
記住我


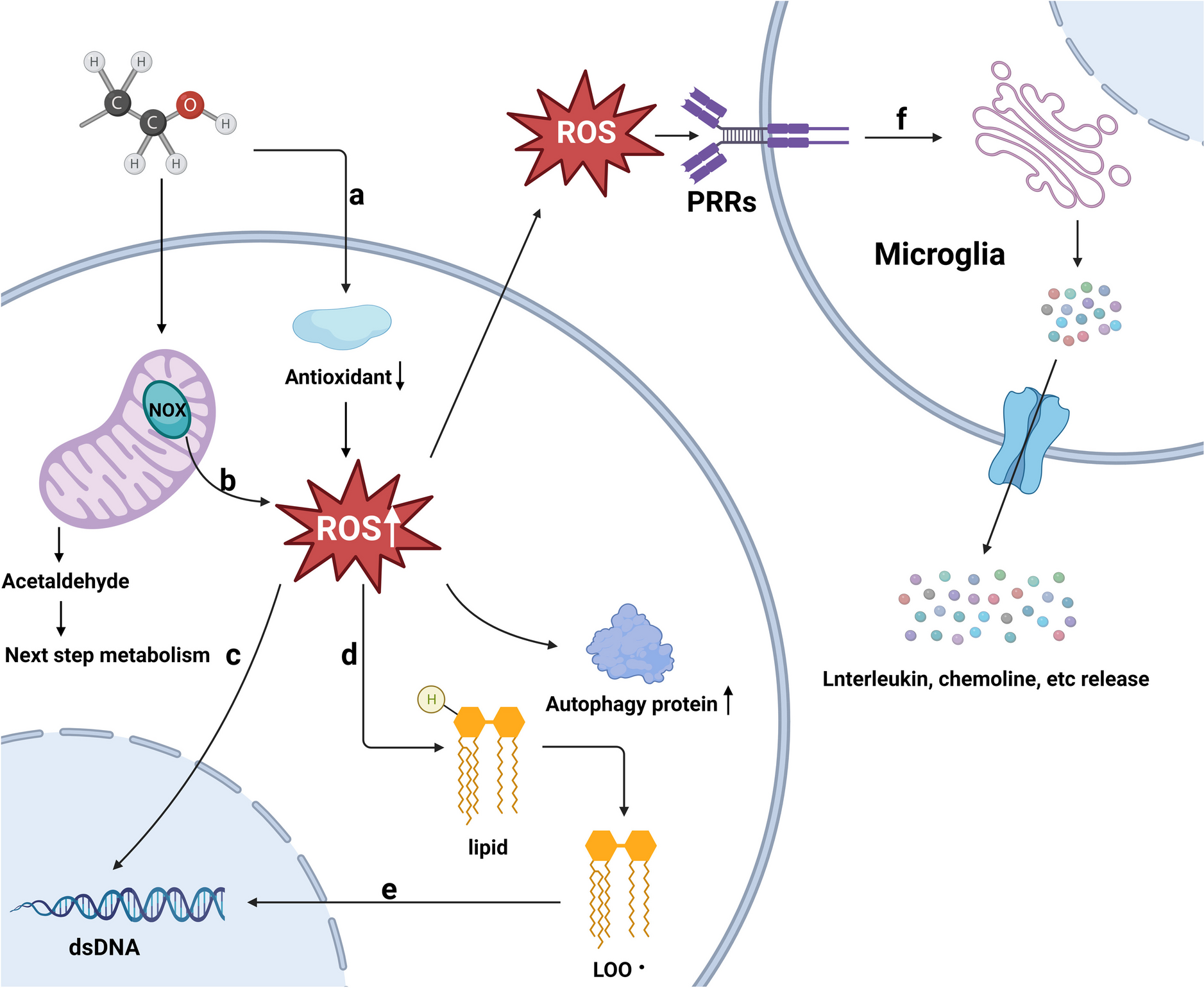
The final sample included 45 children (17 female, 28 male) with an average age of 28.5 months (SD = 3.0 months, range = 24.5–34.7 months) recruited from the greater Boston area. The sample skewed male because we focused recruitment on late talkers, who are more likely to be male [49]. Participants were prescreened for a history of hearing loss or tubes; additionally, children were screened at their visit for a high risk of autism spectrum disorder using the Modified Checklist for Autism in Toddlers, Revised (M-CHAT-R: [70]). All participants in the final sample were classified as “low risk.” Per parent report, all children were exposed to English at least 70% of the time. Participants had no reported developmental disorders other than for language: Three children were reported to have a language-related diagnosis, either “expressive language delay” or “language delay.” Seven additional children participated but were excluded from final analysis due to a prolonged history of ear tubes (n = 2), a history of tongue-tie (n = 1), diagnosis with autism spectrum disorder within a week following participation (n = 1), or failure to complete the experimental session due to fussiness (n = 3).
We asked parents to report on race/ethnicity and parent education. One family did not provide information on race/ethnicity, and three families did not provide information on parent education. Of those who did, participants were primarily White (91%), 2% were Asian, and 5% were more than one race. Nearly all children (96%) had at least one parent with a college degree or more advanced degree, including 35% of children who had at least one parent with a doctorate (Ph.D., M.D., or J.D.).
Expressive vocabulary was assessed using the MacArthur-Bates Communicative Development Inventories Level 2 Short Form A (MBCDI: [71]). Children were reported to produce, on average, 69 of the 100 words (SD = 27, range = 1–100). The Preschool Language Scales, 5th edition (PLS: [72]) was administered to characterize broader language abilities. Children averaged a standard score of 106 (SD = 17) on the Auditory Comprehension subscale (PLS-AC) and 107 (SD = 16) on the Expressive Communication subscale (PLS-EC). Finally, the Visual Reception subscale of the Mullen Scales of Early Learning (MSEL-VR: [73]) was used as a proxy for nonverbal intelligence. Children had an average T-score of 53 (SD = 11); one participant did not complete MSEL-VR testing.
We used the MBCDI to classify each child as either a “late talker” (n = 14) or “typically developing” (n = 31). Of the late talkers, eight had a standard score at or below the 15th percentile for their age and gender. The MBCDI is only normed for children up to age 30 months; however, children older than 30 months whose score was at or below the 15th percentile for their gender at 30 months were also classified as late talkers (n = 4). An additional 2 late talkers were classified based on parent report that they had qualified for speech and language therapy because of late talking. In total, 10 late talkers had qualified for or were receiving speech therapy services at the time of participation; no typically developing children had any reported history of therapy. There were no group differences with respect to average age (t = 1.14, p = 0.26, n.s.), proportion male (z = 0.85, p = 0.39, n.s.), or proportion monolingual English language learners (z = 1.5, p = 0.12, n.s.). All standardized measures showed group differences (see Table 1).
Table 1 Late talkers’ and typically developing children’s performance on standardized assessments (experiment 1)ApparatusStimuli were displayed on a 24-inch Tobii T60 XL corneal reflection eye-tracking monitor, which samples gaze approximately every 17 ms, calibrated at the beginning of each experimental session using a 5-point calibration procedure. Children sat in a car seat 20 in from the monitor or in their parent’s lap while the parent wore a blindfold.
StimuliThe stimuli were initially developed by Konishi et al. [74] and modified for an eye-tracking procedure by Valleau et al. [17]. Konishi et al. selected a total of 36 verbs and 14 nouns that are highly imageable and learned early in typical language development. They filmed 6-s video clips depicting the referent action for each verb and selected static images depicting the referent object for each noun. Valleau et al. recorded accompanying auditory stimuli and arranged the stimuli into the trial structure depicted in Fig. 1. Experiment 1 included a subset of ten of the verb trials from the stimuli used by Valleau et al., described below, including only one item from each pair (e.g., “clap” but not “stretch”), as well as four of the noun trials which served as fillers to break up the session. All participants saw the same 14 trials in the same order. Children saw each trial once. See Additional file 1: Appendix A for a list of trials.
Fig. 1
The trial structure of one trial for experiments 1 and 2
Visual stimuliVerb trials featured two dynamic scenes side-by-side. Two verb trials featured dynamic scenes with just an actor (e.g., “clapping” and “stretching”) and eight trials featured dynamic scenes with an actor and an object (e.g., “shaking” and “opening” a present). Within each trial, the actor and object were the same in both dynamic scenes (e.g., in the trial depicting “tickle” and “kiss,” one scene depicted a girl tickling a teddy bear, while the other depicted the same girl kissing the same teddy bear). Videos were looped to provide continuous depictions of the events; Some events were durative and therefore continuous (e.g., “run”), whereas others occurred punctually between two (e.g., “kick”) and five (e.g., “break”) times. Filler trials targeting nouns featured two static images side-by-side.
Auditory stimuliA female American English speaker recorded the auditory stimuli in a sound-attenuated booth. Children heard attention-grabbing phrases (e.g., “Wow!”) and directives to find the target. For trials including both an actor and object, verbs were targeted using transitive syntax (e.g., “Where is she tickling the bear?”), whereas those including only an actor were targeted using intransitive syntax (e.g., “Where is she clapping?”). Children also heard prompts in neutral syntax (e.g., “Find clapping!”).
DesignEach trial included an Inspection Phase, a Baseline Phase, a Prompt Phase, and a Test Phase (see Fig. 1). Verb trials and noun filler trials were structured identically; however, the Inspection and Baseline Phases were shorter for noun trials than for verb trials because static images do not change over time and we did not want children to tire of looking at them.
In the Inspection Phase (8 s for verb trials; 4 s for noun trials), children previewed each visual stimulus individually, one on the left and the other on the right. Side (left or right first) and order (target or distractor first) were counterbalanced. The Baseline Phase (6 s for verb trials; 3 s for noun trials) depicted both visual stimuli simultaneously in the same locations they had appeared in during the Inspection Phase. The Inspection and Baseline Phases included attention-grabbing phrases to direct children’s attention to the screen (e.g., “Look!”, “Wow!”).
In the Prompt Phase (4 s for verb and noun trials), children heard a prompt to find the target scene or image. Scenes featuring only an actor were queried in intransitive syntax (e.g., “Where is she clapping?”), whereas scenes featuring an actor and agent were queried in transitive syntax (e.g., “Where is she throwing the balloon?”). Because pairs of scenes always featured the same actor and objects, nouns and pronouns were not a cue for the target versus distractor. A centrally positioned star directed children’s attention to the center of the screen. In the Test Phase (6 s for verb and noun trials), the visual stimuli reappeared in their original positions. Children heard an additional prompt in neutral syntax (e.g., “Find clapping!”) after two seconds.
Procedure overviewParticipation was part of a two-visit protocol approved by Boston University’s Institutional Review Board. At the first visit, parents provided written consent and completed a demographics questionnaire, the MBCDI and M-CHAT-R. The first author, a licensed speech-language pathologist, administered the PLS. Children also participated in an unrelated experimental task. At the second visit, approximately 2 weeks later, children took part in two additional experimental tasks, of which this study was the second. The MSEL-VR was also administered during the second visit.
Exclusionary criteriaAll trials with more than 50% track loss (e.g., blinks) during the Test Phase were removed from analysis. After these removals, on average, 9 of 10 verb trials (SD = 1, range = 5–10) were included for typically developing children, while 7.5 of 10 (SD = 2, range = 4–10) were included for late talkers; this difference was significant (t(43) = 3.35, p = 0.002). Differences in the number of included trials is unsurprising given that late talkers show differences in attention during experimental tasks [75]. However, some of this inattentiveness may also be driven by task difficulty; for example, late talkers may look toward a parent or examiner for cues because they are unsure of the target word’s meaning.
AnalysisOur analyses considered children’s (1) accuracy and (2) processing speed. For each, we conducted a mixed-effects regression to determine whether there were group differences. This included the outcome variable of eye gaze behavior (accuracy or processing); random effects of participant and trial; and fixed effects of age, gender, and group (late talker or typically developing). Regressions were run using the lme4 package (Version 1.1–12; [76]) in R [77] with model comparisons made using the drop1() function with chi-square tests.
AccuracyFollowing Reznick [7], we calculated accuracy as an increase of 15% in target looking between Baseline (before children are prompted to find the target) and Test (after the auditory prompt). To identify at what point in time during the 6-s test window we should make this calculation, we applied a bootstrapped cluster-based permutation analysis [66] using the eyetrackingR Package [78]. We hypothesized that late talkers might require a later time window for demonstrating vocabulary knowledge than typically developing toddlers, so we ran separate analyses for each group. The cluster analysis compared children’s gaze behaviors between Baseline and Test to identify if and when children preferred the target in the Test Phase above and beyond Baseline looking rates. For the Baseline Phase, we averaged proportion of looks to the target scene versus elsewhere across all time points and trials to obtain a single measure of each group’s overall preference for the target scene during this Phase. This is because we were not interested in the dynamics of their attention to the target scene during Baseline, but rather how much they preferred to look at it overall. For the Test Phase, in which we were interested in the dynamics of children’s attention over time, we calculated children’s average proportion of looks to the target scene versus elsewhere in each 50-ms window. In both cases, when calculating the proportion of looking to the target, we included looks to neither the target nor the distractor (e.g., looking in between the two scenes) and track loss in the denominator of the proportion; these looks may reflect children’s uncertainty and we did not want to remove these data points.
Our planned model for identifying clusters was a mixed-effects regression with the dependent variable of proportion of looks to the target scene versus elsewhere, the predictor variable of phase (Baseline or Test, dummy coded as “0” and “1”), and random effects of trial and participant. We applied a threshold of p = 0.05, meaning the time bin had to reach this level of statistical significance in order to be included in a cluster. Adjacent clusters and those separated by only 50 ms were combined into larger clusters. We then ran the permutation analysis with 1000 permutations to confirm that these windows emerge even when the data is scrambled. Two paired t tests (following, e.g., [79]), one including all the children in the LT group and another including all children in the TD group, compared, for each trial for each child, the average proportion of looks to the target scene between each trial’s overall Baseline looking and the identified cluster.
The earliest statistically significant cluster was used to identify the response window for the accuracy analysis. Response windows—separate for each group—began at the start of the earliest significant cluster wherein children looked more to the target scene in the Test Phase than in Baseline. We standardized the duration of the response windows to 1500 ms, as has been done in receptive noun vocabulary tasks (e.g., [8]).
Accuracy was then calculated, by-child by-trial, by comparing the average proportion of looks during the whole 6 s of the Baseline Phase and the response window of the Test Phase. A child was credited with knowing the meaning of the target verb if their looks increased at least 15% from Baseline to Test.
Processing speedProcessing speed was operationalized as latency, i.e., the earliest time point within the Test Phase of each trial in which the child looked toward the target scene. As in Valleau et al. [17], children who did not look to the target scene during the Test Phase at all were given a latency of 6000 ms. Also following Valleau et al. [17], we excluded looks in the first 50 ms of the Test Phase as being too early to be attributable to hearing the auditory stimuli; it takes approximately 300 ms to program and launch a saccade (e.g., [80]).
ResultsDe-identified gaze data are available on the Open Science Framework (https://osf.io/ghp7q). Figure 2 depicts children’s preference for the target scene over time as the Test Phase unfolded; target preference is calculated as the proportion of frames in which children looked to the target scene versus all other locations. Baseline looking preference is indicated by the dashed lines. Late talkers averaged a smaller proportion of looking to the target scene than typically developing children during the Test Phase (M(LTs) = 0.39, SD(LTs) = 0.08; M(TDs) = 0.49, SD(TDs) = 0.09; t(43) = 3.8, p < 0.001). Conversely, late talkers averaged a higher track loss than typically developing children on included trials (M(LTs) = 0.28, SD(LTs) = 0.09; M(TDs) = 0.22, SD(TDs) = 0.09; t(43) = 2.3, p = 0.024). However, there were no between-group differences in average proportion of looks to the distractor scene (M(LTs) = 0.33, SD(LTs) = 0.06; M(TDs) = 0.29, SD(TDs) = 0.07; t(43) = 3.8, p = 0.16, n.s.). We observed from visual inspection of the graph that both groups preferred the target during the Test Phase above Baseline looking rates. This suggests that, overall, children know at least some of the target verbs queried.
Fig. 2
Timecourse of children’s gaze to the target scene during the test phase by group (experiment 1). The x-axis represents time, in ms, from the onset of the test phase, and the y-axis represents the proportion of looks to the target scene versus elsewhere. Error bars indicate standard error of participant means. Dashed lines indicate group baseline averages. The boxes indicate times in which proportion of looking to the target was significantly greater in the Test Phase over the Baseline Phase for LTs (red) and TDs (purple), per cluster-based permutation analysis
AccuracyFor late talkers, the bootstrapped cluster-based permutation analysis revealed three clusters in which proportion of looking to the target scene differed between Baseline looking rates (p = 0.40) and the Test Phase. The first cluster lasted from 0 to 600 ms: Here, late talkers looked less to the target scene in Test than they had in Baseline (t(104) = 15, p < 0.001). This is unsurprising given the trial structure: Recall that children begin the Test Phase looking at the center of the screen, as they have just seen a central fixation star. The second cluster began at 1550 ms and lasted to 3100 ms (t(104) = − 2.5, p = 0.01); here, late talkers looked more to the target scene in test than in Baseline. The third cluster, from 4850 to 6000 ms, was not statistically significant (t(104) = − 1.3, p = − 0.19, n.s.) after the permutation analysis and t test. Given the results of this analysis, late talkers were given the response window of 1550 to 3050 ms for the accuracy analysis (because we standardized windows to a duration of 1500 ms).
For typically developing children, two significant clusters emerged in which the proportion of looking to the target differed between Baseline (p = 0.43) and Test. The first cluster lasted from 0 to 600 ms. As with late talkers, typically developing children began the Test Phase looking less to the target scene than they had in Baseline (t(276) = 19, p < 0.001). The second cluster lasted from 900 to 6000 ms. Here, typically developing children looked at the target scene significantly more during test than they had during baseline (t(276) = − 5.7, p < 0.001). We therefore used a response window for the accuracy analysis of 900 to 2400 ms for typically developing children to standardize the duration, but we note that it is interesting that the original cluster for typically developing children was much longer (5100 ms) than for late talkers (1600 ms), suggesting that once typically developing children had settled on the target they sustained their attention on it for much longer.
Using the threshold of 15% increase between Baseline and response window, late talkers knew 51% of the target verbs (SD = 0.22, range = 0.125–1) for trials they contributed. Typically developing children knew 49% of the target verbs (SD = 0.19; range = 0.0–0.9) for the trials they contributed. The regression model indicated no significant relationship between children’s accuracy and any of the fixed effects included (bgroup = 0.02, tgroup = 0.34, pgroup = 0.70, n.s.; bage = 0.02, tage = 1.88, page = 0.054, n.s.; bgender = − 0.09, tgender = − 1.51, pgender = 0.11, n.s.). This indicates that, when provided enough time to demonstrate knowledge of target items, there are no significant differences in the number of verbs late talkers and typically developing children know.
At the recommendation of one reviewer, we conducted a post-hoc analysis wherein late talkers were given the same response window as typically developing children (900 to 2400 ms). Given this window, late talkers knew only 35% of the target verbs (SD = 0.20; range = 0.0–0.75). Here, the analysis yielded between-group differences, wherein late talkers knew significantly fewer verbs than typically developing children ((bgroup = 0.15, tgroup = 2.3, pgroup = 0.016); no other factors were significant (bage = 0.02, tage = 1.86, page = 0.063, n.s.; bgender = − 0.09, tgender = − 1.79, pgender = 0.079, n.s.). These findings indicate that late talkers perform poorer than typically developing children when assessment measures do not account for differences in overall response time.
We also included exploratory analyses in which language was treated as a continuous variable. However, we found no significant effect of the language variables (MBCDI raw score b = − 0.001, t = − 0.19, p = 0.84, n.s.; PLS-AC standard score b = 0.002, t = 0.916, p = 0.31, n.s.).
As an illustration of which verbs children in both groups tended to know, Table 2 shows the rank order of most to least accurate trials, by group. We note considerable variability between groups; late talkers had the highest proportion accuracy on the trial targeting “jump” (with the distractor “run”), whereas typically developing children had the highest proportion of accuracy on trials targeting “lick” (with the distractor “break”). Interestingly, “lick” was the second most-difficult verb for late talkers. Although intriguing, we note here that our goal was to explore methodological preliminaries surrounding our abilities to use eye-tracking to collect such information. With this in mind, we propose further research using this methodology but specifically designed to explore whether, as with expressive verb vocabulary [57, 58], late talkers and typically developing children differ in their receptive verb vocabulary compositions.
Table 2 The proportion of each verb known by late talkers and typically developing children, ranked (experiment 1). Numbers in parentheses indicate the proportion of participants who knew the target verb, by groupProcessing speedParticipants’ latency to look to the target scene averaged 1500 ms (SD = 502 ms). Surprisingly, late talkers (M = 1551 ms, SD = 477 ms) did not average longer latencies than typically developing children (M = 1477 ms, SD = 519 ms; t(43) = 0.66, p = 0.45, n.s.). The regression analysis indicated that age significantly predicted latency (b = − 72, t = − 4.9, p = 0.004), but group (b = − 119, t = − 0.75, p = 0.44, n.s.) and gender (b = 36, t = 0.25, p = 0.79, n.s.) did not.
This finding is perhaps striking given that there were between group differences in the start of the response window for accuracy analysis. We note that, although both relate to processing in some way, they are distinct measures. Latency is children’s first look to the target; it is calculated by-trial and independently of children’s performance in the Baseline Phase. By contrast, the response window represents patterns of sustained looking across all trials, and it is calculated relative to Baseline looking rates. In so doing, we are capturing how quickly children demonstrate a sufficiently robust representation of the target verb above and beyond chance looking rates. For example, a child may look first toward the target as their initial guess, but their representation may not be sufficient to feel confident in this choice; they would therefore scan back and forth between the two scenes before settling back onto the target with certainty (see [81] for a similar pattern in autistic children’s sentence processing). What we therefore interpret from these two measures together is that LTs and TDs were equally quick to first look to the target scene (latency), but that LTs took longer than TDs to settle on the target for a sustained period of time (response window), perhaps indicating less robust lexical entries.
We again included exploratory analyses in which language was treated as a continuous variable. We observed that broader receptive language abilities, but not vocabulary, predicted performance, such that children with higher standard scores on the Auditory Comprehension subtest of the PLS-5 averaged faster latencies; here, too, we found no significant effect of the language variables (MBCDI raw score b = 1.17, t = 0.245, p = 0.79, n.s.; PLS-AC standard score b = − 15.04, t = − 1.88, p = 0.049).
DiscussionIn experiment 1, we explored children’s eye gaze during a receptive verb vocabulary task with 2-year-old late talkers and typically developing children. We considered children’s overall accuracy and processing speed.
In calculating children’s accuracy, prior research has suggested that the response window that has been typically used with static images and noun stimuli (300 to 1800 ms) is inappropriate for dynamic scene targets [15, 17]. Instead, we identified a response window using bootstrapped cluster-based permutation analyses [66]. Given that late talkers are slower lexical processors than typically developing toddlers [11], it is perhaps unsurprising that they required a later window than their typically developing peers to demonstrate verb knowledge. While typically developing children preferred the target scene above Baseline looking rates beginning at 900 ms in the Test Phase, late talkers did not do so until 1550 ms. These findings echo research on older children with developmental language disorder, who show delayed responses during receptive language tasks (e.g., [82]). However, when provided additional time, late talkers knew as many verbs as did typically developing children. By contrast, when late talkers were held to the same expectations as typically developing toddlers (i.e., the 900 to 2400 ms window), there was a significant group difference. This discrepancy highlights the importance of adapting assessment measures to the population being studied, and accounting for differences between toddlers who are typically developing and those with language delay or disorder.
While not what we had hypothesized, the finding that late talkers and typically developing children showed receptive knowledge of the same proportion of the tested verbs is not altogether unsurprising. Late talkers are defined by the size of their expressive vocabularies; prior research indicates that although some late talkers also have smaller receptive vocabularies, others do not show receptive language deficits [51]. We also acknowledge that although late talkers and typically developing children knew on average the same number of verbs, it is not necessarily the case that they have equally robust representations of those verbs. Indeed, we observed in our bootstrapped cluster-based permutation analysis that, unlike typically developing toddlers, late talkers did not sustain a preference for the target scene for as long a duration once they identified it. One possibility is that this reflects late talkers’ confidence in their responses. In support of this hypothesis, we note that late talkers lost significantly more trials due to track loss than typically developing children, indicating more looks away from the screen (and possibly to a parent or researcher for cues or confirmation). Alternatively, the difference in sustained attention may be an indication that late talkers’ representations are more fragile than typically developing toddlers’ representations. It remains an open question in the field of how best to operationalize robustness of a lexical entry. One possibility is that overall looking time to the target indicates robustness of the lexical entry [83], but it is also possible that children with robust entries look quickly and then scan as they become bored with the task [84, 85]. We advocate for continued research into how best to operationalize robustness of representation, and whether this may vary as a factor of age, language ability, or population.
It is also worth noting that, although overall rates of accuracy did not differ between LTs and TDs, there were group differences in which verbs children were most likely to identify correctly (Table 2). This is consistent with prior research demonstrating that LTs and TDs show differences in the composition of their vocabularies (e.g., [54,55,56,57,58]). While most of these studies have focused on children’s expressive vocabularies, we offer evidence for possible differences in receptive vocabularies as well. Given the small number of trials in the current experiment and that they were not balanced across different types of verbs to be able to make systematic comparisons, we do not provide an interpretation of the differences in the lists in Table 2, but we leave this topic for future work, which should consider the intersection of verb knowledge, verb learning, and subsequent grammatical development. We tentatively hypothesize that a nuanced understanding of late talkers’ emerging verb vocabularies—both in the number and type of verbs acquired—may support endeavors to identify which late talkers are at greatest risk for developmental language disorder (similar to 19, which included outcomes for autistic toddlers).
Latency is a well-established eye gaze measure for processing speed given static images and noun targets, but research with dynamic scene stimuli has drawn mixed conclusions [16, 17, 28]. Although late talkers average slower latencies than typically developing children given noun targets and static images [11], we found no group differences in average latency to verb targets and dynamic scenes. Instead, children’s age significantly predicted performance, with older children faster to orient to the target than younger children. These results may provide insight into the discrepancies of prior findings. Golinkoff et al. [16] and Valleau et al. [17], who found no relationship between language ability and latency, both studied children who were younger than 2 years of age. However, Koenig et al. [28] did find that language predicted latency in 3-year-olds. We hypothesize that children are refining their processing abilities during the third year of life, improving their incremental language processing skills as well as their ability to focus on task demands over and above the ways in which dynamic scenes draw their attention. This in turn results in processing speed better reflecting other aspects of language knowledge. We would therefore expect that among older children, latencies reflect the difficulty of identifying the word’s referent, which should relate to their performance on other language assessments.
留言 (0)