
記住我






Weighing the risks and benefits of clinical interventions is an everyday part of clinical practice, but clinicians are far from perfect in estimating risk. In a study of patients with CKD stage 3–5, nephrologists substantially overestimated their patients' 2-year risk of progressing to kidney failure as compared with the Kidney Failure Risk Equation (KFRE).1 If acted upon, these informal risk estimates could have led to unnecessary workups or interventions. Risk prediction, through more formal estimation, helps clinicians and patients match their treatment intensity to the estimated risk. However, the recent explosion of models in nephrology has led to literature of varying quality, made further opaque through the use of machine learning algorithms.
In this overview, we use a clinical case study to broadly illustrate the decisions analysts must make when developing and evaluating risk prediction models, including the role of machine learning. While excellent resources touching on specific analytical aspects of risk prediction exist, we hope that our broad overview will be a useful starting point for clinicians involved in these types of studies. We will cover several key aspects of the modeling process, including the (1) framing of the problem; (2) availability and quality of the data; (3) functional form of the model; (4) performance measures of the model; and (5) ethical concerns in the clinical use of the model.
Case StudyYour multidisciplinary team is asked to estimate the risk of CKD incidence over a 10-year period in patients older than 45 years in your health system. You hope these predictions will help prioritize CKD screening efforts. Which aspects of this case will your team need to consider as it develops a risk prediction model?
Framing of the ProblemBefore any data can be requested or collected, the team needs to frame the problem. Specifically, what is the outcome, who is at risk, when are they at risk, and how will the risk support clinical decision making? In this case, the outcome is whether a patient develops incident CKD in 10 years from some index period. The index period refers to the time point for each patient (e.g., first clinic appointment) at which the prediction is made. Although most studies use a single index period per patient (i.e., each patient contributes one observation to the model), it is possible to use multiple index periods for each patient (e.g., one observation per clinic visit).
Outcomes can be continuous (e.g., eGFR), binary, multinomial or multiclass (e.g., multiple mutually exclusive categories such as CKD stage), or right-censored. Although the 10-year risk of CKD is a binary outcome (whether a patient develops CKD), modeling it as a binary outcome could result in immortal time bias if patients with <10 years of follow-up were excluded. Modeling this as a time-to-event outcome would account for loss to follow-up, but the team also needs to consider the competing risk of death because of the older patient population and long (i.e., 10-year) time horizon.2 A patient who dies within this time period would be unable to develop CKD and thus would not benefit from CKD screening. Finally, the team needs to exclude all patients with preexisting CKD because such patients are no longer at risk for a condition they already have.
Availability and Quality of DataA common source of data for risk prediction is retrospective electronic health record (EHR) or registry data. Although clinical trial data are occasionally used for risk prediction, this is often not advisable because the sample size required for risk prediction is generally larger than that required for trials,3 and enrolled patients may differ from patients seen in clinical practice because of selection bias. While clinical trials are powered based on an anticipated effect size for an intervention, risk prediction studies are powered based in part on the anticipated predictability of the outcome given the available predictors.4
The team also needs to consider data quality, which can be assessed by evaluating conformance, completeness, and clinical plausibility.5 EHR data are generated as a result of routine clinical care and billing, and thus should not be interpreted in the same way as data collected systematically in trials. Both the presence of specific data elements and the context in which they were collected have predictive value in EHR data because lower-risk patients may have fewer visits and test results available in the EHR.6
When data elements are missing, analytical decisions need to be made about whether to exclude variables (e.g., those with high missingness), whether to exclude patients (e.g., where information about inclusion/exclusion criteria is not available), or whether to estimate missing values using information from other variables (i.e., model-based imputation).
The Model's FormWhile all models aim to learn a relationship between predictors and an outcome, this relationship can be represented in different forms. The KFRE, for example, takes the form of a Cox proportional hazards regression model. Machine learning, a catch-all phrase used to refer to many different algorithms, can be either simpler or more complex than a regression model.
At one extreme, decision rules or decision stumps are among the simplest models. They refer to logical statements such as if age ≥60, the risk of kidney failure is 20%, and otherwise 10%. These statements can be connected to form a decision tree. Multiple decision trees can be averaged to produce a tree ensemble. When trees take on different weights, this is referred to as a gradient boosting decision tree (GBDT) ensemble. As certain software implementations of these algorithms take on outsized prominence, the software may be referred to in studies in place of the algorithm itself (e.g., XGBoost instead of GBDT). Deep learning models are complex math equations that perform particularly well in modeling large and complex datasets with a high signal-to-noise ratio (e.g., using slide images to diagnose pathology). Among the most complex models are stacked ensembles, which average risks across multiple different forms of models.
Complexity comes at a cost. More complex models require much more data than regression models to achieve a similar degree of performance.7 Because of this, which model form is selected should depend on how much data are available, what kinds of data are available (e.g., time series, imaging), and how predictable the outcome is estimated to be by a clinical expert using the available predictors.
Strategies to Measure Model PerformanceAlthough it is common practice in epidemiological studies to report model fit (e.g., C-statistic) on the same data on which a model is derived, this practice of double-dipping is undesirable in risk prediction because it may overestimate generalizability. When using machine learning for risk prediction, every analytical step—feature selection, training, tuning, recalibration, and evaluation—requires different slices of data, achieved either through data splitting (e.g., train/test, cross-validation) or bootstrapping.
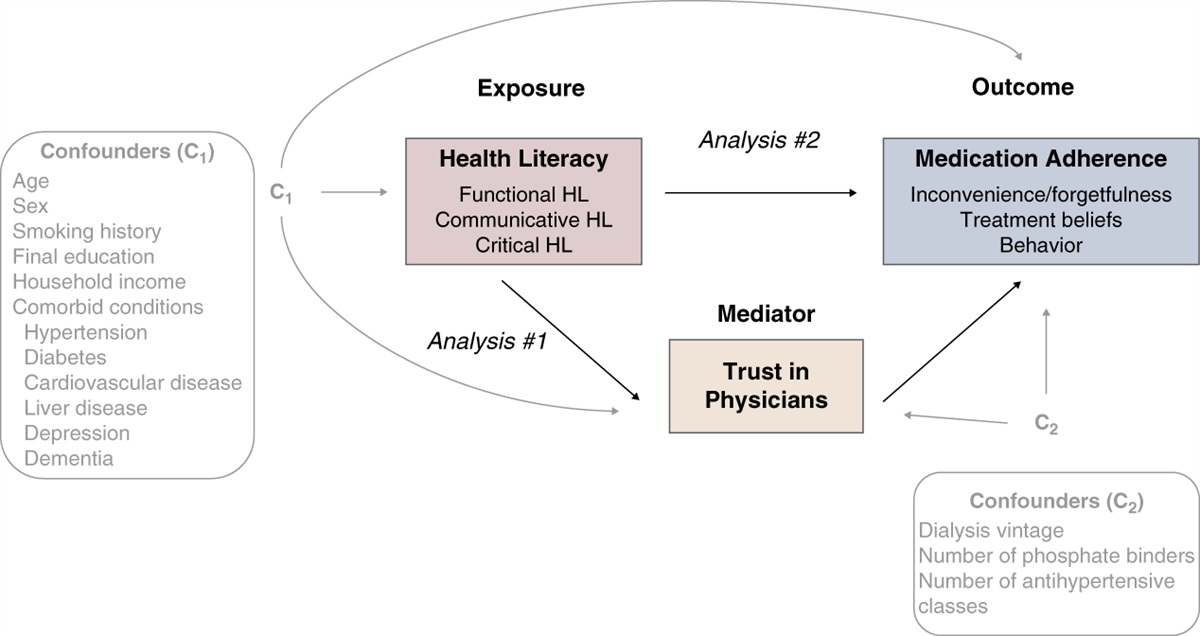
When model performance is evaluated in the test set, the selection of evaluation metrics depends on the nature of the problem and the outcome. When the outcome is binary, as in our case study, three aspects of model performance should be evaluated: discrimination, calibration, and net benefit (see Figure 1).8
 Figure 1:
Figure 1: Evaluation measures for a model predicting the risk of a binary outcome.
Ethical ConsiderationsJustice is a major consideration in risk prediction. Because EHR data are generated as a result of clinical care, inequalities in health care access and outcomes are similarly reflected in data used to train models.9 For example, the inclusion of race in a model may lead to different risk predictions for people of different races, which may lead to different clinical actions being taken. These actions may be inequitable, but even if they were equitable, asking a patient their race to make a non–race-related clinical decision may itself lead to mistrust and harm. Recent recognition of harms of including race in models used to allocate care has led to its removal from models in multiple disciplines.10
In this overview, we provide key considerations for developing and appraising risk prediction models, including the framing of the problem, availability and quality of the data, functional form of the model, performance measures of the model, and ethical concerns related to its use.
DisclosuresJ. Cao reports an internship with Merck & Co, and J. Cao's spouse reports employment with and ownership interest in Eli Lilly and Company. K. Singh reports consultancy agreements with Flatiron Health (as part of scientific advisory board); research funding from Teva Pharmaceutical Ltd; honoraria from Harvard University for education: K. Singh teaches in the Safety, Quality, Informatics, and Leadership (SQIL) program and their HMS Executive Education program; honorarium from Flatiron Health for giving a talk; advisory or leadership role for Flatiron Health (paid member of scientific advisory board); and other interests or relationships with Blue Cross Blue Shield of Michigan: K. Singh receives salary support through the University of Michigan for work done on the Michigan Urological Surgery Improvement Collaborative; and K. Singh's institution receives grant funding from the Blue Cross Blue Shield of Michigan, National Institute of Diabetes and Digestive and Kidney Diseases, and Teva Pharmaceuticals for unrelated work. The remaining author has nothing to disclose.
FundingThis work was supported by grant R01DK133226 from the National Institute of Diabetes and Digestive and Kidney Diseases.
AcknowledgmentsThis article is part of the Artificial Intelligence and Machine Learning in Nephrology series, led by series editor Girish N. Nadkarni.
The content of this article reflects the personal experience and views of the authors and should not be considered medical advice or recommendation. The content does not reflect the views or opinions of the American Society of Nephrology (ASN) or CJASN. Responsibility for the information and views expressed herein lies entirely with the authors.
Author ContributionsAll authors conceptualized the study; K. Singh was responsible for supervision; E.A. Balczewski wrote the original draft; and all authors reviewed and edited the manuscript.
References 1. Potok OA, Nguyen HA, Abdelmalek JA, Beben T, Woodell TB, Rifkin DE. Patients,“nephrologists,” and predicted estimations of ESKD risk compared with 2-year incidence of ESKD. Clin J Am Soc Nephrol. 2019;14(2):206–212. doi:10.2215/CJN.07970718 2. Ramspek CL, Teece L, Snell KIE, et al. Lessons learnt when accounting for competing events in the external validation of time-to-event prognostic models. Int J Epidemiol. 2022;51(2):615–625. doi:10.1093/ije/dyab256 3. Stidham RW, Vickers A, Singh K, Waljee AK. From clinical trials to clinical practice: how should we design and evaluate prediction models in the care of IBD? Gut. 2022;71(6):1046–1047. doi:10.1136/gutjnl-2021-324712 4. Riley RD, Ensor J, Snell KIE, et al. Calculating the sample size required for developing a clinical prediction model. BMJ. 2020;368:m441. doi:10.1136/bmj.m441 5. Corey KM, Helmkamp J, Simons M, et al. Assessing quality of surgical real-world data from an automated electronic health record pipeline. J Am Coll Surg. 2020;230(3):295–305.e12. doi:10.1016/j.jamcollsurg.2019.12.005 6. Agniel D, Kohane IS, Weber GM. Biases in electronic health record data due to processes within the healthcare system: retrospective observational study. BMJ. 2018;361:k1479. doi:10.1136/bmj.k1479 7. van der Ploeg T, Austin PC, Steyerberg EW. Modern modelling techniques are data hungry: a simulation study for predicting dichotomous endpoints. BMC Med Res Methodol. 2014;14(1):137. doi:10.1186/1471-2288-14-137 8. Steyerberg EW, Vergouwe Y. Towards better clinical prediction models: seven steps for development and an ABCD for validation. Eur: Heart J. 2014;35(29):1925–1931. doi:10.1093/eurheartj/ehu207 9. Suresh H, Guttag J. A framework for understanding sources of harm throughout the machine learning life cycle. In: Equity and Access in Algorithms, Mechanisms, and Optimization. 2021;pp. 1–9. 10. Vyas DA, Eisenstein LG, Jones DS. Hidden in plain sight—reconsidering the use of race correction in clinical algorithms. N Engl J Med. 2020;383(9):874–882. doi:10.1056/nejmms2004740
留言 (0)