
記住我
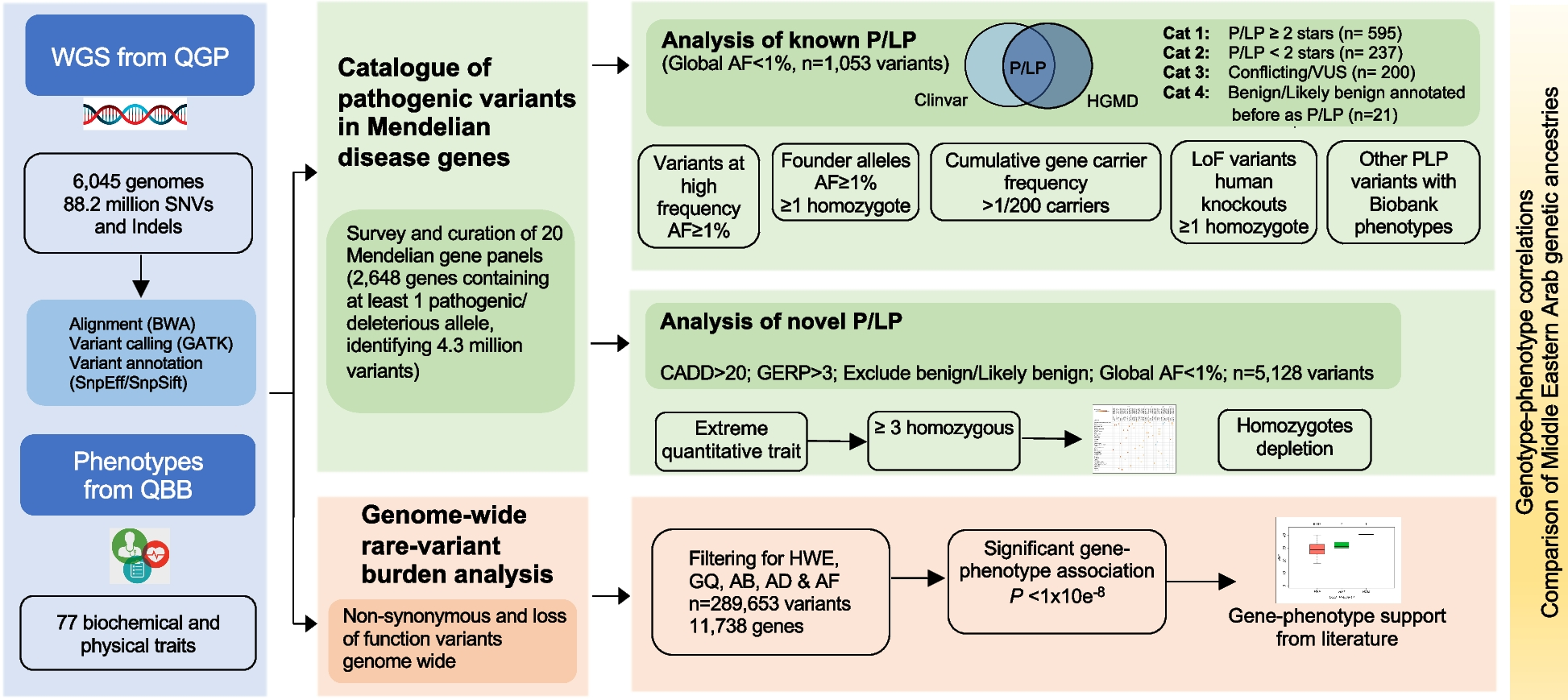
Previous work [10, 12, 23], including our own [14], has demonstrated the utility of HPO-based, CNLP-derived phenotype descriptions for post sequencing diagnostic applications. Here, we explore the feasibility of using CNLP phenotype descriptions, manufactured using the same NLP protocols, for triaging patients for WGS. To do so, we combined a natural language processing (NLP) workflow based around the commercially available CLiX tool [19] with an ML-based prioritization tool we call MPSE, the Mendelian Phenotype Search Engine.
MPSE (see the “Methods” section) employs the Human Phenotype Ontology (HPO) [11] to prioritize patients. The a priori likelihood that a patient has a Mendelian condition is a computed probability based on the existence of HPO terms in the patient’s phenotype that are similar to those patients who previously had WGS. To investigate feasibility, we utilized curated RCHSD clinical data: 1049 level IV NICU admissions and their clinical notes. Of these 1049 patients, 293 had rWGS and 85 received a molecular diagnosis. We validated the results presented below using leave-one-out cross validation; see the “Methods” section for details. To examine the broader applicability of the RCHSD training data to other NICUs, we also carried out a second independent replication study using the clinical notes of 2965 patients from the University of Utah level III NICU.
Automated generation of HPO termsWe obtained HPO phenotype descriptions for all probands from clinical notes using Clinithink, a third party NLP tool [19]. Automatically generating phenotypic descriptions via NLP is a major strength, as it enables the creation of large and dynamic pools of HPO-based phenotype descriptions for downstream prioritization activities.
Comparison of the CNLP descriptions to their corresponding manually compiled ones revealed notable differences with regards to HPO term numbers and contents. The CLiX generated descriptions for the RCHSD and NeoSeq cohorts had an average of 114.8 terms (min: 3, median: 91, max: 1000) and 64.5 terms (min: 1, median: 58, max: 300) respectively, whereas the corresponding manually created descriptions averaged 4.1 terms (min: 1, median: 3, max: 24) and 9.5 terms (min: 3, median: 9, max: 16) respectively.
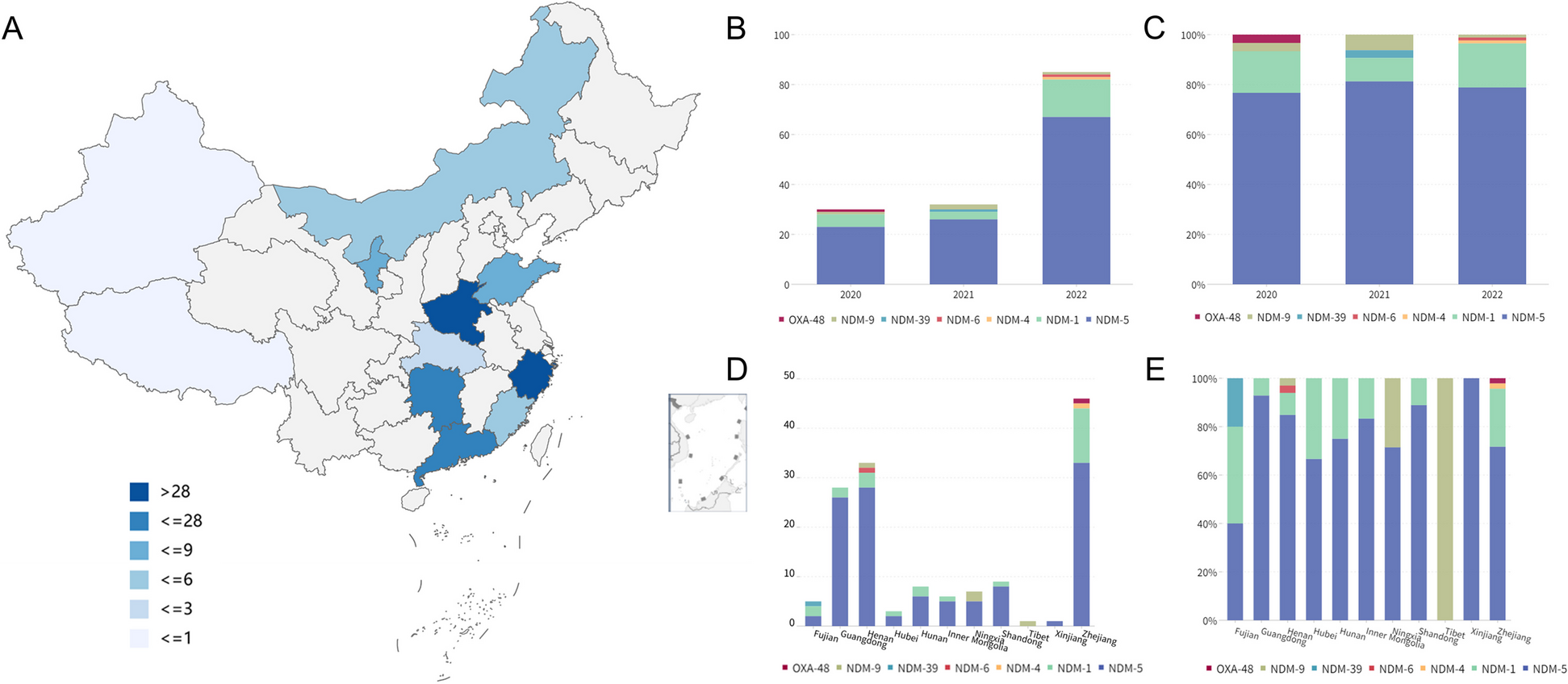
Prioritizing patientsWe first sought to evaluate how effective our CNLP/MPSE pipeline was at prioritizing patients for WGS. In other words, did the children originally selected for WGS by physicians have higher MPSE scores than those who were not selected? Figure 1 demonstrates that this is the case. As can be seen, the distributions of MPSE raw scores for the RCHSD and Utah WGS-selected children are well-separated from unsequenced ones. RCHSD sequenced cases had an average MPSE score of 26.6 while unsequenced controls had an average score of − 31.7, statistically different by Student’s independent samples t-test (p < 2e−16). The difference in mean MPSE score between Utah sequenced cases (17.3) and unsequenced controls (-33.7) was also statistically different (p = 2e−12). The insert shows a receiver operator characteristic (ROC) curve for the RCHSD data (AUC 0.86), indicating that MPSE can effectively prioritize probands for rWGS. The corresponding AUC for the Utah data was 0.85, essentially identical to the RCHSD result (ROC curve not shown). A possible clinical application scenario can be imagined where MPSE score cutoffs are used to prioritize patients for further review by physicians. For the RCHSD training cohort described here, for example, taking only MPSE scores > 30 would prioritize 30% (89/293) of cases and 4% (31/756) of controls, while taking only MPSE scores > 90 would prioritize 14% (40/293) of cases and 0.8% (6/756) of controls. Anonymized MPSE scores for each patient in these cohorts are tabulated in Additional file 1: Tables S3 and S4.
Fig. 1
Automatically identifying probands with Mendelian phenotypes and prioritizing them for WGS using NLP-derived HPO phenotype descriptions. Distributions of MPSE raw scores for RCHSD sequenced (red) and RCHSD unsequenced (blue) probands. Score distributions for Utah NeoSeq (green) and Utah unsequenced probands (purple). Insert: Receiver operator characteristic (ROC) curve for RCHSD data. MPSE scores are -log likelihood ratios
Cardinal phenotype termsMPSE also provides means to identify, and highlight for expert review, those terms in a phenotype description that are most consistent with Mendelian disease. We refer to these terms as the proband’s cardinal phenotypes. Figure 2 shows a CNLP phenotype description as a word cloud, wherein font sizes have been scaled by their individual contributions to the proband’s final MPSE score; those with the highest scores are shown in red; these are the proband’s MPSE cardinal phenotypes. These views of the patient’s phenotype description are designed to speed physician review and improve explainability.
Fig. 2
An automatically generated HPO-based phenotype description scored by MPSE. In this word-cloud, size and color are proportional to each HPO term’s contribution to the proband’s final MPSE prioritization score. Previously diagnosed by RCHSD using WGS, this child is heterozygous for a large deletion on the X chromosome which spans the PCDH19 gene, causative for female-restricted X-linked epileptic encephalopathy
MPSE diagnostic ratesTo estimate MPSE-driven diagnostic rates, RCHSD and University of Utah sequenced probands were scored using leave-one-out cross validation, as described in the “Methods” section. The diagnostic fraction for these cohorts was 29% (85/293) and 43% (15/35), respectively. It should be borne in mind that this RCHSD diagnostic rate is for the specific dataset under analysis. It is not the RCHSD institutional WGS diagnostic rate. To facilitate comparison between these groups, we randomly re-sampled the larger RCHSD dataset so that it too had a 43% (85/198) diagnostic rate.
Figure 3 shows projected diagnostic rates for these cohorts as a function of their MPSE scores. The negative slopes of the red, green, and blue curves indicate that when using CNLP, higher MPSE scores are associated with diagnosed probands at both institutions. For instance, the top 25% of probands ranked on their MPSE scores from CNLP-generated phenotypes show very high diagnostic rates, approaching 100% for the highest MPSE scores. Moreover, for the CNLP datasets, diagnostic rates remain at or above the cohort diagnostic fraction of 43% at every MPSE score percentile. In contrast, the MPSE scores calculated from manually curated phenotypes (gray curve) are at best weakly associated with diagnostic status. This is not a result of inferiority of the physician-generated phenotypes; rather, it is due to the fact that MPSE was trained using deep CNLP-derived phenotype data; recall that CNLP compared to manual review resulted in 64.5 vs 9.5 HPO terms/proband, respectively. Collectively, these results indicate that an MPSE-based prioritization pipeline in conjunction with manual review could increase diagnostic rates above those obtained solely through expert manual case-review.
Fig. 3
MPSE projected diagnostic rates. Higher MPSE scores correspond to increased probability of diagnosis, and projected diagnostic rates remain at or above the cohort diagnostic fraction of 43% at every MPSE score percentile
Impact of note typesBoth RCHSD and the University of Utah limit manual review of clinical notes to a subset of note types deemed most informative by their institution’s expert reviewers. This is done to speed review by avoiding less informative and redundant note types. A potential advantage of CNLP is that volume is no longer an issue, and every note can be processed. We thus sought to evaluate the utility of processing all notes for every proband. The results of this experiment are also shown in Fig. 3, where the blue and green curves summarize diagnostic enrichment as a function of MPSE score and note volumes. AUC for the top 50% of high scoring probands using all clinical notes vs. using only the selected note types is quite similar—62% and 65%, respectively. Thus, for the Utah dataset, using all available notes for every proband does not negatively impact diagnostic rates.
Impact of patient populationsIt is worth noting that underlying NICU populations differ between RCHSD and the University of Utah. Whereas RCHSD is a level IV NICU, the University of Utah operates a level III NICU, with the most severely ill patients transferred to Intermountain’s Primary Children’s neighboring level IV facility. Thus, patients in the Utah dataset are likely to have fewer conditions requiring surgical interventions and a higher level of intensive care. Despite being trained using the RCHSD level IV data, Fig. 1 makes it clear that the lesser acuity of level III patients compared to level IV patients did not interfere with MPSE’s ability to identify suitable candidates for sequencing nor did it negatively impact the correlation between MPSE score and Mendelian diagnostic rates (Fig. 3). This finding suggests MPSE’s robustness to differences in NICU patient populations.
留言 (0)