
記住我




Parkinson’s disease (PD) is a degenerative neurological sickness that disturbs a large number of individuals (1). Freezing of gait (FoG) and the subsequent increased risk of falls are the primary disabling issues for a noteworthy figure of individuals with PD (2). There are presently few options for pharmacological therapies. Several tools and wearable devices that make available treatments, like rhythmical cueing and step-synchronized vibratory cueing, demonstrate good concert and results (3). Efficient treatment of FoG is now being investigated via examination on FoG recognition and prediction.
FoG is a sporadic walking problem characterized by sudden interruptions in stride or a significant decrease in forward movement of the feet (4). It greatly impacts quality of life and increases the likelihood of reductions and breakages in individuals with PD (2, 5). These symptoms may disrupt patients’ everyday activities, jeopardize their mental well-being, and lead to a weakening in their superiority of life. Approximately half of individuals with PD have encountered signs of FoG, which is the primary factor leading to falls (6–8). FoG is characterized as a temporary and intermittent inability or noteworthy reduction in the advancing motion of the feet, even when there is a desire to walk. In their study, Schaafsma et al. (9) categorized FoG into five distinct subtypes: start hesitation, turn hesitation, hesitation in confined spaces, hesitation toward a specific goal, and hesitation in wide spaces. Typically, FoG is linked to a particular sensation of “the feet being adhered to the ground” (10). FoG is influenced by surroundings, drugs, and anxiety, which might impact its frequency and duration (11). FoG is often considered to be a characteristic of akinesia, which is a severe type of bradykinesia (12). FoG is characterized by transient periods of immobility or the execution of very small steps while attempting to begin walking or change direction (2). The state of FoG is significantly influenced by ambient cues, cognitive input, medicines, and anxiety (11, 13). It is more common to experience it at home rather than in a clinical environment, particularly in scenarios when there is full darkness or when there is a higher cognitive load, such as dual-tasking conditions (14–17). Figure 1 displays FoG sporadic walking.
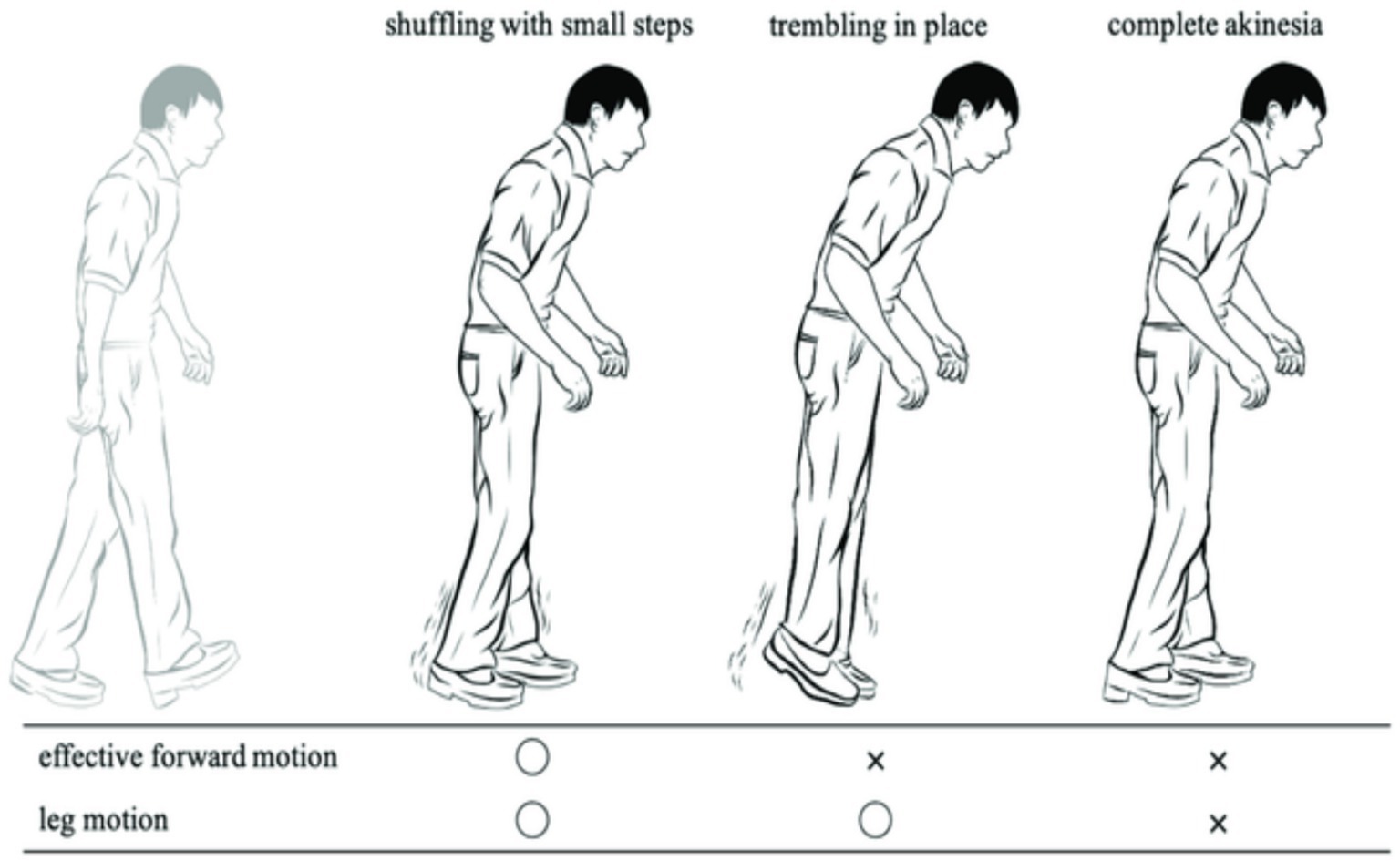
Figure 1. FoG sporadic walking.
FoG is a very debilitating condition often seen in individuals with PD. The symptoms often manifest in the later stages of the illness, with roughly 50% of all PD patients experiencing some indications and around 80% being significantly impacted (10, 18–20). Episodes of FoG often present as a sudden and temporary inability to initiate movement, often occurring while starting to walk, during making turns, or under stressful circumstances. During bouts of FoG, individuals with PD experience a phenomenon where they perceive their feet to be firmly stuck to the ground without any apparent cause (9). During episodes of FoG while walking, patients exhibit variations in their walking pattern and experience a significant decrease in the length of their steps. Additionally, they often display shaking in their legs (19, 20). The typical frequency range for normal gait steps, as measured by ankle sensors, is 0.5 to 3 Hz. However, FoG occurrences have a higher rate variety of 6 to 8 Hz (21–23).
Recent research has begun using machine leaning and deep learning for the resolution of automated categorization. Deep learning is a branch of artificial intelligence (AI) that utilizes algorithms having capability of mechanically extracting distinguishing features from information and data, such as signals acquired straight from sensors without any prior processing. Deep learning (DL) and machine learning (ML) have facilitated the creation of classifiers that cover the entire process and have demonstrated exceptional performance in various fields, including image processing, computer vision, medical information analysis, bioinformatics, natural language processing, logical reasoning, robotics, and control (24–27). Therefore, DL techniques have been used in human activity recognition (HAR) systems utilizing data collected from various light sensors (28, 29).
DL and ML methods have become more popular for detecting FoG in recent years, as seen by the employment of these techniques in several studies (30–34).The following are the most significant and noteworthy. Kim et al. (30) and Pepa et al. (32) introduced a novel sensing tool, namely a smartphone positioned in the pant pocket, as a more convenient method for monitoring patients with PD and detecting FoG. The researchers used a technique that relied on convolutional neural networks (CNN) to automatically extract distinctive characteristics from sensors integrated into an Android smartphone. The performance of the CNN classifier was compared to that of the random forest (RF) classifier, and the CNN classifier exhibited a sensitivity that was 20% greater than that of the RF classifier.
Approximately 7 to 10 million individuals worldwide are affected by PD, with a significant portion experiencing FoG. During an episode of FoG, a patient experiences a phenomenon where their feet get immobilized, making it impossible for them to go forward despite their efforts. FoG significantly impairs health-related quality of life, leading to depression, heightened fall risk, greater reliance on wheelchairs, and limited autonomy.
This study used a standardized dataset obtained from 65 participants, using a 3D accelerometer. The dataset has been categorized into four classes: Normal, Turn, Walking, and StartHesitation. Preprocessing methods were suggested to cleanse the dataset and address the issue of imbalanced classes. The output from the preprocessing approach was analyzed using several ML, deep learning and transformers modes to determine if the patients are experiencing FoG or are in a normal state. The primary contribution of this work is as follows:
1The initial system employed for the classification of FoG used a new dataset.
2In our research, we have categorized the dataset into four distinct classes namely Normal, Turn, Walking, and StartHesitation because the dataset did not have labels.
3Employed various of ML, deep learning, and transformer approaches to predict the occurrence of FoG in patients with PD, the system achieved 91% with respect to accuracy.
2 Background of the studyFoG is an indication often seen in people with PD. However, the fundamental mechanisms of FoG are not well understood. Patients with PD often report this symptom as a sensation of their feet being firmly adhered to the ground (34–37). Handojoseno et al. (38) utilized the wavelet factors of electroencephalogram (EEG) data as the input for the multilayer perceptron neural network and KNN technique. This method achieved a sensitivity of 87% and an accuracy of 73% in predicting the transition from walking to FoG. Delval et al. (39) used a multi-camera setup to capture the gait kinematics gestures of patients. Deep pointers were affixed to the patients’ bodies and recorded from various angles. Okuno et al. (40) utilized a plantar pressure measurement system of 1.92 m × 0.88 m for recording the walking patterns of patients by monitoring the weight exerted on their soles. While the sensors may all be used for FoG detection, the predominant method for FoG detection in community environments relies on inertial sensors.
Moore et al. (21) developed a portable monitoring apparatus and algorithm that used the occurrence features of vertical leg movement. This movement was measured using an accelerometer put on the left shank of 11 individuals with PD. The contributors’ ages ranged from 45 to 72 years. The contributors were trained to go through a series of interior passages, including a tight entryway, and three obstacles. This research took into account the specific effects of the levodopa/carbidopa drug combination throughout both the “on” and “off” periods. The researchers used a threshold-based method to identify FoG, achieving a FoG detection rate of 78% and an accuracy rate of 89%. Delval et al. (39) conducted research in which they induced FoG in patients and used a series of measurable indicators to identify the presence of FoG. They used a 3D motion-analysis device to capture video footage of 10 sick and 10 healthy people while they were on a treadmill. Indicators were affixed to the heels, toes, ankles, shoulders, and on the T10 vertebra. Obstacles were encountered due to special situations, causing the patients to be in an inactive state. The identification of FoG in that particular investigation relied on a combination of threshold and frequency investigation. Bachlin et al. (41) devised a FoG recognition architecture using three accelerometers and implementing Moore’s threshold-based algorithm (21). Upon detecting an episode of FoG, the device used a metronome to offer stimulation to the patient, aiding them in regaining their focus and stability. The system support resulted in improved gait for six out of eight individuals who had FoG. Azevedo et al. (41) Developed a FoG detector that included gait pattern analysis by using a solitary inertial sensor positioned on the lower extremity. Based on its findings, it determines that relying just on frequency-based analysis is insufficient for accurately identifying the occurrence of FoG. It is essential to not only detect but also forecast when a FoG event will take place. The authors used rhythm and tread data into their methodology to enhance the categorization process. In order to assess the walking patterns of individuals with PD, Jovicic et al. (42) developed a technique that utilizes inertial sensors placed on both lower legs to categorize different gait patterns. The system also distinguished between regular and pathological gait by utilizing an expert rule-based approach, based on data collected from 12 PD patients who walked over a convoluted course. A rule-based categorization approach was used for the identification and categorization of FoG. Pham et al. (43) introduced a FoG detection method that is not reliant on specific individuals. The uniqueness of this idea is in its ability to operate autonomously from the topic matter. An additional instance of a FoG recognition system that uses wearable accelerometers and video capture to categorize the occurrence is shown in the research conducted by Zach et al. (44). Their finding suggests that FoG may be detected with just one accelerometer placed in the lumbar area.
Pepa et al. (32) used soft computing approaches for FOG identification. A fuzzy method was created to integrate information pertaining to freeze index, energy, cadency fluctuation, and the derivative energy ratio. A building was constructed that relied on a smartphone as its foundation. Their findings demonstrated that, on average, the system exhibited a specificity of 92.33% and recall of 83.33% in classifying FoG events. Cole et al. (36) presented a method using dynamic neural networks (DNN) to accurately identify FoG. They gathered information from three accelerometers and an electromyographic shallow worn by patients and achieved favorable consequences in terms of detection. A noteworthy involvement of this study is the creation of a database documenting unscripted and unimpeded everyday activities of PD patients, including instances of FoG. Ahlrichs et al. (22) introduced a FoG detector that utilizes a single accelerometer worn at the waist and a recognizer based on SVM. They documented the performance of 20 people with PD engaging in pre-planned everyday tasks. Patients were required to be documented both when taking medicine and while not taking medication. Their findings demonstrated a precision rate of 98.7%.
Rodrıguez-Martın et al. (45) developed a ML method designed to identify episodes of FoG. Their preference for FoG detection was SVM. Their technique relies on a solitary 3D accelerometer positioned at the waist to identify FoG in real-world scenarios. A total of 21 individuals diagnosed with PD contributed in the research work. The patients were asked to execute two sets of pre-determined exercises during both their “off” and “on” times. These activities were associated with everyday existence. According to their research, the medicine had an impact on the patients’ motor reaction. Deep learning methods have been popular for detecting FoG in recent years, as seen by their frequent application in research (30, 34, 46–48). Kim et al. (30) used a novel sensing device, namely a smartphone positioned in the trouser pocket, to discover a more pragmatic approach for monitoring patients with PD and identifying FoG. The researchers used a technique that relied on CNN to automatically extract distinctive characteristics from sensors integrated into an Android smartphone. The performance of the CNN method was compared to that of the RF technique, and the CNN exhibited a sensitivity that was 20% better that of the RF classifier. Xia et al. (49) suggested a FoG detection method based on CNN to accomplish automated feature learning and classification for FoG. Bachlin et al. (41) conducted experiments that relied on the patient’s input and studies that did not need the patient’s involvement. The most favorable outcomes were documented in the patient-dependent experiments. Same researchers used DL to predict FoG and PD (50–53).
3 Materials and methodsThe proposed system aims to identify FoG, a distressing symptom that affects many individuals with PD. The proposed solution is built upon a machine learning models that have been trained using data obtained from a wearable 3D sensor device positioned on the lower end. Figure 2 displays the framework of the FoG system based on a machine learning approach.
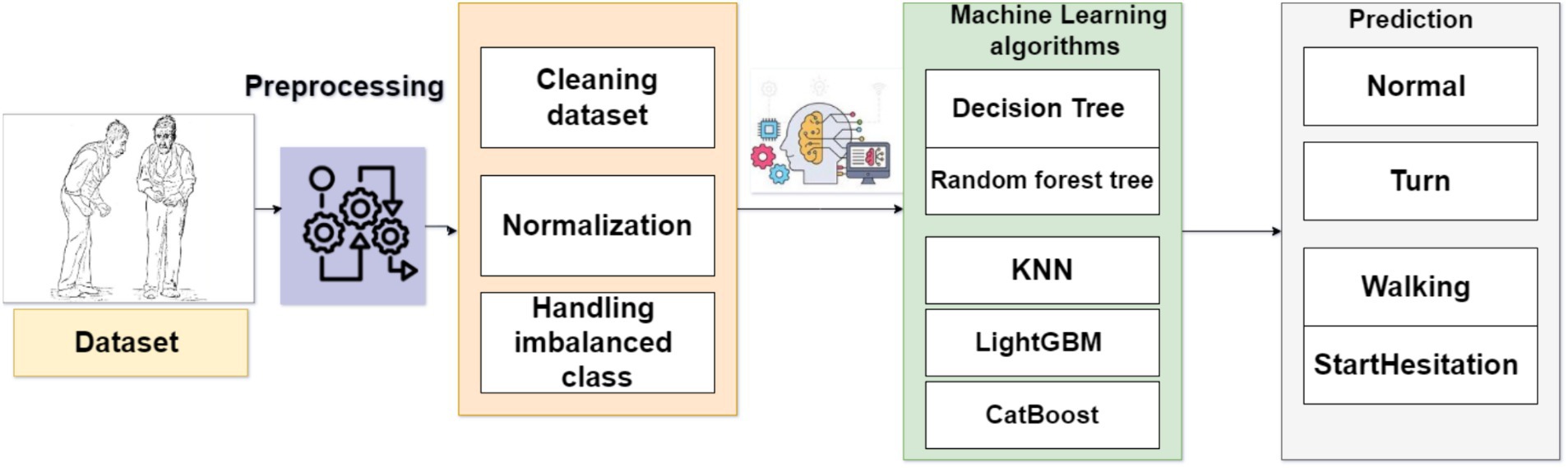
Figure 2. Framework of the system to predict FoG.
3.1 DatasetThe dataset was obtained from the Kaggle repository and consists of 3D accelerometer data from the lower back of individuals experiencing bouts of FoG, a debilitating condition often seen in individuals with PD. FoG has a detrimental effect on the ability to walk, hindering movement and independence. The goal is to identify the initiation and termination of each freezing episode, as well as the presence of three specific kinds of FoG events: start hesitation, turning, and walking. The data series consists of three unique datasets, each obtained under separate circumstances: (1) The tDCS FoG (tdcsfog) dataset consists of data series obtained in a laboratory setting, where individuals underwent a FoG-provoking procedure; (2) The DeFOG dataset consists of data series that were obtained in the subject’s home as they conducted a FoG-provoking regimen; and (3) The daily living dataset consists of 1 week of uninterrupted 24/7 recordings from 65 people. Out of the total number of participants, 45 display symptoms of FoG and also have series in the DeFOG dataset. In contrast, the other 20 patients do not show any symptoms of FoG and do not have series in any other part of the data. Table 1 displays meta data, whereas the training dataset is presented in Table 2.

Table 1. Metadata of dcsfog and tdcsfog.

Table 2. features of dataset.
3.2 Preprocessing approachData features engineering require the creation of new features or the transformation of existing features to enhance the effectiveness of a machine-learning model. Data preprocessing entails the extraction of pertinent information from unprocessed data and converting it into a format that is readily comprehensible by a model. The objective is to enhance the precision of the model by providing more significant and relevant data. The missing values in the dataset were removed from all features. We have combined DeFOG features, namely Time, AccV, AccML, and AccA, with the DeFOG-metadata for Subject, Visit, and Medication Condition. Figure 3 shows the preprocessing steps for the classification of FoG of PD patients.
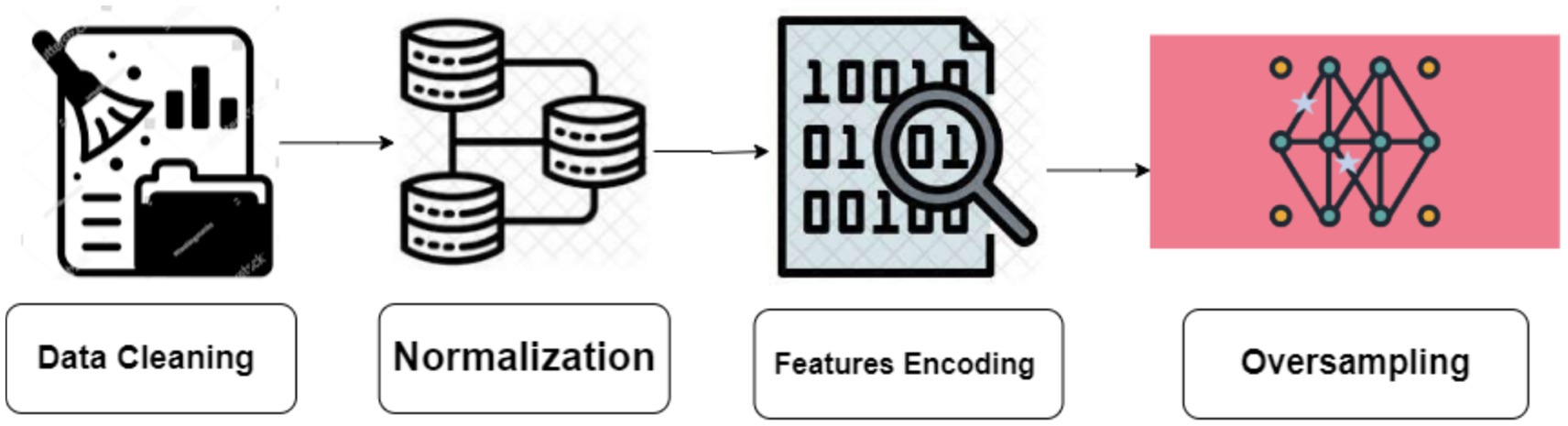
Figure 3. Preprocessing steps.
3.2.1 NormalizationNormalization is an essential preprocessing step for any machine-learning task. The process can be executed by either scaling or altering the initial data in order to equalize the influences of various characteristics in the data examples. In the present research work, we have standardized the input data to generate a representation among one and zero.
xnormalize=x−xminxmax−xmin (1)Where the x is training data, and xmin is maximum value [1] and xminis minimum value [0].
3.2.2 Handling imbalance classesUnbalanced data raises to a condition where the representation of observations and samples among dissimilar classes is unequal, with one class dominating the dataset and the other classes having insufficient representation.
The synthetic minority oversampling strategy (SMOTE) is a resampling strategy used to address extremely imbalanced datasets by creating synthetic samples in the minority class, hence increasing its representation. SMOTE is effective in increasing the figure of minority class examples and achieving class balance. To mitigate the problem of overfitting, the synthetic production of fresh samples deviated from the increase procedure.
The primary concept behindhand SMOTE technique is to create additional data samples in the minority class using interpolation between neighboring examples within this class (54). SMOTE enhances the amount of instances belonging to the minority class in an unbalanced dataset, thus improving the classifier’s ability to generalize well. Figure 4 shows the SMOTE method in practice.
Dnew=Di+D̂j−Dixδ (2)The dataset Dnew represents the ADHD dataset. Di consists of samples from the minority group, whereas D̂j is a k-nearest neighbor of Di . Let δ represent a uniformly distributed random number between 0 and 1. We used the SMOTE technique to enhance the categorizing process.
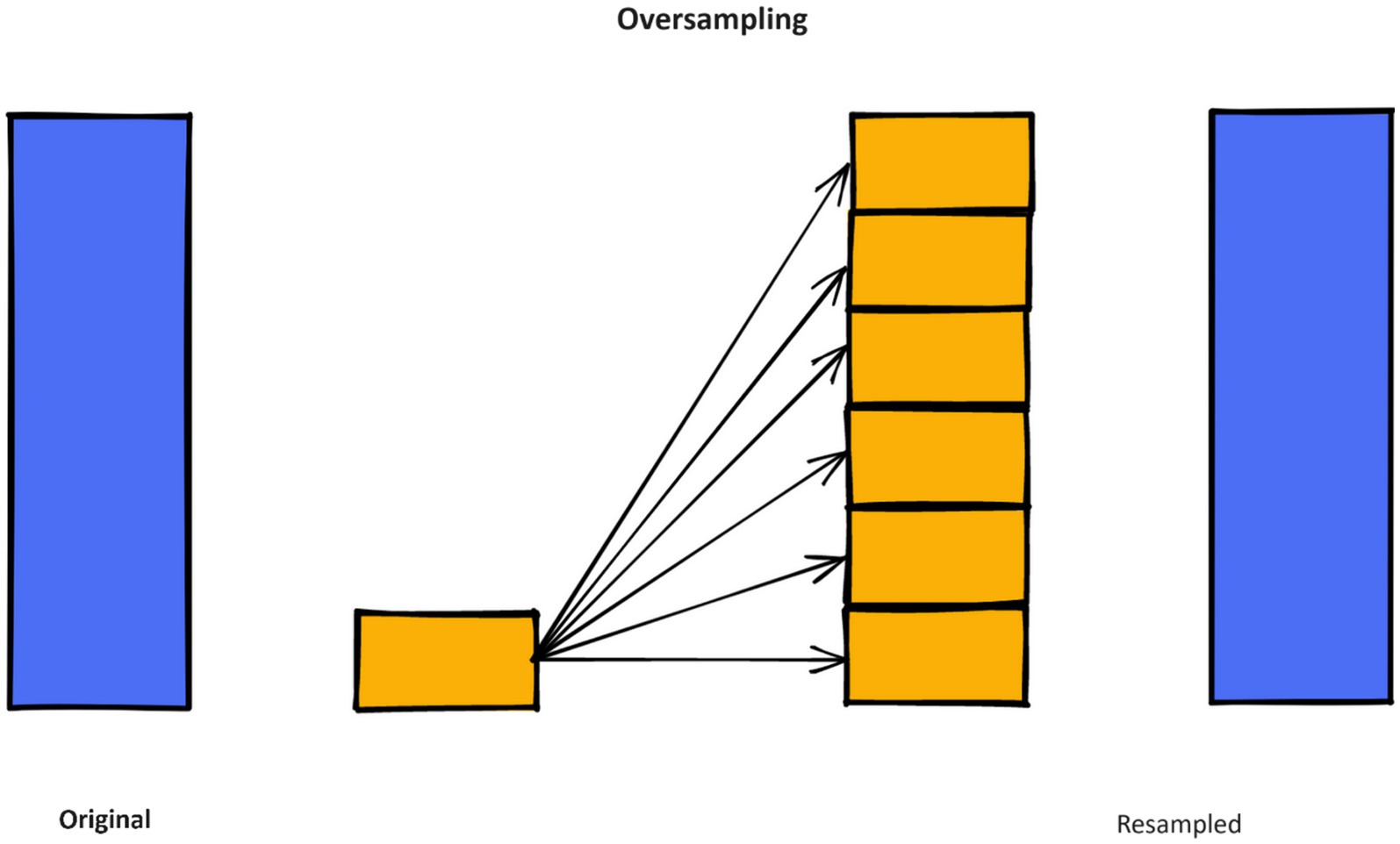
Figure 4. Working of SMOTE method.
Figure 5 and Table 3 show the dataset before and after class distribution of the dataset using the SMOTE approach in the training dataset. The startHesitation class has less values (352); therefore, we have applied the SMOTE approach for handing this imbalance class to enhance the machine algorithms.
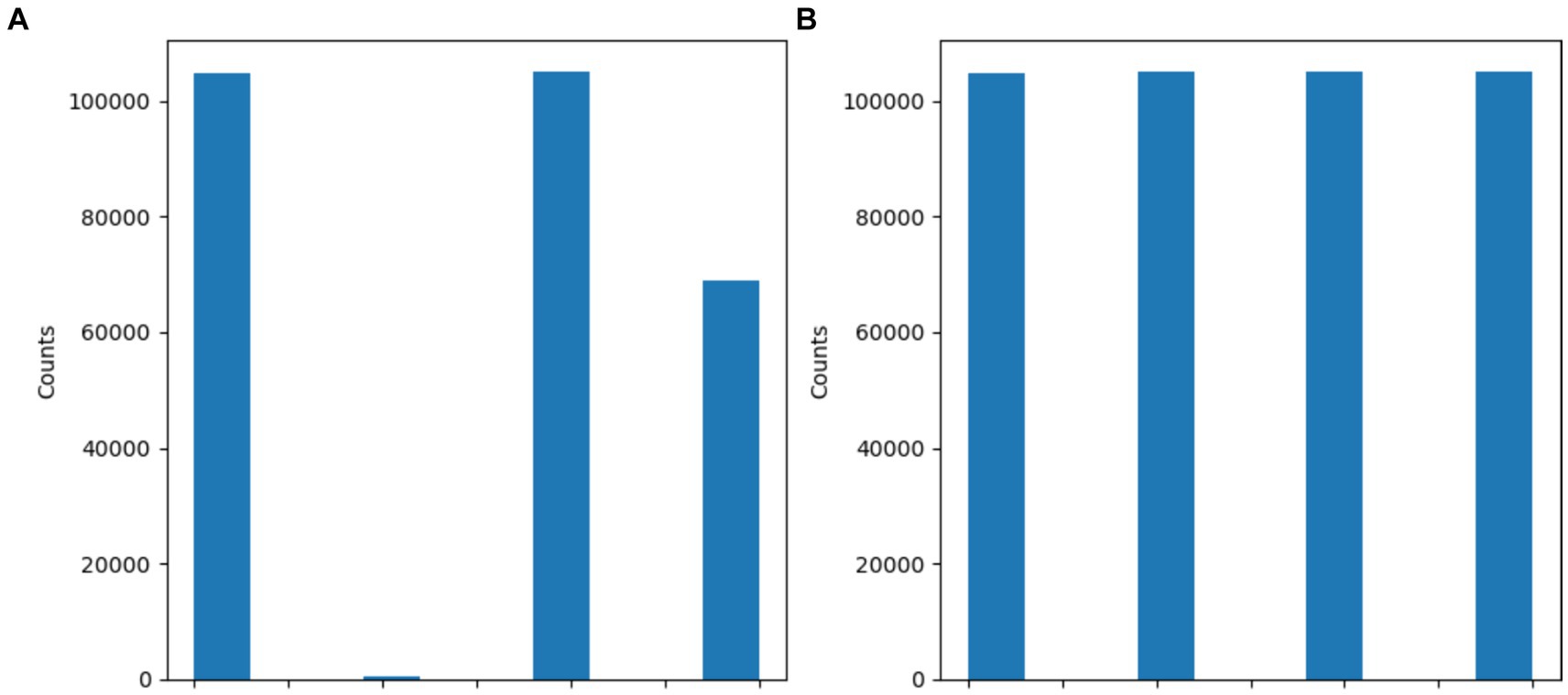
Figure 5. Results of SMOTE approach (A) before SMOTE (B) After SMOTE.
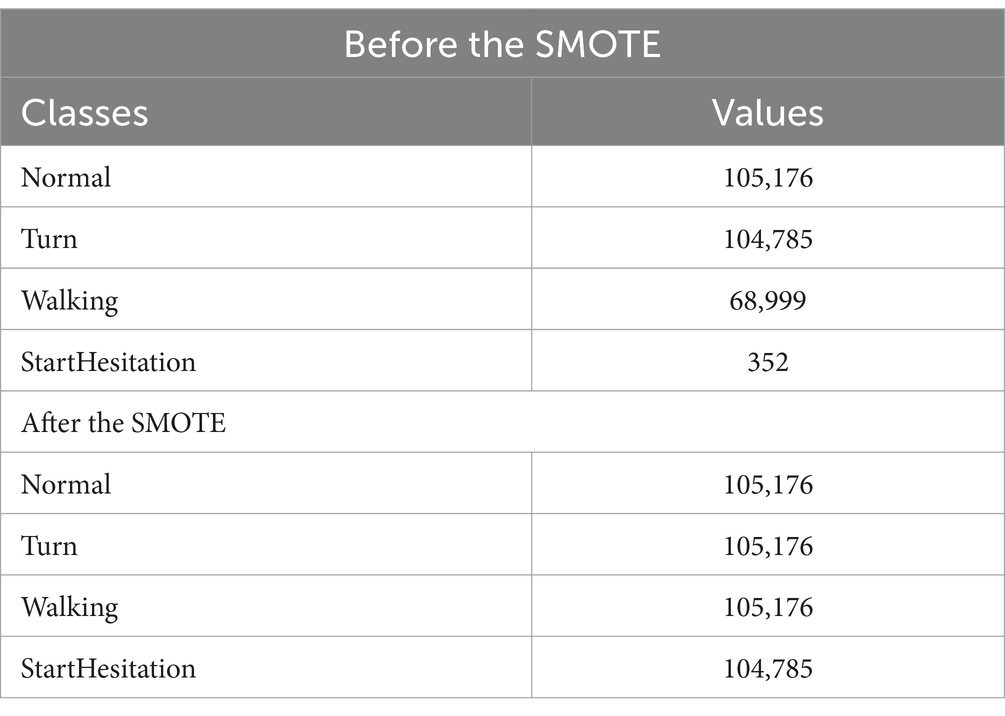
Table 3. Results of SMOTE approach.
3.3 Algorithms 3.3.1 K-nearest neighborsThe KNN technique is a straightforward nonparametric approach that\ is often utilized for the purposes of regression and classification tasks. The KNN algorithm is a kind of instance-based learner, commonly referred to as idle learning. It does not build a categorization model-based approach till it is given samples to classify. The fundamental premise of KNN in categorization is to compare individual test samples with k nearby training samples in the variable space. The category of the test sample is determined based on the classification of its nearest k neighbors. Neighbors are often determined by calculating the Euclidean distance between the data point being analyzed and its k nearest neighbors. The k parameter, denoting the quantity of nearest neighbors’ number, is often kept minimal to avoid the inclusion of excessive data points that may distort the underlying characteristics of the data point under consideration. It is important to choose acceptable values for k in order to avoid overfitting and model instability, since large values of k might contribute to both issues. KNN utilizes the Euclidean distance metric. The underlying assumption is that each element in the dataset may be shown as a point in a space with N dimensions. KNN utilizes a parameter k to denote the number of examples to be considered, based on which the majority class is selected to categorize the new instance.
Ei=x1−x2+x3−x42 (3)where x1 , x2 , x3 , and x14 calculate of the Euclidean distance in a two-dimensional space.
3.3.2 Decision treeA decision tree (DT) is a well-recognized nonparametric supervised learning technique. DT is one of the ML algorithms that can be applied for both regression and classification tasks. DT classifies the instances by traversing down the tree from the root to certain leaf nodes. Instances are categorized by evaluating the attribute specified by the node, beginning at the root node of the tree, and thereafter down the tree branch associated with the attribute value. The most often used criteria for splitting are “gini” for measuring Gini impurity and “entropy” for quantifying information gain, which may be mathematically represented.
Entropy=S=∑i=1Cpilog2pi (4) EntropyS|B=∑j=1jsiSientropySi (5) GainS|B=entropyS−entropyS|B (6)The training dataset is indicated as S, while the freezing of gait dataset is represented by the class c , which encompasses both attack and normal data. The likelihood of seeing data that belongs to class Si is represented as Pi . This probability is specifically related to the subsets of class Si in the characteristics B.
3.3.3 Random ForestA random forest (RF) classifier is a well-recognized collaborative classification technique used in machine learning and data science across several application domains. This approach employs “parallel ensembling,” whereby several DT classifiers are concurrently trained on distinct sub-samples of the dataset. The ultimate result is decided via mainstream vote or averaging of the outcomes. Therefore, it reduces the issue of over-fitting and enhances both the accuracy of predictions and control. Hence, the RF learning model, which utilizes many decision trees, often exhibits higher accuracy compared to a model based on a single decision tree. In order to construct a sequence of decision trees with regulated diversity, the method associates bootstrap combination (bagging) with arbitrary attributes selection. It is versatile for both classification and regression issues and is suitable for both categorical and continuous variables. Table 4 shows parameters of RF model.
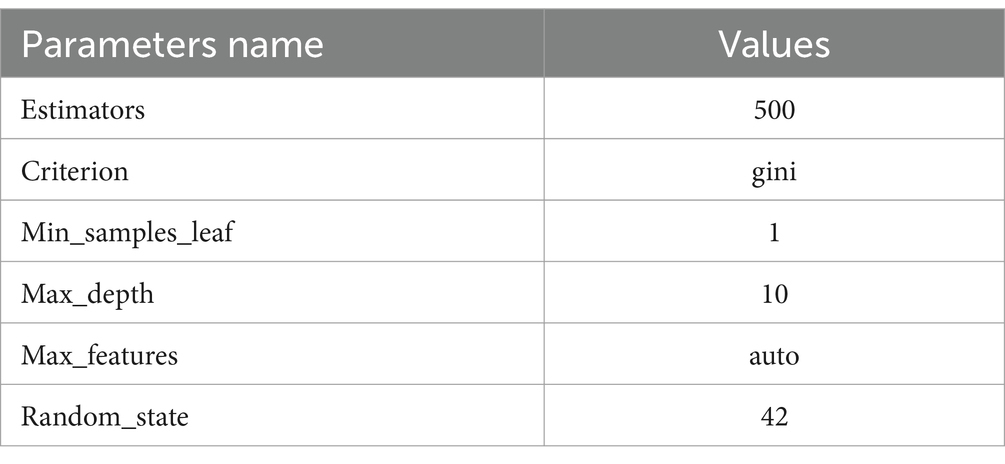
Table 4. RF parameters.
3.3.4 LightGBM approachLightGBM approach is a gradient boosting context that employs tree-based learning techniques. It is specifically engineered to be widely spread and highly effective, offering the following benefits: Enhanced training velocity and increased efficacy; Reduced memory consumption LightGBM provides support for parallel and GPU learning; Proficient at managing enormous volumes of data LightGBM is a rapid, circulated, and efficient gradient-boosting system that relies on decision tree methods. It is extensively used in a range of machine-learning tasks, including regression, ranking, and categorization (55). It is a furthering method that utilizes numerous weak machine-learning methods to create a powerful learning model. Boosting methods amplify the weights of incorrectly classified data while reducing the weightiness of successfully categorized data. Table 5 shows LightGBM parameter.
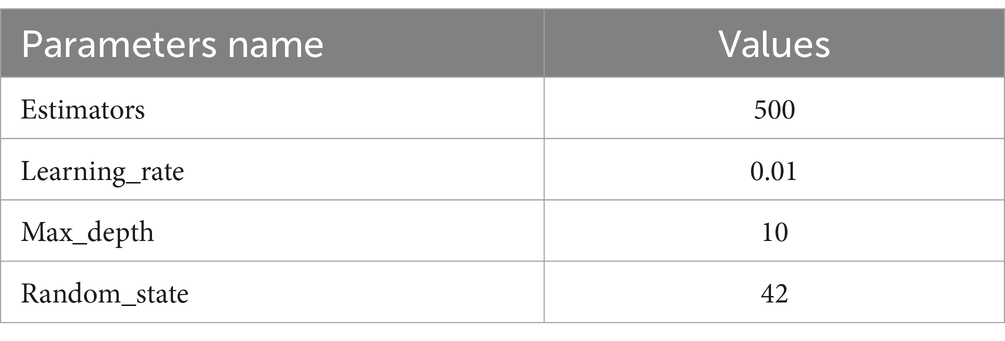
Table 5. LightGBM parameters.
3.4 Gated recurrent unit–transformers 3.4.1 Gated recurrent unitThe GRU is a fundamental architecture of recurrent neural networks (RNNs) that has resemblance to Long Short-Term Memory (LSTM) models. GRU is specifically developed to represent sequential data by enabling the selective retention or loss of information over time. Nevertheless, GRU possesses a more streamlined structure compared to LSTM, with a reduced number of parameters. This characteristic facilitates training and enhances computing efficiency.
The GRU is designed to handle sequential data by iteratively updating its hidden state in response to both the current input and the prior hidden state. During each iteration, the GRU calculates a “candidate activation vector” that integrates data from the input and the preceding hidden state. Subsequently, the candidate vector is employed to modify the concealed state for the subsequent time step. Two gates, namely the reset gate and the update gate, are used to calculate the candidate activation vector. The reset gate is responsible for determining the extent to which the previous hidden state is disregarded, whereas the update gate is responsible for determining the extent to which the candidate activation vector is integrated into the future hidden state.
μt=σVμxt+Wμot−1+bμ (7) rt=σVrxt+Wrot−1+bμ (8) it=tanhVoxt+Wort⊙ot−1+b0 (9) ot=σ(μt⊙ot−11−μt⊙it (10)Input is it , output is ot , update gate output is μt , reset gate output is rt , and Hadamard product is ⊙. Weight matrices V, W, and b are parameters. The GRU encoder and Transformer path embeds input sequences using a recurrent GRU layer. Thirty-two GRU units encoded 200-dimensional vectors each timestep. Using multi-head self-attention with two heads, GRU embeddings may attend to each other based on learnt connections. Residual connections and layer normalization stabilize training. Flattening attention outputs to 1D vectors. Structure of GRU mode is presented in Figure 6.
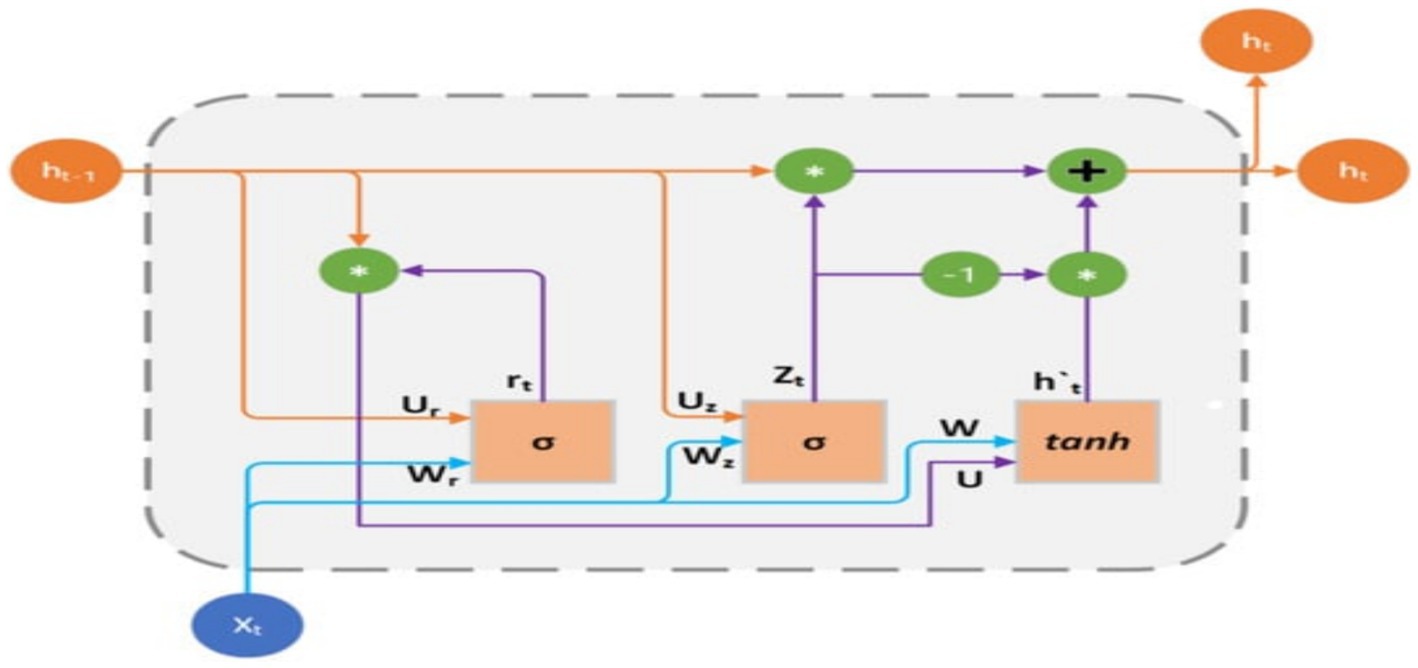
Figure 6. GRU structure.
3.4.2 TransformersThe self-attention mechanism-based sequence-to-sequence model Transformer is extensively used in natural language processing methods including machine translation, text summarization, language synthesis. Significant outcomes are achieved quickly. Transformers has a different architecture than RNN. The Transformer branch in the proposed GRU-Transformer model assumes a crucial function in capturing complex interdependencies and multidimensional characteristics present in the input sequence. The aforementioned objective is accomplished by utilizing the self-attention and multi-head attention processes of the Transformer, as seen in Figure 3. Its attention-based encoder-decoder structure enables the Transformer to effectively handle sequence-to-sequence tasks.
A=SoftmaxQKTdk (14)Where, X be the input and (K, Q, ?) is query matrix, key matrix, value matrix, learnable weight matrix is A , attention matrix is Y , output matrix is dk , and attention header dimension, the scaling factor, reduces overly large or minuscule attention weights. To determine key value weight, softmax is used as a normalizer. The attention mechanism calculates the association between each input sequence item and the others to capture global dependencies.
The unit recurrent layer is 200 unit that stores sequence data and may capture dependencies. The parameter “return_sequences” sends the sequence of outputs for each time step to the next layer instead of just the final output. This Transformer component lets the model focus on different input sequence segments during prediction. Two 200-key dimension attention heads are used in the suggested method. This implementation helps the layer capture data relationships and connections. Attention boosts and accelerates learning. The residual link, or skip connection, solves the fading gradient problem by offering an alternate gradient movement path. Each time step of the sequence receives an individual 120-unit dense layer to extract unique characteristics. This strategy stochastically assigns input units to 0 during training after the TimeDistributed layer at 0.2 to reduce overfitting.
The output of the previous layers is turned into a unified vector to link with the final Dense layer for classification. The neural network generates probabilities for each of the four classes using a Dense layer with softmax activation. Figure 7 shows the structure of GRU-transformers. Parameters of GRU-transformers is presented in Table 6.
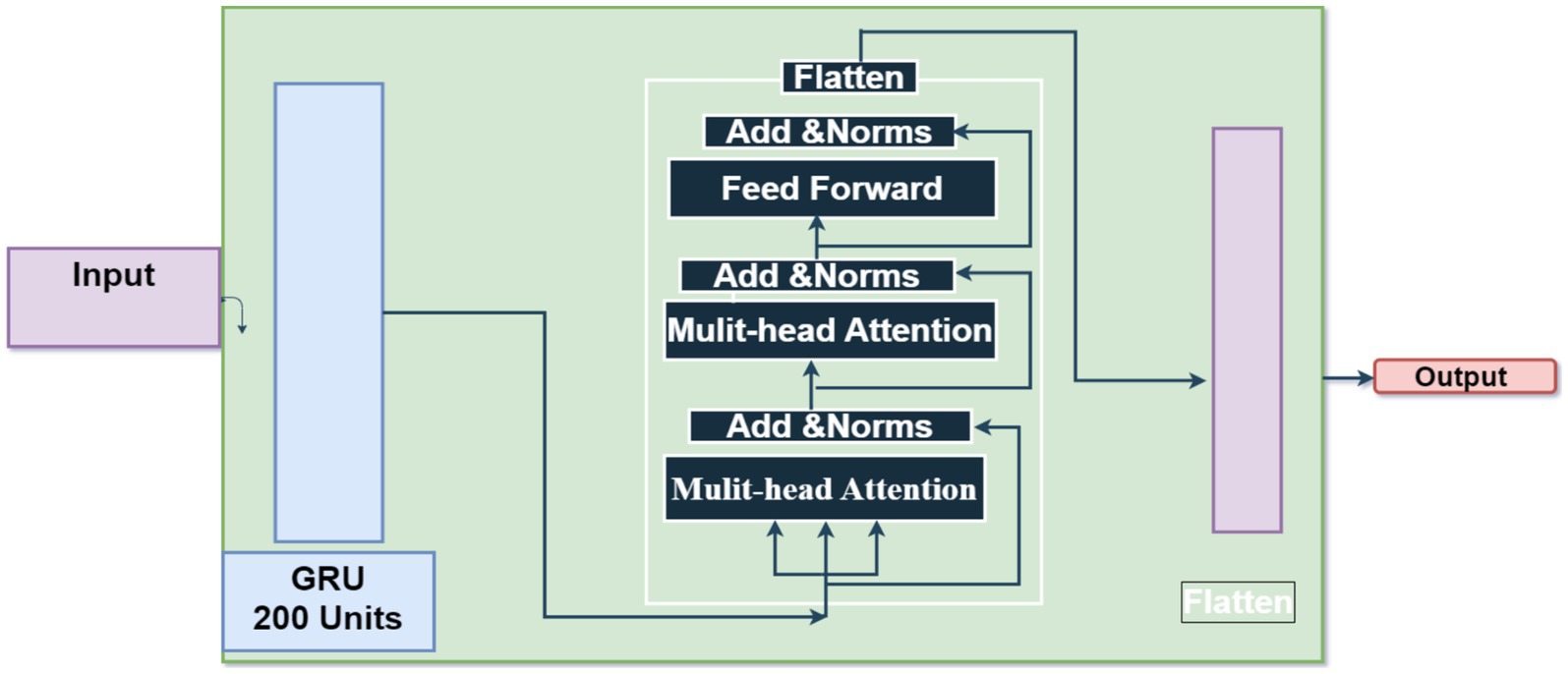
Figure 7. GRU-transformers.
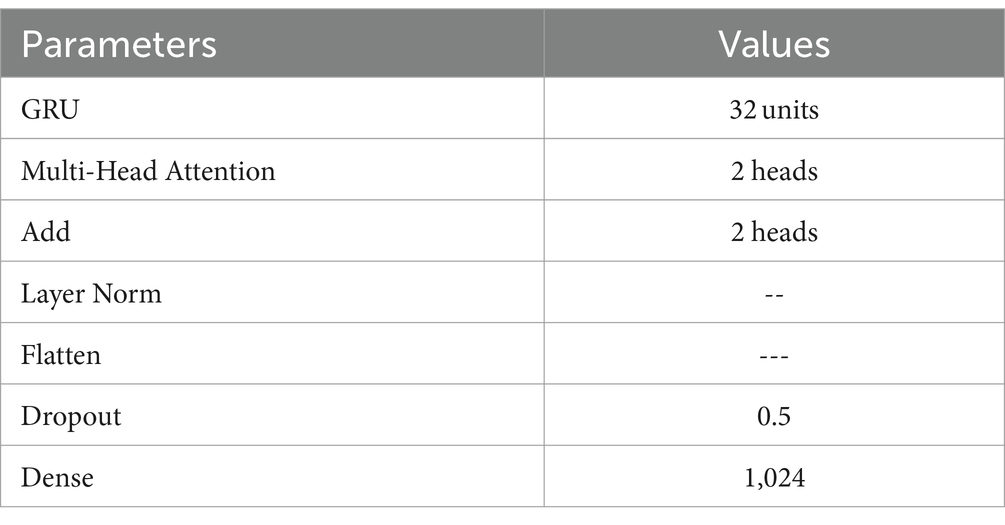
Table 6. paramters of GRU-transformers.
3.5 Long-term recurrent convolutional networksLRCN neural networks combine the strengths of the CNN and RNN to handle sequential input with spatial and temporal dependency. The model’s early layers use Convolutional Neural Networks (CNNs) to extract spatial properties from input data. These collected characteristics feed Recurrent Neural Networks (RNNs) to capture temporal relationships and long-term correlations. LRCN may acquire spatial and temporal complex data representations by integrating CNN and LSTM components. This neural network design handles sequential data well. LRCN is an RNN developed to evaluate its performance on sequence input data.
C=∑1i∑1jIijFij (16) CiL=BiL+∑j=1xL−1Fi,jL∗CjL−1 (17)Where, F represents a convolution kernel or filter, while i and j represent rows and columns of dataset. A unique two-dimensional output is obtained by convolving the input dataset.
With the kernel. BiLrepresents the bias matrix, whereas Fi,jL represents the filter connecting the jth feature map in the layer.
ft=σ(WefXt+Wefht−1+WcfCt−1Uf+) (18) it=σ(WxiXt+Whiht−1+WciCt−1+Ui (19)) Ct=σ(ftct−1+ittanh(WxcXt+Whcht−1+U (20)) ot=σWxoXt+Whoht−1+WcoCt−1+Uo, (21) ht=Ot×tanh(Ct (22
留言 (0)