
記住我
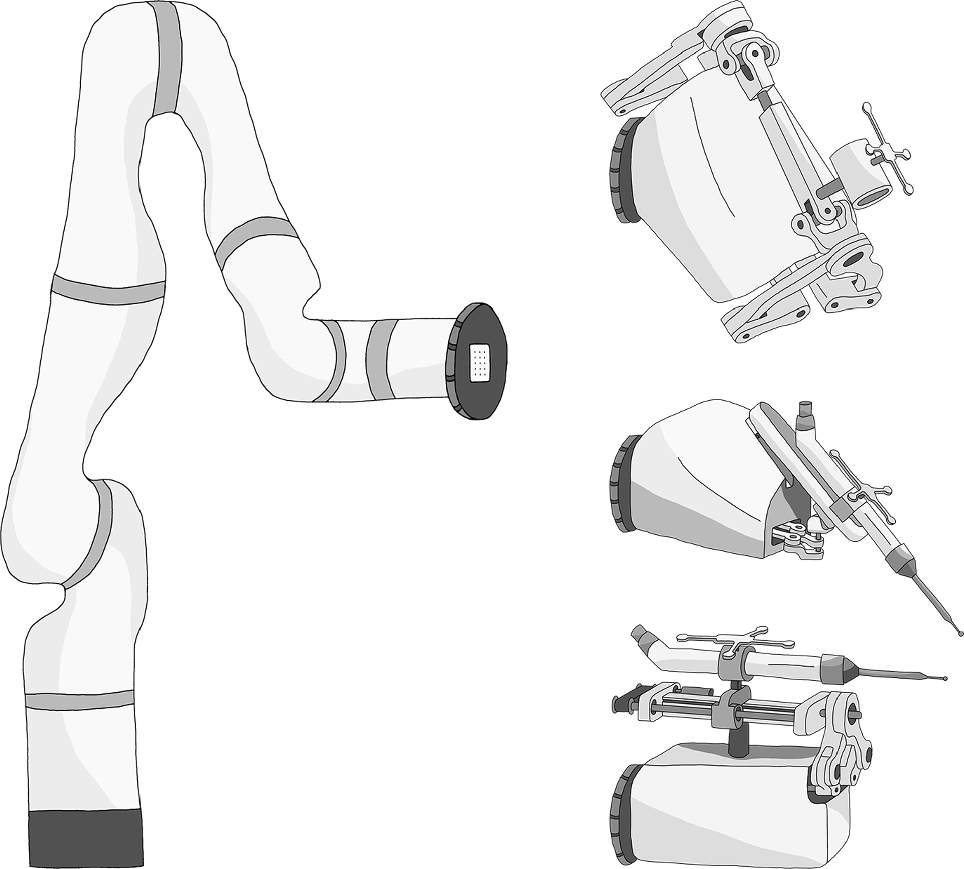







The proposed method primarily comprises (i) an optimized search behavior generation algorithm and (ii) an optimized path generation algorithm (Fig. 2). Here, the optimized search behavior generation algorithm (i) takes as input the detection confidence C of the heart component detected in the US image obtained by the echocardiographic robot and the position (X, Y) of the probe when obtaining the US image. This algorithm outputs the next position to be searched by the probe using DQN. The optimized path generation algorithm (ii) uses the information on the next location to be searched by the robot calculated by algorithm (i) as input and generates a path that enables the robot to search in the shortest possible time by processing, e.g., by avoiding previously searched locations. These algorithms are designed to find the optimal solution quickly in the presence of local solutions, which were described in the previous section. These algorithms are described in detail in the next section. Note that the probe position and angle were adjusted using a probe scanning unit (PSU) consisting of a serial link mechanism with three degrees of freedom for rotation (roll, pitch, and yaw) and a linear motion mechanism with three degrees of freedom for translation (X, Y, and Z) (Fig. 3a). The positional relationship between the PSU and the patient is shown in Fig. 3b. Also, since the PSU is equipped with a function that adjusts the Z-axis position according to the unevenness of the body surface so that the probe can always be pressed against the body surface, the proposed method in this paper aims to derive the X and Y coordinates of the probe that can illustrate the heart component based on the assumption that this function is installed.
Fig. 2
Overview of optimized robotic navigation system for heart components
Fig. 3
Degrees of freedom of the unit/positioning with the patient. a Degrees of freedom of the PSU. b Positioning of the PSU and the patient
Optimized robotic navigation system for heart componentsOptimized search behavior generation algorithmThe optimized search behavior generation algorithm uses DQN to search for heart components at time costs that are similar to those of physicians. This method also avoids local solutions using an epsilon greedy algorithm and experience replay [9] in learning DQN and by devising reward conditions. The structure of the DQN model, agent, environment, behavior, state, and reward conditions to solve the heart component search behavior optimization problem using deep reinforcement learning are described as follows.
(A)Structure of the DQN model: The number of nodes in the hidden layer of the DQN model used in this method is 100. The number of hidden layers, D, on the other hand, is a variable and is determined by experimentation, as described in the next section.
(B)Agent: The agent is the tip position of the probe moved by the echocardiography robot. The coordinate system, as shown in Fig. 4a, is set with the xiphoid process of the human body as the origin, the vertical axis as the X-axis, and the forehead axis as the Y-axis. Note that the probe angle was fixed at 0° for roll, pitch, and yaw, respectively.
(C)Environment: The environment in which the probe tip position (i.e., the agent) can act is the X–Y grid world on the chest plane, as shown in Fig. 4a.
(D)Behavior: The behavior that can be performed on the grid world of the probe tip position as the agent includes nine types of movements in eight directions (up, down, left, right, and diagonal) and stops.
(E)State: The state in which the probe tip position as the agent is observable on the grid world (Fig. 4b) is defined as the XYC state space comprising the probe positions X and Y (grid numbers) and the object detection confidence C of the heart component in the US image acquired by the probe at each position. The object detection confidence C of the heart component in each grid is calculated through the following steps: (i) during the search process, the object detection confidence of the heart component is calculated for each ultrasound image acquired in the grid using the object detection model Yolo v8. (ii) The median value of the object detection confidences of the heart component calculated in (i) is selected as the object detection confidence C of the heart component in the grid. The initial position of the probe is assumed to start at (Xs, Ys) in the grid map. This Xs, Ys is a variable and is determined by experimentation as described in the next section.
F)Reward conditions: The reward conditions are defined as shown in Table 1. The reward conditions can be divided into two categories, i.e., (i) a condition to reduce the search time and (ii) a condition to avoid local solutions. The first three items in Table 1 belong to (i) and the last four items in Table 1 belong to (ii). The following is a detailed description of the two distinctive items in this section that address the issues in this paper.
Fig. 4
DQN learning conditions: a grid world on the chest plane, b XYC state space, and c five-way traveling scan path
Table 1 DQN reward conditionsFirst, let Cb be the heart component confidence score at the point before the move for a single move and Ca be the heart component confidence score at the point after the move for a single move, then the calculated change in heart component confidence score when the move is made, Δ, is calculated by Eq. 1.
$$ \beginc} - C_ } \\ \end $$
(1)
Here, 10.0•Δ points are added or subtracted for each Δ change in the heart component confidence C per move to encourage movement in the direction of increasing C.
Next, when the probe stops a nonoptimal solution, the points Pld shown in Eq. 2 are deducted from the reward. Note that mL is the variable, Cm is the confidence score of heart components at the optimal solution, and Cp is the confidence score of heart components at the stopping position.
$$ \beginc} = m_ \left( - C_ } \right)} \\ \end $$
(2)
These reward conditions allow the system to move when the total reward can be expected to increase by moving further in a certain state, i.e., when the current position is a nonoptimal solution, and to suppress the stopping behavior at nonoptimal solution positions, including local solutions.
D, mL, Xs, and Ys are variables and are determined by experimentation as described in the next section. The advantages and disadvantages of increasing values of D, mL are shown in Table 2. It is believed that the D, mL appropriate for the complexity of the present task and the characteristics of the local solution will be determined experimentally. As for the initial position of the probe Xs, Ys, it is considered that the position where the heart component is most likely to be located relative to the body’s xiphoid process, which is the origin of the grid map, will be determined experimentally.
Table 2 The advantages and disadvantages of increasing values of D, mLOptimized path generation algorithmPath generation using only the information on the optimal action calculated by the optimized search behavior generation algorithm has the following problems: (i) it repeatedly searches for a position once passed, which results in an infinite number of moves without selecting a stopping action; (ii) it stops at a grid with zero mitral valve confidence; and (iii) if an optimal solution is found during the search, it is impossible to return to the optimal solution position. Thus, the optimized path generation algorithm is designed to solve the above issues using information on the DQN’s action value vector as the main axis of the algorithm. The optimized path generation algorithm is implemented as explained in Fig. 5.
Fig. 5
Flowchart of optimized path generation algorithm
In (A) of Fig. 5, when the probe comes to the same position two or more times, it chooses the best action among those other than the search action already chosen at that position. This avoids problem (i). In (B) of Fig. 5, when the selected search action is a stop action and the confidence C of the heart component at the current probe position is 0, the probe returns to the probe position where the confidence C of the heart component on the trajectory searched to this point is the maximum and begin again from this position. This avoids problem (ii). In (C) of Fig. 5, when the selected search action is a stop action, the search is terminated, and the position with the highest heart component confidence C on the trajectory searched so far is estimated as the position where the heart component can be obtained most clearly. This avoids problem (iii).
留言 (0)