




記住我




In the early stages of Alzheimer’s disease (AD), impairments in semantic memory and the executive component of verbal fluency manifest as language deficiencies characterized by difficulties in initiating speech and slower response times (Appell et al., 1982; Murdoch et al., 1987; Salmon and Chan, 1994; Emery, 2000; Minati et al., 2009; de Looze et al., 2022). As the disease progresses, syntactic and pragmatic language abilities begin to show impairment with speech becoming verbose, circuitous, incoherent, and exhibiting repetition of syllables, words, or sentences (Appell et al., 1982; Kempler et al., 1987; Liampas et al., 2022; Roelofs, 2023). In addition to linguistic deficiencies, research has also identified impairments in speech motor function and changes in the acoustic characteristics of speech in AD, including alterations in voice pitch, prosody, intensity, vocal quality, and speech rate (Hoffmann et al., 2009; Martínez-Sánchez et al., 2012; Sajjadi et al., 2012; Meilán et al., 2014; Cho et al., 2022).
Research on speech-based AD detection has used observable acoustic features in AD patients. For example, López-de-Ipiña analyzed speech recordings from a multilingual database, AZTIAHO, comprised of video recordings of conversation, and built AD classification models with 86.1% accuracy (López-de-Ipiña et al., 2013). Meilán characterized AD patients with 84.8% accuracy using an oral sentence reading task (Meilán et al., 2014). König used speech recordings from multiple speech tasks such as countdown, picture description, sentence repetition, and semantic fluency, to build classification models, achieving 87% accuracy in distinguishing between AD patients and healthy older adults (König et al., 2015). However, previous research has focused less on how speech tasks may effectively reflect the distinctive speech characteristics of AD and more on utilizing accessible speech data from random speech tasks.
It is important to understand the inherent properties of speech tasks, as different speech tasks demand distinct cognitive abilities that may be susceptible to AD pathology or remain intact until the final phase of AD. Recent empirical data and theoretical foundations imply that cognitive loads traditionally thought to be unrelated to speech motor performance may, in fact, have an effect on speech motor performance, as reflected in changes in speech kinematics and acoustic characteristics (Caruso et al., 1994; Dromey and Bates, 2005; Dromey and Shim, 2008; Kemper et al., 2010; Huttunen et al., 2011; Sadagopan and Smith, 2013; Bailey and Dromey, 2015; MacPherson et al., 2017). For example, the cognitive load in the form of divided attention affects speech kinematics, such as lower lip movement pattern variability, articulatory displacement and velocity, and utterance duration (Sadagopan and Smith, 2013; Bailey and Dromey, 2015). Other studies focused on acoustic findings have revealed that the increased cognitive demand is correlated with a decrease in speech rate (Kemper et al., 2010), increased cepstral peak prominence, decreased low-to-high spectral energy ratio (MacPherson et al., 2017), sound pressure level, fundamental frequency, intensity, and the variability of fundamental frequency and intensity (Dromey and Bates, 2005; Dromey and Shim, 2008; Huttunen et al., 2011). Moreover, special populations such as children, older adults, and patients with cognitive impairment, who are assumed to have comparatively smaller cognitive reserves, may be more susceptible to cognitive load-induced changes in speech motor performance (Kamhi et al., 1984; Maner et al., 2000; Prelock and Panagos, 2009; Svindt et al., 2019). Previous investigations have revealed the susceptibility of older adults to increases in cognitive load, exhibiting greater performance costs, such as reductions in fine motor control, disruptions in the stability and timing of speech, and increased articulatory coordination variability (Ramig and Ringel, 1983; Kemper et al., 2010, 2011; Marzullo et al., 2010; Bailey and Dromey, 2015; MacPherson, 2019).
Based on prior research, it is apparent that there are clear associations between cognitive load and speech motor performance. Since AD is characterized by memory impairment, a speech task requiring a high memory load would cause greater changes in the acoustic features of AD patients. Furthermore, it is expected that a speech task with a high memory load will have higher diagnostic value as a speech-based AD detection method, as well as demonstrate superior performance in AD classification and in the MMSE prediction model. In this study, we hypothesized that (1) there are differences in speech characteristics between AD patients and healthy older adults, (2) a high-memory-load speech task makes AD speech characteristics detectable, and (3) a high-memory-load speech task enhances the performance of AD classification and MMSE prediction models.
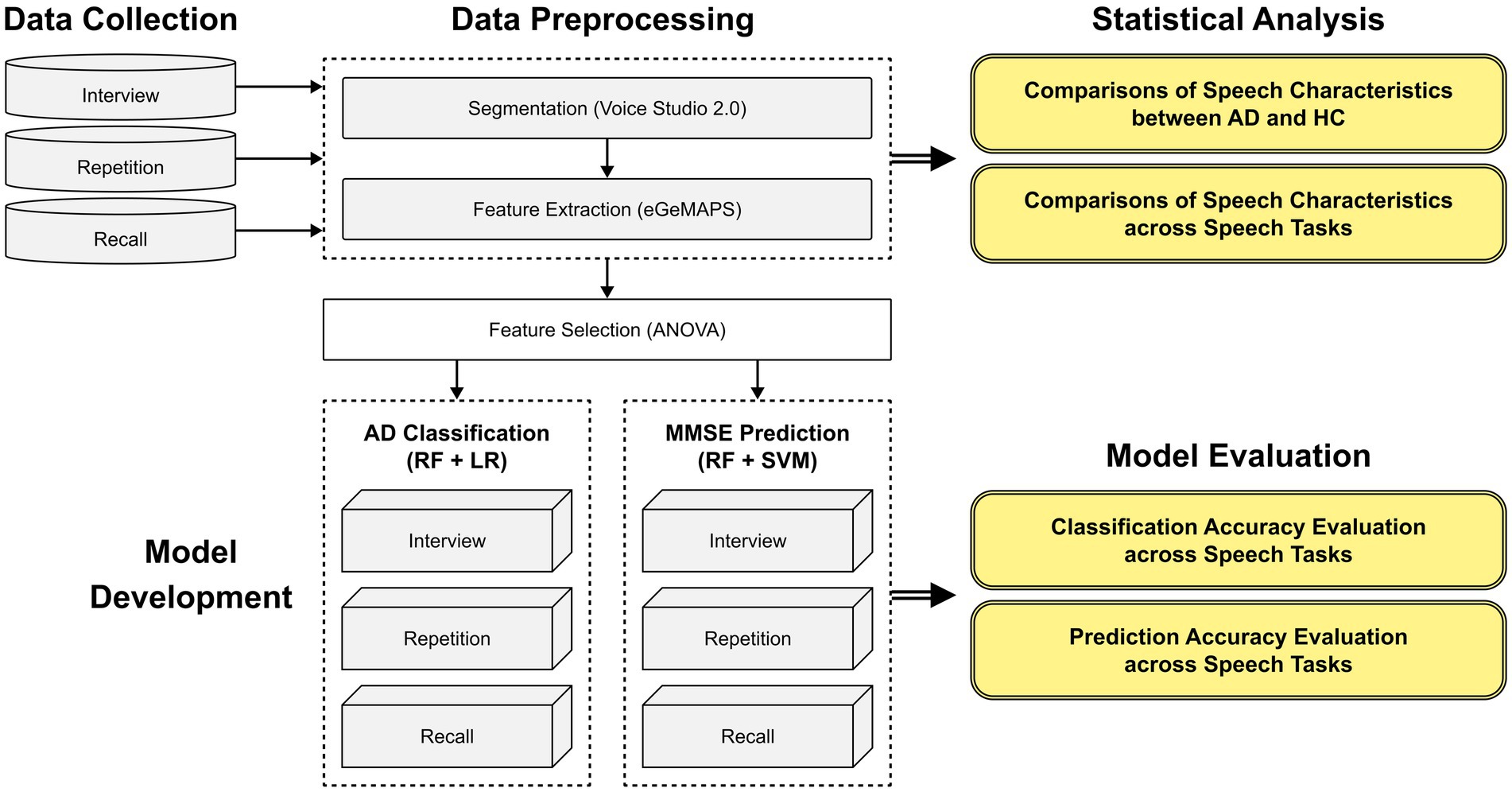
2. Methods 2.1. ParticipantsWe collected speech data from 45 individuals with mild-to-moderate AD and 44 healthy older adults. This study was conducted in accordance with the current Declaration of Helsinki (World Medical Association, 2013). The institutional review board approved the protocol of the SMG-SNU Boramae Medical Center (IRB No. 30–2020-174) and the informed consent was exempted but we obtained the verbal consent. AD patients were recruited from the SMG-SNU Boramae Medical Center. AD was diagnosed by a geriatric psychiatrist using the National Institute of Aging and Alzheimer’s Association (NIA-AA) criteria (Hyman et al., 2012), and subjects suspected or diagnosed with dementia types other than AD were excluded. Healthy older adults were recruited from the local community. They were also screened by a geriatric psychiatrist, and the Mini-Mental State Examination (MMSE) score was 27 or higher for all participants in that group (Cockrell and Folstein, 1988). The MMSE was administered on a different day from the experiment. All participants were (1) between 65 and 85 years of age, (2) native Korean speakers, (3) had no neurological/psychiatric disorder other than AD, (4) had no hearing problem, and (5) volunteered to participate.
The demographics of participants are presented in Table 1. The final data were comprised of 45 individuals with mild-to-moderate AD (number of female participants = 28, mean age = 75.67 ± 4.88, mean education years = 7.24 ± 4.88, mean MMSE score = 16.89 ± 4.27) and 44 healthy older adults (number of female participants = 24, mean age = 75.30 ± 0.80, mean education years = 7.67 ± 5.39, mean MMSE score = 28.95 ± 1.15). There were no significant differences between sex ratio, mean age, and mean education years between groups.
Table 1. Demographics of participants in the dataset.
2.2. Speech taskSpeech tasks were performed over the phone by four well-trained researchers (three researchers with master’s degree in Clinical Psychology and one graduate student in Cognitive Science). Participants were instructed to perform the tasks alone in a silent room so that they would not be interrupted. One call was conducted per each participant. It took about 10 min to conduct three speech tasks. The participants’ responses were recorded as *.m4a sound files and then converted to *.wav sound files.
In this study, three speech tasks with varying memory loads were administered: the interview task, the repetition task, and the recall task. We manipulated the memory load by varying the length of stimuli to be remembered. In the low memory load condition, participants were given the interview task, which consisted of five questions about personal information and daily life activities, to which they were free to respond. In the moderate memory load condition, the repetition task was administered. As the researcher read a sentence aloud to the participants, they were instructed to remember and repeat the sentence as precisely as they could. If a participant was unable to repeat the sentence correctly, the researcher read it aloud again. Stimuli were composed of two sets, and each set included eight sentences. In the high-memory-load condition, the recall task was performed. In this circumstance, the length of items to be remembered increases from one sentence to one paragraph. As a paragraph of the story was presented, participants were asked to recall as many details as possible. The key details of story that are expected to be answered such as the name of the main characters and the main event of the story were defined under the agreement of the researchers before the experiment. If the response was insufficient or lacked key details, the researcher encouraged the participants to elaborate up to two times (e.g., Who else are the characters in the story?, What happened to the main character?). Two stories were given, and each story was composed of eight sentences. One of them was adapted from the Kim’s study (Kim and Sung, 2014).
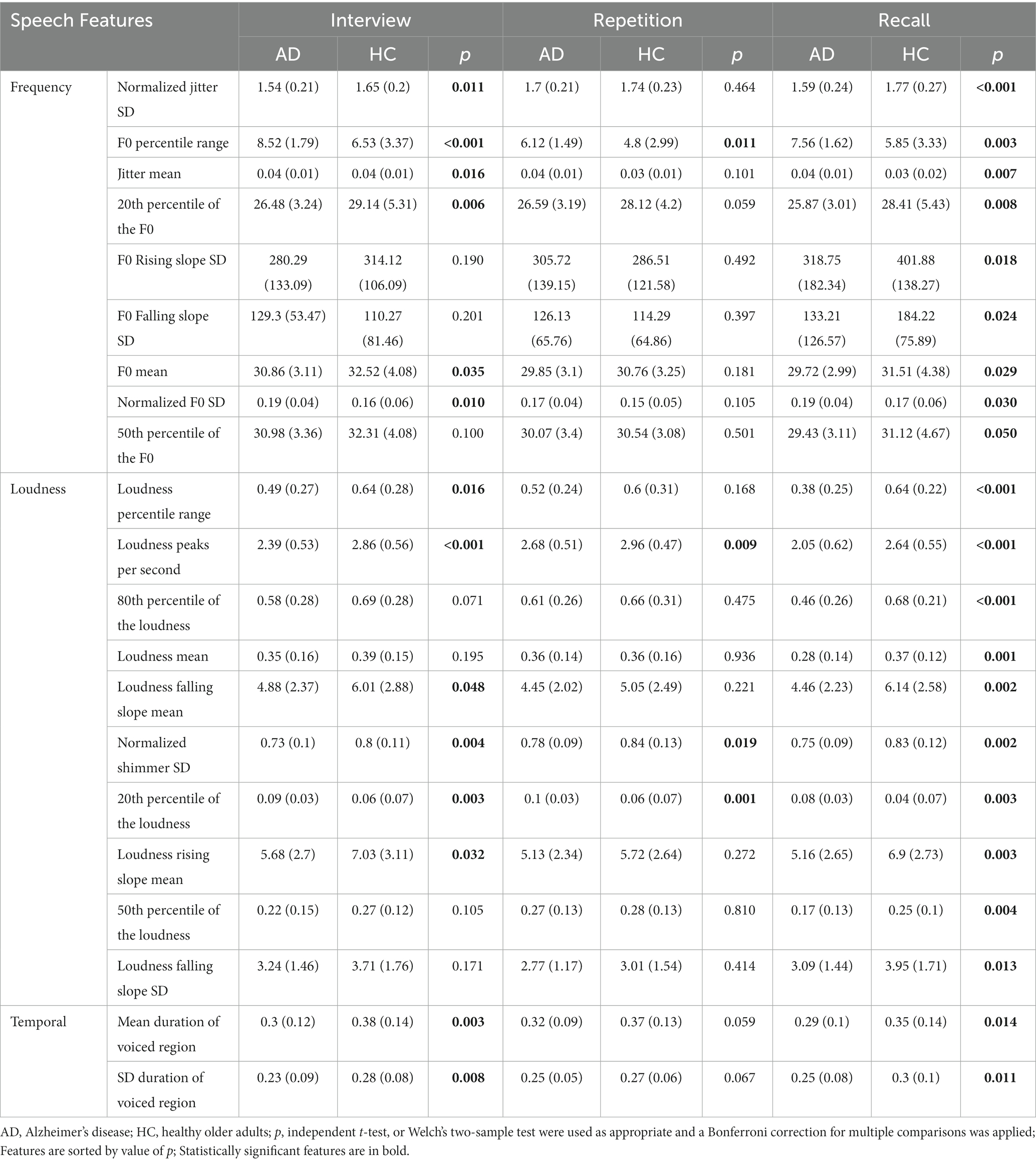
2.3. Data preparationAn experimental scheme of the total study is presented in Figure 1. Rather than the automatic speaker diarization, manual speech segmentation method was employed to eliminate the voice of researchers completely to overcome the speech overlap issue between researchers and participants. Using the open-source software “Voice studio2.0,” the acquired speech samples were segmented into pauses and utterances. Twenty researchers with training in audio segmentation guidelines manually tagged the time stamps of corresponding utterances, while four other researchers evaluated the quality of the time stamp tagging to ensure if the speech of participants was completely included and the speech of researchers was completely removed. Among the 3,831 speech segments, 30 samples were disqualified due to excessive noise or sound distortion.
Figure 1. An experimental scheme of the study.
We extracted the extended Geneva acoustic feature set (eGeMAPS; Eyben et al., 2015) using the Python library and the openSMILE toolkit (Eyben et al., 2010). The eGeMAPS is a minimalistic set of voice parameters that was initially developed to recognize the affective state of a speaker based on the information conveyed by the voice. However, eGeMAPS is now widely used in various areas of speech analysis, particularly in speech-based AD detection (Haider et al., 2019; Pappagari et al., 2021; Valsaraj et al., 2021). The eGeMAPS is utilized in numerous studies because it consists of a standardized, limited set of features that were selected based on their theoretical relevance and ability to analyze an important aspect of speech (Xue et al., 2019). Because eGeMAPS is divided into four parameter groups, namely, frequency-related, intensity-related, temporal, and spectral, it is capable of revealing significant aspects of voice characteristics. Frequency-related features are related to the pitch of speech such as Fundamental Frequency (F0), jitter. Intensity-related features are involved to the amplitude of speech such as loudness, and shimmer. Temporal features are related to the speed of speech such as the duration of speech. Spectral features indicate how much energy is present in the signal at different frequencies such as MFCC, Alpha Ratio, and Hammarberg Index.
2.4. Statistical analysisWe described the demographics of the participants using the independent t test or chi-squared test. We performed an independent two-sample t test or Welch’s two-sample t test to investigate differences in speech characteristics between AD patients and healthy older adults. We conducted a pairwise t test to examine the impact of memory load on the speech characteristics of AD. A two-sided p value of <0.05 was determined to be statistically significant, and a Bonferroni correction for multiple comparisons was applied. All statistical analyses were performed using R version 4.2.1.
2.5. Machine learningIn this study, feature selection was accomplished via analysis of variance (ANOVA) only on the training data. Statistically significant features (p < 0.01) were selected from the original features that were extracted from speech samples to build classification models. Certain features were scaled so that features with large values could not outweigh features with small values. Each dataset from the three speech tasks was split into 70% training data and 30% test data. Due to the segmentation of each participant’s speech data into utterances, the dataset contains multiple speech segments from a single participant. When splitting datasets, we ensured that there were no participant overlaps and that each set maintained a similar class distribution. A weighted voting classifier combining random forest and logistic regression was then used to classify the data. Weights were added to the classifier based on the performance of that classifier so that a classifier that achieved better accuracy was given a higher weight. The hyperparameters were tuned on training data through 10-fold cross-validation, and the resulting model was evaluated on the testing data. To evaluate and compare the performance of different speech tasks, accuracy, precision, sensitivity, specificity, F1-score, and the area under the curve (AUC) were measured.
We built MMSE prediction models using the same methodology as the AD classification models. A weighted voting regressor combining random forest, support vector machine was built. To evaluate and compare the prediction performance of speech tasks, the mean absolute error (MAE), and the root mean square error (RMSE) were calculated. Machine learning was performed using Python version. 3.10.8.
3. Results 3.1. Speech characteristics of ADTo investigate the speech characteristics of AD, frequency, intensity, and temporal features were compared between patients with AD and healthy older adults. While the eGeMAPS includes spectral features, because they are timbral features, it is difficult to gain intuitive insight from them, even if AD patients have spectral features that differ from those of healthy older adults. This is why the present study investigated frequency, intensity, and temporal characteristics to determine the speech characteristics of AD.
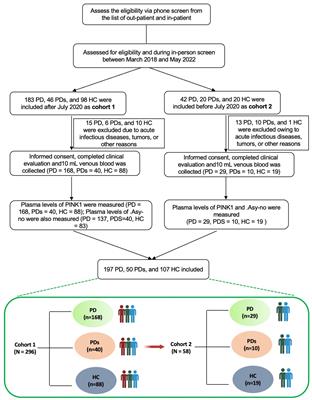
The comparisons of acoustic features between AD patients (AD) and healthy older adults (HC) are summarized in Table 2. First, for the frequency-related features, the mean F0 (AD = 30.14 ± 3.13, HC = 31.6 ± 3.94, p < 0.001), 20th percentile of F0 (AD = 26.31 ± 3.15, HC = 28.55 ± 4.98, p < 0.001), and 50th percentile of F0 (AD = 30.16 ± 3.35, 31.32 ± 4.02, p = 0.011) indicate the pitch of the voice. In all cases, values are lower for AD patients. The F0 percentile range indicates that the F0 range for AD patients was greater (AD = 7.4 ± 1.77, HC = 5.73 ± 3.36, p < 0.001) and high standard deviation of F0 also indicates the higher variability of F0 in AD patients (AD = 0.19 ± 0.04, HC = 0.16 ± 0.06, p < 0.001). AD patients demonstrated a greater degree of jitter (AD = 0.04 ± 0.01, HC = 0.03 ± 0.02, p < 0.001), indicating greater pitch variability. To sum up, frequency-related features indicate that AD patients have lower voice pitch and higher pitch variability compared to healthy older adults.
Table 2. A comparison in acoustic features between patients with AD and healthy older adults.
For AD patients, the 80th percentile of loudness (AD = 0.55 ± 0.27, HC = 0.68 ± 0.28, p < 0.001), 50th percentile of loudness (AD = 0.22 ± 0.14, HC = 0.27 ± 0.12, p = 0.008) and the mean loudness (AD = 0.33 ± 0.14, HC = 0.37 ± 0.14, p = 0.012) were lower. Loudness peaks per second (AD = 2.37 ± 0.57, HC = 2.82 ± 0.59, p < 0.001), loudness percentile range (AD = 0.46 ± 0.25, HC = 0.62 ± 0.28, p < 0.001), loudness falling slope (AD = 4.6 ± 2.25, HC = 5.73 ± 2.64, p < 0.001), and loudness rising slope (AD = 5.33 ± 2.61, HC = 6.55 ± 2.82, p < 0.001), all of which indicating loudness variability, were reduced in AD patients. Intensity-related features indicate that AD patients exhibit diminished loudness and monotonous loudness.
In terms of temporal features, AD patients had a shorter duration of voiced regions (AD = 0.3 ± 0.11, HC = 0.37 ± 0.14, p < 0.001) and a greater number of voiced regions (AD = 2.06 ± 0.4, HC = 1.79 ± 0.82, p < 0.001). This suggests that AD patients had difficulty maintaining speech, spoke at a slower rate, and produced more pauses and hesitations than healthy older adults.
3.2. The effect of memory load on the speech characteristics of patients with ADTo investigate the effect of memory load on the speech characteristics of patients with AD, we divided the dataset according to the applied speech task and conducted an independent t test. Table 3 depicts the speech characteristics across speech tasks that demonstrated statistical significance in at least one of the study tasks. The greatest number of recall task features was reported to be statistically significant (n = 21). In the interview and recall tasks, fourteen and four features, respectively, demonstrated statistical significance.
Table 3. A comparison of speech characteristics between AD patients and healthy older adults across speech tasks.
Regarding frequency-related features, we observed a certain tendency in the speech of AD patients regardless of the speech tasks. In all speech tasks, AD patients demonstrated a lower pitch (e.g., F0 mean, 20th, and 50th percentile of the F0) and greater pitch variability (F0 percentile range, Normalized F0 SD). In the interview and repetition tasks, however, those tendencies were not recognizable enough to report statistical significance; in the recall task, however, the majority of features demonstrated statistical significance. In addition, when we previously analyzed speech features regardless of speech task, there were no significant differences between groups for the F0 rising slope and F0 falling slope. However, after separating the data by speech task, it was discovered that these features were significantly different for the recall task.
In the case of intensity-related features, we also observed a consistent trend regardless of the speech tasks. In all speech tasks, patients with AD exhibited small loudness (loudness mean, 20th, 50th, and 80th percentile of the loudness) and monotonous loudness (loudness percentile range, loudness peaks per second, loudness rising slope, and loudness falling slope). Despite this, the interview and repetition task failed to identify statistically significant differences in the majority of intensity-related features. In the meantime, they were distinguishable enough for statistical significance in the recall task.
In terms of temporal features, the recall task did not show superior discriminability. AD patients exhibited a shorter duration and a higher number of breaks in the interview and the recall task.
3.3. Machine learning performancesThe diagnostic value of the three speech tasks was evaluated, and the results are displayed in Table 4; Figure 2. In Table 4, the performance of the AD classification models is compared. With an accuracy of 81.4%, the recall task outperformed all other speech tasks, including interviews and repetitions. The repetition task achieved the second-highest accuracy of 78.5%, and the interview task achieved 76.1%.
Table 4. A comparison of the performance of AD classification models.
Figure 2. The ROC curves of the recall, repetition, and interview speech tasks. ROC, receiver operating characteristic; AUC, area under the curve.
The recall task demonstrates the highest scores for all other performance analysis metrics, including precision, sensitivity, and F1-score, but specificity, indicating the relative success of AD classification. In particular, the recall task has both high F1-score of 86.5%, indicating an exceptional ability to screen AD patients correctly and not miss AD patients.
Moreover, an analysis was conducted on the Area Under the Curve (AUC) to evaluate the classification performance in distinguishing between classes (see Figure 2). The recall task yielded the highest AUC value of 0.88, while the interview and repetition tasks yielded AUC values of 0.81 and 0.85, respectively.
In the MMSE prediction, we measured MAE, and RMSE, to evaluate the model performances. The performance metrics of various speech task models are displayed in Table 5. The MAE and RMSE are metrics for measuring prediction error which means that the lower the MAE and RMSE, the greater the predictability. With an MAE of 4.62, and RMSE of 5.85, the recall task achieved the best prediction accuracy. With an MAE of 4.89, and RMSE of 6.16, the interview task had the second-best performance.
Table 5. A comparison of the performance of MMSE prediction models.
4. DiscussionThe study’s key findings were as follows: (1) AD patients exhibited speech characteristics that distinguished them from healthy controls; (2) the memory load imposed by the speech task accentuated the speech characteristics of AD; and (3) the speech task with a high memory load enhanced the performance of classification and prediction models for speech-based AD detection.
In this study, we examined the acoustic features of speech in patients with AD and healthy older adults, and investigated how these features change under different speech tasks and memory loads. We found that AD patients had distinct speech characteristics compared to healthy older adults, including a lower pitch, increased pitch variability, decreased loudness, monotonous loudness, and a slower speech rate. The present study’s findings align with those of earlier investigations, which also noted changes in the acoustic characteristics of individuals with AD (Horley et al., 2010; Martínez-Sánchez et al., 2012; Meilán et al., 2012, 2014). However, there was a disparity in regards to the frequency-related characteristics of AD. Previous studies found a higher pitch associated with AD, which is inconsistent with the current study’s results (Martínez-Sánchez et al., 2012; Meilán et al., 2014). We posit that this inconsistency is attributable to the disparate sex ratios of study participants (the proportion of female patients = 62.2% in this study; the proportion of female patients = 68% in Meilán’s study; and the proportion of female patients = 84% in Martínez-Sánchez’s study). As sex is among the most influential physiological factors affecting pitch (Puts et al., 2012), and the effects of cognitive decline and aging on speech features vary according to sex, accounting for the sex ratio of participants is critical when comparing the frequency-related features of diverse studies. Consequently, previous studies with a comparably higher female ratio than the current study yielded opposing results. Collectively, the results of the current study validate that speech’s acoustic features are associated with AD and specify how these features change, suggesting a basis for speech-based AD detection in clinical settings.
This study also demonstrated that the speech characteristics of Alzheimer’s Disease (AD) can be accentuated when a high memory load is imposed. Specifically, our findings indicate that the acoustic features of speech in AD can vary in prominence depending on the speech task, with the recall task, which involves a high memory load, eliciting the most noticeable differences. These results corroborate prior studies that have established a relationship between cognitive load and alterations in the acoustic features of speech. Previous investigations have shown that cognitive load can modify speech acoustics and that cognitively impaired individuals, including older adults, are particularly vulnerable to these effects, leading to more pronounced changes in speech characteristics (Ramig and Ringel, 1983; Kemper et al., 2010, 2011; Marzullo et al., 2010; Bailey and Dromey, 2015; MacPherson, 2019). This phenomenon can be explained by the cognitive “supply and demand” model (Seidler et al., 2010), whereby an imbalance between available cognitive resources and the cognitive demands of a task leads to greater alterations in speech motor performances and acoustic features. Temporal features, however, appear to be less affected by memory load than frequency and intensity-related features. Numerous studies have reported that a slower speech rate is the most characteristic speech trait of AD (Hoffmann et al., 2009; Martínez-Sánchez et al., 2012, 2013; Meilán et al., 2012, 2014). As a slower speech rate is one of the most recognizable acoustic features of AD, we believe it was observed to be less task-dependent. In other words, among the various speech characteristics of AD, some features are consistently distinct and not task-dependent, whereas others can be observable or unobservable depending on the context. Therefore, to induce and effectively capture the latter, we must impose a heavy memory load; consequently, cognitive struggles of AD patients can manifest as changes in the acoustic features of speech.
Last, the current investigation revealed that a speech task with a high-memory-load can improve the performance of AD classification and MMSE prediction models. We conducted a comparative analysis of the performance of AD classification and MMSE prediction models, utilizing speech data obtained from three speech tasks that varied in their memory loads. The recall task with a high memory load outperformed the other tasks in both the AD classification and MMSE prediction models that other tasks with less memory load. Few studies have compared the performance of speech tasks and evaluated their potential, and a recent study found that the recall task achieved the best classification performance using linguistic features (Clarke et al., 2021). Our study provides evidence that recall tasks employing acoustic features can effectively perform in both AD classification and MMSE prediction. It is conceivable that the acoustic features of AD, which were accentuated by the high memory load of the recall task, could increase the variability in speech characteristics between groups and facilitate their classification and prediction. Based on the obtained results, we conclude that the recall task has practical implications as a speech-based AD detection tool.
This research has a number of limitations. One limitation is the small sample size, with speech data collected from only 45 AD patients and 44 healthy controls. This limited dataset size may constrain the ability to achieve improved classification and model performance. Also, the current study conducted only one call per participant which is not free from the fluctuations in the cognitive performance of patients. Hence, building larger datasets with more participants and repeated conduction of the experiment may allow for the enhancement of classification and prediction performances and the reliability of results. Another limitation of this research is that the acoustic features were extracted using an existing conventional feature set, eGeMAPS. While eGeMAPS comprises standardized features with a robust theoretical foundation and is widely used in speech-based AD detection, it may not be the optimal feature set to describe the AD voice, as it was initially designed to identify the emotional states of a speaker. Therefore, in future studies, it is critical not only to identify the optimal speech task but also to develop an appropriate acoustic feature set that accurately characterizes the AD voice. Another limitation is that the current study provides limited explanation between the speech features and the memory load. We observed that the differences in speech features between AD patients and healthy older adults accentuated in the recall task with high memory load and it possibly led to the excellent AD classification performance and MMSE prediction performance of the recall task. Yet, a clinically valid explanation which connects the speech characteristics of AD patients and the memory load is still lacking. Hence, in the future study, the associations between speech features and the cognitive function or brain structures should be identified to provide clinical validity as an AD detection method to the speech features and the memory load.
Otherwise, this study highlights the significance of utilizing appropriate speech tasks for accurate and efficient speech-based AD detection. Our findings demonstrate that a recall task with a high memory load can effectively reveal the speech characteristics of AD, leading to improved AD classification and MMSE prediction. Given the practicality and limited availability of data and time in the real-world setting, an efficient speech-based AD detection tool must accurately detect AD with minimal resources. The use of memory load in speech tasks is shown to be advantageous in achieving effective speech-based AD detection, as it enhances the speech characteristics of AD and improves detection accuracy. Hence, rather than the combination of various speech tasks like previous studies, the compact method with high-memory-load speech task would allow the efficient and less demanding speech-based AD detection for patients and clinicians.
In addition, this study benefits from the utilization of acoustic features in speech analysis. Unlike linguistic features, which are limited to specific language properties and contexts, acoustic features serve as language-universal markers with broader applicability. Our research, based on acoustic features, allows for more generalizable findings that can be applied to various linguistic contexts.
In future research, it is important to seek neuroscientific evidence to support speech-based AD detection. While it is clear that AD patients exhibit changes in acoustic features of their speech, the neural mechanisms underlying these alterations are not yet well-understood. Thus, future investigations should explore the neural correlates of AD speech characteristics to provide clinical validity to speech-based AD detection. By elucidating the neural underpinnings of AD speech features, we can gain a better understanding of the AD and develop more accurate and effective diagnostic tools.
Data availability statementThe raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statementThe studies involving human participants were reviewed and approved by the SMG-SNU Boramae Medical Center. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Author contributionsJ-YL, HK, and MB conceived and designed the study. MB, M-GS, and HH acquired the data. MB analyzed the data and wrote the manuscript. J-YL, KK, and MB interpreted the data. All authors have read and agreed to the published version of the manuscript.
FundingThis research was funded by the Ministry of Education through the National Research Foundation of Korea (NRF), grant number (NRF-2021R1A2C2095809).
AcknowledgmentsWe would like to thank the reviewers for their time and constructive comments.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesAppell, J., Kertesz, A., and Fisman, M. (1982). A study of language functioning in Alzheimer patients. Brain Lang. 17, 73–91. doi: 10.1016/0093-934x(82)90006-2
CrossRef Full Text | Google Scholar
Bailey, D. J., and Dromey, C. (2015). Bidirectional interference between speech and nonspeech tasks in younger, middle-aged, and older adults. J. Speech Lang. Hear. Res. 58, 1637–1653. doi: 10.1044/2015_jslhr-s-14-0083
CrossRef Full Text | Google Scholar
Caruso, A. J., Chodzko-Zajko, W. J., Bidinger, D. A., and Sommers, R. K. (1994). Adults who stutter responses to cognitive stress. J. Speech Lang. Hear. Res. 37, 746–754. doi: 10.1044/jshr.3704.746
CrossRef Full Text | Google Scholar
Cho, S., Cousins, K. A. Q., Shellikeri, S., Ash, S., Irwin, D. J., Liberman, M. Y., et al. (2022). Lexical and acoustic speech features relating to Alzheimer disease pathology. Neurology 99, e313–e322. doi: 10.1212/wnl.0000000000200581
CrossRef Full Text | Google Scholar
Clarke, N., Barrick, T. R., and Garrard, P. (2021). A comparison of connected speech tasks for detecting early Alzheimer’s disease and mild cognitive impairment using natural language processing and machine learning. Front. Comput. Sci. 3:634360. doi: 10.3389/fcomp.2021.634360
CrossRef Full Text | Google Scholar
Cockrell, J. R., and Folstein, M. F. (1988). Mini-mental state examination (MMSE). Psychopharmacol. Bull. 24, 689–692.
PubMed Abstract | Google Scholar
de Looze, C., Dehsarvi, A., Suleyman, N., Crosby, L., Hernández, B., Coen, R. F., et al. (2022). Structural correlates of overt sentence Reading in mild cognitive impairment and mild-to-moderate Alzheimer’s disease. Curr. Alzheimer Res. 19, 606–617. doi: 10.2174/1567205019666220805110248
PubMed Abstract | CrossRef Full Text | Google Scholar
Dromey, C., and Shim, E. (2008). The effects of divided attention on speech motor, verbal fluency, and manual task performance. J. Speech Lang. Hear. Res. 51, 1171–1182. doi: 10.1044/1092-4388(2008/06-0221)
PubMed Abstract | CrossRef Full Text | Google Scholar
Eyben, F., Scherer, K. R., Schuller, B. W., Sundberg, J., Andre, E., Busso, C., et al. (2015). The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput.. 7, 190–202. ACM. doi: 10.1109/taffc.2015.2457417
CrossRef Full Text | Google Scholar
Eyben, F., Wöllmer, M., and Schuller, B. (2010). Opensmile: the Munich versatile and fast open-source audio feature extractor. Proceedings of the 9th ACM International Conference on Multimedia, MM. 1459.
Haider, F., Fuente, S. d. l., and Luz, S. (2019). An assessment of paralinguistic acoustic features for detection of Alzheimer’s dementia in spontaneous speech. IEEE J. Sel. Top. Signal Process. 14, 272–281. doi: 10.1109/jstsp.2019.2955022
CrossRef Full Text | Google Scholar
Hoffmann, I., Nemeth, D., Dye, C. D., Pákáski, M., Irinyi, T., and Kálmán, J. (2009). Temporal parameters of spontaneous speech in Alzheimer’s disease. Int. J. Speech lang. Pathol. 12, 29–34. doi: 10.3109/17549500903137256
PubMed Abstract | CrossRef Full Text | Google Scholar
Horley, K., Reid, A., and Burnham, D. (2010). Emotional prosody perception and production in dementia of the Alzheimer’s type. J. Speech Lang. Hear. Res. 53, 1132–1146. doi: 10.1044/1092-4388(2010/09-0030)
PubMed Abstract | CrossRef Full Text | Google Scholar
Huttunen, K. H., Keränen, H. I., Pääkkönen, R. J., Eskelinen-Rönkä, R. P., and Leino, T. K. (2011). Effect of cognitive load on articulation rate and formant frequencies during simulator flights. J. Acoust. Soc. Am. 129, 1580–1593. doi: 10.1121/1.3543948
PubMed Abstract | CrossRef Full Text | Google Scholar
Hyman, B. T., Phelps, C. H., Beach, T. G., Bigio, E. H., Cairns, N. J., Carrillo, M. C., et al. (2012). National Institute on Aging–Alzheimer’s association guidelines for the neuropathologic assessment of Alzheimer’s disease. Alzheimers Dement. 8, 1–13. doi: 10.1016/j.jalz.2011.10.007
CrossRef Full Text | Google Scholar
Kemper, S., Hoffman, L., Schmalzried, R., Herman, R., and Kieweg, D. (2011). Tracking talking: dual task costs of planning and producing speech for young versus older adults. Neuropsychol. Dev. Cogn. B Aging Neuropsychol. Cogn. 18, 257–279. doi: 10.1080/13825585.2010.527317
PubMed Abstract | CrossRef Full Text | Google Scholar
Kim, H., and Sung, J. E. (2014). Age-related changes in story retelling procedures and their relation to working memory capacity. Special Educ. Res. 13:7. doi: 10.18541/ser.2014.10.13.3.7
CrossRef Full Text | Google Scholar
König, A., Satt, A., Sorin, A., Hoory, R., Toledo-Ronen, O., Derreumaux, A., et al. (2015). Automatic speech analysis for the assessment of patients with predementia and Alzheimer’s disease. Alzheimer’s Dement. 1, 112–124. doi: 10.1016/j.dadm.2014.11.012
CrossRef Full Text | Google Scholar
Liampas, I., Folia, V., Morfakidou, R., Siokas, V., Yannakoulia, M., Sakka, P., et al. (2022). Language differences among individuals with normal cognition, amnestic and non-amnestic MCI, and Alzheimer’s disease. Arch. Clin. Neuropsychol. 38, 525–536. doi: 10.1093/arclin/acac080
PubMed Abstract | CrossRef Full Text | Google Scholar
López-de-Ipiña, K., Alonso, J.-B., Travieso, C. M., Solé-Casals, J., Egiraun, H., Faundez-Zanuy, M., et al. (2013). On the selection of non-invasive methods based on speech analysis oriented to automatic Alzheimer disease diagnosis. Sensors 13, 6730–6745. doi: 10.3390/s130506730
PubMed Abstract | CrossRef Full Text | Google Scholar
MacPherson, M. K. (2019). Cognitive load affects speech motor performance differently in older and younger adults. J. Speech Lang. Hear. Res. 62, 1258–1277. doi: 10.1044/2018_jslhr-s-17-0222
PubMed Abstract | CrossRef Full Text | Google Scholar
MacPherson, M. K., Abur, D., and Stepp, C. E. (2017). Acoustic measures of voice and physiologic measures of autonomic arousal during speech as a function of cognitive load. J. Voice 31, 504.e1–504.e9. doi: 10.1016/j.jvoice.2016.10.021
PubMed Abstract | CrossRef Full Text | Google Scholar
Maner, K. J., Smith, A., and Grayson, L. (2000). Influences of utterance length and complexity on speech motor performance in children and adults. J. Speech Lang. Hear. Res. 43, 560–573. doi: 10.1044/jslhr.4302.560
PubMed Abstract | CrossRef Full Text | Google Scholar
Martínez-Sánchez, F., Meilán, J. J. G., García-Sevilla, J., Carro, J., and Arana, J. M. (2013). Oral reading fluency analysis in patients with Alzheimer disease and asymptomatic control subjects. Neurología 28, 325–331. doi: 10.1016/j.nrleng.2012.07.017
PubMed Abstract | CrossRef Full Text | Google Scholar
Martínez-Sánchez, F., Meilán, J. J. G., Pérez, E., Carro, J., and Arana, J. M. (2012). Expressive prosodic patterns in individuals with Alzheimer’s disease. Psicothema 24, 16–21.
PubMed Abstract | Google Scholar
Marzullo, A. C. d. M., Neto, O. P., Ballard, K. J., Robin, D. A., Chaitow, L., and Christou, E. A. (2010). Neural control of the lips differs for young and older adults following a perturbation. Exp. Brain Res. 206, 319–327. doi: 10.1007/s00221-010-2411-3
PubMed Abstract | CrossRef Full Text | Google Scholar
Meilán, J. J. G., Martínez-Sánchez, F., Carro, J., López, D. E., Millian-Morell, L., and Arana, J. M. (2014). Speech in Alzheimer’s disease: can temporal and acoustic parameters discriminate dementia? Dement. Geriatr. Cogn. 37, 327–334. doi: 10.1159/000356726
PubMed Abstract | CrossRef Full Text | Google Scholar
Meilán, J. J. G., Martínez-Sánchez, F., Carro, J., Sánchez, J. A., and Pérez, E. (2012). Acoustic markers associated with impairment in language processing in Alzheimer’s disease. Span. J. Psychology. 15, 487–494. doi: 10.5209/rev_sjop.2012.v15.n2.38859
PubMed Abstract | CrossRef Full Text | Google Scholar
Minati, L., Edginton, T., Bruzzone, M. G., and Giaccone, G. (2009). Reviews: current concepts in Alzheimer’s disease: a multidisciplinary review. Am. J. Alzheimer’s Dis. Other Demen. 24, 95–121. doi: 10.1177/1533317508328602
CrossRef Full Text | Google Scholar
Murdoch, B. E., Chenery, H. J., Wilks, V., and Boyle, R. S. (1987). Language disorders in dementia of the Alzheimer type. Brain Lang. 31, 122–137. doi: 10.1016/0093-934x(87)90064-2
CrossRef Full Text | Google Scholar
Pappagari, R., Cho, J., Joshi, S., Moro-Velázquez, L., Żelasko, P., Villalba, J., et al. (2021). Automatic detection and assessment of Alzheimer disease using speech and language technologies in low-Resource Scenarios. Interspeech 2021, 3825–3829. doi: 10.21437/interspeech.2021-1850
留言 (0)