

記住我









Efficient processing of information is a core capacity of the brain. It enables us to perceive rapidly, comprehend, identify changes, and engage with our environment—sometimes even without conscious effort. Accordingly, in attempting to understand the underlying brain mechanisms responsible for these capacities, it is useful to employ approaches that originate from information theory. This mathematical theory provides multivariate analysis tools, is not bound to a single type of data, is model-independent (i.e., does not require assumptions about the data itself), and can capture nonlinear interactions (Li and Vitányi, 2008; Ince et al., 2017; Timme and Lapish, 2018; Piasini and Panzeri, 2019). Specifically, by measuring the degree of redundancy, the branch of algorithmic information theory (AIT) estimates the absolute information contained in individual brain responses. The higher the information content, the more complex its structure. Accordingly, the less compressible or more random the response (Li and Vitányi, 2008). Assessing the absolute information content of responses recorded from different contact sites enables inferring the complexity of the activity recorded at the respective sensors and potentially identification of underlying dynamics.
Hence, principles from information theory can be utilized for the analysis of neurophysiological recordings originating from scalp electroencephalography (EEG), intracranial EEG (iEEG), magnetoencephalography (MEG), or functional magnetic resonance imaging (fMRI). While information theory-based metrics have been employed to advance our understanding of brain processes, direct comparisons with well-established metrics or demonstrations of their easy applicability are highly needed. More specifically, AIT has been applied to analyses of task-related cognitive operations or to discriminate between states of consciousness measured with EEG, iEEG, MEG, or fMRI recordings (Sitt et al., 2014; Schartner et al., 2015, 2017; Canales-Johnson et al., 2020; Fuhrer et al., 2021), however, its use in neuroscience has been limited despite its clear potential.
Here, we carry out such a comparison and demonstrate the AIT-based measure of encoded information (EI; Fuhrer et al., 2022) as an advantageous tool to directly quantify the level of similarity between responses of neurophysiological data across experimental conditions. We do so by analyzing iEEG recordings stemming from 34 humans (Blenkmann et al., 2019; Llorens et al., 2022) and three marmoset monkeys (Komatsu et al., 2015; Canales-Johnson et al., 2021) which were exposed to passive and active paradigms as well as auditory or visual stimuli. We compare the performance of encoded information with that of a conventional t-test, Mutual Information (MI), Gaussian Copula Mutual Information (GCMI; Ince et al., 2017), or Neural Frequency Tagging (NFT; Picton et al., 2003; Norcia et al., 2015) considering the signal band-pass power time series of theta (5 to 7 Hz), alpha (8 to 12 Hz), beta (12 to 24 Hz), high-frequency (HFA; 75 to 145 Hz), and event-related potential (ERP).
2. Materials and methods 2.1. Test paradigms and neurophysiological recordingsTo evaluate the methods, we examined their sensitivity to discriminate experimental conditions from three different neurophysiological data sets. Two of these used auditory stimuli and one used visually presented stimuli. We focused our analysis on the cortical representation of theta, alpha, beta, HFA, and ERP band-pass power time series.
2.1.1. Extraction of band-pass power time seriesData were low-pass filtered at 30 Hz using a sixth-order Butterworth filter to obtain the ERPs. Theta, alpha, and beta frequency bands were extracted from the demeaned signals using wavelet time-frequency transformation (Morlet wavelets) based on convolution in the time domain (Oostenveld et al., 2011). Wavelets of 3, 3, or 5 oscillations were used to extract respective frequencies bands [theta (5 to 7 Hz), alpha (8 to 12 Hz), and beta (12 to 24 Hz)] in steps of 1 Hz. All trials were then baseline corrected by subtracting the mean amplitude of the baseline period of each trial and frequency band from the entire trial (see respective sections for the different data sets for the used baseline intervals).
To extract the HFA, the pre-processed data were filtered into eight bands of 10 Hz ranging from 75 to 145 Hz by use of bandpass filters. Next, the instantaneous amplitude signal of each filtered signal was computed by applying a Hilbert transform to the filtered time series leading to the analytic signal (Foster et al., 2016), constituting a complex-valued time series. The analytic amplitude time series or signal envelope corresponding to specific frequency bands was then obtained using Pythagoras' Theorem. To obtain one time series across all eight frequency bands, their mean amplitude value was calculated. As the last step, the respective time series were normalized by dividing them by a mean baseline period computed from all trial recordings. This resulted in a normalized measure relative to the baseline activity and termed HFA.
To eliminate any residual artifacts not rejected by visual inspection, responses with an amplitude larger than five standard deviations from the mean for more than 25 consecutive ms, or with a power spectral density above five standard deviations from the mean for more than six consecutive Hz were excluded.
2.1.2. Optimum-1 paradigmWe analyzed experimental iEEG data obtained from intracranial electrodes implanted in (self-reported) normal-hearing adults with drug-resistant epilepsy. Analyses of this data have been previously presented in Blenkmann et al. (2019) and Fuhrer et al. (2021, 2022). Participants (n = 22, mean age 31 years, range 19 to 50 years, 6 female) performed a passive auditory oddball paradigm where a standard tone alternated with random deviant tones. The tones had a duration of 75 ms and were presented every 500 ms in blocks of 5 min consisting of 300 standards and 300 deviants. At the beginning of each block, 15 standards were played. To capture automatic, stimulus-driven processes, participants were asked not to pay attention to the sounds while reading a book or magazine. They completed 3 to 10 blocks, providing at least 1,800 trials (for details, see Blenkmann et al., 2019; Fuhrer et al., 2022). From the 22 participants, a total of 1078 channels (mean: 48, range: 12 to 104) were available after data cleaning. Data were then segmented into 2000 ms epochs (750 ms before and 1250 ms after tone onset) and demeaned. The different band-pass power time series were then extracted. For each time series, differences between standard and deviant tone responses were then evaluated in the 400 ms time window following the sound onset across channels and subjects. The baseline window was from −100 to 0 ms relative to tone onset. Additionally, for this data set the neural oscillation synchronization to the tone onset frequency (2 Hz) and the frequency for standard and deviant tones (1 Hz) were examined by considering the pre-processed data (needed for the NFT approach).
2.1.3. Roving Oddball paradigmFurther, we considered experimental iEEG data collected during a passive auditory Roving Oddball paradigm on three awake adult male common marmosets (Callithrix jacchus). This experimental data has been previously studied in Komatsu et al. (2015), Canales-Johnson et al. (2021). The paradigm consisted of trains of three, five, or eleven repeated single tones of 20 different frequencies (250 to 6727 Hz with intervals of 1/4 octaves). All tones were pure sinusoidal tones, lasted 64 ms (7 ms rise/fall) and there was stimulus onset asynchrony 503 ms between them. For each sound train, all tones were identical but varied across tone trains. Consequently, the mismatch occurred between the transition from one train to another in the form of a frequency change. Accordingly, the last tone of a train is defined as a standard tone, while the first tone of a new train is considered a deviant tone. Standard to deviant tone transitions then occurred 240 times during a recording session.
The number of implanted electrodes varied from monkey to monkey. For monkey “Fr”, 32 channels were implanted in the left hemisphere epidural space, for “Go”, 64 channels were implanted in the right hemisphere, and for monkey “Kr”, 64 electrodes were implanted in the right hemisphere (Figure 5C; see Komatsu et al., 2015; Canales-Johnson et al., 2021, for more detailed information). Recorded data were re-referenced through an average reference montage and epoched into −950 to 2000 ms segments relative to the standard or deviant tone onset. The different band-pass power time series were then extracted and baseline corrected (by use of the −100 to 0 ms time interval relative to tone onsets). For the analysis, all recordings were shortened to the −100 to 350 ms interval relative to sound onsets.
2.1.4. Verbal working memory paradigmAs a third data set, we investigated iEEG data stemming from the insular cortex during a verbal working memory task (vWM; see Llorens et al., 2022). Participants (n = 12, mean age 31.2 ±11.1 yr, 4 female) performed a recent-probes task, where in each trial a list of five letters was displayed (stimulus duration 500 ms, inter-onset interval 1000 ms) on the computer screen. The letter presentation was followed by 4 s maintenance and a 2 s probe period. During the latter, a probe letter was displayed where the participants had to answer whether the presented probe letter was in the current list (p = 0.5). In total, 144 trials were presented to each participant in a pseudo-random order within three blocks (each 10 min).
From the twelve participants, a total of 90 bipolar channels (mean: 7.5, range: ±5.9) were available after data cleaning. Data were then segmented into 16 s epochs (-12 s before and 4 s after probe period) and demeaned. The different band-pass power time series were then extracted, and for each band-pass power time series, differences between maintenance (−2 to 0 s) and probe period (0 to 2 s) were evaluated across channels and participants. The window for the baseline correction was from −9.5 to −8.5 s, i.e., the second preceding the presentation of the letter list.
2.2. Encoded informationWe estimated the EI of the mean responses of the different experimental conditions as described in Fuhrer et al. (2022). In short, by employing algorithmic or Kolmogorov Complexity (K-complexity), we estimated the EI between conditions through the measure of Normalized Compression Distance (NCD) (Li et al., 2004; Li and Vitányi, 2008). For a pair of signals (x, y), it is defined as
NCD(x,y)=C(xy)-min(C(x),C(y))max(C(x),C(y)),with C(xy) denoting the compressed size of the concatenation of x and y, and C(x) and C(y) their respective size after compression (Li et al., 2004; Li and Vitányi, 2008). Further, the NCD is non-negative, that is, it is 0 ≤ NCD(x, y) ≤ 1 + ϵ, where the ϵ accounts for the imperfection of the employed compression technique. Small NCD values suggest similar signals and high values indicate rather different signals.
To obtain a compressed version of a signal, it was first simplified by grouping its values into 128 regular intervals (bins) while keeping the temporal sampling rate unchanged. The bins covered equal distances and in a range between the global extrema of all the signals considered. The discrete signal was then compressed by passing an integer representation of the signal to the compressor. This representation constituted the mapping between each respective signal value and the number of the closest bin (Sitt et al., 2014; Canales-Johnson et al., 2020). For instance, the signal value X(t) at time point t is closest to the bin Q∈ℕ with 1 ≤ Q ≤ 128. The value for the time point t which is then used for the integer representation is Q. Compression of this integer representation subsequently proceeded through a compression routine based on Python's standard library with gzip. The statistical hypothesis testing was then performed through a permutation-based approach as described below.
2.3. t-testThe t-test is one of the most common methods to compare amplitude or power time series mean value differences across experimental conditions. For each sample and channel, a two-sided t-test was performed, where the resulting t-value represented the activity difference between the two conditions (e.g., standard or deviant). To correct for multiple comparisons across samples and channels, a False Discovery Rate (FDR) adjustment was applied with an FDR of 0.05.
2.4. Neural frequency taggingFor the Optimum-1 data, we used NFT to identify the brain's capability to automatically segment the continuous auditory stream (Picton et al., 2003; Norcia et al., 2015). In the respective auditory sequence, the two main segments are represented by the frequency of sound onsets (~2 Hz) or by the frequency of transitions between standards to standards or deviants to deviants (i.e., half the frequency or ~1 Hz). If the neural activity of a recording site showed such “tagging” of frequency-specific properties within the stimuli, we defined it as “responsive”. If it tagged half the frequency, we identified it as sensitive to the pattern of a standard-deviant alternation.
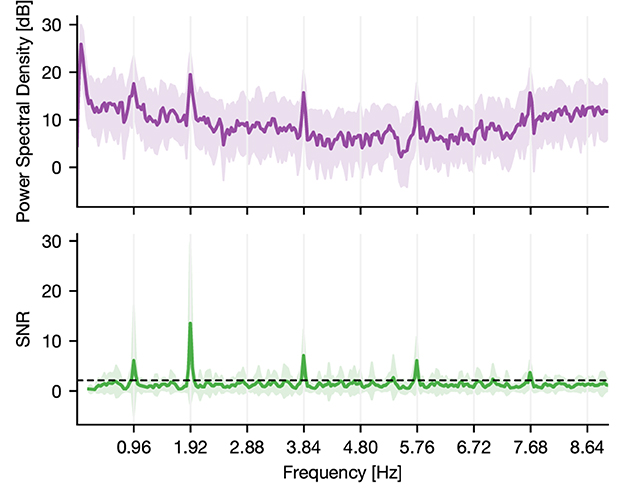
To assess this tagging, we computed the power-spectral density (PSD) of the epoched raw data using Welch's method (Figure 1; Gramfort et al., 2013). Subsequently, we estimated the signal-to-noise ratio (SNR) of the PSD (Meigen and Bach, 1999). Here, SNR defined the ratio of power in a given frequency (signal) to the average power in the surrounding frequencies (noise). By doing so, we normalized the spectrum and accounted for the 1/f power decay (Gramfort et al., 2013). We then identified significant peaks through a lower threshold consisting of two times the standard deviation. The latter was estimated by computing the median absolute deviation, which was obtained by taking the median SNR multiplied by the constant distribution-dependent scale factor (Figure 1). In the case of normally distributed observations, it reflects the 50% of the standard normal cumulative distribution function, leading to a scale factor of 1.4826 (Donoho and Johnstone, 1994; Quiroga et al., 2004). Power peaks of harmonics higher than the tone representation rate of 2 Hz are method-related peaks and are thus not regarded.
Figure 1. PSD and SNR of a responsive channel located in the superior temporal sulcus of a human. The activity of the channel shows synchrony to the main frequency of tone onsets, which is around 2 Hz. The displayed deviation is due to a constant lag of tone presentation during recording (the resulting theoretical main sequence is at 1.919 Hz). Further, it shows synchrony to half the main frequency indicating that the underlying region of this channel tags the presentation rate of solely standard or deviant tones. Thus, it discriminates between standard and deviant conditions. The dashed line indicates the statistical threshold.
2.5. Mutual informationBesides the t-test and NFT, EI was compared to the measure of MI. While it is also an information-theoretic quantity, in contrast to EI it draws on the concept of Shannon entropy (i.e., classic information theory). For a discrete random variable x with N outcomes, the entropy can be defined as
H(x)=-∑k=1Np(xk)logp(xk), (1)with p(xk) being the occurrence probability for each element xk, …, xN of x. Given this definition, the MI between two discrete random variables (x, y) with N or M outcomes can be defined as
MI(x;y)=H(x)−H(x|y) =H(y)−H(y|x) =∑k=1N∑j=1Mp(xk,yj)logp(xk,yj)p(xk)p(yj), (2)with the joint probability p(xk, yj) and the marginal probabilities p(xk) and p(yj).
This estimation of MI requires estimating the probability distribution of Eq. 2 by binning the signal into discrete steps. This is followed by a maximum likelihood estimation, yielding the probability distribution estimates. In our analysis, the respective signals were binned into four bins (Ince et al., 2017; Timme and Lapish, 2018).
Besides this binning approach, a novel estimation technique of MI after Ince et al. (2017) was employed. With this approach, MI is estimated via Gaussian Copula. In short, each univariate marginal distribution is transformed into a standard normal. Subsequently, a Gaussian parametric MI estimate is applied. That yields a lower bound estimate of MI, named GCMI. Statistical significance testing was then estimated through surrogate data testing.
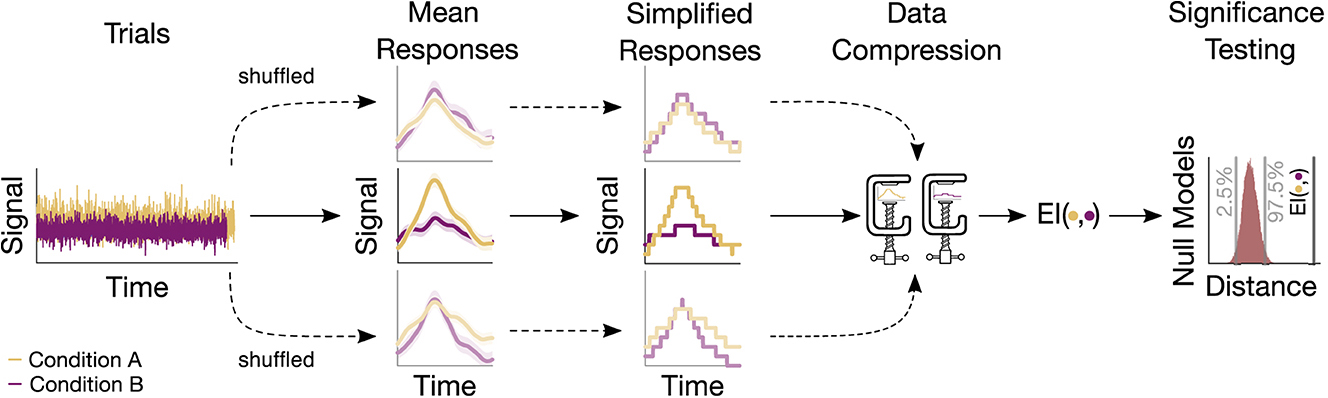
2.6. Surrogate testingThe statistical significance of the information-based measures (EI, MI, and GCMI) was assessed through surrogate data testing. Accordingly, p-values were obtained by evaluating the observed information-based quantity in terms of a null distribution (Figure 2). For EI and binned MI, null distributions were created by repeatedly shuffling the trials (i.e., single evoked responses) between conditions (e.g., standard and deviant) and then re-computing the information-based measure. For the GCMI, this proceeded for each sample of the time series signal. If not noted otherwise, we chose 20.000 iterations to build the null distributions, which is sufficiently above the recommendation of 100 shuffles (Lancaster et al., 2018). Single-sided p-values lower or equal to 0.05 were considered statistically significant. To correct for multiple comparisons across channels, FDR adjustment was applied with an FDR of 0.05.
Figure 2. Sketch of the procedure for an example electrode. Based on the trials, a mean response for each condition is computed. Trials are then shuffled, resulting in surrogate mean responses. Subsequently, these signals undergo a simplification procedure, followed by their compression. The output of the compression routine is the EI, quantifying the similarity between responses. The resulting values are then evaluated, leading to a null model distribution. This distribution serves to assess the significance of the actual EI value.
2.7. Significance ratioTo compare the different methods we determined the number of channels with statistically different activity between conditions relative to the total amount of channels. This ratio was computed either for each subject, where the total significance ratio was the mean ratio across all subjects accompanied by a bootstrapped 95%-confidence interval. Or by taking the total ratio by collapsing across all channels (regardless of subjects). The latter was used when considering individual brain regions, where the number of channels was limited, leading to distorted ratios with large confidence intervals. For the Roving Oddball data, the ratio of each monkey was considered individually.
2.8. Performance for limited amount of dataWe further considered scenarios where only a reduced number of trials were available. Channels were selected from the Optimum-1 paradigm with differing sensitivity to deviating tones. The channels were located in the respective 25, 50, 75, and 97.5 -percentiles of the t-value distribution emerging from the t-test-based analysis of HFA (Figure 7A). The number of trials varied from 1 to 100% of all available trials (759.50 ± 360.85 trials for deviant responses and 715.14 ± 388.12 trials for standards across all channels). For each percentage and condition, trials were randomly chosen and a null distribution with 1.000 surrogates was created. This step was repeated 50 times for each trial increment to obtain an average p-value as a function of the number of trials (Figure 7B). The surrogate number was chosen in line with the recommendations of Lancaster et al. (2018) and the repetition number was based on an empirical approach, keeping it as low as possible to account for the considerable computational resources.
2.9. False positive estimatesEvaluating the methods' performances, we employed neurophysiological data sets and were thus not able to compute the false positive rate of each method given the ground truth. Therefore, we estimated the methods' false positive rates through a simulation-based approach. The methods were employed to discriminate between two samples drawn from the standard normal distribution (Colquhoun, 2014). Each sample consisted of a time-course signal of 100 observations, was repeatedly drawn (500 times), and for each draw the number of surrogates for EI, MI, or GCMI was 1.000. Given that both samples originated from the same distribution, each statistically significant output constituted a false positive. The false positives were then accumulated across simulations and put relative to the respective number of simulations to estimate the false positive rate (Figure 7C).
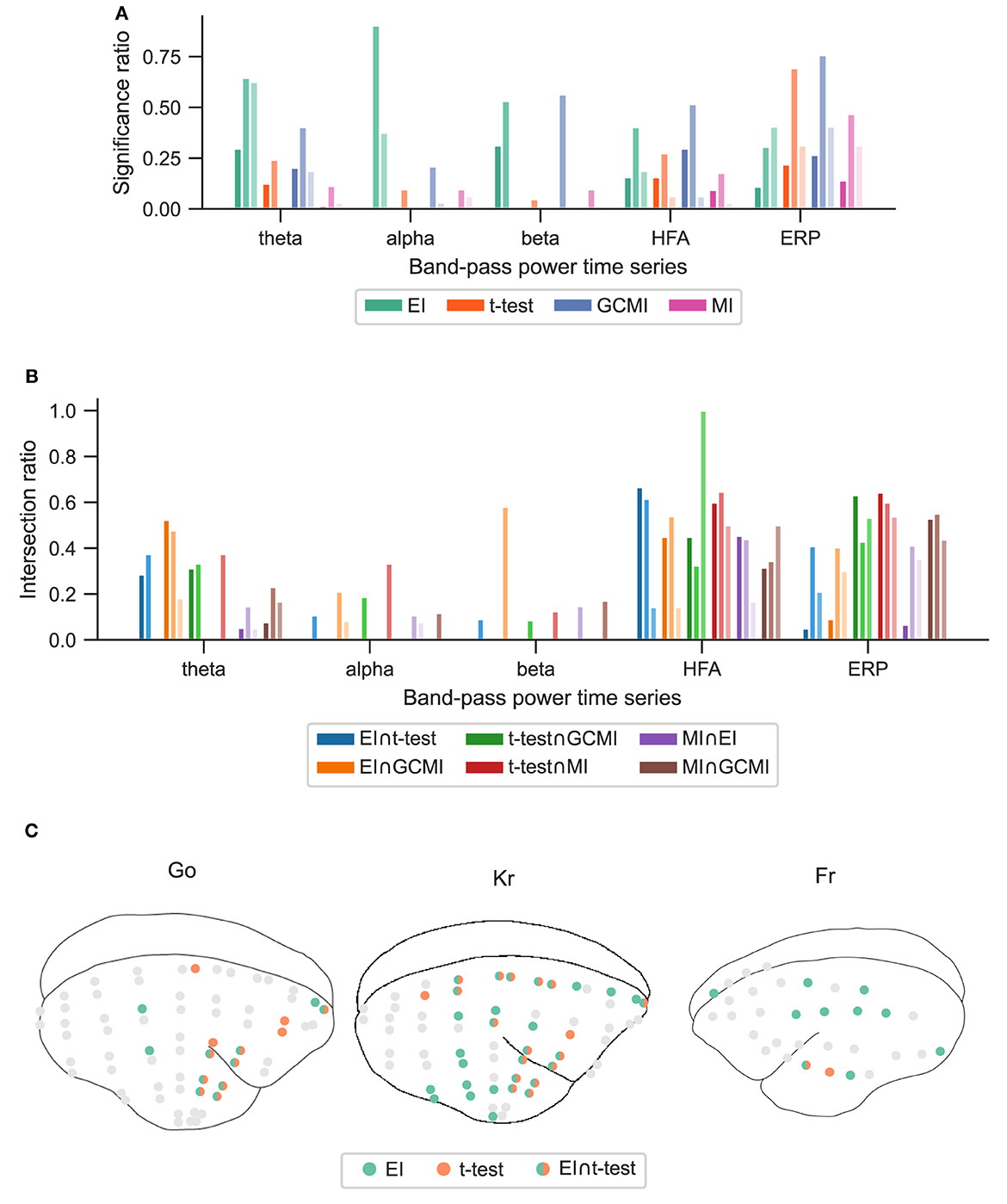
3. ResultsBased on three neurophysiological data sets, we compared the methods' performances of EI, a conventional t-test, MI, and GCMI on discriminating evoked responses to that across five different cortical band-pass power time series. Additionally, we considered the approach of NFT. Overall, EI and t-test showed the greatest significance ratios (Figures 3A, 5A, 6A).
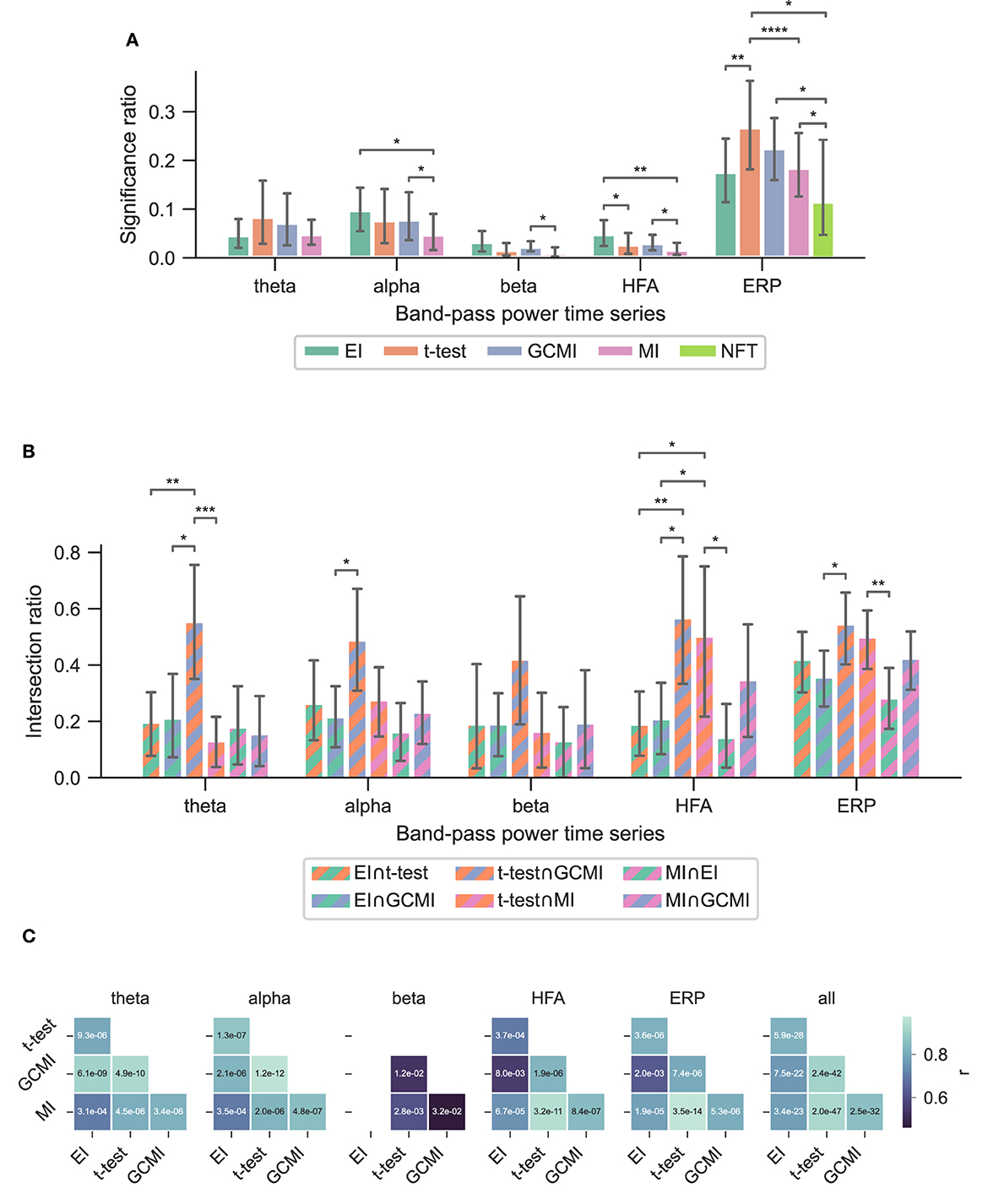
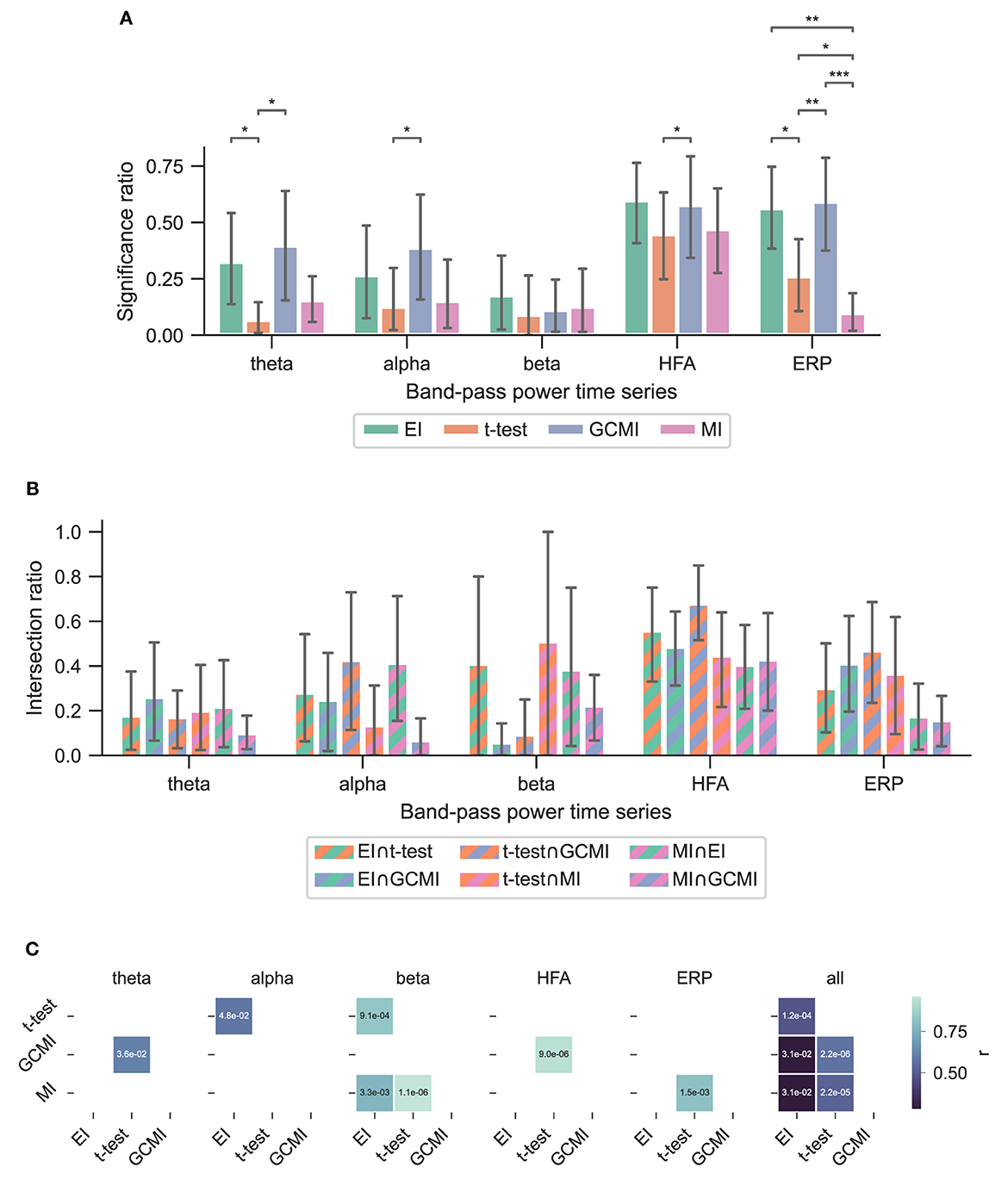
Figure 3. Performance of the different methods for the Optimum-1 paradigm. Error bars indicate 95%-CIs across subjects. Importantly, each subject has a unique electrode distribution such that the range of significant channels can greatly vary. (A) Significance ratio for each electrophysiological representation. Statistical significance is indicated with *p ≤ 5e−2, **p ≤ 1e−2, ***p ≤ 1e−3, and ****p ≤ 1e−4. (B) Intersection of the significant channels across methods. Each number is shown relative to the total number of significant channels. (C) Correlation matrices comparing the subject-specific significant ratios. The respective p-value is annotated in each square.
3.1. Optimum-1 paradigmAcross the 1,078 channels stemming from the Optimum-1 paradigm, for alpha and HFA signals, EI's significance ratio was significantly greater than MI or t-test (Figure 3A) while the t-test showed the greatest significance ratio for the ERP (two-sided paired t-tests on a subject level, p = [1.02e−2, 4.17e−2, and 3.666e−3]). MI resulted in the lowest ratios, although it was only significantly lower on a subject level for HFA (two-sided paired t-test, p max = 4.17e-2). Note that for human iEEG, the number of channels and their distribution is not constant across subjects and can thus vary greatly. Consequently, the fewer channels for a subject, the less robust the estimated individual significance ratio.
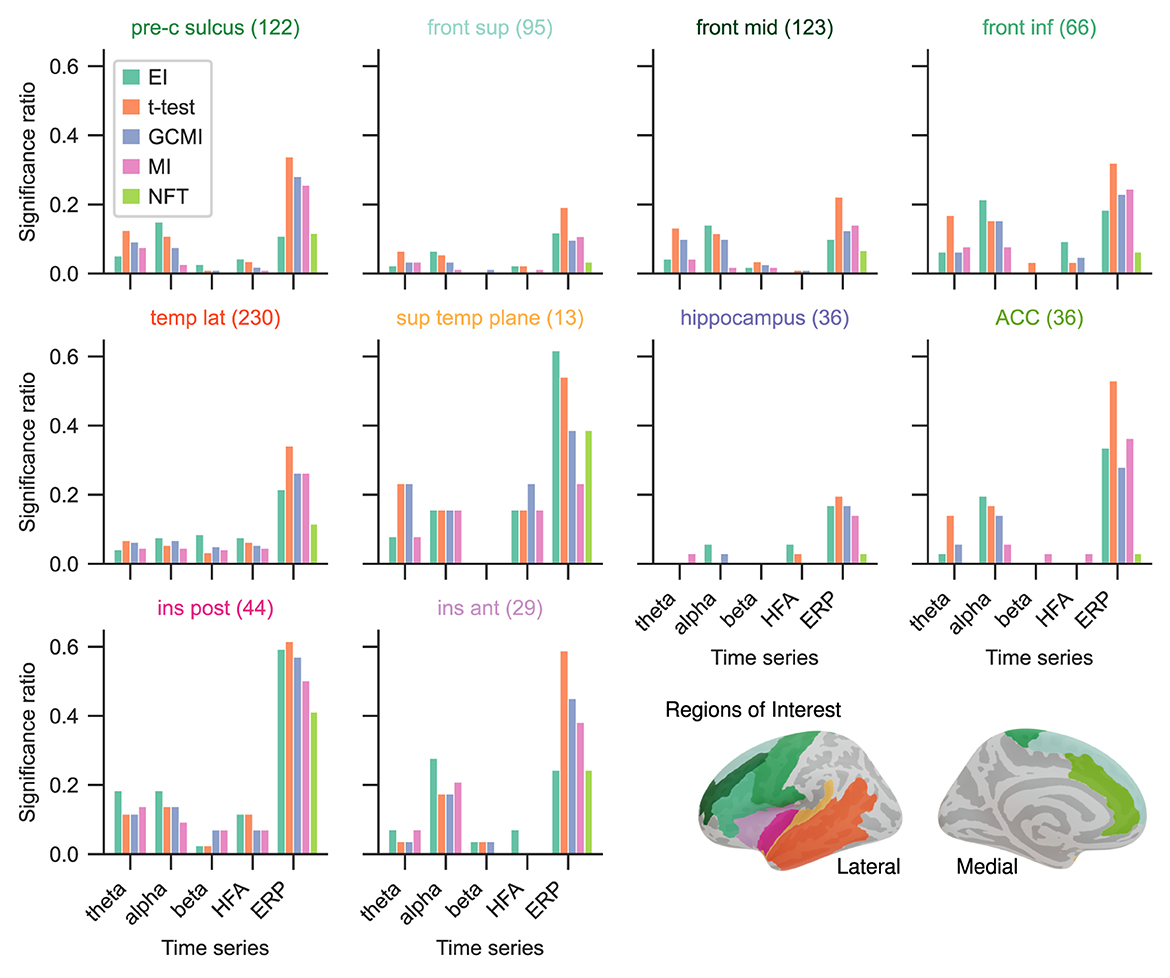
Given the differing sensitivity to deviating sounds across individual brain regions and the number of participants for the Optimum-1 paradigm, we then compared the methods' significance ratios across individual cortical areas. For this reason, we evaluated the methods' performances across different areas comprising temporal, frontal, insular, peri-central sulci, and anterior cingulate cortices (ACC), as well as the hippocampus (Figure 4; see Fuhrer et al., 2021 for exact definitions). Overall, the significance ratios of EI aligned with the other methods across brain regions and representation. Specifically, the ratio for higher cortical areas such as the superior or middle frontal cortex was low while being higher in areas such as the superior temporal plane (which includes Heschl's gyrus). The NFT method together with MI showed the lowest sensitivities across brain regions. However, there were higher or equally high ratios in responsive brain areas such as the superior temporal plane or posterior insular cortices.
Figure 4. Significance ratio across brain regions for the different methods based on the Optimum-1 paradigm. The number of channels per ROI is indicated in brackets (For more detailed information on the ROIs, see supplementary of Fuhrer et al., 2021).
3.1.1. Performance of NFTFor the Optimum-1 paradigm, we further evaluated the NFT of all contact sites. The number of responsive channels, i.e., the number of channels that solely tagged the frequency of standards or deviants, was lower in comparison to all other methods (two-sided paired t-test between NFT and MI, p = 3.55e−2).
3.2. Roving Oddball paradigmThe observations from this data set are in line with the results from the marmoset recordings, which had 160 channels in total. Based on the significance ratio of each marmoset monkey, for theta, alpha, and beta signals, EI detected more channels than the other approaches. For HFA, GCMI, and EI performed similarly well, while for ERP, GCMI, and t-test performed best (Figure 5A). Additionally, common to all methods was the variability in significance ratios across monkeys.
Figure 5. Performance of the different methods for the Roving Oddball paradigm across the three marmoset monkeys “Go”, “Kr”, and “Fr”. (A) Global significance ratio for each marmoset. (B) Intersection of the significant channels for each method combination. Each number is shown relative to the total number of significant channels for each method combination. (C) Location of the significant channels for EI and t-test for HFA (monkey “Go” has 64, “Kr” 62, and “Fr” exhibits 32 channels).
3.3. vWM taskA similar observation was made by considering EI's performance for the vWM task (Figure 6A). Across all band-pass power time series, EI showed the highest significance ratios. Interestingly, for the ERPs, both EI and GCMI had a significantly greater significance ratio than the t-test (p max = 8.21e−3). Besides that, especially GCMI exhibited a consistently higher significance ratio across band-pass power time series in comparison to the Optimum-1 and Roving Oddball paradigms.
Figure 6. Performance of the different methods across subjects for the vWM task. (A) Performance of the different methods. The error bars indicate the 95% CIs across subjects. (B) Significance ratio across representation. Statistical significance is indicated with *p ≤ 5e-2, **p ≤ 1e−2, ***p ≤ 1e−3 and ****p ≤ 1e−4. (C) Correlation matrices comparing the subject-specific significant ratios. The respective p-value is annotated in each square.
3.4. Method overlap across data setsTo assess channels that the methods commonly detected, we divided the number of common significant channels (i.e., the intersection) by the total amount of significant channels for each pairwise method combination (Figure 5C, i.e., each method's specific unique set of significant channels plus their intersection) and defined this ratio as the intersection ratio. For the Optimum-1 paradigm, the intersection ratio between the t-test and GCMI was the greatest across all band-pass power time series (Figure 3C). For beta and HFA signals, there was also a high intersection ratio between the t-test and GCMI. However, for these band-pass power time series, the number of significant channels was low (Figure 3A), which led to higher percentages. This can also be observed by correlating the method-specific channel distributions across subjects (Figure 3C), i.e., by correlating the significance ratios across subjects for each method-to-method combination. Besides that, the approaches correlated the least for beta signals, which were also the signals with the lowest significance ratios. Overall, there was a high correlation across methods (Figure 3C).
The relatively high intersection ratio between the t-test and GCMI across band-pass power time series was not observable for the Roving Oddball paradigm and the vWM task. For the former, the intersection ratios were the highest for HFA and ERP signals (Figure 5B), while for the latter it was highest for HFA (Figures 6B, C). Furthermore, the same effect as for the Optimum-1 paradigm recordings occurred for the Roving Oddball paradigm. For HFA, the monkey Fr showed maximum intersection ratios between t-test, GCMI, or MI. Of note, the respective significance ratios were rather low (Figure 5A). Moreover, when comparing Kr to Go it appeared that the latter had a smaller number of significant and overlapping channels for EI and t-test. However, because Kr exhibited more significant channels for both methods, the intersection ratio was of comparable magnitude for both monkeys.
3.5. Reduced trials and false positivesConsidering the two best-performing methods of EI and t-test, when reducing the number of trials they only marginally differed in reaching statistical significance although EI tended to reach this threshold slightly earlier (Figure 7B). In terms of the simulation-based estimation of the false positive rate estimates, all methods showed similar rates which were close to the level of significance α of 0.05 (Figure 7C).
Figure 7. Performance in the case of a limited amount of data and estimation of false positives. (A) Selection of channels according to their respective t-value. The channels emerged from HFA or the Optimum-1 paradigm and were located in the respective 25, 50, 75, and 97.5 -percentiles of the t-value distribution. (B) The number of trials was reduced by randomly selecting a varying number of trials for each condition. This was followed by repeatedly applying the measures (50 times for each percentage). The dashed line represents the significance threshold (p = 0.05). Note that the y-range is limited to 6 (corresponding to a p-value of 2.5e−3). 100% of the trials was around 759.50 ± 360.85 trials for deviant responses and 715.14 ± 388.12 trials for standards for each channel. The dots on the significance line indicate the trial percentage when each method exceeded the significance level. (C) False positive rate estimation by repeatably discriminating two random samples with 100 observations each, drawn from the standard normal distribution. The significance level α = 0.05 is indicated with a black dashed line.
4. DiscussionDespite its ability to estimate the absolute information contained in individual brain responses, the use of AIT in neuroscience is limited. Hence, information-theoretical approaches in neuroscience are needed to facilitate its use. With the measure of EI, we proposed information-based task condition discrimination as an alternative to the classical t-test and other information theory approaches. Using compression as the core principle, this procedure quantifies the similarity between recordings stemming from different conditions. We applied all procedures to event-related potentials extracted from different frequency bands in three iEEG datasets and compared it to that of t-test, MI, GCMI, and NFT. We discuss the performance and sensitivity of these methods, their pros and cons, and similarities and differences.
4.1. Sample vs. mean response approachBesides their individual procedures in estimating test statistics, the examined methods also differ in how the data were processed. While for the t-test and GCMI approach, each sample or time point across trials is considered independently, EI and MI in its current implementation, make use of all time samples by computing the respective mean responses across trials. Consequently, for each channel, the first two methods result in test statistics along the time axis, while the last two output a single value channel-dependent test statistic. Such a time course is advantageous when the core interest is within the time domain or latency of responses, i.e., at which time point responses differ most. However, when it comes to assessing how sensitive contact sites are toward different conditions, this time course is of a minor role. To assess a channel's significance, it is necessary to reduce the time course of the test statistics to one single value. Additionally, the complete time series of the respective statistic also needs to be corrected for multiple comparisons across channels and trials (i.e., correction of a 2D array that covers samples and channels vs. a 1D array that only includes channels). Therefore, corrections might undermine the sensitivity of sample-based approaches.
4.2. Performance of EIAdopting the sample-based approach mentioned above is not beneficial for EI. While MI or GCMI estimates the underlying distribution of the input data, EI is a compression-based approach. It thus compresses the entire time series while exploiting structures along the time axis. This mechanism is a key feature of this approach and is possibly responsible for the higher significance ratios across evoked potentials and other band-pass power time series. If EI is applied along trials for each sample, this feature of exploiting structures along the time axis would be removed because the input would be a concatenation of different signals. Further, especially for time course responses that are close in magnitude or partially overlapping, i.e., situations where the classical t-test might fail to disentangle condition differences measuring EI proves beneficial. By exploiting complementary structures within both responses, subtle information-grounded differences that extend beyond the width of one sample can be identified in such scenarios. Additionally, the binning parameter or resolution along the time axis plays minor importance when it comes to computation time, while it can have a great effect on the computation time of GCMI or cluster-based t-tests.
Especially for the beta and HFA power time series, EI appears to be a useful tool for detecting active channels (Figure 3A). Across all data sets, EI exhibited the highest significance ratios compared to the t-test, MI, and GCMI. HFA presumably carries stimulus mismatch or prediction error signals (Bastos et al., 2015). In that regard, detecting a high number of channels in HFA discriminating between standard and deviating sounds in regions such as the hippocampus appears to be especially interesting (Figures 4, 6A).
4.3. Performance of t-testFor the ERP, the t-test showed the greatest significance ratios for the Optimum-1 and Roving Oddball paradigm. One possible reason for this could be the generally low variance (or standard error) in EPRs compared to the other electrophysiological representations. This low variance leads to statistically strong differences in ERP amplitudes resulting from the different stimulus conditions. Further, the number of samples that significantly differ in amplitude across conditions after correcting for multiple comparisons can be rather low for a channel (i.e., the entire trial vs. only a few sample points differ). EI, on the other hand, considers the full-time course and only assesses channels as significant when the information content of the entire mean responses differs. However, the high performance of the t-test is not observable for the vWM task. Here, both EI and GCMI detected a greater number of responsive channels, while also showing a relatively high intersection ratio between t-tests, respectively.
4.4. Performance of NFT and MICompared to all the other measures (EI, t-test, MI, and GCMI), the NFT approach had inferior performance. However, when considering individual ROIs, it performed equally well for regions close to or belonging to the temporal cortex. Notably, NFT is based on a different procedure. It exploits the static presentation rates of stimuli visible in the spectral decomposition of the entire sequence. Figure 1 shows such a “tagging” effect in an exemplary channel, where a specific brain region synchronizes to the exact frequency of the stimuli presentation. The highest SNR or power was contained at 1.92 Hz, which was the presentation rate of the tones (standards and deviants). In addition, it also showed a peak at half this frequency, which is the combination of either standard-to-standard or deviant-to-deviant tones. This implies that this brain region discriminates between standard and deviant tones. Importantly, one prerequisite for the frequency tagging approach is that the presentation rate is static. Any temporal jitter during the presentation critically disturbs the “tagging” effect. A possible reason for the relatively low performance could be related to this unique feature of NFT combined with the employed multi-featured oddball paradigm. It may perform better in paradigms with fewer deviant types than in the present task containing eight types of deviant tones.
When it comes to performance, MI was close to NFT. It detected fewer channels than the other methods, especially for alpha, beta, and HFA band-pass power time series. It is important to notice that for comparison reasons, we implemented MI in the same way as EI. That is, the entire time series of a mean response was considered. It is also possible to implement it in the sample-based fashion of GCMI, where it has been shown to operate similarly well (Ince et al., 2017).
4.5. Method overlapOverall, the sample-based approaches of t-test and GCMI correlated the most (Figure 3C). Besides that, there was no clear outlier method apparent for the analyzed data sets. The same conclusion can be drawn considering the significance ratios across individual brain regions (Figure 4). This can be seen as a validation of the EI measure: While showing higher significance ratios in some ROIs (e.g., hippocampus or pre-central sulcus), it performed similarly well as the other methods across brain areas and did not indicate implausible results. Further, our simulation-based analysis indicates that none of the methods exhibited a higher number of false positives than the others (Figure 7C). All methods' false positive rate estimates converged to the theoretical value of 0.05 pointing toward the conclusion that all methods are equally reliable.
4.6. Choice of number of binsFurthermore, the number of bins along the potential or power dimension during the binning procedure was held constant across data sets. We chose 128 bins for EI and 4 bins for MI (Ince et al., 2017; Fuhrer et al., 2021, 2022). Adapting this parameter might be needed when the relevant trials are of increasing length, i.e., it might be necessary to reduce the number of bins for the EI measure for longer-lasting trials. The main motivation for this step is to simplify the signal to an extent that ensures that the compressor keeps operating effectively. However, both EI and MI should be robust to this parameter choice. For example, EI showed similar results when varying the number of bins from 128 to 64, but showed a decreased performance when using only 32 bins (Sitt et al., 2014; Canales-Johnson et al., 2020; Fuhrer et al., 2022). An alternative to adapting the number of bins is to segment the time series into shorter segments, which would then yield segments of EI values along the trials, or to down-sample the signal along the time axis.
4.7. Reduced number of trialsLastly, in the case of limited data availability, the two best-performing methods showed relatively similar performance (Figure 7). For lower t-values (below the 75-percentile), both methods needed around 50% of the maximally available trials to identify a channel as event-responsive. However, EI appeared to require slightly fewer trials than the t-test. Noteworthy is that for channels with relatively distinct responses to standards and deviants (above the 97.5-percentile), both measures only required around 3% (ca. 22 trials) of the available trials to identify the respective channel as significant.
4.8. Performance across paradigmsAltogether, the examined neurophysiological data sets stem from two species (human and non-human primates) and employ both passive and active paradigms as well as auditory or visual stimuli. In contrast to the Optimum-1 and Roving Oddball paradigms, in the vWM study subjects were instructed to solve a memory task where they were exposed to visual stimuli. Moreover, as opposed to comparing standard with deviant tones responses, for the vWM paradigm, the probe period was compared to the baseline period based on one cortical region. Regardless of these differences, EI as well as MI, and GCMI performed robustly across all data sets (Figures 3A, 5A, 6A).
5. ConclusionTaken together, our findings demonstrate that EI, MI, as well as GCMI, constitute viable approaches to discriminate differences in neurophysiological recordings of evoked responses. Specifically, EI competed well in detecting iEEG channels sensitive to deviating sound types across diverse types of electrophysiological responses among the methods considered. Especially for beta and HFA signals, EI detected a higher number of sensitive channels in comparison to the other procedures. Future studies focusing on EI could explore this further by extending it through a hybrid approach, i.e., using Shannon's information theory besides AIT. Another possibility is to focus on the compression method. Modern compressors such as LZMA, Brotli, or neural network compressors might be able to increase EI's performance. On a more general note, information-based encoding proved to be a worthwhile tool in assessing where in the brain neural responses differ across experimental conditions.
Data availability statementThe data analyzed in this study is subject to the following licenses/restrictions: due to the confidential nature of human intracranial EEG data, the patients' datasets analyzed for the current study are not publicly available. Our ethical approval conditions do not permit public archiving of study data. Readers seeking access to the data supporting the claims in this paper should contact AB, Department of Psychology, University of Oslo. Requests must meet the following specific conditions to obtain the data: a collaboration agreement, data sharing agreement, and a formal ethical approval. Requests to access these datasets should be directed to a.o.blenkmann@psykologi.uio.no. Custom analysis codes written inMatlab are available at osf.io/tnvc4.
Ethics statementThis study was approved by the Research Ethics Committee of El Cruce Hospital, Argentina, the Regional Committees for Medical and Health Research Ethics, Region North Norway, and the University of California, Berkeley. Patients gave written informed consent before participation.
Author contributionsJF, KG, A-KS, TE, and AB contributed to the conception, design of the study, and interpretation of the results. AB and AL carried out the experiment and collected the data. JF wrote the manuscript with inputs from AB, KG, TE, and A-KS. All authors revised the manuscript. All authors have read and approved the final manuscript.
FundingThis work was partly supported by the Research Council of Norway (RCN) through its Centers of Excellence scheme project number 262762, RCN project number 240389, and RCN project number 314925.
AcknowledgmentsWe thank the patients for kindly participating in the studies. We want to express our gratitude to the EEG technicians at El Cruce Hospital and Oslo University Hospital-Rikshospitalet for their support. We thank Pål G. Larsson, Jugoslav Ivanovic, and Ludovic Bellier for their collaboration. Further, we would like to thank Misako Komatsu, Kana Takaura, and Naotaka Fujii for publicly sharing their data.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesBastos, A. M., Vezoli, J., Bosman, C., Schoffelen, J.-M., Oostenveld, R., Dowdall, J., et al. (2015). Visual areas exert feedforward and feedback influences through distinct frequency channels. Neuron. 85, 390–401. doi: 10.1016/j.neuron.2014.12.018
PubMed Abstract | CrossRef Full Text | Google Scholar
Blenkmann, A. O., Collavini, S., Lubell, J., Llorens, A., Funderud, I., Ivanovic, J., et al. (2019). Auditory deviance detection in the human insula: An intracranial eeg study. Cortex 121, 189–200. doi: 10.1016/j.cortex.2019.09.002
PubMed Abstract | CrossRef Full Text | Google Scholar
Canales-Johnson, A., Billig, A. J., Olivares, F., Gonzalez, A., Garcia, M. D. C., Silva, W., et al. (2020). Dissociable neural information dynamics of perceptual integration and differentiation during bistable perception. Cerebral Cortex 30, 4563–4580. doi: 10.1093/cercor/bhaa058
PubMed Abstract | CrossRef Full Text | Google Scholar
Canales-Johnson, A., Teixeira Borges, A. F., Komatsu, M., Fujii, N., Fahrenfort, J. J., Miller, K. J., et al. (2021). Broadband dynamics rather than frequency-specific rhythms underlie prediction error in the primate auditory cortex. J. Neurosci. 41, 9374–9391. doi: 10.1523/JNEUROSCI.0367-21.2021
PubMed Abstract | CrossRef Full Text | Google Scholar
Donoho, D. L., and Johnstone, I. M. (1994). Ideal spatial adaptation by wavelet shrinkage. Biometrika 81, 425–455. doi: 10.1093/biomet/81.3.425
CrossRef Full Text | Google Scholar
Foster, B. L., He, B. J., Honey, C. J., Jerbi, K., Maier, A., and Saalmann, Y. B. (2016). Spontaneous neural dynamics and multi-scale network organization. Front. Syst. Neurosci. 10, 7. doi: 10.3389/fnsys.2016.00007
留言 (0)