
記住我








Enhanced by deep neural networks (DNNs), reinforcement learning (RL) (Sutton and Barto, 2018) empowers the agent to optimize its policy and solve difficult tasks by interacting with the task environment and exploiting the collected trajectories, which has made great breakthroughs in game playing (Vinyals et al., 2019), robotic locomotion (Hwangbo et al., 2019), robotic manipulation (Bai et al., 2019), etc. In standard RL, the policy is optimized for a single implicit goal embedded in the task, which cannot satisfy many practical tasks (e.g., robotic manipulation tasks) where the RL agent is required to understand multiple human control instructions and act toward various goals (Veeriah et al., 2018). Based on universal value function approximators (UVFAs) (Schaul et al., 2015), goal-conditioned RL (GCRL) (Colas et al., 2022) is proposed to accomplish these tasks by leveraging the goal-conditioned value network and policy network. The RL agent is optimized by goal-labeled trajectories with goal-specific rewards. However, when designing the goal-conditioned reward function, performing appropriate reward shaping (Badnava and Mozayani, 2019) for each goal is unrealistic, which makes the sparse reward setting become a common choice. Under this setting, the positive rewards are only sparsely set at some key nodes (e.g., when task goals are achieved). As a result of the lack of sufficient directive signals from the reward function, the RL agent inevitably meets the hard exploration problem (Ecoffet et al., 2019), which traps the policy optimization and goal attainment.
To overcome the hard exploration problem, because modifying goals in GCRL does not affect the environment dynamics, hindsight experience replay (HER) (Andrychowicz et al., 2017) is proposed to discover learning signals from the collected trajectories by relabeling the failed goal-reaching trajectories with their already achieved goals. However, this method only works fine when the task goals are continuous or densely distributed (e.g., setting the destination coordinates of objects as goals). For discrete or sparsely distributed goals in the form of semantic configurations (Akakzia et al., 2021) or natural language (Colas et al., 2020), which more conform to the human habits of giving instructions, the trajectories that can achieve the concerned goals account for a rather small proportion. Only from these trajectories can the goal relabeling method discover useful learning signals. The other trajectories cannot be finely evaluated and differentiated just by the sparse external rewards, no matter if goal relabeling is done.
In this paper, we focus on leveraging the sparse-reward GCRL to solve the robotic manipulation task with semantic goals. Since relying on only the external reward function makes it difficult to discover more useful learning signals, curiosity-motivated exploration methods become possible solutions, which generate intrinsic rewards to encourage the agent to explore novel states (Ostrovski et al., 2017; Burda et al., 2018b; Lee et al., 2020) or discover unlearned environment dynamics (Stadie et al., 2015; Houthooft et al., 2017; Pathak et al., 2017). However, the previous curiosity-motivated methods are not well compatible with the GCRL tasks, which we summarize into two aspects: uncontrollability and distraction. Because the agent cannot distinguish which novel states are more beneficial to the task, uncontrollability denotes that the task-irrelevant or even dangerous novelties will mislead the agent and cause the “noisy TV” problem (Pathak et al., 2017) to trap the exploration process. In curiosity-motivated methods, the agent policy is optimized by the weighted combination of the external rewards and the intrinsic rewards, which means the combined policy actually has two optimization objectives. Thus, the combined policy cannot be best optimized for the original goal-pursuing objective, and the agent will even be distracted by the dynamically varying intrinsic rewards to visit the intrinsic novelties instead of pursuing the goals. Comparison between our MIHM and previous curiosity-motivated methods is shown in Figure 1.
Figure 1. Comparison between our MIHM and previous curiosity-motivated methods. The previous curiosity-motivated methods have two defects, uncontrollability and distraction, which deteriorate their performance in semantic-GCRL. Comparatively, our MIHM contributes two innovations, the decoupled-mutual-information-based intrinsic rewards and hybrid policy mechanism, which effectively solve these defects.
To accomplish the sparse-reward semantic-goal-conditioned robotic manipulation task by curiosity-motivated exploration, we propose a conservative curiosity-motivated exploration method named mutual information motivation with hybrid policy mechanism (MIHM), which successfully solves the defects of uncontrollability and distraction in the previous curiosity-motivated methods. The conservativeness in our method is embodied in two aspects. Firstly, we design a more conservative decoupled-mutual-information-based intrinsic reward generator, which encourages the agent to explore novel states with controllable behaviors. Secondly, the utilization of the curiosity-motivated exploration is more conservative. We construct a PopArt-normalized (Hessel et al., 2018) hybrid policy architecture, which detaches the goal-pursuing exploitation policy and precisely trains the curiosity-motivated exploration policy. Based on the two policies, we propose a value-function-based automatic policy-switching algorithm, which eliminates the distraction from the curiosity-motivated policy and achieves the optimal utilization of exploration and exploitation. In the robotic manipulation task proposed by Akakzia et al. (2021) with 35 different semantic goals, compared with the state-of-the-art curiosity-motivated methods, our MIHM shows the fastest learning speed and highest success rate. Moreover, our MIHM is the only one that achieves stacking three objects with just sparse external rewards.
2. Related workFacing the hard exploration problem in sparse-reward semantic-GCRL, the agent is urgently required to improve its exploration ability toward unfamiliar states and unlearned semantically valid skills. An RL algorithm based on the DNNs can be more inclined to explore by adding action noise [e.g., the Gaussian noise or Ornstein-Uhlenbeck noise in deep deterministic policy gradients (Silver et al., n.d.)] or increasing action entropy [e.g., the entropy temperature adjustment in soft actor-critic (Haarnoja et al., 2018)]. However, lacking the exploitation of more environmental features, the above action-level exploration cannot help the agent to be aware of the states or state-action pairs that are potentially worth pursuing, which does not satisfy the circumstances when the state space or task horizon is expanded. Inspired by the intrinsic motivation mechanism in psychology (Oudeyer and Kaplan, 2008), intrinsically rewarding the novel state transitions is proven to be an effective method to motivate and guide the agent's exploration, which is named curiosity-motivated exploration. The intrinsic rewards are mainly generated for two purposes: increasing the diversity of the encountered states (Ostrovski et al., 2017; Burda et al., 2018b; Lee et al., 2020) and improving the agent's cognition of the environment dynamics (Stadie et al., 2015; Houthooft et al., 2017; Pathak et al., 2017).
For the first purpose, the intrinsic reward can be determined based on the pseudo count of the state (Ostrovski et al., 2017; Tang et al., 2017), where lower pseudo count means a rarer state and a higher reward. To gain adaptation to the high-dimensional and continuous state space, in recent years, the pseudo count has been realized by DNN-based state density estimation (Ostrovski et al., 2017) or hash-code-based state discretization (Tang et al., 2017). Moreover, the state novelty can also be calculated as the prediction error for a random distillation network (Burda et al., 2018b), which overcomes the inaccuracy of estimating the environment model. Another state novelty evaluation method is based on reachability (Savinov et al., 2018). By rewarding the states that cannot be reached from the familiar states within a certain number of steps, the intrinsic reward can be generated more directly and stably.
For the second purpose, the prediction error of the environment dynamics model can be used as the intrinsic reward. (Burda et al., 2018a) proved that, for training the environment dynamics model, it is necessary to use the encoded state space rather than the raw state space. They proposed an autoencoder-based state encoding function. (Pathak et al., 2017) proposed a self-supervised inverse dynamics model to learn to encode the state space, which is robust against the noisy TV problem. Moreover, the environment forward dynamics can be modeled by variational inference. (Houthooft et al., 2017) proposed motivating exploration by maximizing information gain about the agent's uncertainty of the environment dynamics by variational inference in Bayesian neural networks, which efficiently handles continuous state and action spaces.
In games (Vinyals et al., 2019) or robotic locomotion tasks (Hwangbo et al., 2019), the agent is often required to explore states as diverse as possible. The curiosity-based intrinsic rewards are consistent with the task objectives and show great performance. Moreover, replacing the traditional timestep-limited exploration rollouts, the infinite time horizon setting (Burda et al., 2018b) is often adopted in these tasks to further facilitate the discovery of novel information in the environment. However, in goal-conditioned robotic manipulation tasks, the agent is required to discover fine motor skills about the objects, which makes uncontrollably pursuing too diverse states easily cause interference. The intrinsic rewards are required to work as the auxiliaries for the external goal-conditioned rewards. Thus, it is necessary to improve the previous curiosity-motivated methods to solve the defects of uncontrollability and distraction. In our MIHM, we propose to improve the quality of intrinsic rewards and the utilization method of curiosity-motivated exploration.
3. Preliminaries 3.1. Goal-conditioned reinforcement learningThe multi-step policy-making problem that RL concerns can be formulated as a Markov decision process (MDP) (Sutton and Barto, 2018) M=<S, A, P, R, γ>, where S, A, P, R and γ represent the state space, action space, state transition probabilities, rewards, and discount factor, respectively. At timestep t, once interacting with the task environment, the agent can obtain a reward rt for the state transition < st, at, st+1 > by a predefined external reward function r. The discounted accumulation of future rewards is called return: Rt=∑i=t∞γi-tri. The policy π:S→A that RL optimizes is to maximize the expected return ?so~p(s0)[Vπ(s0)], where the state value function Vπ(st)=?π[Rt|st]. In practice, instead of Vπ(st), the state-action value function Qπ(st,at)=?π[Rt|st,at] is often used, which can be updated by bootstrapping from the Bellman equation (Schaul et al., 2016). Leveraging the representation ability of the DNNs, the application scope of RL is extended from tabular cases to continuous state space or action space. The well-known RL algorithms include deep Q-networks (DQN) (Mnih et al., 2013), deep deterministic policy gradients (DDPG) (Silver et al., n.d.), twin delayed deep deterministic policy gradients (TD3) (Fujimoto et al., 2018), soft actor-critic (SAC) (Haarnoja et al., 2018).
In GCRL, the goal space G is additionally introduced, where each goal g∈G corresponds to an MDP Mg=<S, A, P, Rg, γ>. Under different goals, the same transition will correspond to different rewards. To avoid the demand of the specific Vπg(s), Qπg(s,a) and πg(s) for every goal g, UVFAs are proposed to use the DNN-based goal-conditioned Vπ(s, g), Qπ(s, a, g) and π(s, g) to universally approximate all the Vπg(s), Qπg(s,a) and πg(s). The optimization objective of GCRL becomes balancing all the goals and maximizing ?so~p(s0)g~p(g)[Vπ(s0,g)]. The universal approximators can be updated by the similar bootstrapping techniques in standard RL algorithms and are helpful to leverage the shared environmental dynamics across all the goals. Schaul et al. (2015) proved that, with the help of the generalizability of DNNs, the universal approximators can even generalize to the previously unseen goals, making it possible to use finite samples to learn policies for infinitely many or continuously distributed goals.
3.2. Semantic-goal-conditioned robotic manipulationCompared with giving the precise destination coordinates, goals with semantic representations more conform to human habits and can contain more abstract and complicated intentions. In this paper, the semantic goal representations we concern are derived from Akakzia et al. (2021), where two semantic predicates, the close and the on binary predicates, c(·, ·) and o(·, ·), are defined to describe the spatial relations “close to” and “on the surface of” for the object pairs in the task environment. For example, o(a, b) = 1 expresses that object a is on the surface of object b. Furthermore, the joint activation of the predicates can express more complicated intentions. Because the close predicate has order invariance, considering the task with 3 objects a, b and c, a semantic goal g is the concatenation of 3 combinations of the close predicate and 6 permutations of the on predicate, as
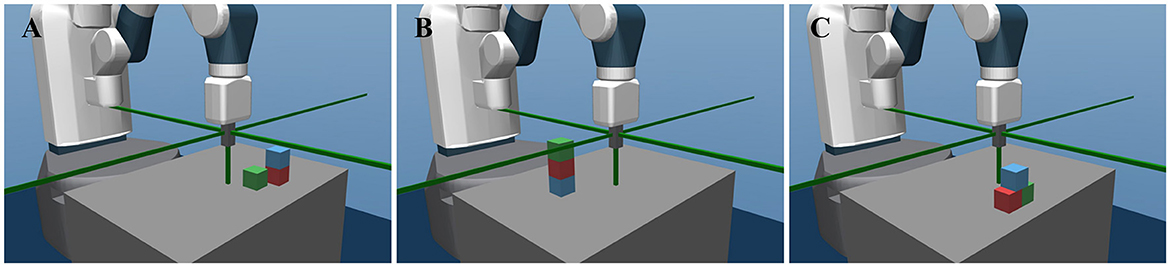
g=[c(a,b),c(a,c),c(b,c),o(a,b),o(b,a),o(a,c),o(c,a), o(b,c),o(c,b)]. (1)Thus, in the semantic configuration space 9, the agent can reach up to 35 physically valid goals, including stacks of 2 or 3 objects and pyramids, as Figure 2 shows. A simulation environment for this manipulation task is built based on the MuJoCo (Todorov et al., 2012) physics engine and OpenAI Gym interface (Brockman et al., 2016).
Figure 2. The robotic manipulation environment and three examples of the semantic configurations. (A) Shows the stack of 2 blocks, with the semantic configuration [111000100]. (B) Shows the stack of 3 blocks with the configuration [110011000]. (C) Shows a pyramid with the configuration [111000101].
4. Methodology 4.1. Decoupled mutual information and intrinsic motivationIn the robotic manipulation task, instead of blindly pursuing state coverage or diversity, we think the exploratory behaviors toward the unfamiliar states must be more conservative and controllable. To model this controllable exploration paradigm, we adopt the information theoretic concept of mutual information. Particularly, we propose that the exploration objective is to maximize the mutual information I between the next state S′ and the current state-action pair C, where C is the concatenation of the current state S and action A. Using the definition of mutual information, I can be expressed as the differential of the entropy H:
I(S′;C)=H(C)-H(C|S′) (2) =H(S′)-H(S′|C). (3)Equations 2, 3 are the inverse form and forward form of I(S′; C), respectively. Equation 2 means that to maximize I(S′; C), the agent is encouraged to increase the diversity of the state-action pairs [maximizing H(C)], while C is required to be unique when S′ is given [minimizing H(C|S′)]. Equation 3 means maximizing I(S′; C) corresponds to discovering more unfamiliar states [maximizing H(S′)], while S′ is predictable when the state-action pair is known [minimizing H(S′|C)]. Thus, H(C) or H(S′) represents the curiosity-based motivation while −H(C|S′) or −H(S′|C) represents the conservativeness. The mutual information I(S′; C) can be considered the KL-divergence between p(s′, c) and p(s′)p(c).
I(S′;C)=DKL(p(s′,c)∥p(s′)p(c)). (4)Because the probability distributions of s′ and c are all unknown, following the mutual information neural estimator (MINE) (Belghazi et al., 2021), maximizing the KL-divergence can be represented as maximizing its Donsker-Varadhan lower bound. However, in practical RL tasks, because the initial ability of the agent is weak and it cannot initially acquire an extensive coverage of s′ and c, directly exploring to maximize the mutual information lower bound in the form of KL-divergence or JS-divergence (Kim et al., 2019) will make the agent more likely to confirm its actions in the experienced states than to explore the unfamiliar novel states (Campos et al., 2020). Consequently, the direct mutual-information-based exploration is too conservative to discover fine goal-conditioned manipulation skills with sparse rewards, while it is mainly adopted for unsupervised motion mode discovery (Eysenbach et al., 2018; Sharma et al., 2020) or high-operability state discovery (Mohamed and Rezende, 2015).
To explain this phenomenon, due to p(s′, c) = p(s′|c)p(c), we rewrite DKL(p(s′,c)∥p(s′)p(c)) as
DKL(p(s′,c)∥p(s′)p(c))=∫p(s′,c)logp(s′|c)p(s′)ds′dc =?p(s′,c)[logp(s′|c)p(s′)] (5)where s′, c are sampled from the RL rollouts with the agent's current policy π. The mutual information I(S′; C) can be maximized by optimizing the agent's policy in an RL manner with the intrinsic reward function rint=logq(s′|c)-logq(s′), where q(s′|c) and q(s′) are the online estimations of p(s′|c) and p(s′) based on the collected < s′, c>. Assuming that q(s′) can be approximated by plenty of q(s′|c), i.e., q(s′)=1N∑∀ciq(s′|ci), the intrinsic reward can be rewritten as
rint=logq(s′|c)-log1N∑∀ciq(s′|ci) =logq(s′|c)∑∀ciq(s′|ci)+logN =logq(s′|c)1+∑∀ci≠cq(s′|ci)+ϵq(s′|c)+ϵ+logN. (6)In the experienced states, for s′ generated from c, the forward dynamics q(s′|c) is updated to be close to 1. For other ci ≠ c, q(s′|ci) is close to 0. Therefore, the typical intrinsic reward rint ≈ log1 + logN = logN > 0. Comparatively, in the unexperienced states, for any ci, q(s′|ci) is nearly 0. The typical intrinsic reward rint′≈log(1N)+logN=0<rint. Thus, the agent is more likely to obtain higher intrinsic rewards in the experienced states, which prevents its exploration to the unfamiliar states.
To solve this problem, different from (Kim et al., 2019; Belghazi et al., 2021), we propose to decouple the calculation of mutual information and respectively maximize the two entropy components H(S′) and −H(S′|C) in Equation 3 with different paces. The pace of H(S′) is fixed and the pace of −H(S′|C) is adjusted with a decay factor to ensure a curiosity-motivated, conservativeness-corrected exploration. We firstly introduce how to maximize H(S′) and −H(S′|C) then the adjustment of the pace. To approximate H(S′)=-?p(s′)log[p(s′)], because p(s′) is high-dimensional and hard to be estimated, we adopt the non-parametric particle-based entropy estimator proposed by Singh et al. (2003) that has been widely researched in statistics (Jiao et al., 2018). Considering a sampled dataset i=1N, H(S′) can be approximated by considering the distance between each s′i and its kth nearest neighbor.
Ĥparticle(S′)=1N∑i=1NlogN·||s′i-s′ik-NN||2DS′·πDS′2k·Γ(DS′2+1)+b(k) (7) ∝1N∑i=1Nlog‖s′i-s′ik-NN‖2 (8)where s′ik-NN denotes the kth nearest neighbor of s′i in the dataset i=1N, b(k) denotes a bias correction term that only depends on the hyperparameter k, DS′ is the dimension of s′, Γ is the gamma function, and ||·||2 denotes the Euclidean distance. The transition from Equations 7, 8 always holds for DS′>0. To maximize H(S′), we can treat each sampled transition < s′, c> as a particle (Seo et al., 2021). Following (Liu and Abbeel, 2021), we use the average distance over all k nearest neighbors for a more robust approximation, so the intrinsic reward rintH(S′) is designed as
rintH(S′)=log(m+1k∑siik-NN∈Nk(s′i)‖s′i-s′ik-NN‖2) (9)where m = 1 is a constant for numerical stability, Nk(s′i) denotes the set of k nearest neighbors around s′i.
Compared with p(s′), the posterior probability p(s′|c) in -H(S′|C)
留言 (0)