Sleep problems
The Pittsburgh Sleep Quality Index [PSQI; 15] is a 19-item self-rated measure. The scale has good psychometric properties [15] and is commonly used in studies of cancer patients [16,17,18]. Respondents rate items based on their usual sleep habits over the last month. The scale comprises seven subscales (or ‘components’): subjective sleep quality, (2) sleep latency, (3) sleep duration, (4) habitual sleep efficiency, (5) sleep disturbances, (6) use of sleep medication and (7) daytime dysfunction. Component scores range from 0 to 3. A global score is also derived based on the sum of all component scores. Higher scores on the component and global scores indicate more severe sleep difficulty. Consistent with other studies [9, 19], we use a cutoff score of > 5 for the global score to indicate clinically significant sleep problems. Other sleep outcomes derived from this measure included insufficient sleep duration (< 7 h, i.e. component score > 0); poor sleep quality (‘fairly bad’ and ‘very bad’ sleep quality, i.e. component score of ≥ 2); poor sleep efficiency (habitual sleep efficiency of ‘65–74%’ and ‘ < 65%, i.e. component score ≥ 2) and frequent sleep disturbance (‘once or twice a week’ and ‘three or more times a week’, i.e. component score ≥ 2).
CovariatesSociodemographic and clinical data
The following demographic and clinical data were collected: age in years (< 45 years, ≥ 45 years; these categories were used as 45 years of age is commonly used to denote the commencement of perimenopause), BMI (derived from self-reported weight and height: obese/not obese), education level (by category of attainment: low = ≤ grade 10, intermediate = grade 12, technical or diploma qualification; high = university of postgraduate qualification), marital status (married or de facto, otherwise), income (< $AU20,000 [low], $AU20,000–$80,000 [middle], > $AU80,000 [high]), menopausal status (pre-menopausal, peri-menopausal and post-menopausal).
Pain
Pain was measured using the Bodily Pain subscale of the SF-36. Two items comprise the subscale. Items were ‘How much bodily pain have you had during the past 4 weeks?’ and ‘During the past 4 weeks, how much did pain interfere with your normal work (including both work outside the home and housework). The subscale was scored as per standard scoring instructions. This bodily pain subscale has been used as a stand-alone subscale in a cancer population previously [20]. Higher scores indicate less pain-related disability. This subscale was transformed into three categories, each containing a third of the study participants: 1st tertile (0–62), 2nd tertile (63–74) and 3rd tertile (75–100).
Climacteric symptoms
Climacteric symptoms were measured with the Greene Climacteric Scale [GCS; 21]. The GCS has 21 self-rated items that assess vasomotor, somatic and psychological symptoms. Participants were asked about the extent to which they were bothered ‘at the moment’ by any of the 21 listed symptoms. Each item was rated on a scale of 0 to 3 (0 = not at all, 1 = a little, 2 = quite a bit, 3 = extremely). The scale has three main scales: psychological (11 items), physical (7 items) and vasomotor (2 items: hot flushes, sweating at night), with an additional item that elicits information about ‘loss of interest in sex’. Higher scores indicate greater severity of the symptoms.
Other covariates
Physical activity was measured using the 7-item International Physical Activity Questionnaire Short Form [IPAQ-SF; 22], low ≤ 600 MET.min/wk), moderate = 600–1199 MET.min/wk, high = 1200 + MET.min/wk). Depression-like symptoms were measured using the 20-item Center for Epidemiologic Studies Depression Scale [CES-D; 23], cut score > 16 = risk for clinical depression, and anxiety symptoms were measured with the 20-item Zung Self-rating Anxiety Scale [SAS; 24], cut score > 44 = mild to moderate anxiety levels or greater.
Data analysis
The proportion of women with insufficient sleep duration, poor sleep quality, poor sleep efficiency, frequent sleep disturbance and clinically significant sleep disturbance was compared across different subgroups by sociodemographic, health and behaviour-related variables. The predictors of the five binary study outcomes were assessed by logistic regression analyses. First, we examined the independent associations between all possible predictors meeting our criteria for inclusion and the five study outcomes (see Supplementary Table 1). There was a high degree of multicollinearity between the CES-D score and the Greene Climacteric Scale total scores, and the Zung self-rating anxiety score and the Greene Climacteric total scores. As a result, the CES-D and Zung variables were not included in subsequent model analyses (see Supplementary Table 2 for descriptive statistics of these variables). Due to substantial amount of missing data on the IPAQ-SF (> 20%), this variable was also removed for subsequent model analyses.
Redundant predictors in a regression model can yield an increase in the log-likelihood and less biased predictions, but they could increase the variance of predictions [25]. Hence, we used the STATA command gvselect to identify the best possible subset of the predictors. In this method, the leaps-and-bounds algorithm [26] was applied using the log-likelihoods of candidate models. The best model with the subset predictors was decided based on Akaike’s information criterion (AIC) and Bayesian information criterion (BIC).
Missing data
There was minimal missing data on the sleep duration (1.8%), sleep quality (1.8%) and sleep efficiency (6.0%) component score outcomes, but substantial missing data on the sleep disturbance component of the PSQI (45%) and consequently the global PSQI score (53.6%). Items were randomly missing throughout the measures, rather than the full measures being skipped. Covariates with > 20% missing data (i.e. the IPAQ-SF) were excluded from the main analysis. Due to the substantial missing values on the sleep disturbance component (and consequently the global PSQI score) of the PSQI, three select PSQI component scores with minimal missing data are reported separately as outcomes (rather than the global score alone). Additionally, all the regression analyses were conducted in three different samples: (1) available sample (unadjusted model), (2) complete sample (adjusted model on complete sample after excluding missing values at covariates and (3) imputed full sample (complete sample after imputing missing values). We used multiple imputations (MI) statistical techniques to impute the missing value in our sample. In MI, the distribution of observed data is used to estimate a set of plausible values for missing data. The missing values are replaced by the estimated plausible values to create a ‘complete’ dataset. In this study, there were various types of covariates that needed to be imputed, such as binary, ordinal and continuous. To impute those types of covariates, we used chained equations, a sequence of univariate imputation methods with fully conditional specification (FCS) of prediction equations using STATA command mi impute chained. STATA was used to impute the missing outcome values, which fills in missing values of the variables using a specified regression model in the imputation method. The imputation routine consisted of 1000 iterations to create 30 imputed data sets. Imputations were validated by comparing distributions of covariates before and after imputation. To assess the accuracy of the imputation, several parameters were also examined, such as RVI (relative increase in variance), FMI (fraction of missing information), DF (degrees of freedom), RE (relative efficiency) and the between-imputation and the within-imputation variance estimates. Estimates from the imputed sample were compared with the estimates from the complete case analysis. The results that report the analyses using complete cases (i.e. participants with data on all predictor variables and the sleep outcome) are presented in Supplementary Table 3. We did not observe significant differences in the estimates between the imputed sample and the complete case sample. Therefore, we report estimates from the imputed sample in the main text.

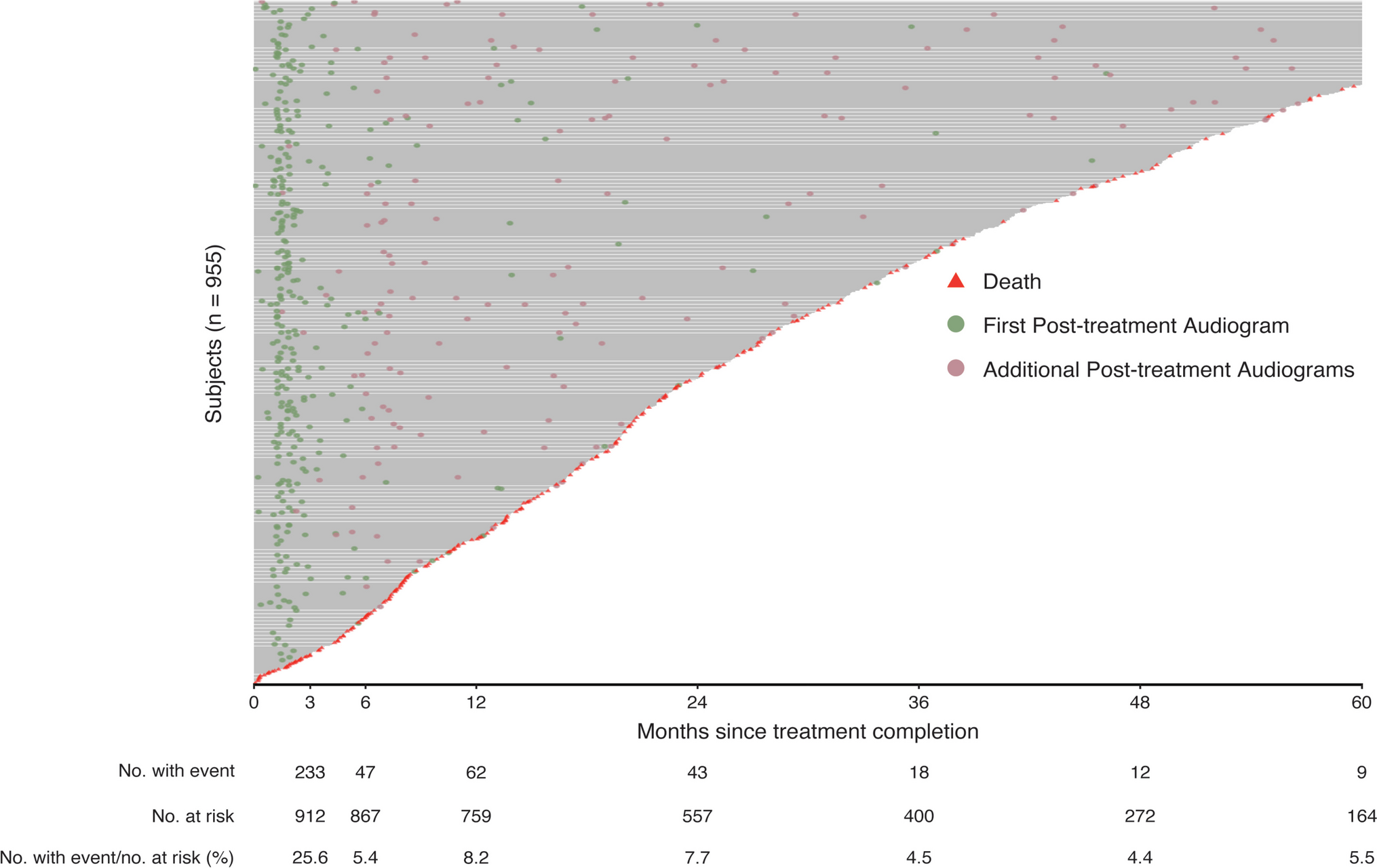
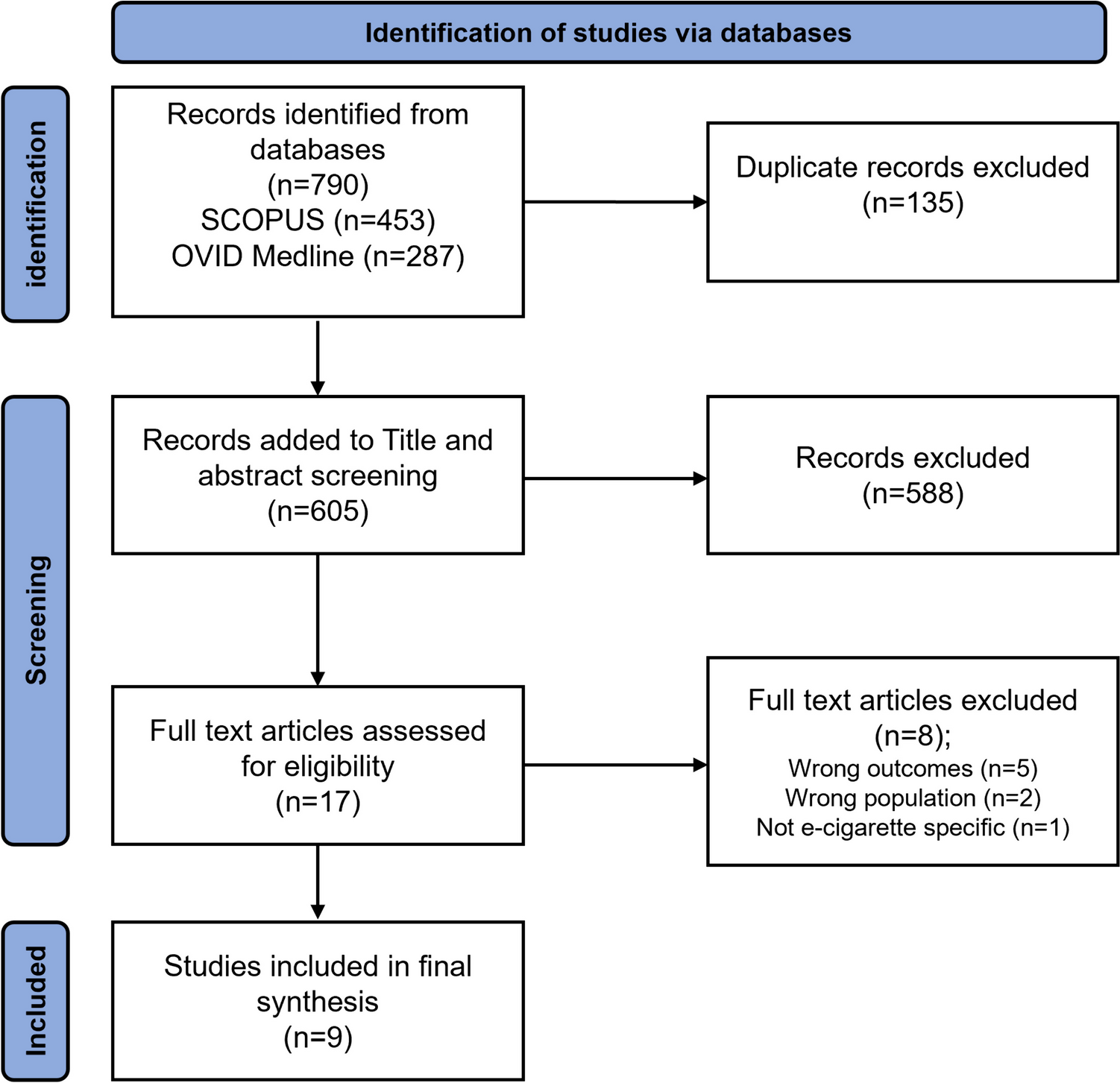

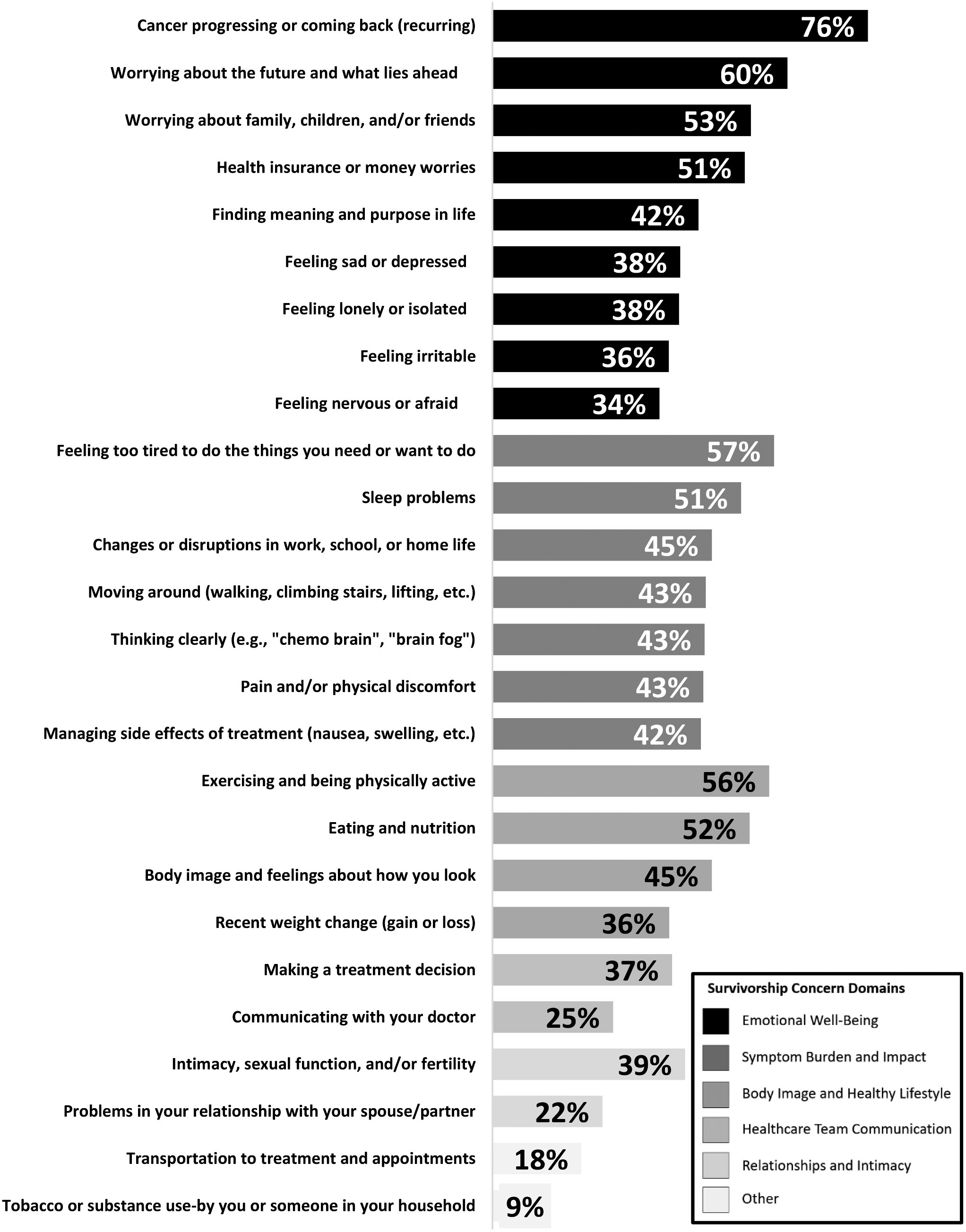
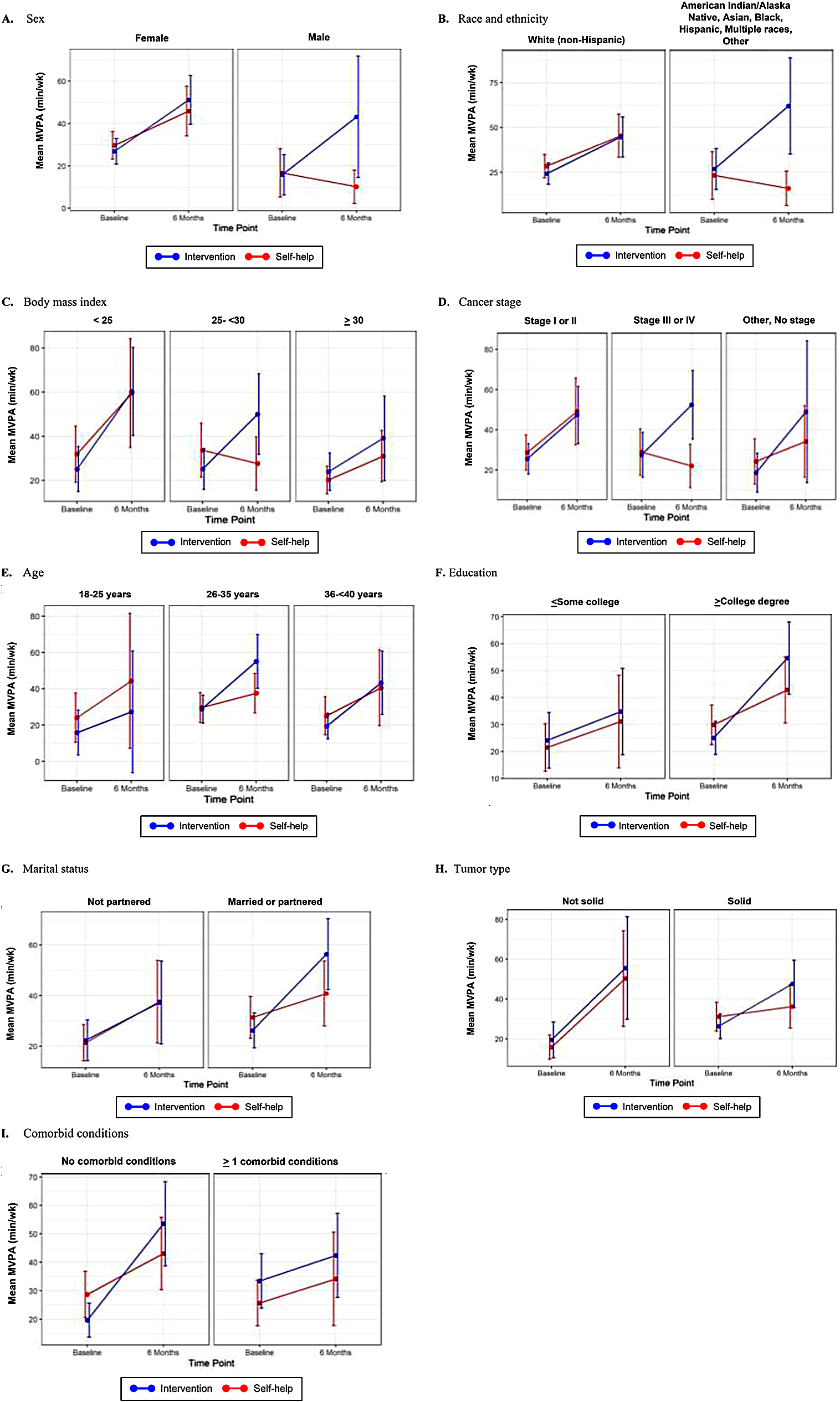

留言 (0)