Data sources
Data from two hospitals from the CHFT Foundation NHS Trust Hospitals were used in this retrospective observational study. Ethical approval was obtained from the University of Huddersfield Ethics Committee (reference number: SAS-SREIC 21.7.21–7). CHFT granted data access for the study following training and compliance with Information Governance protocols.
Using structured queries on the electronic health records, the hospital's informaticist extracted the feature-rich dataset (reports) that met the study's eligibility criteria. We anonymized and pre-processed (cleaned) the extracted data to ensure it was in an ideal format for analysis. Importantly, patient consent waiver was applied to the study, given that the data from the electronic health records were de-identified and were used for retrospective analysis.
Study population
We retrospectively identified adult patients between May 1, 2017, and October 20, 2021, both male and female, over the age of 18, who were receiving DOAC therapy. Those who met the inclusion criteria were drawn from a range of CHFT wards (e.g., general medicine, geriatrics, cardiology, and respiratory medicine). They were either admitted directly to these wards or transferred to them. Outpatients and patients admitted to the maternity ward were excluded from the study.
DOAC therapy
DOAC therapy was prescribed for the management or prevention of ischaemic stroke in atrial fibrillation or the treatment and prevention of venous thromboembolism (deep vein thrombosis or pulmonary embolism), based on local NHS guidelines. Given that many patients had several events (treatment episodes), we chose the last treatment (dose of medication) the patient received (last treatment encounter) to reflect the stable or maintenance dose. Also, we only considered patients who received uniform DOAC therapy throughout; patients whose DOAC therapy was switched were excluded.
Covariates
For each patient, demographics (e.g., age, gender, ethnicity), clinically relevant variables such as obesity status, height, weight, chronic kidney disease status, bleeding risk, venous thromboembolism risk (using the hospital’s local risk assessment tool), comorbidities, medication (e.g., apixaban, rivaroxaban, edoxaban, and dabigatran), DOAC treatment duration (in days and years), medication dose, and indications, respectively, were extracted from the electronic health records as continuous or categorical features.
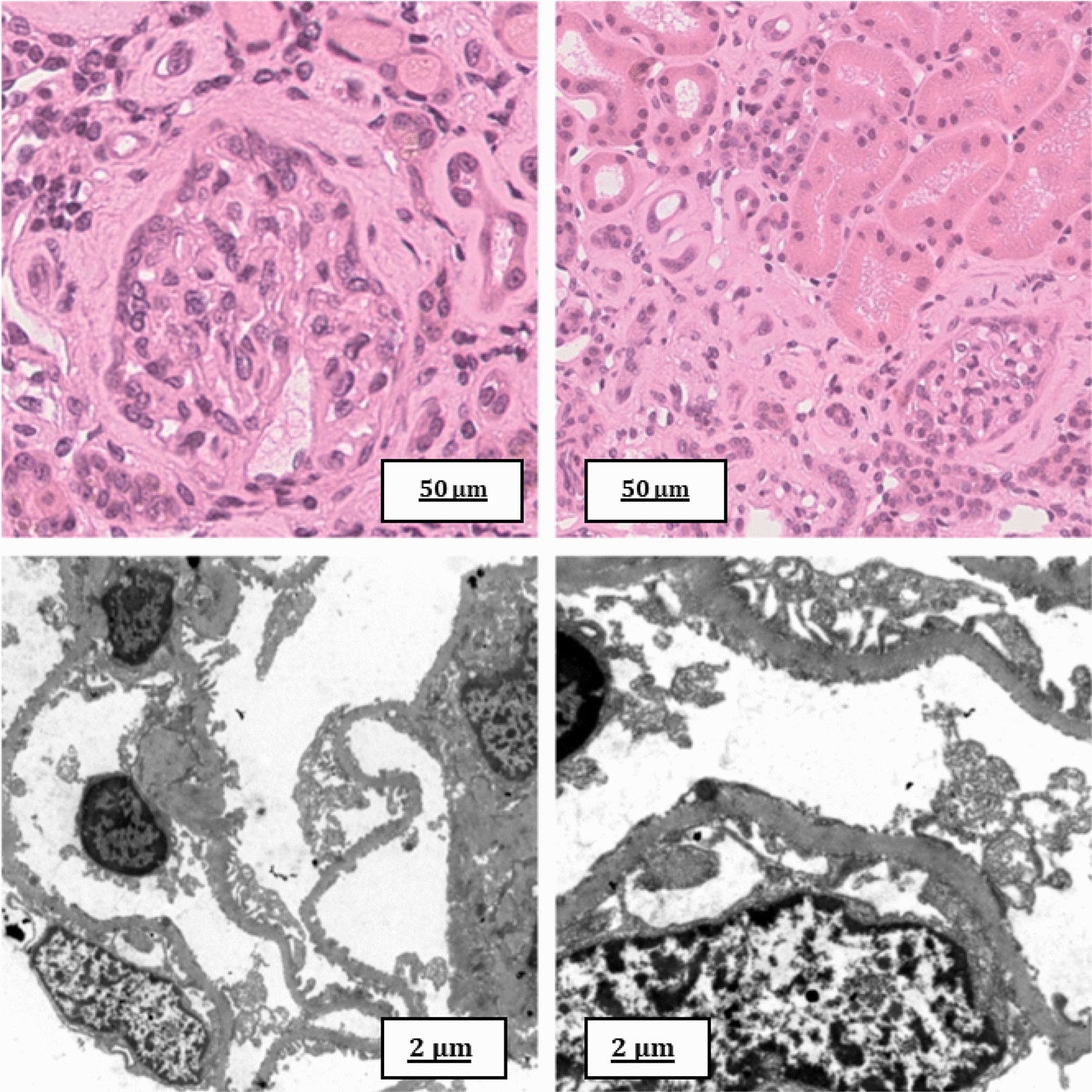
The definition of CKD was based on the recent Kidney Disease Improving Global Outcomes (KDIGO) guidelines: abnormalities of kidney structure or function, present for > 3 months, with implications for health. Chronic kidney disease is categorised based on (estimated) glomerular filtration rate (eGFR). The CKD classification standard adopted by the NHS is as follows: stage 1 (normal kidney function) where eGFR ≥ 90 ml/min; stage 2 where eGFR is slightly reduced (60–89 ml/min); stage 3a (eGFR of 45–59 ml/min); stage 3b (eGFR 30–44 ml/min); stage 4 (eGFR 15–29 ml/min) and Stage 5 which depicts kidney failure/end-stage kidney disease (ESKD) (eGFR of 0–15 ml/min).
The Chronic Kidney Disease Epidemiology Collaboration (CKD-EPI) equation adopted by the local NHS standard was used to estimate the renal function of the selected cohort as follows:
eGFR = 141 × min(SCr/κ, 1)α x max(SCr /κ, 1)– 1.209 × 0.993Age × 1.018 [if female] × 1.159 [if Black] (eGFR (estimated glomerular filtration rate) = mL/min/1.73 m2 | SCr (standardized serum creatinine) = mg/dL| κ = 0.7 (females) or 0.9 (males)| α = − 0.329 (females) or − 0.411 (males)| min = indicates the minimum of SCr/κ or 1|max = indicates the maximum of SCr/κ or 1| age = years).
The values which are based on CKD staging were encoded accordingly: stage 5 or ESKD (eGFR < 15) = 5; stage 4 (15–29 mL/min) = 4; stage 3b (30–44 mL /min) = 3; stage 3a (45–59 mL/min) = 2; normal kidney function (eGFR ≥ 60) = 1 [9].
Outcomes
Our study outcomes encompassed; length of stay (in days), all-cause mortality (deceased), clinically relevant non-major bleeding in atrial fibrillation and surgical patients, ischaemic stroke, any thromboembolism events, and the number of emergency visits (any hospital emergency visits post-DOAC treatment). We used the International Society on Thrombosis and Haemostasis definition of clinically relevant non-major bleeding, which is ‘any sign or symptom of haemorrhage requiring medical intervention by a healthcare professional or leading to hospitalisation or increased level of care, or prompting a face-to-face evaluation’ [20]
The primary outcomes were clinically relevant non-major bleeding, all-cause mortality, ischaemic stroke, and any thromboembolic events, while secondary outcomes were the length of stay and the number of emergency hospital visits.
Statistical analyses
The distribution variables extracted for the study were tested for normality using preliminary statistical techniques. Data were summarized using descriptive statistics for continuous (e.g., mean, median, mode, standard deviation) and categorical data (frequency, proportion); intracohort comparison was carried out. Furthermore, possible correlation(s) between the variables were assessed using Pearson’s test. The significance level was set to p < 0.05.
The analysis was completed in two phases. In the first phase, machine learning algorithms were implemented and used to identify important features contributing to a specific outcome. In the next phase, multivariate regression models were conducted to examine the association between DOAC therapy and outcomes. The important features identified using machine learning algorithms were entered as confounders in the multivariate regression models. This step provided a strong rationale for selecting relevant covariates in multivariate regression models to examine the statistical associations.
Machine learning workflowData cleaning
The most important phase of the machine learning pipeline is data pre-processing. No matter how powerful a machine learning algorithm is, using poor-quality data would yield unrealistic results. Standard data cleaning procedures include removing redundant and irrelevant data, standardising text capitalization (lower case or upper case) and addressing missing values and human errors. A lengthy narrative text was encoded (e.g., the clinical notes in the indication field). The label encoding method was also used to encode categorical features such as gender, race, clinically relevant non-major bleeding/bleeding risk, and stroke/stroke risk. Clinical domain expertise was used to guide feature engineering. Redundant features were removed to reduce the number of features from 49 to 26, and some features were changed to make them more informative.
Data that were missing but had a significant count were labelled as unknown, whereas data that had no significant count (less than 5% of the entire sample) were eliminated. Estimated GFRs > 90 were labelled as 100; for missing values in the body mass index (BMI) column, we replaced them with their computed BMI using the patient’s height and weight. Missing values in the eGFR column were replaced with the average value (imputation of mean). There was a considerable number of human errors in the recording of height and weight. For instance, the height column contained over 12,000 values with incorrect decimal points, leading to numerous outliers. As a result, the data were adjusted, and the BMI was recalculated using the weight and BMI function. Normalizing and scaling variables were further parts of data cleansing.
Model development and evaluation
The cleaned data were split into 70% training and 30% test subsets using stratified sampling to ensure the same target class distribution. A range of classification models was trained using the training data and tested on the unseen testing data. Then, the models were evaluated on various performance metrics, including accuracy, precision, recall, F1-score, and confusion matrix—the details on these are shown elsewhere [21]. Figure S1 below summarises the steps of the machine learning pipeline that were implemented.
Besides analysing the dataset using classification models like random forests and decision trees, the same models were used to rank the predictor variables in the overall patient dataset according to the weights of their contribution to the outcomes in the study.
Machine learning analysis
Machine learning models are capable of discerning patterns and information from datasets, creating a concise summary of the present data and enabling predictions to be made on new, previously unseen data. The experiments aimed to find the classification model most suitable for the dataset of patients with CKD. Seven (6) well-known machine learning classification models were trained on the cleaned dataset. These selected models employ different algorithms/approaches to learn from data and have different parameters and hyperparameters. The models were trained on the same dataset under the same training and testing settings. The accuracy of the models on the test dataset is shown in Table S1. Apart from the support vector machine, gradient boosting classifier and logistic regression, the remaining models (i.e., random forests and decision trees) achieved excellent accuracy of more than 97%. They learned the patterns in the data better to make acceptable predictions. As a result, they achieved higher values of precision, recall, and F1 scores, as shown in Table S2.
As illustrated in Figures S1 and S2, the decision trees and random forest machine learning algorithms produced a ranking of the features in the dataset based on their strength of influence on clinical outcomes. In descending order, the top 4 features impacting all-cause mortality were treatment days, length of stay, age, and emergency hospital visits.





留言 (0)