
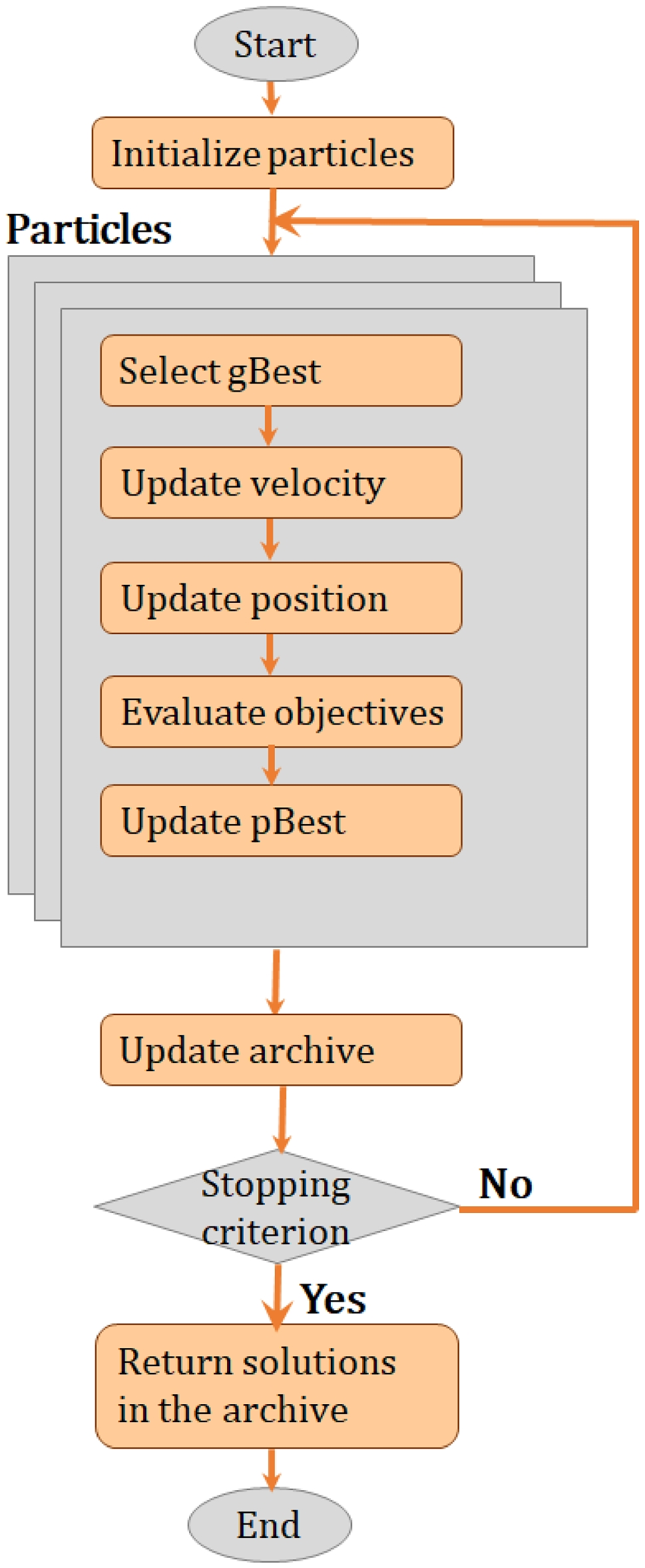
記住我




As concerns text data for experiments, the “Reuters-21578” data set and the “Abstracts” data set have been used. Reuters-21578 is a benchmark data set for document classification consisting in 8 classes. The collection of documents appeared on the Reuters news-wire in 1987. The documents were assembled and indexed with categories by personnel from Reuters Ltd. [81]. The adopted splitting is the “ModApte” split [82] on 7674 documents and 8 classes. The “Abstracts” data set is a collection of 575 abstracts of scientific papers belonging to 5 classes (‘Anatomy’, ‘Information theory’, ‘Smart Grid’, ‘String Theory’, ‘Semiconductors’), collected by authors. Some statistics on the experimented data sets are reported in Tables 1 and 2. The former provides some general information about the data set, while the latter reports some statistic per class, such as the mean and standard deviation of document length per class.
Table 1 Data set statistics (in brackets it is reported the standard deviation)Table 2 Data set statistics per class (in brackets it is reported the standard deviation)Specifically, in Table 1 the total number of documents (\(\#\) docs), the dimension of the vocabulary before pre-processing (\(\left| \mathcal \right|\)), the dimension of the vocabulary after the pre-processing (\(\left| \mathcal \right| _\)), the number of classes (\(\#\) class) and the average length of documents in terms of tokens (words) (\(\left| \bar\right|\)) with standard deviation in brackets are reported. In Table 2 the class names (class), the average length of documents in term tokens (words) (\(\left| \bar\right|\)) with standard deviation in brackets and the number of documents per class (\(\#\) docs) are reported. In Fig. 5 the statistics on document lengths per class and for each data set are reported, while in Fig. 6 the histograms of the length of documents for both data sets are depicted. This information will be useful for setting the sequence length parameter for experiment with the LSTM algorithm.
Fig. 5
Document length per class
Fig. 6
Document length histogram
Fig. 7
Class distribution for the experimented data sets
In Fig. 7 the class distributions for both the data sets are reported. We note that the “Reuters-21578” data set has a heavy skewed class distribution leading to a strong unbalanced data set, making challenging the classification task, while the “Abstracts” data set classes are equally distributed.
Experimental SettingsAs concerns the performance measures of the classifiers, several metrics for the multi-class case are adopted.
Specifically, considering the i-th class (\(i=1,2,...|C|\)) of the available data sets it is possible to define:
\(TP_i\) (true positive): number of patterns belonging to the i-th class and correctly classified by the system;
\(FN_i\) (false negative): number of patterns belonging to the i-th class whose class is incorrectly assigned to the \(i_th\) class predicted by the system;
\(FP_i\) (false positive): number of patterns not belonging to the i-th class whose class is incorrectly by the system.
\(TN_i\) (true negative): number of patterns belonging to the i-th class and correctly classified by the system.
Starting from these metrics a set of derived indicators for each class can be computed, such as the \(Accuracy_i\), \(Precision_i\) and \(Recall_i\) together with other global figures of merit, such as the Informedness and the Cohen’s Kappa. Besides these metrics, the global classification performances can be assessed in two ways: (i) macro-averaging that is the average of the same measure calculated for each class, (ii) micro-averaging that is the sum of counts to obtain cumulative TP, FN, TN, FP and then calculating the performance measure. Macro-averaging treats all classes equally while micro-averaging favors classes characterized by a relative higher number of patterns [83].
The final metrics adopted in the current study are (the higher, the better):
the average Accuracy (Acc.) in [0,1], that is the average per-class effectiveness of a classifier;
the Precision (P) in [0,1], that is the fraction of relevant instances among the retrieved instances by the classifier;
the Recall (R) in [0,1], that is the fraction of the total amount of relevant instances that were actually retrieved by the classifier;
the Informedness (Inf.) in [0,1] — known as J-index — is the maximum distance between the bisector diagonal line of the Receiver operating characteristic (ROC) [84] diagram and the ROC curve estimated. It indicates the probability of an informed decision compared to a chance;
the Cohen’s kappa (kappa) in [0,1] that, considering the classification task as a rating process, measures inter-rater reliability (sometimes called inter-observer agreement) [85];
the macro F1 score (Fmacro) in [0,1] that is the unweighted mean of the F1 scores calculated per class, where \(F1= \frac\) [83];
the micro F1 score (Fmicro) in [0,1] the same expression as Fmacro, but using the total number of TP, FP and FN, instead of computing these scores for each class [83].
The experimental settings are organized as follows.
In order to assess the proposed approach, two main sets of experiments are provided. The first set aims at comparing the three learning algorithms (namely, LSTM, C-SVM, RF) adopting both the word2vec and the LSA embedding, for both “Abstracts” and “Reuters-21578” data sets. The embedding is computed on the given corpus. In this case the cardinality of the alphabet \(\mathcal \), that is the number of clusters k or the number of concept regions, is left to vary in the integer range [2,1002] (see Fig. 8), while a snapshot of the performance, for \(k=502\), is provided in Table 3 for the “Reuters-21578” data set and, for \(k=202\), in Table 4 for the “Abstracts” data set. The specific choice of the granularity level k has been made simulating an arbitrary setting where we have no information about the variability of the performance as function of the granularity level. In other words, this setting simulates the case in which the performance cannot be computed for an increasing set of granularity levels due to, for example, computational and time constraints. The best granularity level, instead, is considered in the second set of experiments. In fact, the second set of experiments — reported in Tables 5 and 6 — allows evaluating and comparing the proposed methodology with a baseline approach. Specifically, for the mentioned learning algorithms the best level of granulation k in terms of performances is compared with a classical approach where the feature vectors representing documents are obtained either from the TF-IDF representation or from the LSA representation. In other words, the features for the classification task are the TF-IDF weighted words count or the weights related to the latent variables, respectively. In the end, taking advantage of the implicit features weighting offered by the RF algorithm, a task of knowledge discovery is performed. Hence, a threshold filtering is adopted in order to select and show the most important concepts within the concept region that, in turn, allowed reaching a good classification performance. Before discussing the main results, it is worth to deal with the text pre-processing steps and the parameter setting of the adopted learning algorithms.
Regarding the pre-processing steps, words in documents are lowercased and stop words are eliminated using a stop words list.
As concerns the LSTM algorithm, it is preceded by a word embedding layer (through the word2vec algorithm) — namely a concept embedding layer — with a dimension of the word vectors equal to 100. The LSTM layer foresees 180 cells followed by a fully connected layer and a softmax layer. The classification layer computes the cross entropy loss for multi-class classification problems with mutually exclusive classes. The maximum number of epochs is set to 50, while the initial learning rate is set to 0.005. In the case of SVM, a C-SVM with multiple kernels is used. A set of hyper-parameters are optimized with the Bayesian optimization technique and 5-fold cross validation. Specifically, the hyper-parameters optimized are the multi-class coding (One-versus-All and One-versus-One), the Box Constraint, the scale of the kernel, the type of kernel function (Gaussian, linear, polynomial), the polynomial order and the binary variable indicating whether standardize data or not. For the ensemble learning, an ensemble of boosted classification trees is experimented, hence with trees as weak learners. Even in this case, a Bayesian hyper-parameters optimization has been chosen and 5-fold cross validation is performed. In particular the optimization of the training algorithm (Bag, Subspace, AdaBoostM1, AdaBoostM2, GentleBoost, LogitBoost, LPBoost, RobustBoost, RUSBoost, TotalBoost) and the number of learning cycles [80, 86,87,88]. The OOB performance is measured for establishing the predictor importance.
Where not specified, for robustness purposes, the optimizations of hyper-parameters or the simple learning routines (for example, in LSTM) are repeated three times and performance results are averaged. The data set splitting for the training set \(\mathcal _\) and test set \(\mathcal _\) is 80%, 20%, respectively, both for C-SVM and RF. In the case of LSTM the data set is split in training set \(\mathcal _\), validation set \(\mathcal _\), test set \(\mathcal _\) with the following percents: 50%, 25%, 25%, respectively.
Results and Granularity AssessmentFixing the concept granularity value to \(k=202\) — see Table 4 — where the three classification algorithms are compared both with the word2vec embedding and the LSA embedding in building the concept space over the “Abstracts dataset” (that is balanced), best classification performances in term of Accuracy (0.94) are obtained with C-SVM with word2vec. The second best performances are obtained with RF and C-SVM (Accuracy 0.93) with the LSA embedding. LSTM reaches lower performances on both embeddings with an Accuracy of 0.85 for word2vec and 0.87 for the LSA embeddings. Interestingly, if we compute the figures of merits as the granularity of the concept space increases (varying k), by inspection of Fig. 8, it is found that with a very low number of concepts all classifiers achieve higher performances that, in turn, stabilize till the end of the experimented range (\(k=1002\)). A similar behavior can be found analyzing the “Reuters-21578” data set. Here the granularity level is fixed to \(k=502\). Also in this case the performance in terms of classification capability increases quickly rising k (graphs not shown for the sake of brevity). However, in this case, examining the results reported in Table 3, the higher Accuracy value is attained by C-SVM (0.95 with LSA embedding), but even the LSTM obtains a good Accuracy (0.94 with word2vec embedding).
If we consider the classification task as a rating process, Cohen’s kappa coefficient is low for LSTM and RF, for both embeddings, but reaches the highest value for C-SVM with word2vec embedding. In terms of Fmicro and Fmacro C-SVM obtains its best results with the word2vec embedding. The best informed decision, taking into account the unbalance of the “Reuters-21578” data set is achieved by C-SVM with Informedness of 0.86 (LSA embedding). In general, as an expected behavior, we have a moderate variability of the classifiers’ performances for both embeddings and data sets. The low Accuracy attained by LSTM for the “Abstracts” data set is likely to be addressed to the low granularity level and the short dimension of the data set, in terms of the number of documents and documents length. However, if we look at results for the best granularity level reported in Table 6 (“Abstracts” dataset), where the three classifiers are compared for both embedding types and with the TF-IDF features, LSTM obtains better performances with Accuracy 0.90 (word2vec embedding for best \(k=222\)) and 0.92 (LSA embedding for best \(k=162\)), outperforming the plain case (Accuracy 0.70), where sequences are directly generated without conceptualizing the corpus. In this particular setting, C-SVM with LSA embedding, for the best \(k=382\), outperforms both LSTM and RF. For C-SVM the LSA embedding adopted for constructing the conceptual space is found better than the TF-IDF case (Accuracy 0.98 and 0.96, respectively). It is worth to note that for both C-SVM and RF the results for the plain case (TF-IDF feature space) are good (RF attains an Accuracy of 0.97 for \(k=342\) and 0.95 with TF-IDF) in spite of the high dimensionality of the features space. This confirms the capability of both classifiers to work well in high-dimensional spaces. Both algorithms achieve high Accuracy and high Informedness for a similar granularity level above \(k=300\) in the LSA embedding case, while LSTM obtain even good performances (Accuracy 0.92) with the same embedding with a very low granularity (\(k=162\)). Furthermore, considering the “Reuters-21578” data set on the same experimental setting, we have C-SVM that outperforms the other classifiers in terms of Informedness and Fscores in TF-IDF case, with a not so great separation from the LSA embedding with a granularity level of \(k=722\). For this data set even LSTM achieves good results in terms of Accuracy and Informedness, specially for the word2vec embedding (Accuracy 0.95, Informedness 0.82, Fmicro 0.95, Fmacro 0.83). Similar performances are obtained with RF that only in the word2vec embedding case outperforms the TF-IDF setting. In fact, for the LSA embedding, despite the high granularity level (\(k=962\)) the TF-IDF setting attains a high Accuracy (0.95 v.s. 0.93) and a higher Informedness (082 v.s. 0.89). A similar behavior can be found for the Fmicro and Fmacro and for the kappa coefficient. Comparing the two data sets, that are very different in their structure and contents, the granularity level needed for attaining good results is found proportional to the complexity of the data set itself. In fact, the “Abstracts” data set consists of a set of short documents and each class is well separated in term of contents, at least at a semantic point of view. The “Reuters-21578” data set possesses more classes that are strongly unevenly distributed (see Fig. 7). For both data set, the conceptualization does not degrade the results, instead we obtain good performances with a lower granularity level. This means a low complexity of the feature space, that instead to be equal to the cardinality of the vocabulary (in the plain TF-IDF case) it matches the number of concepts adopted for representing the documents.
In the current experiments, there is no supremacy among the word2vec and the LSA in building the concept space. In fact, even if for both embeddings a smaller concept space attains good performances, there are classifiers that perform well for LSA and classifiers that do the best for the word2vec embedding. It is well known that both the embeddings possess suitable semantic characteristics, and the general performances depend on the entire processing chain and the particular hyper-parameter settings.
In general, the granulation of the word embedding space can be seen as a dimensionality reduction paradigm at the cost of inserting a new block in the downstream processing of texts before the classification task. However, this conceptualization block can be constructed once and for all even adopting richer corpora (e.g., Wikipedia), conversely to the one employed for the specific classification task. It is important to take care of the granulation parameter, significant for the classifier performances due to their attitudes in working with high or low dimensionality.
Towards the Explainable AI paradigmThe choice of the three particular classification algorithms depends on their specific characteristics. In fact, if from one hand SVM is known to be performing even with high dimensional feature spaces embedded in \(\mathbb ^n\), LSTM is suitable with sequences and needs a further dense layer to be appropriate for classification tasks. RF, for its part, is suited for classification tasks where it is important also estimating the importance of features. In fact, RF offers the possibility to obtain a set of weights, as many as the number of features, that, in turn, in this study are a kind of superordinate word, we call concepts. Fixing an arbitrary threshold over these weights leads to estimate the strongest concepts related to the specific classification task. From a different point of view, this procedure can be seen as a concept filtering task, where only the strongest ones survive. This methodology can help to infer knowledge on the corpus, eliciting the Explainable AI paradigm.
In Fig. 9(a), (b), as a bar chart, the weights related to the concepts and the thresholds (fixed to the 20% of the largest weight value), for the “Reuters-21578” and “Abstracts” data set, respectively, are depicted. For these specific experiments, for brevity purposes, the granularity of the concept space is fixed to \(k=50\) and it is constructed through the word2vec neural embedding. It is worth to note that the CSS is obtained through the k-means clustering algorithm, thus the prototype, being the average word vector for a given concept region, is a surrogate word vector. So forth, in order to find the existing word related to the prototype, the \(\ell _2\) norm distance is computed selecting the nearest word vector and the corresponding token. In Tables 7 and 8 the survived concepts together with the nearest five words obtained computing a \(\ell _2\) norm between the prototype and the respective word vectors are reported, normalizing for the highest similarity value that hold for the closest existing word vector to the prototype. In case of clusters with cardinality lower than five, all words within the cluster are shown. For the “Abstracts” data set, the best closest prototypes, for a given threshold value, are holographic, concurrently, explicitly, explanation, succesfully, achieve, intrusiveness, leastsquares, pregnancy, furthermore, nonabelian, effectiveness, percutaneous, approximation, nanolasers, robustness, insulator, chalcogenide, rolling, infrared. From Table 7, selecting, for example, a populated region, such as the fourth and considering the closest word (concurrently) to its prototype, we have electrification, resistant, diameter, platform, industrial. In general, we can find high semantic words that elicit roughly which term the algorithm estimates as important for the classification task; in fact, besides words with high semantic content, we can find verbs (for example, achieve) or other lexemes that are mostly used in papers’ abstracts. The same rationale can be found behind the results for the “Reuters-21578” data set illustrated in Table 7. Here, we can find less singleton or low-populated clusters, due to the dimension of the corpus. Even in this case it can be found a set of prototype words that span uniformly the conceptual space. Nevertheless, the richness of the semantic contents of prototypes and the underlying word cloud is attributable to the dimension and the heterogeneity of the corpus, since it is likely to lead to better representations for words, that in turn, leads to a performing CSS.
Table 3 Classification performances for a given granularity level k for LSTM, C-SVM and RF (“Reuters-21578” data set)Table 4 Classification performances for a given granularity level k for LSTM, C-SVM and RF (“Abstracts” data set) Fig. 8
Classification performance varying the number of concept regions from 2 to 402 (“Abstracts” data set) for the LSTM, SVM, RF algorithms, for both word2vec and LSA techniques
Table 5 Performances comparison over the “Reuters-21578” data set between LSTM, C-SVM and RF for both word2vec and LSA embeddings. Results of the best granulation level k are compared with the plain solution given by a sequence formed by the word vectors related to words in the given text for LSTM, and the TF-IDF weighting scheme for the other classifiers Table 6 Performances comparison over the “Abstracts” data set between LSTM, C-SVM and RF for both word2vec and LSA embeddings. Results of the best granulation level k are compared with the plain solution given by a sequence formed by the word vectors related to words in the given text for LSTM, and the TF-IDF weighting scheme for the other classifiers Fig. 9
Concept importance for the “Reuters-21578” (a) and “Abstracts” (b) data sets. The threshold value filters low importance concepts. The value is set as the half of the max value computed on concept importance
Table 7 Most important concepts obtained by filtering the Concept Regions through the feature importance estimation provided by the RF algorithm (“Reuters-21578” data set). There are reported the first five words for each region that exceed a threshold value — see Fig. 9(a) Table 8 Most important concepts obtained by filtering the Concept Regions through the feature importance estimation provided by the RF algorithm (“Abstracts” data set). There are reported the first five words for each region that exceed a threshold value — see Fig. 9(b)
留言 (0)