
記住我
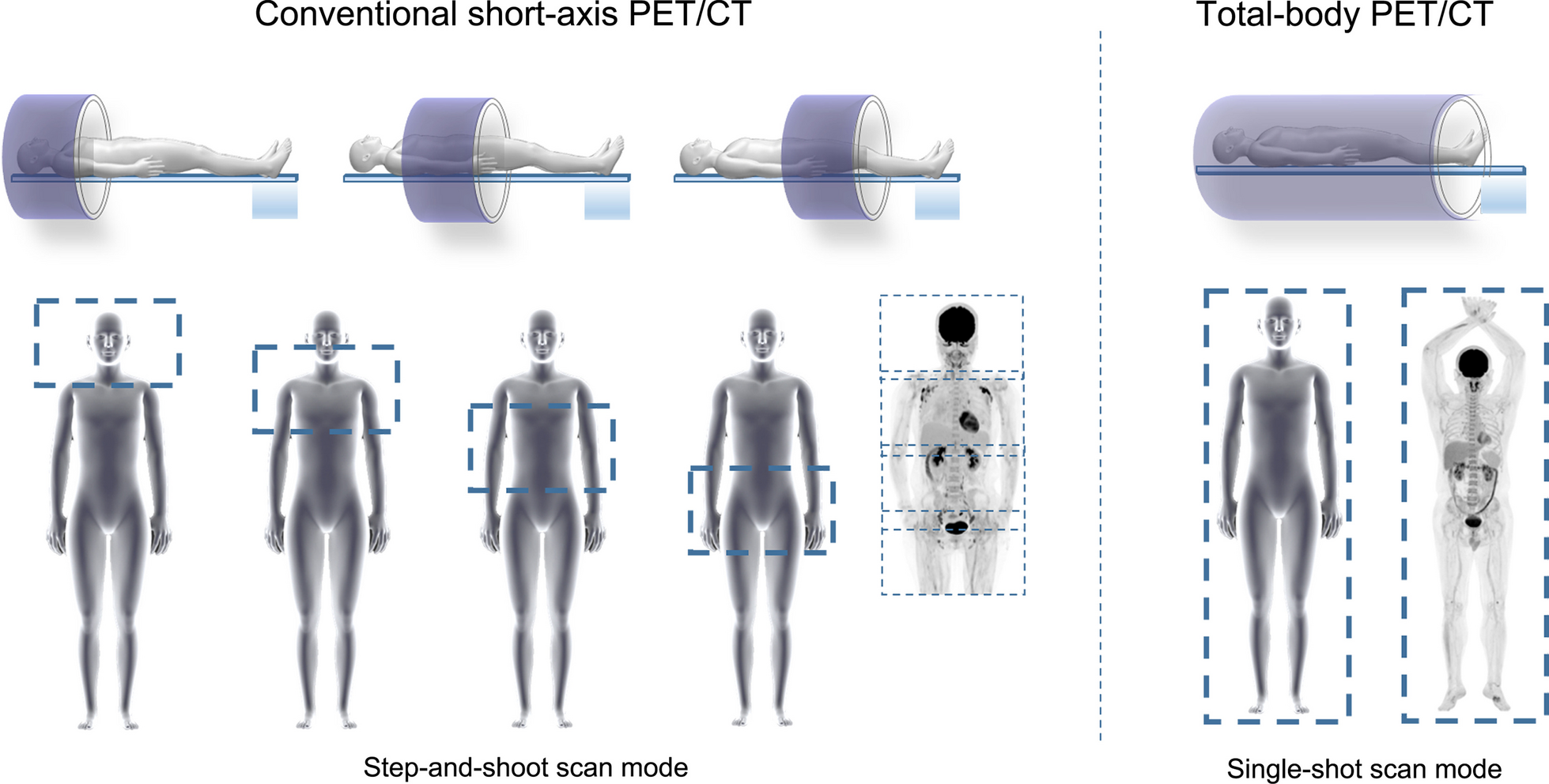
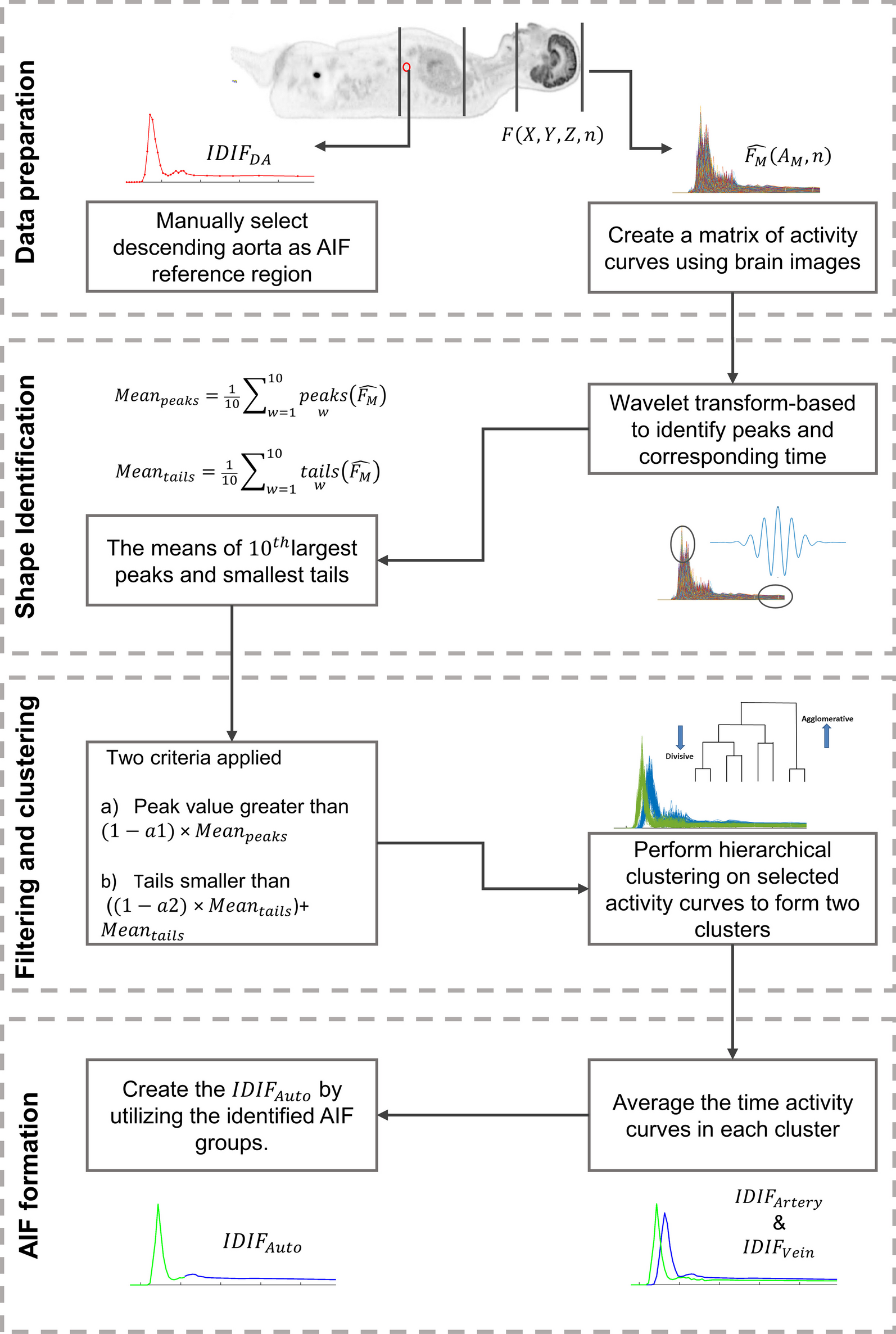
Figure 1 presents the schematic workflow of the proposed deep learning (DL) model based on PET/CT for pathological grading of patients with PDAC, which consists of multiple processing stages. Below, we elaborate the details related to the workflow, starting with study population, image labeling, model construction, and finally model testing.
Fig. 1
The workflow of DL model based on PET/CT for pathological grading of patients with pancreatic ductal adenocarcinoma (PDAC)
Study populationPatients who underwent pancreatic surgery at the PLA General Hospital from January 2016 to September 2021 and obtained pathological confirmation of PDAC were collected and included in the study according to the inclusion and exclusion criteria, and 370 patients were finally included.
Inclusion criteria: (i) PDAC was pathologically confirmed by radical pancreatic resection; (ii) PDAC was confirmed by pathological biopsy of non-radical pancreatic surgery; (iii) PET/CT of the pancreas was performed within 1 month before surgery. Exclusion criteria: (i) patients had adjuvant treatment such as radiotherapy, chemotherapy and intervention before surgery; (ii) PET/CT images were of poor quality (tumor and borders could not be distinguished with the naked eye or there were artifacts interfering) and could not be used to analyze patients; (iii) other malignant tumors were combined; (iv) pathological findings and images could not correspond. Clinical data such as a patient’s age, gender, preoperative CA199 level, tumor location, tumor size (long and short diameter) on PET/CT images, and SUVmax values were also collected.
PET-CT image labeling processSupplementary Method 1.1 provides detailed information about the PET/CT scanning protocol. The regions of abnormal 18F-FDG uptake on PET and density abnormality on CT are localized as the lesion region as follows. After the PET/CT image fusion is completed, two experienced PET/CT diagnostic physicians use 3D slicers (version 5.1.0, https://www.slicer.org) software with a threshold of 40% SUVmax to draw out the ROI (Region of Interest) of the target lesion, and all discrepancies are confirmed through discussion. All images were analyzed by two senior nuclear medicine experts (each with over 5 years of experience in PET interpretation). The analysis included aspects such as tumor lesion location, size, standard uptake value (SUVmax), relationship with surrounding tissues, liver mean standard uptake value (SUVmean), SUVR (tumor-to-normal liver standard uptake value ratio, SUVmax of the tumor /SUVmean of the normal liver parenchyma), presence of lymph node metastasis, presence of distant metastasis, and observations under various sequences.
The patients' 18F-FDG PET/CT scans were obtained from three different machines. Consequently, measurements of metabolic parameters may exhibit variations due to differences in machine design and scintillation detectors [18,19,20]. We cannot exclude that such differences may have at least in part confounded SUVmax measurements. To address this problem, we retrospectively calculated the mean SUV values of hepatic parenchyma in 370 patients with original PET/CT images (GE Discovery VCT, n = 161; Siemens Biography 64 PET/CT, n = 166; uMI 510 PET/CT, n = 43). To measure normal liver parenchyma activity, 3 non-overlapping spherical 1-cm3-sized VOIs were drawn in the normal liver on the axial PET images. There were no significant differences in terms of SUVmean-liver among the 3 PET/CT scanners (GE Discovery VCT, 2.30 ± 0.48 vs. Siemens Biograph 64, 2.28 ± 0.38 vs. uMI 510, 2.35 ± 0.29, respectively; F = 0.407, p = 0.666, variance analysis).
Constructing the lesion segmentation modelThe whole process of building the deep model for lesion segmentation is shown in Fig. 1A. 100 cases of annotated PET/CT images of pancreatic cancer were input into the segmentation model for training.
The PET-CT images were first pre-processed: (a) Window width and window level (350, 40) were applied to intercept the gray value; (b). Each pair of 3D CT series (512*512*HCT) and 3D PET series (of size 96*96*HPET, 128*128*HPET, 168*168*HPET, 170*170*HPET) were uniformly resized to 256*256*HPET; (c) For each slice, the gray scale was normalized [0,1]; (d) 3 PET slices and 3 CT slices centered around the corresponding location form a 6-channel input to the model.
Model construction: The 6-channel input has a PET part and a CT part, each fed into a 2D-Unet network branch with no shared parameters. The feature vectors of the two 2D-Unets are then concatenated to pass through convolutions, which output the final lesion segmentation mask (Additional file 1: Fig.S1.). We employed a batch size of 8 and early stopping for choosing the best training step. The learning rate was set to 1 × 10–5, and the parameters were updated using the Adam optimiser.
Post-processing the segmentation result: (a) All slices in a patient case were predicted and combined into a complete 3D mask; (b) A pre-trained nnUnet [21] model of organ segmentation was loaded to provide a coarse segmentation of the abdominal organs. The predicted segmentation of nnUnet gave the location of pancreas. It was used to reduce the wrong segmentation in other organs when fused with the pancreatic tumor segmentation results from 2D-Unettumor; (c) Medical image analysis techniques including erosion, expansion, and SUVmax 40% threshold segmentation are further applied to obtain the final lesion segmentation results.
Building PDAC pathological grade classification modelsDue to the low prevalence of pathological samples with extreme pathological differentiation grades in the clinic, the grades with few samples were merged in this study and all samples were set to two predictive labels: low grade or high grade. Highly, moderate-highly, and moderately differentiated pathologies were defined as low grade; undifferentiated, lowly, and moderate-lowly differentiated were defined as high grade (Additional file 1: Fig. S2.). This is similar to the classification method of Wasif and Rochefort et al. [22, 23]
According to the segmentation result, the lesion regions were cropped out of the 3D data of PET, CT, and segmentation Mask, respectively, and three aligned copies of size 64*64*16 (length*width*height) were obtained. The CT data were intercepted with a window width and window level (350, 40) and normalized to [0,1], and the PET data were normalized to [0,1]. The PET/CT, cropped according to segmentation mask, were concatenated in the channel dimension to obtain a tensor of size 2*64*64*16 (number_of_channels*length*width*height). The tensor was fed into a Unet3D-based Encoder to extract image feature vectors as shown in Fig. 1B. The overall network model structure diagram is provided in Additional file 1: Fig. S3.
Cases with clinical data missing ratios greater than 20% were excluded from our study. A total of 21 clinical variables were collected to build predictive models based on clinical experience and literature reports. Subsequently, the individual clinical data were analyzed for significance using the Random Forest method (Additional file 1: Fig.S4.). Eleven important clinical characteristics including age, BMI, SUVmax, ALT, AST, total bilirubin, direct bilirubin, blood glucose, CEA, CA125 and CA199 were kept. Finally, the clinical data feature vectors were extracted using the MLP through the multi-layer perceptron. The part was shown in Fig. 1C, D.
Both image features and clinical data features can be used to obtain prediction results for their respective modalities through the fully connected (FC) layer. To obtain better prediction performance, we replaced the last FC layer with a TMC (Trusted Multi-view Classification) [24] to integrate image features and clinical data features and constructed a PET/CT + Clinical data model. TMC is a new multi-view classification algorithm that dynamically integrates different views at an evidence level to promote classification reliability by considering evidence from each view (Additional file 1: Method 1.2). The learning rate was set to 1 × 10–5, and the parameters in the feature extractor were updated using the Adam optimiser.
Sevenfold cross-validation for model testingWe used a sevenfold cross-validation to better evaluate the generalization ability of the model. This is shown in Fig. 2. We divided 370 patients into 7 folds, of which 5 folds were the training set for the model in each training round, onefold was the internal validation set and onefold was used as the test set to test the final performance of the model. The next round was trained by changing the order of the training, validation and test folds. The final model is obtained by averaging the results of the 7 folds.
Fig. 2
Sevenfold cross-validation model
Statistical analysisThe clinical data were statistically processed using SPSS 22.0 statistical analysis software: normally distributed measures were expressed as x ± s and comparisons between groups were made using the student-t test. Skewed measures were expressed as median (range), and comparisons of count data were made using the X^2 test or Fisher's exact probability method.
Dice score was used to evaluate the pancreatic lesion segmentation model. Accuracy, sensitivity, and specificity of the test dataset results were calculated using receiver operator characteristic curve (ROC) for the classification models. p values less than 0.05 were considered statistically significant.
留言 (0)