
記住我








Named entity recognition (NER) and term normalization are important steps in biomedical natural language processing (NLP). NER is used to extract key information from textual medical reports, and normalization consists of matching a specific term to its formal reference in a shared terminology such as the United Medical Language System (UMLS) Metathesaurus []. Major improvements have been made recently in these areas, particularly for English, as a huge amount of data is available in the literature and resources. Modern automatic language processing relies heavily on pretrained language models, which enable efficient semantic representation of texts. The development of algorithms such as transformers [,] has led to significant progress in this field.
In , the term “mention level” indicates that the analysis is carried out at the level of a word or small group of words: first at the NER stage (in blue) and then during normalization (in green); finally, all mentions with normalized concept unique identifiers (CUIs) are aggregated at the “document level” (orange part). The sets of aggregated CUIs per document predicted by the native French and translated English approaches are then compared to the manually annotated gold standard.
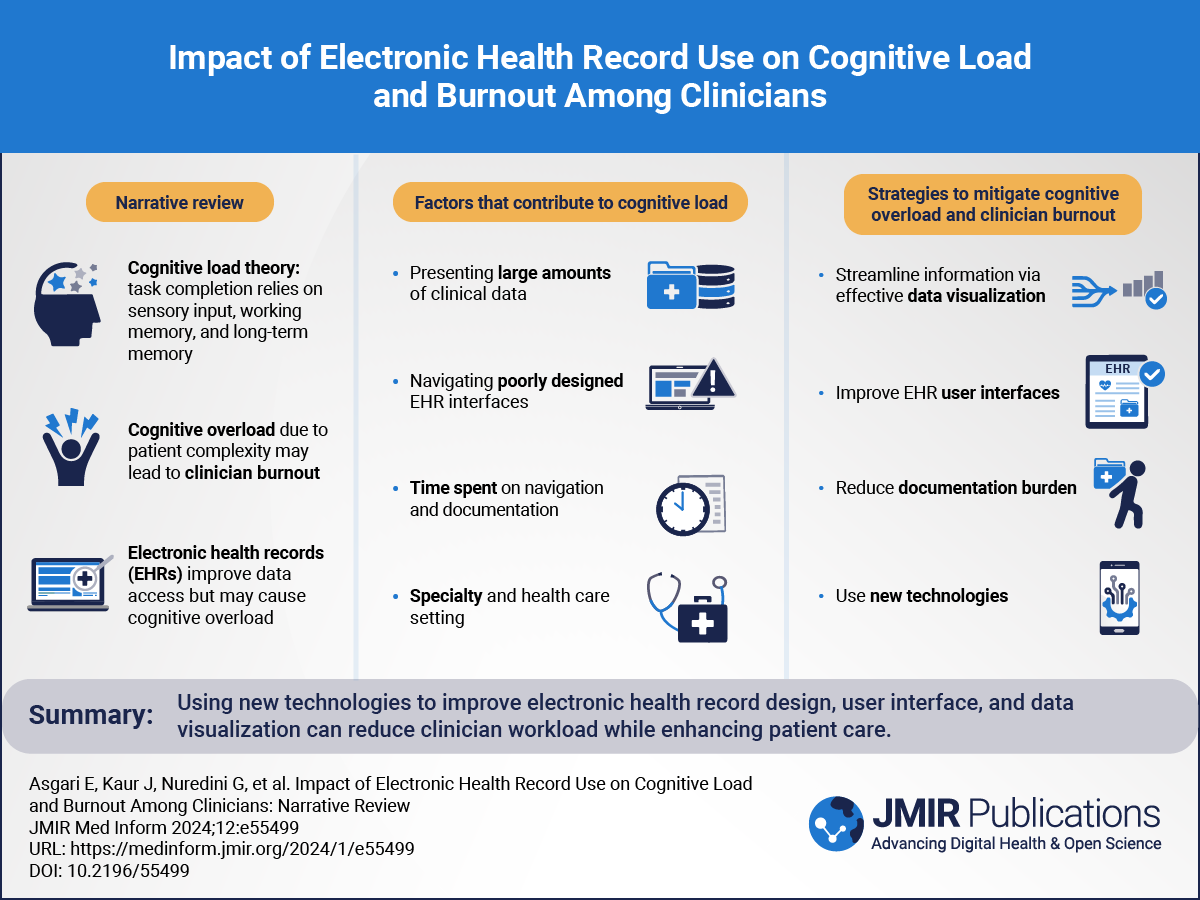
 Figure 1. Overall objective of the method: translating plain text to the CUI codes of the UMLS Metathesaurus, document by document. CHEM: Chemicals & Drugs; CUI: concept unique identifier; DISO: Disorders; PROC: Procedures; UMLS: United Medical Language System.
Figure 1. Overall objective of the method: translating plain text to the CUI codes of the UMLS Metathesaurus, document by document. CHEM: Chemicals & Drugs; CUI: concept unique identifier; DISO: Disorders; PROC: Procedures; UMLS: United Medical Language System. In many languages other than English, efforts remain to be made to obtain such results, notably due to a much smaller quantity of accessible data []. In this context, our work explores the relevance of a translation step for the recognition and normalization of medical concepts in French biomedical documents. We compared 2 methods: (1) a native French approach where only annotated documents and resources in French are used and (2) a translation-based approach where documents are translated into English, in order to take advantage of existing tools and resources for this language that would allow the extraction of concepts mentioned in unpublished French texts without new training data (zero-shot), as proposed in van Mulligen et al [].
We evaluated and discussed the results on several French biomedical corpora, including a new set of 42 annotated hospitalization reports with 4 entity groups. We evaluated the normalization task at the document level, in order to avoid a cross-language alignment step at evaluation time, which would add a potential level of error and thus make the results more difficult to interpret (see word alignment in Gao and Vogel [] and Vogel et al []). This normalization was carried out by mapping all terms to their CUI in the UMLS Metathesaurus []. summarizes these various stages, from the raw French text and the translated English text to the aggregation and comparison of CUIs at the document level. Our code is available on GitHub [].
The various stages of our algorithms rely heavily on transformers language models []. These models currently represent the state of the art for many NLP tasks, such as machine translation, NER, classification, and text normalization (also known as entity binding). Once trained, these models can represent any specific language, such as biomedical or legal. The power of these models comes from their neural architecture but also largely depends on the amount of data they are trained on. In the biomedical field, 2 main types of data are available: public articles (eg PubMed) and clinical electronic medical record databases (eg MIMIC-III []), and the most powerful models are, for example, BioBERT [], which has been trained on the whole of PubMed in English, and ClinicalBERT [], which has been trained on PubMed and MIMIC-III. In French, the variety of models is less extensive, with CamemBERT [] and FlauBERT [] for the general domain and no specific model available for the biomedical domain.
In , axis 1 (green axis on the left) corresponds to the native French branch with a NER step based on a FastText model trained from scratch on French clinical notes and a CamemBERT model. A multilingual Bidirectional Encoder Representations From Transformers (BERT) model was then used for the normalization step, with 2 models tested: a deep multilingual normalization model [] and CODER [] with the full version. Axes 2.1 and 2.2 (the 2 purple axes on the right) correspond to the translated English branches, with a first translation step performed by the OPUS-MT-FR-EN model [] for both. Axis 2.1 (left) was conducted with decoupled NER and normalization steps: FastText trained from PubMed and MIMIC-III [] for NER, and deep multilingual normalization [] or CODER [] with the English version for normalization. Axis 2.2 (right) used a single system for the NER and normalization stages: MedCAT [].
In addition to particularly powerful English-language pretrained models, universal biomedical terminologies (ie, the UMLS Metathesaurus) also contain many more English terms than other languages. For example, the UMLS Metathesaurus [] contains at least 10 times more English terms than French terms, which may enable rule-based models to perform better in English. As mentioned above, each reference concept in the UMLS Metathesaurus [] is assigned a CUI, associated with a set of synonyms, possibly in several languages, and a semantic group, such as Disorders, Chemicals & Drugs, Procedure, Anatomy, etc.
In parallel, the performance of machine translation has also improved thanks to the same type of transformer-based language models, and recent years have seen the emergence of high-quality machine translations, such as OPUS-MT developed by Tiedemann et al [], Google Translate, and others. These 2 observations have led several research teams to add a translation step in order to analyze medical texts, for example, to extract relevant mentions in ultrasound reports [,] or in the case of the standardization of medical concepts [,,]. Work in the general (nonmedical) domain has also focused on alignment between named entities in parallel bilingual texts [,].
 Figure 2. Diagram of different experiments comparing French and English language models without and with intermediate translation steps. CHEM: Chemicals & Drugs; CUI: concept unique identifier; DEVI: Devices; DISO: Disorders; EHR: electronic health record; EN: English; FR: French; FT: fine-tuned; PROC: Procedures; UMLS: United Medical Language System.
Figure 2. Diagram of different experiments comparing French and English language models without and with intermediate translation steps. CHEM: Chemicals & Drugs; CUI: concept unique identifier; DEVI: Devices; DISO: Disorders; EHR: electronic health record; EN: English; FR: French; FT: fine-tuned; PROC: Procedures; UMLS: United Medical Language System. shows the main approaches and models used in our study. We explored 1 “native French approach axis” (axis 1 in ), based on French linguistic models learned from and applied to French annotated data, and 2 “translated English approach axes” (axes 2.1 and 2.2), based on a translation step and concept extraction tools in English. We compared the performance of all axes with the average of the document-level CUI prediction precisions for all documents.
Native French ApproachAxis 1 consisted of 2 stages: a NER stage and a normalization stage. For the NER stage, we used the nested NER algorithm. Next, a normalization step was performed by 2 different algorithms: a deep multilingual normalization model [] and CODER [] with the CODER all version.
Translated-English ApproachFirst, axes 2.1 and 2.2 consisted of a translation step, performed by the state-of-the-art OPUS-MT-FR-EN [] or Google Translate algorithm. Second, similar to axis 1, axis 2.1 was based on a NER step and a normalization step. The NER step was performed by the same algorithm but trained on the National NLP Clinical Challenges (N2C2) 2019 data set [] without manual annotation realignment; for the normalization step, we used the same deep multilingual algorithm [] and the English version of CODER [] based on a BioBERT model []. This axis allows us to compare 2 methods whose difference lies solely in the translation step.
Axis 2.2 was based on the MedCAT [] algorithm, which performs NER and normalization simultaneously. In this case, we compared the native French method with a state-of-the-art, ready-to-use English system, which is not available in French.
Data SetsFor all our experiments, we chose to focus on 4 semantic groups of the UMLS Metathesaurus []: Chemical & Drugs (“CHEM”); Devices (“DEVI”), corresponding to medical devices such as pacemakers, catheters, etc; Disorders (“DISO”), corresponding to all signs, symptoms, results (eg, positive or negative results of biological tests), and diseases; and Procedures (“PROC”), corresponding to all diagnostic and therapeutic procedures such as imaging, biological tests, operative procedures, etc, as well as the corresponding number of documents.
shows the data sets used for all our experiments and the corresponding number of documents. First, 2 French data sets were used for the final evaluation, as well as for training the axis-1 models. QUAERO is a freely available corpus [] based on pharmacological notes with 2 subcorpora: MEDLINE (short sentences from PubMed abstracts) and EMEA (drug package inserts). We also annotated a new data set of real-life clinical notes from the Assistance Publique Hôpitaux de Paris data warehouse, described in Section S1 in .
Table 1. Overview of all data sets used. When a data set is used for both training and testing, 80% of the data set is used for training and 20% is used for testing. Thus, for the EMEA data set, 30 documents were used for training and 8 for testing, 34 French notes were used for training and 8 for testing, and so on.VariablesLanguages and data setsFrenchEnglishEnglish and FrenchQUAERO []French notesN2C2 2019 []Mantra []WMT 2016 []WMT 2019 []EMEAMEDLINETypeDrug noticesMEDLINE titlesFrench notesEnglish notesDrug notices and MEDLINE titlesPubMed abstractsPubMed abstractsSize (documents), n38251442100200>600,000 sent6542UseTrain NER✓✓✓✓ Test NER✓✓✓✓ Normalization✓✓✓✓ Test MedCAT ✓✓ Translation (fine-tuning) ✓✓Translation (test) ✓aN2C2: National Natural Language Processing Clinical Challenges.
bWMT: Workshop on Machine Translation.
cNER: named entity recognition.
Second, we used the N2C2 2019 corpus [] with annotated CUIs, on which we automatically added semantic group information from the UMLS Metathesaurus [], to train the axis-2.1 system and evaluate the NER and English normalization algorithms. We also used the Mantra data set [], a multilingual reference corpus for biomedical concept recognition.
Finally, we refined and tested the translation algorithms on the Workshop on Machine Translation biomedical corpora of 2016 [] and 2019 []. A detailed description of the number of respective entities in the data sets can be found in Table S1 in .
The annotation methods for the French corpus are detailed in Section S1 and Figure S1 in . The distribution of entities for this annotation is detailed in Table S1 in .
TranslationWe used and compared 2 main algorithms for the translation step: the OPUS-MT-FR-EN model [], which we tested without and with fine-tuning on the 2 biomedical translation corpora of 2016 and 2019 [,], and Google Translate as a comparison model.
NER AlgorithmFor this step, we used the algorithm of Wajsbürt [] described in Gérardin et al []. This model is based on the representation of a BERT transformer [] and calculates the scores of all possible concepts to be predicted in the text. The extracted concepts are delimited by 3 values: start, end, and label. More precisely, the encoding of the text corresponds to the last 4 layers of BERT, FastText integration, and a max-pool Char-CNN [] representation of the word. The decoding step is then performed by a 3-layer long short-term memory [] with learning weights [], similar to the method in Yu et al []. A sigmoid function was added to the vertex. Values (start, end, and label) with a score greater than 0.5 were retained for prediction. The loss function was a binary cross-entropy, and we used the Adam optimizer [].
In our experiments, for the native French axis (axis 1 in ), the pretrained embeddings used to train the model were based on a FastText model [], trained from scratch on 5 gigabytes of clinical text, and a CamemBERT-large model [] fine-tuned on this same data set. For English axis 2.1, the pretrained models were BioWordVec [] and ClinicalBERT [].
Normalization AlgorithmsOverviewThis stage of our experiments was essential for comparing a method in native French and one translated into English, and it consisted of matching each mention extracted from the text to its associated CUI in the UMLS Metathesaurus []. We compared 3 models for this step, described below: the deep multilingual normalization algorithm developed by Wajsbürt et al []; CODER []; and the MedCAT [] model, which performs both NER and normalization.
These 3 models require no training data set other than the UMLS Metathesaurus.
Deep Multilingual NormalizationThis algorithm by Wajsbürt et al [] considers the normalization task as a highly multiclass classification problem with cosine similarity and a softmax function as the last layer. The model is based on contextual integration, using the pretrained multilingual BERT model [], and works in 2 steps. In the first step, the BERT model is fine-tuned and the French UMLS terms and their corresponding English synonyms are learned. Then, in the second step, the BERT model is frozen and the representation of all English-only terms (ie, those present only in English in the UMLS Metathesaurus []) is learned. The same training is used for the native French and translated English approaches. This model was trained with the 2021 version of the UMLS Metathesaurus [], corresponding to the version used for annotating the French corpus. The model was thus trained on over 4 million concepts corresponding to 2 million CUIs.
CODERThe CODER algorithm [] was developed by contrastive learning on the basis of the medical knowledge graph of the UMLS Metathesaurus [], with concept similarities being calculated from the representation of terms and relations in this knowledge graph. Contrastive learning is used to learn embeddings through multisimilarity loss []. The authors have developed 2 versions: a multilingual version based on the multilingual BERT [] and an English version based on the pretrained BioBERT model []. We used the multilingual version for axis 1 (native French approach) and the English version for axis 2.1. Both types of this model (CODER all and CODER en) were trained with the 2020 version of UMLS (publicly available models). CODER all [] was trained on over 4 million concepts corresponding to 2 million CUIs, and CODER en was trained on over 3 million terms and 2 million CUIs.
For the deep multilingual model and the CODER model, in order to improve performance in terms of accuracy, we chose to add semantic group information (ie, Chemical & Drugs, Devices, Disorders, and Procedures) to the model output: that is, from the first k CUIs chosen from a mention, we selected the first from the corresponding group.
The MedCAT algorithm is described in detail in Section S1 in .
Ethical ConsiderationsThe study and its experimental protocol were approved by the Assistance Publique Hôpitaux de Paris Scientific and Ethical Committee (IRB00011591, decision CSE 20-0093). Patients were informed that their electronic health record information could be reused after an anonymization process, and those who objected to the reuse of their data were excluded. All methods were applied in accordance with the relevant guidelines (Commission nationale de l'informatique et des libertés reference methodology MR-004 []).
The sections below present the performance results for each stage. The N2C2 2019 challenge corpus [] enabled us to evaluate the performance of our English models on clinical data, and the Biomedical Translation 2016 shared task [] allowed us to evaluate our translation performance on biomedical data with a BLEU score [].
NER PerformancesTo be able to compare our approaches in native French and translated English, we used the same NER model, trained and tested on each of the data sets described above. shows the corresponding results. Overall F1-scores were similar across data sets: from 0.72 to 0.77.
Table 2. Named entity recognition (NER) performance for each model. For all experiments, we used the same NER algorithm but with different pretrained models. The best performance values are italicized.GroupsData sets and modelsEMEA test, with FastText* and CamemBERT-FT []French notes, with FastText* and CamemBERT-FTN2C2 2019 test, with BioWordVec [] and ClinicalBERT []PrecisionRecallF1-scorePrecisionRecallF1-scorePrecisionRecallF1-scoreCHEM0.800.830.820.840.880.860.870.850.86DEVI0.420.810.550.000.000.000.580.510.54DISO0.540.630.590.670.650.660.740.720.73PROC0.730.780.740.780.720.750.800.780.79Overall0.710.770.740.730.710.720.780.760.77aFastText* corresponds to a FastText model [] trained from scratch on our clinical data set.
bN2C2: National Natural Language Processing Clinical Challenges.
cCHEM: Chemical & Drugs.
dDEVI: Devices.
eDISO: Disorders.
fPROC: Procedures.
Normalization PerformancesThis section presents only the normalization performance based on the gold standard’s entity mentions, without the intermediate steps. The results are summarized in . The deep multilingual algorithm performed better for all corpora tested, with an improvement in F1-score from +0.6 to +0.11. By way of comparison, the winning team of the 2019 N2C2 had achieved an accuracy of 0.85 using the N2C2 data set directly to train their algorithm []. In our context of comparing algorithms between 2 languages, the normalization algorithms were not trained on data other than the UMLS Metathesaurus. MedCAT’s performance (shown in Table S2 in ) cannot be directly compared with that of other models, as this method performed both NER and normalization in a single step. However, we note that this algorithm performed as well as axis 2.1 in terms of overall performance, as shown in .
Table 3. Performance of the normalization step. Model results were calculated from the annotated data sets, focusing on the 4 semantic groups of interest: Chemical & Drugs, Devices, Disorders, and Procedures. The best performance values are italicized.AlgorithmsData set modelsEMEA testFrench notesN2C2 2019 testDeep multilingual normalization0.650.570.74CODER all0.580.51—CODER en——0.63aN2C2: National Natural Language Processing Clinical Challenges.
bNot applicable.
Table 4. Overall performances. The normalization step was performed by the deep multilingual model and the translation was performed by the OPUS-MT-FR-EN FT model. The best performance values are italicized.MethodsEMEA testFrench notesPrecisionRecallF1-score (95% CI)PrecisionRecallF1-score (95% CI)Axis 1 (French NER+normalization)0.630.600.61 (0.53-0.65)0.490.530.51 (0.47-0.55)Axis 2.1 (Translation+NER+normalization)0.530.400.45 (0.38-0.51)0.410.380.39 (0.34-0.44)Axis 2.2 (Translation+MedCAT [])0.530.460.49 (0.38-0.54)0.380.380.38 (0.36-0.40)aNER: named entity recognition.
Translation PerformancesFor both translation models, the respective BLEU scores [] were calculated on the shared 2016 Biomedical Translation Task []. The chosen BLEU algorithm was the weighted geometric mean of the n-gram precisions per sentence.
A fine-tuned version of OPUS-MT-FR-EN [] was also tested on the 2016 and 2019 Biomedical Translation shared tasks. For fine-tuning, we used the following hyperparameters: a maximum sequence length of 128 (mainly for computational memory reasons), a learning rate of 2 × 10–5, and a weight decay of 0.01, and we varied the number of epochs up to 15 epochs (the error function curve stops decaying after 10 epochs). The Google Translate model could not be used for our clinical score experiments for reasons of confidentiality.
presents the BLEU scores for the 3 models, showing that fine-tuning the OPUS-MT-FR-EN model [] on biomedical data sets gave the best results, with a BLEU score [] of 0.51. This was the model used to calculate the overall performance of axes 2.1 and 2.2.
Table 5. Translation performances: BLEU scores of the translation models. The best performance value is italicized.ModelsWMT Biomed 2016 testGoogle Translate0.42OPUS-MT-FR-EN0.31OPUS-MT-FR-EN FT0.51aWMT: Workshop on Machine Translation.
bOPUS-MT-FR-EN FT corresponds to the OPUS-MT-FR-EN model [] fine-tuned on biomedical translated corpus from the WMT Biomedical Translation Tasks in 2016 [] and 2019 [].
Overall Performances From Raw Text to CUI PredictionsThis section presents the overall performance of the 3 axes, in an end-to-end pipeline. For axis 2, the results are those obtained with the best normalization algorithm (presented in ). The model used for translation is the OPUS-MT-FR-EN [] fine-tuned model. The results are presented in , with the best results obtained by the native French approach on the EMEA corpus [] and French clinical notes. The 95% CIs were calculated using the empirical bootstrap method [].
In this paper, we compared 2 approaches for extracting medical concepts from clinical notes: a French approach based on a French language model and a translated English approach, where we compared 2 state-of-the-art English biomedical language models, after a translation step. The main advantages of our experiment are that it is reproducible and that we were able to analyze the performance of each step of the algorithm: NER, normalization, and translation, and to test several models for each step.
The Quality of the Translation Is Not SufficientWe showed that the native French approach outperformed the 2 translated English approaches, even with a small French training data set. This analysis confirms that, where possible, an annotated data set improves feature extraction. The evaluation of each intermediate step showed that the performance of each module was similar in French and English. We can therefore conclude that it is rather the translation phase itself that is of insufficient quality to allow the use of English as a proxy without a loss of performance. This is confirmed by the translation performance calculations, where the calculated BLEU scores were relatively low, although improved by a fine-tuning step.
In conclusion, although translation is commonly used for entity extraction or term normalization in languages other than English [,,-], due to the availability of turnkey models that do not require additional annotation by a clinician, we showed that this induces a significant performance loss.
Commercial application programming interface–based translation services could not be used for our task due to data confidentiality issues. However, the OPUS-MT model is considered state of the art, it is adjustable to domain-specific data, and the translation results presented in confirm the absence of performance difference between this model and the Google Translate model.
Although our experiments were carried out on a single language, the French-English pair is one of the best performers in recent translation benchmarks []. Other languages are unlikely to produce significantly better results.
Error AnalysisIn these experiments, the overall results may appear low, but the task is still complex, especially because the UMLS Metathesaurus [] contains many synonyms with different CUIs. To better understand this, we performed an error analysis on the normalization task only, as shown in Table S3 in , with a physician’s evaluation, on a sample of 100 errors for both models. We calculated that 24% (24/100) and 39% (39/100) of the terms found by the deep normalization algorithm [] and CODER [], respectively, were in fact synonyms but had 2 different UMLS CUIs. This highlights the difficulty of achieving normalization on the UMLS Metathesaurus. The UMLS Metathesaurus indeed groups together numerous terminologies whose mapping between terms is often imperfect, implying that certain synonyms, as shown here, do not have the same CUI, as pointed out by Cimino [] and Jiménez-Ruiz et al []. For example, “cardiac ultrasound” has the CUI of C1655737, whereas “echocardiography” has another CUI of C0013516; similarly, “H/O: thromboembolism” has a CUI of C0455533, whereas “history of thromboembolism” has a CUI of C1997787, and so on.
Moreover, to be more precise, each axis had its own errors: overall, the errors in axis 2 were essentially due to the loss of information in translation. One notable error was literal translation: for example, “dispersed lupus erythematous” instead of “systemic lupus erythematosus,” or “crepitant” instead of “crackles.” This loss of translation led to more errors in the extraction of named entities.
In addition to the loss of translation information, axis 2.1 was also penalized by the NER step, due to the difference between the training set (N2C2 notes) and the test set (the translated French notes; the aim being to compare the performance of English-language turnkey models with the performance of French-language models from an annotated set). Axis 2.1, for example, omitted the names of certain drugs more often.
Finally, both axes were penalized by abbreviations. These were often badly translated (for example, the abbreviation “MFIU” for “mort foetale in utero,” meaning “intrauterine fetal death,” was not translated), which penalized axis 2. Nevertheless, if they were indeed extracted by NER steps in axis 1, they were not correctly normalized due to the absence of a corresponding CUI in the UMLS Metathesaurus.
LimitationsThis work has several limitations. First, the actual French clinical notes contained very few terms in the Devices semantic group, which prevented the NER algorithm from finding them in the test data set. However, this drawback, which penalized the native French approach, still allowed us to draw a conclusion for the results. Furthermore, in this study, we did not take into account attributes of the extracted terms such as negation, hypothetical attribute, or belonging to a person other than the patient for comparison purposes, as the QUAERO [] and N2C2 2019 [] data sets did not have this labeled information.
The authors would like to thank the Assistance Publique Hôpitaux de Paris (AP-HP) data warehouse, which provided the data and the computing power to carry out this study under good conditions. We wish to thank all the medical colleges, including internal medicine, rheumatology, dermatology, nephrology, pneumology, hepato-gastroenterology, hematology, endocrinology, gynecology, infectiology, cardiology, oncology, emergency, and intensive care units, that gave their permission for the use of the clinical data.
The data sets analyzed as part of this study are not accessible to the public due to the confidentiality of data from patient files, even after deidentification. However, access to raw data from the Assistance Publique Hôpitaux de Paris (AP-HP) data warehouse can be granted by following the procedure described on its website []: by contacting the ethical and scientific committee at secretariat.cse@aphp.fr. Prior validation of access by the local institutional review committee is required. In the case of non-APHP researchers, a collaboration contract must also be signed.
CG contributed to conceptualization, data curation, formal analysis, investigation, methodology, software, validation, original drafting, writing—original version, and writing—revision and editing the manuscript. YX contributed to investigation, methodology, software, and validation. PW contributed to investigation, software, and revision of the manuscript. FC contributed to conceptualization, methodology, project administration, supervision, writing—original version, and writing—revision and editing of the manuscript. XT contributed to conceptualization, formal analysis, methodology, writing—original version, and writing—revision and editing of the manuscript.
None declared.
Edited by Christian Lovis; submitted 03.06.23; peer-reviewed by Luise Modersohn, Manabu Torii; final revised version received 07.01.24; accepted 10.01.24; published 04.04.24.
© Christel Gérardin, Yuhan Xiong, Perceval Wajsbürt, Fabrice Carrat, Xavier Tannier. Originally published in JMIR Medical Informatics (https://medinform.jmir.org), 4.4.2024.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in JMIR Medical Informatics, is properly cited. The complete bibliographic information, a link to the original publication on https://medinform.jmir.org/, as well as this copyright and license information must be included.
留言 (0)