculate the average normalized gene expression across cells as the expression profile for the pseudo-spot. The range of the number of selected cells per pseudo-spot is specified based on the cell density in real ST data. In total, the number of pseudo-spots generated is \(\text(100\times N\times K, \text)\), where \(N\) is the number of spots in the real ST data and \(K\) is the number of cell types in the reference scRNA-seq data. We train the CVAE model using 80% of the pseudo spots, the reference scRNA-seq data, and real ST data. The rest 20% pseudo-spots are used as validation data for learning rate decay and early stopping. Genes used in CVAE are the union of top highly variable genes and cell-type marker genes identified from the reference scRNA-seq data identified using Scanpy 1.9.1 [52]. The sizes of both gene lists can be tuned by users based on the properties of reference scRNA-seq data. Because the training of CVAE is sensitive to differences in data range across different genes, the normalized expression of each gene is further rescaled separately for the scRNA-seq and ST condition to be from 0 to 10 using min–max scaling. The conditional variable in CVAE represents which platform (scRNA-seq or ST) generated the data and is set to 0 or 10 by default. In the training data, the conditional variable for real ST data was set to 10 for the ST condition and the conditional variable for the pseudo-spot data and reference scRNA-seq data was set to 0 for the scRNA-seq condition.
In the CVAE training, we set the number of neurons in latent space as three times the number of cell types in the reference scRNA-seq data and use one hidden layer for both encoder and decoder under each condition, in which the number of neurons is the largest integer no more than the geometric mean of the number of neurons in the input layer and latent space. We use Adam [51] for optimization and the initial learning rate is set to 0.003 with decay specified based on the value of loss function of the validation dataset. The number of epochs is set to 1000 and the early training stopping criteria is when the value of loss function of the validation dataset increases.
After the CVAE training, the real ST data is embedded into the latent space for the ST condition (conditional variable = 10) and then is decoded using the decoder for the scRNA-seq condition (conditional variable = 0). The reference scRNA-seq data is encoded and decoded for denoising using the encoder and decoder for the scRNA-seq condition (conditional variable = 0). The decoded gene expression levels are min–max scaled back using the scRNA-seq rescaling factors. For the real ST data, the rescaled values are further multiplied by 10,000 and rounded to the nearest integers. By using the same decoder, ST and scRNA-seq data are transformed into the same space to remove platform effects. Visualization of the transformed data showed that enough biological signals were retained to separate different cell types (Additional File 1: Fig. S27). The transformed real ST data and reference scRNA-seq data serve as input to the GLRM component. In addition, the mean–variance relationship was well preserved after the CVAE adjustment in all real datasets (Additional File 1: Fig. S28).
Multiple batch effect removal methods have been developed for scRNA-seq data including MNN [53], Harmony [54], Seurat Integration [55], and so on, which can be used to correct for platform effects as well. However, these methods strongly rely on the assumption that there are common cell types or shared biological cell states between batches. Specifically, the MNN-based approaches, such as the Seurat Data Integration method, identify pairs of cells from different batches and the difference between cells in each pair is utilized to estimate batch effects. When scRNA-seq and ST data are considered as two batches by these approaches, each spot from the ST data is a mixture of multiple cells with potentially multiple cell types while each cell from the scRNA-seq data has only one cell type. Unless there are many spots in the ST data that have only one cell type, the identified “cell pairs” do not have the same biological state and the difference between them include both platform effects and cell-type composition difference. This causes the estimated batch effects to be larger than platform effects, so these approaches cannot provide adequate adjustment for platform effects. CVAE is a deep generative model which learns the data distribution in a latent space and a generative process to generate new data points from the learned distribution. It assumes that scRNA-seq data and ST data share the same type of distribution in the embedding space, which is a weaker assumption than the batch correction methods. We accommodate for this assumption by adding pseudo-spots in the CVAE training data. The generated new data will retain the original data distribution as well as the original biological meaning so the CVAE adjusted data is still gene expression data, which is critically important for the GLRM component because it assumes a linear additive relationship between the ST and reference data. To demonstrate the advantage of CVAE, we replaced the CVAE component in SDePER with Seurat Integration method and ran it on the STARmap-based simulated data with external reference. We compared the results to those of SDePER and GLRM (Additional File 1: Fig. S29). The comparison showed that Seurat Integration did correct for a certain part of the platform effects so it had a certain improvement over GLRM. But SDePER was able to achieve further and larger improvement over Seurat + GLRM, suggesting higher efficiency of CVAE in correcting for platform effects than Seurat.
Graph Laplacian regularized model for cell-type deconvolutionWe fit a graph Laplacian regularized model to estimate cell-type compositions in each spot using the transformed ST and reference scRNA-seq data. Since biological signals can be lost by the CVAE adjustment, we identified cell-type marker genes from the transformed reference scRNA-seq data by comparing each cell type to every other cell type using the Wilcoxon Rank Sum test implemented in the FindMarker function in Seurat. Genes with false discovery rate less than 0.05, fold change ≥ 1.2, pct.1 ≥ 0.3 and pct.2 ≤ 0.1 were kept and sorted based on the fold change. By default, the top 20 genes across all comparisons were merged and used to fit the GLRM model. The transformed ST data of each gene is assumed to follow a Poisson distribution with the log-transformed mean being a linear combination of its transformed across all cell types, which forms the base model. The transformed expression profile of each cell type is calculated as the average expression profiles across cells of the given cell type from the transformed reference scRNA-seq data. On top of the base model, we incorporate the spot location information using graph Laplacian regularization that encourages cell-type compositions of neighboring spots to be similar. We also enforce cell-type sparsity within each spot using adaptive LASSO regularization. Specifically, the GLRM component consists of the following three major components.
Base modelThe transformed ST data is modeled using a Poisson-loglinear model which considers dispersion in the data (Additional File 1: Fig. S28). For each spot \(i\) and gene \(j\), the transformed ST count \(_\) is assumed to follow a Poisson distribution:
$$_|_\sim \text\left(__\right),$$
where \(_\) is the observed total UMI count of spot \(i\) and \(_\) represents the true underlying relative expression level of gene \(j\) in spot \(i\). The rate parameter \(_\) is further modeled as a combination of expression profiles of all \(K\) cell types weighted by the cell-type proportions,
$$\text\left(_\right)=_+\text\left(_^__\right)+_,$$
where \(_\) is a parameter representing spot-specific fixed effect, \(_\) is the proportion of cells from cell-type \(k\) in spot \(i\), \(_\) is the mean expression level of gene \(j\) in cell-type \(k\) calculated from the transformed reference scRNA-seq data, and \(_\) is a random error that follows a normal distribution with mean 0 and variance \(^\) as defined in RCTD [12]. The distribution of \(_\) is relaxed to include a heavy tail using an approximation to a Cauchy–Gaussian mixture distribution, which is robust to outliers [56],
$$p\left(\epsilon \right)=\left\\frac^^}^}}, \left|\epsilon \right|\le 3\sigma \\ \frac^)\surd \pi }^}, \left|\epsilon \right|>3\sigma \end,\right.$$
Where \(C\) is a normalizing constant which is chosen to make \(p\left(\epsilon \right)\) integrate to 1. The model parameters \(_\) are subject to the constraint that \(_^_=1\) and \(_\ge 0\) for all \(i\) and \(k\). We considered \(_\) because previous studies [37, 57,58,59,60] demonstrated that the gene expression profile of cells of the same type could vary depending on where they are located in the tissue, potentially due to the influences from neighboring cells or tissue microenvironment.
Adaptive LASSO regularizationTo enforce the local sparsity of cell types in each spot, we penalize the likelihood function of the base model using the adaptive Lasso penalty [61]. For each spot \(i\), we define the adaptive Lasso penalty as
$$r\left(_\right)=_^_\left|_\right|,$$
where \(_\) is the reciprocal of maximum likelihood estimation (MLE) of \(_\) from SDePER without the adaptive LASSO and graph Laplacian penalties (base model), serving as the weight of \(_\) in the adaptive Lasso penalty.
Laplacian regularizationTo incorporate spatial information, we represent the physical proximity between spots using an adjacency matrix \(}_]}_\). Although \(}\) can be calculated using the Euclidean distance between spots, for simplicity, we use unweighted adjacency matrix throughout this article, where \(_\) is an indicator of whether spot \(i\) and \(j\) are neighbors on the tissue slide, and \(I\) is the total number of spots. The graph Laplacian is defined as \(}=}-}\), where \(}\) is a diagonal matrix with \(_=__\), the degree of spot \(i\). The graph Laplacian penalty is defined as
$$\mathcal\left(}\right)=\frac\sum_^__-_\Vert }_^=\text\left(}}^}}\right),$$
where tr(∙) is the trace of a matrix. This penalty measures the aggregate deviation of \(}\) between neighboring spots and therefore encourages \(}\) to be similar across neighboring spots.
Taken together, we fit the GLRM model by minimizing the following objective function:
$$F\left(},\boldsymbol,},\boldsymbol^\right)=_^\left[_\left(}}_,_,}, ^\right)+_r\left(}}_\right)\right]+_\mathcal\left(}\right).$$
The first term of the objective function is the negative log-likelihood of the base model. The second term is the local adaptive Lasso penalty that enforces cell types to be sparsely present within each spot. The third term is the graph Laplacian penalty to encourage smoothness of cell-type compositions across neighboring spots. \(_\) and \(_\) are two positive hyperparameters.
The objective function is minimized using a two-stage strategy. To provide initial values of all parameters (\(}\), \(\boldsymbol\) and \(^\)) for optimization, we calculate the gene expression profile of cell-type \(k\) using the average library size normalized expression levels of all identified cell-type marker genes across all cells of type \(k\), denoted as \(}_\). The maximum likelihood estimations (\(\widehat}}\), \(\widehat}\), and \(}^\)) of the base model are obtained using the L-BFGS algorithm [62] in SciPy 1.8.1 [63] and serve as the initial values for optimization. In the first stage of optimization, we perform cell-type selection in each spot by minimizing the negative log-likelihood function of the base model with the adaptive LASSO penalty: \(_^\left[_\left(}}_,_|\widehat}}, }^\right)+_r\left(}}_\right)\right]\) using alternating direction method of multipliers (ADMM) [64]. A cutoff value of 0.001 is applied to the estimate \(\widehat}}\) to determine which cell types are present in each spot. In the second stage of optimization, we only include cell types selected from the first stage for each spot in the base model and minimize the negative log-likelihood function of the base model with graph Laplacian regularization using ADMM: \(_^_\left(}}_,_|\widehat}}, }^\right)+_\mathcal\left(}\right)\). The values of the two hyperparameters, \(_\) and \(_\), are chosen using fivefold cross-validation. The cell-type marker genes identified from the transformed reference scRNA-seq data were randomly divided into five groups with equal size. Each group was considered as validation data and the rest groups were used as training datasets. For given values of \(_\) and \(_\), the training data was used to fit the GLRM model, which was used to calculate the log-likelihood of the validation data using the base model. The log-likelihood of the five validation datasets was averaged and compared across different settings of \(_\) and \(_\). The setting that achieved the largest average log likelihood was chosen.
Imputation on cell-type composition and gene expressionSDePER borrows information from neighboring spots to perform imputation of cell-type compositions at unmeasured locations in refined tissue map with arbitrary resolution by taking the nearest neighbor random walk on the spatial graph. We first use the “finding contour” function in opencv [65] to determine the contours of the tissue shape and distinguish outlines of the tissue and holes inside the tissue. The spatial spots closest to the outline and border of holes are set to be edge spots. We also develop a custom algorithm to calculate the missing spots in the holes. Suppose the spatial coordinates of the center for spot \(i\) is \(_=(_, _)\) and the distance between centers of two neighboring spots is D. To construct a new spatial map at enhanced resolution, we first create the smallest rectangular region that covers all centers of original spots using \(\left[}_\left(_\right), }_\left(_\right)\right]\times [}_\left(_\right), }_\left(_\right)]\). This rectangular is then gridded into squares with side length \(d (d<D)\). Among all the squares, those with center located at \(_^}=(_^}, _^})\) satisfying one of the following criteria are considered as spots in the new map and imputed:
$$}_\right\}}\Vert _^}-_\Vert =\le D \text }_\right\}}\Vert _^}-_\Vert \le \frac.$$
These criteria filter out center locations that are far away from the edge and inner spot, outside the tissue slice or in biological holes. The new spatial map at enhanced resolution (square side length = \(d\)) consists of the spots with centers \(}}^}=\left\_^}\right\}\), \(^=1,\dots , ^\).
Let \(}}_^}\) denote the cell-type proportions in spot \(^\) in the new spatial map. To perform imputation, we first assign an initial value for \(}}_^}\) by finding the nearest original spot(s) of spot \(^\) and set \(}}_^}^\) as the average cell-type proportion among its neighbors. We construct a Gaussian kernel \(}\) as follows
$$_^^}=\left\0, _^^}>\phi \\ ^_^^}^}^}}, _^^}\le \phi \end ^,^=\text,\dots ,^\right.,$$
where \(_^^}=\Vert _-_\Vert\) is the distance between two spots \(^\) and \(^\) in the new map, \(\phi\) is a predefined neighborhood size within which spots contribute to the imputation of each other, and \(^\) is the variance. A nearest neighbor random walk matrix is constructed as \(}=}}^}\), where \(}\) is a diagonal matrix with \(_^^}=_^}_^^}\). The imputed cell-type compositions are obtained by taking a one-step nearest neighbor random walk with the graph which can be written as
We further impute gene expression at enhanced resolution as \(}}_}=}}_}}}^}\), where \(}\) is the observed UMI counts from ST data, normalized by spot’s sequence depth, and \(}}^\) is the Moore–Penrose inverse of \(}\) with \(}}^=}}^}\right)}^}}^\).
The hyperparameters in the Gaussian kernel \(}\) include \(\phi\) and \(^.\) For a given real ST data, the hyperparameter tunning was conducted using the STARmap-based simulated data. We conducted coarse-graining procedures on the STARmap data to generate simulated ST dataset with different spot sizes varying from 100 × 100 to 1000 × 1000 with an interval of 100, which correspond to high to low resolution. In each simulated ST dataset, we know the true cell-type proportions in each spot. For a given setting of \(\phi\) and \(^\), we impute the cell-type proportions using the simulated dataset with spot size 1000 × 1000 to reconstruct spatial maps with different resolutions higher than 1000 × 1000 (smaller spot size). Then we compare the imputed cell-type proportions to the ground truth and calculated the average RMSE across the different higher resolution levels. The hyperparameter setting that achieved the smallest average RMSE was chosen. The search ranges for \(\tau\) and \(\phi\) are both 1–200 μm.
Other deconvolution methods for comparisonSeven state-to-art spatial deconvolution methods were chosen to compare with SDePER, including RCTD (version 2.0.1) [12], SpatialDWLS (implemented in the R package Giotto, version 1.1.2) [26], SONAR (version 1.0.0) [28], SPOTlight (version 1.8.0) [25], cell2location (version 0.1.3) [15], DestVI (implemented in the python package scVI, version 1.1.3) [14], and CARD (version 1.0) [24]. We followed the tutorial on the GitHub repository of each method and used the recommended default parameter settings for the deconvolution analyses conducted in this article. When parameters are required to be set manually, we used the values suggested in the vignettes.
Simulation studiesTo evaluate the method performance and demonstrate the impact of platform effects on all deconvolution methods, we simulate spot-level ST data in multiple different ways.
STARmap-based simulationWe first simulated ST data based on the adult mouse primary visual cortex STARmap data that has single-cell resolution [35]. We extract experiments “20,180,410-BY3_1kgenes” and “20180505_BY3_1kgenes” and manually put them in the same spatial map with enough space in between so that cells or simulated spots from different experiments are not considered as spatial neighbors. To simulate the ST data, we gridded the tissue slide into squares with a side length of ~ 51.5 μm as capture spots, which generated 581 spots with 1 to 12 cells and an average of 3.6 cells present per spot. We only kept cells from cell types present in both STARmap data and external reference scRNA-seq data. In each spot, the proportion of cells from each cell type is calculated and serves as ground truth for performance evaluation. The simulated gene expression level of gene \(j\) for a given spot that contains cells \(i=1,\dots ,n\) is calculated as \(nUM_=\lceil \frac_^\left(\frac_}__}\right)}\times N\rceil\), where \(_\) is the number of UMIs of gene \(j\) in cell \(i\) from the STARmap data and \(N\) is a fixed scaling factor set to be 1000.
Sequencing-based simulationThe STARmap technology is a hybrid technology of in situ hybridization and sequencing. The protocol enriches for transcripts using hybridization techniques and the final nUMI is generated based on sequencing. To simulate ST data that are purely sequencing-based, we utilized a scRNA-seq dataset from the mouse visual cortex [66] measured using the inDrops technique (GEO accession number: GSE102827). We modified the STARmap data by retaining the spatial location of each cell but replacing its expression profile with that of a randomly chosen cell of the same type from the inDrops data. Then the same coarse-graining procedure was applied to this modified STARmap data to simulate purely sequencing-based ST data.
External and internal referenceTo demonstrate the impact of platform effects on the method performance, each method was applied to the simulated data using two different reference scRNA-seq datasets: internal reference and external reference. The internal reference data is the original ST data with single-cell resolution so there were no platform effects. For STARmap-based simulation, the internal reference data was the STARmap data. For sequencing-based simulation, the internal reference data is the inDrops data (GEO: GSE102827). The external reference data is an independent publicly available scRNA-seq dataset. For both STARmap-based and sequencing-based simulations, the adult mouse visual cortex scRNA-seq dataset (GEO accession number: GSE115746) [67] was used as reference data. Under this case, significant platform effects were expected to exist because the simulated ST data and reference data were generated using the in situ sequencing and SMART-seq technologies, respectively. We selected 12 overlapping cell types between the external reference data and the STARmap data for deconvolution, which include astrocytes, excitatory neurons layer 2/3, excitatory neurons layer 4, excitatory neurons layer 5, excitatory neurons layer 6, endothelial, microglia, oligodendrocyte, Pvalb-positive cells, Vip inhibitory neurons, Sst neurons, and smooth muscle cells. In total, 2002 cells and 1020 genes were included in the STARmap data while 11,835 cells and 45,768 genes were in the external reference data.
Simulation for mismatching cell typesDeconvolutions using the overlapping 12 cell types between the STARmap data and external reference scRNA-seq data represent analysis scenario 1, under which cell types in the reference data match perfectly with those in the ST data. However, in practice, they can have mismatching cell types, so we modified the external reference data to demonstrate the robustness of all methods to mismatching cell types. In analysis scenario 2, we remove Vip inhibitory neurons (n = 1690) from the reference data. In analysis scenario 3, we added “high intronic” cells (n = 182), which are not present in the STARmap data, to the reference data.
Simulations for rare cell typesTo assess the robustness of SDePER to rare cell types, we conducted the following two simulation analyses by choosing oligodendrocytes (“Oligo”) as the “rare cell type” for investigation. First, we down-sampled Oligo cells in the reference scRNA-seq data to a given number (5, 10, 20, and 50) for multiple times and used each down-sampled reference data to deconvolve the STARmap-based simulated ST data. In the second simulation analysis, we examined the performance of SDePER on Oligo cells using groups of spots stratified based on the number of Oligo cells per spot from the STARmap-based simulation. All the simulated spots were divided into groups based on the total number of cells (n) and the number of oligodendrocytes per spot. Within each group of spots with the same total number of cells, both the relative absolute error (RAE) and the false negative rate (FNR) were calculated.
Simulations for high cell densityTo simulate ST data with high cell density, we kept the physical spot size the same as in the sequencing-based simulation but increased the total number of cells in each spot by 3 or 6 times, which corresponds to approximately 3 to 36 cells and 6 to 72 cells per spot with an average of 10.8 and 21.6 cells per spot, respectively. In each spot, the cell-type proportions remained the same but for each existing cell type, three or six times more cells were randomly selected from the inDrops without replacement to calculate the simulated spot data.
Simulations for small number of cell typesTo evaluate the necessity of adaptive Lasso when the number of cell types is small, we removed all cells that do not belong to five chosen cell types (eL2/3, eL4, eL5, eL6, and Oligo) from the STARmap data. The same simulation procedure was conducted to simulate STARmap-based ST data. When conducting deconvolution on the simulated ST data using external reference, cells that do not belong to the five chosen cell types were also removed from the reference data.
Ablation testsTo understand the contribution of different components in SDePER, we conducted ablation tests by disabling the CVAE for platform effects removal, pseudo-spots inclusion in the CVAE training, adaptive LASSO penalty for sparsity, or graph Laplacian penalty for spatial correlation in SDePER. Three datasets were used including those from the STARmap-based simulation, sequencing-based simulation, and the simulation for high cell density. For each dataset, we consider the performance of SDePER as the baseline. The performance of SDePER with each component disabled was compared to the baseline performance to assess the contribution of the component. For adaptive LASSO penalty, the dataset from simulations for a small number of cell types was also used for the ablation test.
Performance evaluation criteriaTo evaluate the method performance, we compare the cell-type compositions estimated by each method, \(}}}_\), to the ground truth \(}}_\) for each spot \(i\) using the root mean square error (RMSE) that quantifies the overall estimation accuracy, Jensen–Shannon Divergence (JSD) that assesses similarity between the estimated cell-type distribution and ground truth per spot, Pearson’s correlation coefficient that measures the similarity of estimation to ground truth, and false discovery rate (FDR) that measures how many cell types were falsely predicted to be present. Formulas of these criteria are as follows:
$$\text\left(}}}_\right)=\sqrt_^}_-_\right)}^}.$$
\(\text(}}}_\Vert }}_)=\frac (KL(}}}_\Vert \frac}}}_+ }}_}) + KL(}}_\Vert \frac}}}_+ }}_}))\), where \(\text(\cdot \Vert \cdot )\) represents Kullback–Leibler divergence.
$$cor\left(}}}_ , }}_\right)=\frac_^(}_-} }_)(_-}_)}_^}_-} }_\right)}^}\sqrt_^_-}_\right)}^}}.$$
$$FD_=\frac_^I(}_\ne 0, _=0)}_^I(}_\ne 0)}.$$
Real dataset analysisMouse olfactory bulb datasetWe obtain the mouse olfactory bulb (MOB) ST data from the Spatial Research lab [4]. We focus on the “MOB replicate 12” file which contains 16,034 genes and 282 spots. An independent scRNA-seq data is also downloaded as the reference scRNA-seq data (GEO accession number: GSE121891) [36], which consists of 18,560 genes and 12,801 cells from 5 cell types: granule cells, olfactory sensory neurons, periglomerular cells, mitral and tufted cells, and external plexiform layer interneurons.
To apply SDePER on the MOB dataset, we select 250 highly variable genes and 244 cell-type marker genes from the reference scRNA-seq data, which form a set of 434 unique genes used in the CVAE component for platform effects removal. We randomly select 10–40 single cells from the scRNA-seq data to generate a pseudo spot to mimic the number of cells per spot suggested in the MOB data; 168 cell-type marker genes are used in GLRM component. The hyperparameter \(_\) is chosen to be 1.931 and \(_\) to be 5.179 based on cross-validation. The running time of SDePER is 0.56 h in total using a 20-core, 100 GB RAM, Intel Xeon 2.6 GHz CPU machine.
Melanoma datasetWe download the melanoma dataset from the Spatial Research lab [7]. We focus on the second replicate from biopsy 1 because it contains regions annotated as lymphoid tissue and is extensively examined in the original paper. Biopsy 1 contains 16,148 genes and 293 spots. The reference scRNA-seq dataset is downloaded from GEO database (accession number: GSE115978), which contains 23,686 genes and 2495 cells from 8 selected samples. In total, seven cell types are present in the reference data, including malignant cells, T cells, B cells, natural killer (NK) cells, macrophages, cancer-associated fibroblasts (CAFs), and endothelial cells [38].
We choose the top 300 highly variable genes and 280 marker genes, corresponding to 534 unique genes for the CVAE component in SDePER. The number of cells per pseudo-spot is set to be 5–40 cells as provided in the original paper; 145 cell-type marker genes are used in GLRM component. The hyperparameter \(_\) is chosen to be 1.931 and \(_\) to be 37.276 based on cross-validation. The running time of SDePER is 0.56 h in total using a 32-core, 100 GB RAM, Intel Xeon 2.6 GHz CPU machine.
Breast cancer datasetWe obtain the HER2-positive breast cancer spatial transcriptomics dataset from a previous study [8]. The first section of patient H with 15,029 genes and 613 spots is selected for the analysis. We obtain the scRNA-seq data of five HER2-positive tumors from GEO database (accession number: GSE176078) [39] as the reference scRNA-seq data for deconvolution. The reference data consists of 29,733 genes and 19,311 cells from 9 cell types.
For the CVAE component of SDePER, we select the top 1500 highly variable genes and 824 cell-type marker genes, corresponding to 1942 unique genes. Each pseudo-spot is assumed to contain 20–70 cells based on estimation by other cancer ST studies using the same ST platform [68]; 290 cell-type marker genes are used in GLRM component. The hyperparameter \(_\) is chosen to be 1.931 and \(_\) to be 37.276 based on cross-validation. The running time of SDePER is 1.8 h in total using a 32-core, 100 GB RAM, Intel Xeon 2.6 GHz CPU machine.
Idiopathic pulmonary fibrotic lung datasetWe measured the ST data of a human IPF lung sample from an explanted lung of a patient with end-stage IPF explanted lung (Yale IRB:1601017047) using the 10 × s Genomics Visium platform, which is a complex and challenging sample with vague structure and different lung compartments including the bronchi, vascular, mesenchyme, and immune compartment. We selected one block of frozen lung tissue obtained from a patient with Idiopathic Pulmonary Fibrosis (IPF). Sections of 10 μm fresh frozen samples were cut from the blocks onto Visium slides (10 × Genomics) and processed according to the manufacturer’s protocol tissue sections were hematoxylin and eosin stained and finally imaged (20 ×) using a scanning microscope (EvosM700, ThermoFischer Scientific). Tissue was permeabilized and mRNAs were hybridized to the barcoded capture probes directly underneath. cDNA synthesis connects the spatial barcode and the captured mRNA. After RT and amplification by PCR, dual-indexed libraries were prepared as in the 10 × Genomics protocol and sequenced (two samples/HiSeq 6000 flow cell) with read lengths 28 bp R1, 10 bp i7 index, 10 bp i5 index, and 90 bp R2. Base calls were converted to reads with the software SpaceRanger’s implementation mkfastq (SpaceRanger v1.2.2). Multiple fastq files from the same library and strand were catenated to single files. Read2 files were subjected to two passes of contaminant trimming with cutadapt (v1.17): for the template switch oligo sequence (AAGCAGTGGTATCAACGCAGAGTACATGGG) anchored on the 5′ end and for poly(A) sequences on the 3′ end. Following trimming, read pairs were removed if the read2 was trimmed below 30 bp. Visium libraries were mapped on the human genome (10 × -provided GRCh38 reference), using STARsolo (STARsolo v2.7.6a).
This data measured the expression of 60,651 genes at 4992 spatial locations. We filtered out the spatial location not covered by tissue and the genes not expressed on all spatial locations. Finally, we performed cell-type deconvolution on 32,078 genes and 3532 spatial spots.
We used the scRNA-seq data from an IPF lung in a previous study as the reference [44]. This dataset consists of 60,651 genes and 12,070 cells. These cells have already been annotated into 39 cell types. Some of the cell types had insufficient cells to provide sufficient information to perform deconvolution. We reannotated the scRNA-seq dataset with 44 cell types in total and selected major cell types with a sufficient number of cells. Therefore, we only considered 11,227 cells from 26 major cell types, and we further filtered out the genes not expressed on these cells. Finally, a final set of 35,483 genes and 11,227 cells serves as the reference scRNA-seq data for deconvolution.
We choose the top 2000 highly variable genes and a set of manually selected 2534 marker genes, corresponding to 3101 unique genes for the CVAE component in SDePER. The number of cells per pseudo-spot is set to be 2–10 cells as provided by expert advice; 1788 cell-type marker genes are used in GLRM component. The hyperparameter \(_\) is chosen to be 0.72 and \(_\) to be 13.895. The running time of SDePER is 8.58 h in total using a 64-core, 100 GB RAM, Intel Xeon 2.6 GHz CPU machine.
留言 (0)