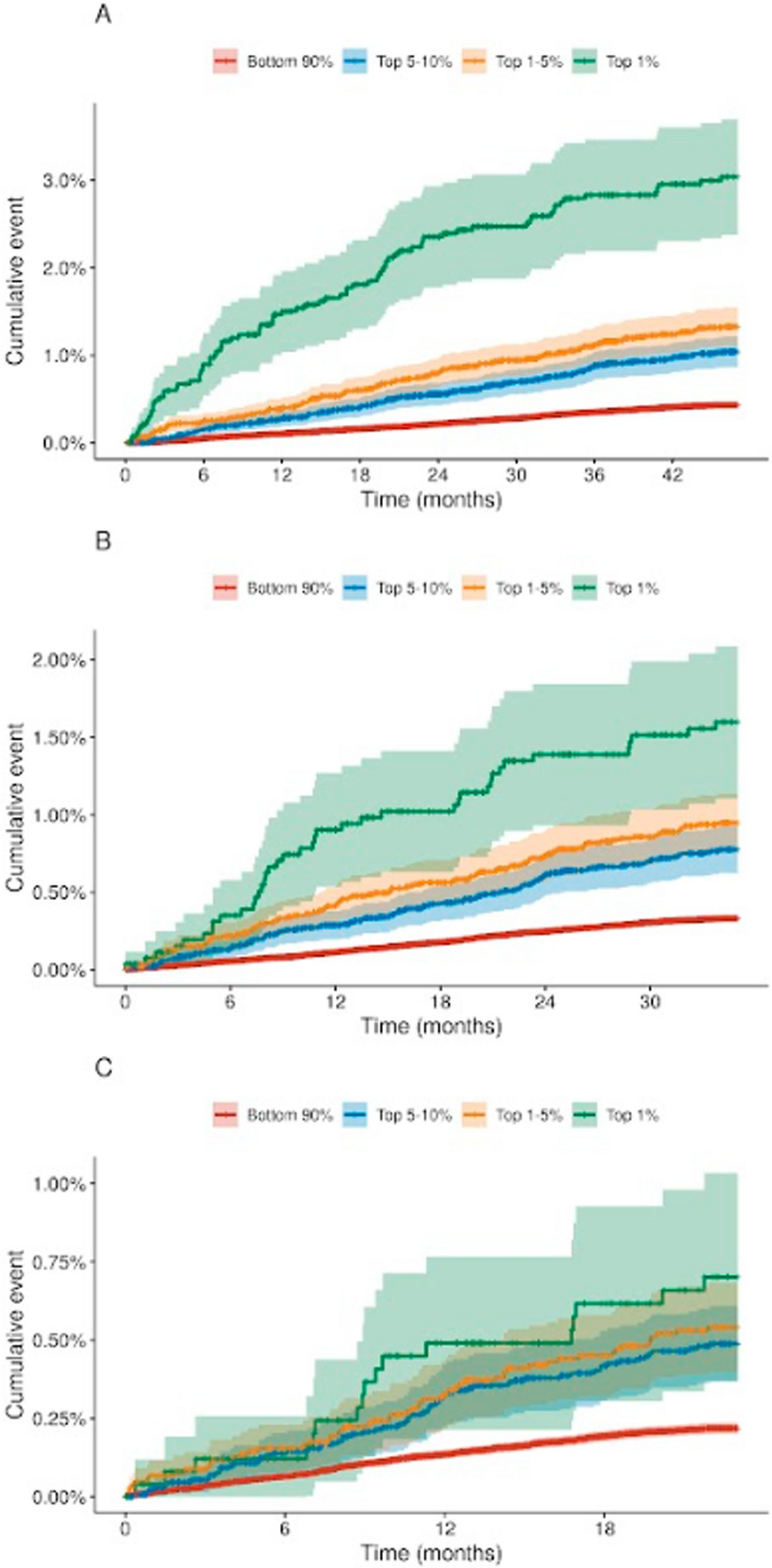
In this study, we describe the development and validation of a CRC risk prediction model based on EHR clinical and laboratory parameters. Our model, which was trained on one of the largest datasets to date, explored the predictive ability of thousands of features and utilized the data from over half a million subjects[14]. Performance was evaluated using two distinct validation cohorts: We demonstrated the model’s high discrimination ability within a cohort of subjects that have not undergone CRC screening, noting the model’s utility as a safety net for identifying high-risk individuals among those with low adherence to screening. We further demonstrated the discrimination ability of the model among subjects that underwent FOBT screening, noting the model’s ability to further assist in decisions regarding those who underwent screening. Specifically, within the cohort of subjects with a negative FOBT, the model was able to pinpoint individuals whose CRC risk was comparable to those with a positive FOBT.
Despite increases in CRC screening rates over the past decade, the absolute rate remains suboptimal [7]. The ongoing lack of compliance can be attributed to patients’ low awareness of screenings, fear of screening procedure—particularly colonoscopy, and general lack of communication with the physician [19]. Utilizing an EHR-based classification model for CRC identification could potentially improve awareness by providing physicians with a method for communicating risk to patients that need to undergo screening.
Across the entire validation cohort, in order to identify 10 CRC cases, 3,636 individuals would require a diagnostic colonoscopy. By stratifying the risk among these individuals and selecting the top 1% risk percentile, only 435 individuals would have to undergo a diagnostic colonoscopy, in order to identify the same amount of CRC cases. By screening the top 1.3% risk percentile, corresponding to 3,521 individuals, 10% of CRC cases within the validation cohort could be identified. This is markedly more efficient when compared with a non-stratified approach, which would require screening 26,881 individuals to achieve the same detection rate. A crucial consideration is that all of the patients in our cohort are already recommended for colonoscopy based on existing medical guidelines. Thus, our approach is designed to prioritize such patients without resulting in additional burden or potentially harmful practices.
Features that had the strongest impact on the model included characteristics such as age, gender and BMI. These identified features are consistent with the current literature regarding risk factors for CRC [20]. As expected, lab values characteristic of iron deficiency and anemia had a strong impact on the model. In addition to these, less obvious lab values—such as a decrease in ALT and aspartate transaminase (AST) values and higher glucose, alkaline phosphatase (ALKP) and triglyceride levels were also shown to increase the risk for CRC according to the model. Interestingly, while these associations are less commonly known, they have all been described in the medical literature [21,22,23].
Our model stands out because it was specifically designed to enhance existing screening approaches. Unlike many models developed over the past decade, which often relied on cohorts with varied indications or required data not commonly found in EHRs, our model was developed using a cohort of at-risk individuals eligible for screening colonoscopy. By focusing on this particular demographic, we believe our model offers enhanced accuracy and generalizability in real-world clinical settings, making it a valuable complement to existing screening strategies. Furthermore, CHS covers more than 50% of the Israeli population and therefore includes subjects from various ethnic backgrounds, providing a representative nation-wide cohort. It is therefore less likely that ethnic biases and healthcare inequalities would have a significant effect on model development [24].
A major strength of our model is the utilization of longitudinal follow-up data. Various features corresponding to the trajectory of laboratory value changes over time (e.g. slope and velocity), were selected by the model as impactful. Such features better reflect the evolving nature of the disease and the patient’s health status compared to a single measurement in time. While a single data point could provide a snapshot of a patient’s condition, it is incapable of capturing the inherent variability and changes over time, which are critical to understanding disease progression and risk prediction. A longitudinal follow-up approach, on the other hand, allows us to identify how such changes in certain lab values correspond to the onset or progression of CRC. In our study, we analyzed the interaction between the last recorded values and the slope of selected lab features. We showed that while both the last value and the slope contribute to the predictive capabilities of the model, for some features such as MCV and MCH, the interaction between the two uncovers discriminatory signals that would otherwise be missed.
This study has several potential limitations. First, a follow-up period of 48 months may not be sufficient for the purpose of CRC risk assessment, especially for slower-progressing forms of the disease which might have been present at the index date but were not identified throughout the follow-up period. Therefore our model’s long-term accuracy beyond this period remains uncertain, and longer follow-up times are necessary to better assess its predictive capability over time. Furthermore, while the study accounts for a range of demographic and clinical features, it’s reliance on electronic health records may be subject to information bias, including inaccuracies in coding, data entry errors, or missing data. There may also be unmeasured confounders or risk factors such as specific biomarkers and genetic factors not included in the model that could affect CRC risk. Finally, the applicability of the model in clinical practice also presents challenges as integration of predictive models into routine clinical workflows requires consideration of practical aspects such as healthcare provider training, patient acceptance, and system-level adaptations.
In conclusion, we developed a CRC risk stratification model that improves risk stratification both among subjects that did not undergo recommended screening and among those that underwent screening using an FOBT. This model leveraged information from one of the largest patient populations used for CRC risk evaluation to date and uses commonly available EHR-based features that allows for automatic risk evaluation on entire patient populations. Employing this model holds great potential to enhance the precision of CRC risk stratification, identify high-risk individuals who might be missed by conventional screening methods, and optimize the use of healthcare resources.



留言 (0)