


記住我








Deep neural networks (DNNs) have achieved remarkable achievements in theories and applications. However, the DNNs have been proven to be easily fooled by adversarial examples (AEs), which are generated by adding well-designed unwanted perturbations to the original clean data (Zhou et al., 2019). In these years, many studies dabbled in crafting adversarial examples and revealed that many DNN applications are vulnerable to them. Such as Computer Vision (CV) (Kurakin et al., 2017; Eykholt et al., 2018; Duan et al., 2020), Neural Language Processing (NLP) (Xu H. et al., 2020; Shao et al., 2022; Yi et al., 2022), and Autonomous Driving (Liu A. et al., 2019; Zhao et al., 2019; Yan et al., 2022). Generally, in CV, the AE needs to meet the following two properties, one is that it can attack the target model successfully, resulting in the target model outputting wrong predictions; another one is its perturbations should be invisible to human eyes (Goodfellow et al., 2015; Carlini and Wagner, 2017).
Unfortunately, most existing works (Kurakin et al., 2017; Dong et al., 2018, 2019) are focused on promoting the generated adversarial examples' attack ability but ignored the visual aspects of the crafted evil examples. Typically, the calculated adversarial noise is limited by a small Lp-norm ball, which tries to keep the built adversarial examples looking like the original image as possible. However, the Lp-norm limited adversarial perturbations blur the images to a large extent and are so conspicuous to human eyes and not harmonious with the whole image. Furthermore, these Lp-norm-based methods, which modify the entire image at the pixel level, seriously affect the quality of the generated adversarial images. Resulting in the vivid details of the original image can not be preserved. Besides, the adversarial examples crafted in these settings can be easily detected by the defense mechanism or immediately discarded by the target model and further encounter the “denied to service.” All the mentioned above can lead the attack to be failed. Furthermore, most existing methods adopt Lp-norm, i.e., L2 and Linf-norm, distance as the metrics to constraint the image's distortion. Indeed, the Lp-norm can ensure the similarity between the clean and adversarial images. However, it does not perform well in evaluating an adversarial example.
Recently, some studies have attempted to generate adversarial examples beyond the Lp-norm ball limited way. For instance, patch-based adversarial attacks, which usually extend into the physical world, do not limit the intensity of perturbation but the range scope. Such as adversarial-Yolo (Thys et al., 2019), DPatch (Liu X. et al., 2019), AdvCam (Duan et al., 2020), Sparse-RS (Croce et al., 2022). To obtain more human harmonious adversarial examples with acceptable attack success rate in the digital world, Xiao et al. (2018) proposed the stAdv to generate adversarial examples by spatial transform to modify each pixel's position in the whole image. The overall visual effect of the adversarial example generated by stAdv is good. However, the adversarial examples generated by stAdv usually have serration modifications and are visible to the naked eye. Later, the Chroma-Shift (Aydin et al., 2021) made a forward step by applying the spatial transform to the image's YUV space rather than RGB space. Unfortunately, these attacks have destroyed the semantic information and data distribution of the image, resulting that the generated adversarial noise that can be easily detected by the defense mechanism (Arvinte et al., 2020; Xu Z. et al., 2020; Besnier et al., 2021) and leading the attack failed.
To gap this bridge, we formulate the issue of synthesizing invisible adversarial examples beyond noise-adding at pixel level and propose a novel attack method called DualFlow. More specifically, DualFlow uses spatial transform techniques to disturb the latent representation of the image rather than directly adding well-designed noise to the benign image, which can significantly improve the adversarial noise's concealment and preserve the adversarial examples' vivid details at the same time. The spatial transform can learn a smooth flow field vector f for each value's new location in the latent space to optimize an eligible adversarial example. Furthermore, the adversarial examples are not limited to Lp-norm rules, which can guarantee the image quality and details of the generated examples. Empirically, the proposed DualFlow can remarkably preserve the images' vivid details while achieving an admirable attack success rate.
We conduct extensive experiments on three different computer vision benchmark datasets. Results illustrate that the adversarial perturbations generated by the proposed method take into account the data structure and only appear around the target object. We draw the adversarial examples and their corresponding noise from the noise-adding method MI-FGSM and the DualFlow in Figure 1. As shown in Figure 1, our proposed method slightly alters this area around the target object, thus ensuring the invisibility of the adversarial perturbations. Furthermore, the statistical results demonstrate that the DualFlow can guarantee the generated adversarial examples' image quality compared to the existing imperceptible attack methods on the target models while outperforming them both on the ordinary and defense models concerning attack success rate. The main contributions could be summarized as follows:
• We propose a novel attack method, named DualFlow, which generates adversarial examples by directly disturbing the latent representation of the clean examples rather than performing an attack on the pixel level.
• We craft the adversarial examples by applying the spatial transform techniques to the latent value to preserve the details of original images and guarantee the adversarial images' quality.
• Comparing with the existing attack methods, experimental results show our method's superiority in synthesizing adversarial examples with the highest attack ability, best invisibility, and remarkable image quality.
Figure 1. The adversarial examples generated by the MI-FGSM (Aydin et al., 2021) and the proposed DualFlow for the ResNet-152 (He et al., 2016) model. Specifically, the first column and the second column are the adversarial examples and their corresponding adversarial perturbations generated by MI-FGSM, respectively. The middle column is the clean images. The last two columns are the adversarial perturbations and their corresponding adversarial examples, respectively.
The rest of this paper is organized as follows. First, we briefly review the methods relating to adversarial attacks and imperceptible adversarial attacks in Section 2. Then, Sections 3 and 4, introduce the preliminary knowledge and the details of the proposed DualFlow framework. Finally, the experimental results are presented in Section 5, with the conclusion drawn in Section 6.
2. Related workIn this section, we briefly review the most pertinent attack methods to the proposed work: the adversarial attacks and the techniques used for crafting inconspicuous adversarial perturbations.
2.1. Adversarial attackPrevious researchers contend that deep neural networks (DNN) are sensitive to adversarial examples (Goodfellow et al., 2015), which are crafted by disturbing the clean data slightly but can fool the well-trained DNN models. The classical adversarial attack methods can be classified into two categories, white-box attacks (Kurakin et al., 2017; Madry et al., 2018) and black-box attacks (Narodytska and Kasiviswanathan, 2017; Bai et al., 2023). In white-box settings, the attackers can generate adversarial examples with a nearly 100% attack success rate because they can access the complete information of the target DNN model, while for the physical world, the black-box attack is more threatening to the DNN applications because they don't need too much information about the DNN models' details (Ilyas et al., 2018, 2019; Guo et al., 2019).
2.2. Imperceptible adversarial attacksRecently, some studies have attempted to generate adversarial examples beyond the Lp-norm ball limit for obtaining humanly imperceptible adversarial examples. LowProFool (Ballet et al., 2019) propose an imperceptibility attack to craft invisible adversarial examples in the tabular domain. Its empirical results show that LowProFool can generate imperceptible adversarial examples while keeping a high fooling rate. For computer vision tasks the attackers will also consider the human perception of the generated adversarial examples. In Luo et al. (2018), the authors propose a new approach to craft adversarial examples, which design a new distance metric that considers the human perceptual system and maximizes the noise tolerance of the generated adversarial examples. This metric evaluates the sensitivity of image pixels to the human eye and can ensure that the crafted adversarial examples are highly imperceptible and robust to the physical world. stAdv (Xiao et al., 2018) focuses on generating different adversarial perturbations through spatial transform and claims that such adversarial examples are perceptually realistic and more challenging to defend against with existing defense systems. Later, the Chroma-Shift (Aydin et al., 2021) made a forward step by applying the spatial transform to the image's YUV space rather than RGB space. AdvCam (Duan et al., 2020) crafts and disguises adversarial examples of the physical world into natural styles to make them appear legitimate to a human observer. It transfers large adversarial perturbations into a custom style and then “hides” them in a background other than the target object. Moreover, its experimental results that AEs produced by AdvCam are well camouflaged and highly concealed in both digital and physical world scenarios while still being effective in deceiving state-of-the-art DNN image detectors. SSAH (Luo et al., 2022) crafts adversarial examples and disguises adversarial noise in a low-frequency constraints manner. This method limits the adversarial perturbations to the high-frequency components of the specific image to ensure low human perceptual similarity. The SSAH also jumps out of the original Lp-norm constraint-based attack way and provides a new idea for calculating adversarial noise.
Therefore, crafting adversarial examples, especially for the imperceptible ones, poses the request for a method that can efficiently and effectively build adversarial examples with high invisibility and image quality efficiently and effectively. On the other hand, with the development of defense mechanisms, higher requirements are placed on the defense resistance of adversarial examples. To achieve these goals, we learn from the previous studies that adversarial examples can be gained beyond noise-adding ways. Hence, we are well motivated to develop a novel method to disturb the original image latent representation obtained by a well-trained normalizing flow-based model, and then apply a well-calculated flow field to it to generate adversarial examples. Our method can build adversarial examples with high invisibility and image quality without losing attack performance.
3. PreliminaryBefore introducing the details of the proposed framework, in this section, we first present the preliminary knowledge about adversarial attacks and normalizing flows.
3.1. Adversarial attackGiven a well-trained DNN classifier C and a correctly classified input (x, y)~D, we have C(x)=y, where D denotes the accessible dataset. The adversarial example xadv is a neighbor of x and satisfies that C(xadv)≠y and ||xadv−x||p ≤ ϵ, where the ℓp norm is used as the metric function and ϵ is usually a small value such as 8 and 16 with the image intensity [0, 255]. With this definition, the problem of calculating an adversarial example becomes a constrained optimization problem:
xadv=arg max ℓ‖xadv−x‖p≤ϵ(C(xadv)≠y), (1)Where ℓ stands for a loss function that measures the confidence of the model outputs.
In the optimization-based methods, the above problem is solved by computing the gradients of the loss function in Equation (1) to generate the adversarial example. Furthermore, most traditional attack methods craft adversarial examples by optimizing a noise δ and adding it to the clean image, i.e., xadv = x+δ. By contrast, in this work, we formulate the xadv by disturbing the image's latent representation with spatial transform techniques.
3.2. Normalizing flowThe normalizing flows (Dinh et al., 2015; Kingma and Dhariwal, 2018; Xu H. et al., 2020) are a class of probabilistic generative models, which are constructed based on a series of entirely reversible components. The reversible property allows to transform from the original distribution to a new one and vice versa. By optimizing the model, a simple distribution (such as the Gaussian distribution) can be transformed into a complex distribution of real data. The training process of normalizing flows is indeed an explicit likelihood maximization. Considering that the model is expressed by a fully invertible and differentiable function that transfers a random vector z from the Gaussian distribution to another vector x, we can employ such a model to generate high dimensional and complex data.
⊮ Specifically, given a reversible function F:ℝd → ℝd and two random variables z~p(z) and z′~p(z′) where z′ = f(z), the change of variable rule tells that
p(z′)=p(z)|det∂F−1∂z′|, (2) p(z)=p(z′)|det∂F∂z|, (3)Where det denotes the determinant operation. The above equation follows a chaining rule, in which a series of invertible mappings can be chained to approximate a sufficiently complex distribution, i.e.,
zK=FK⊙…⊙F2⊙F1(z0), (4)Where each F is a reversible function called a flow step. Equation (4) is the shorthand of FK(Fk−1(…F1(x))). Assuming that x is the observed example and z is the hidden representation, we write the generative process as
Where Fθ is the accumulate sum of all F in Equation (4). Based on the change-of-variables theorem, we write the log-density function of x = zK as follows:
−logpK(zK)=−logp0(z0)−∑k=1Klog|det∂zk−1∂zk|, (6)Where we use zk = Fk(zk−1) implicitly. The training process of normalizing flow is minimizing the above function, which exactly maximizes the likelihood of the observed training data. Hence, the optimization is stable and easy to implement.
3.3. Spatial transformThe concept of spatial transform is firstly mentioned in Fawzi and Frossard (2015), which indicates that the conventional neural networks are not robust to rotation, translation and dilation. Next, Xiao et al. (2018) utilized the spatial transform techniques and proposed the stAdv to craft adversarial examples with a high fooling rate and perceptually realistic beyond noise-adding way. StAdv changes each pixel position in the clean image by applying a well-optimized flow field matrix to the original image. Later, Zhang et al. (2020) proposed a new method to produce the universal adversarial examples by combining the spatial transform and pixel distortion, and it successfully increased the attack success rate against universal perturbation to more than 90%. In the literature (Aydin et al., 2021), the authors applied spatial transform to the YUV space to generate adversarial examples with higher superiority in image quality.
We summarized the adopted symbols in Table 1 to increase the readability.
Table 1. The notations used in this paper.
4. MethodologyIn this section, we propose our attack method. First, we take an overview of our method. Next, we go over the detail of each part step by step. Finally, we discuss our objective function and summarize the whole process as Algorithm 1.
Algorithm 1. DualFlow attack.
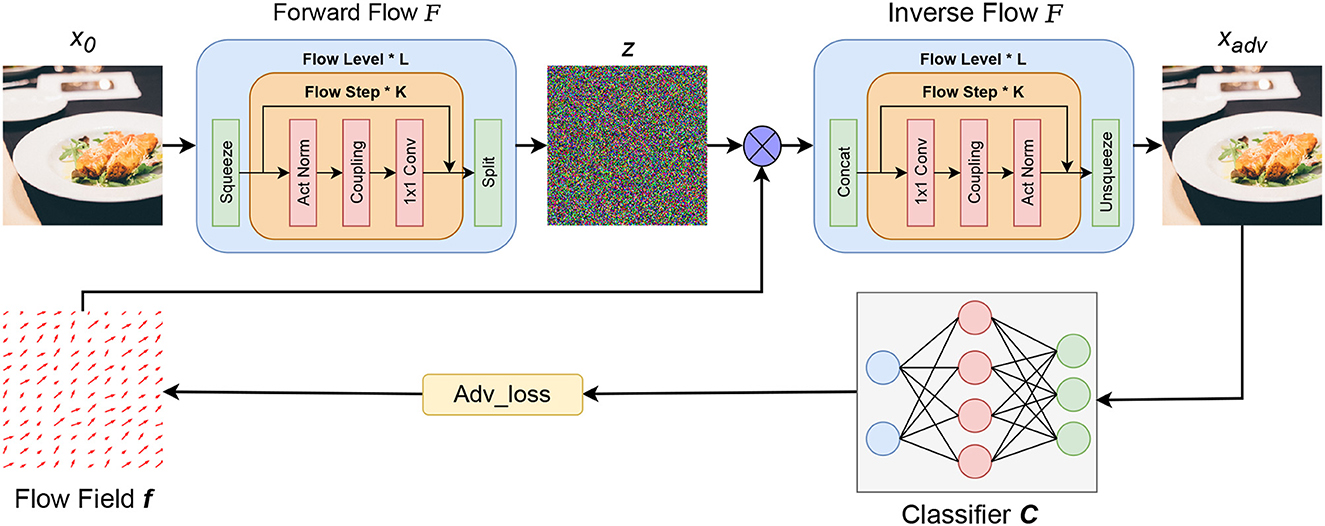
4.1. The DualFlow frameworkThe proposed DualFlow attack framework can be divided into three parts, the first one is to map clean image x to its latent space z by the well-trained normalizing flow model. The second part is to optimize the flow field f, and apply it to the images' latent representation z and inverse the transformed z to generate its corresponding RGB space counterpart xt. Note that step 2 needs to be worked in an iterative manner to update the flow field f guided by the adv_loss until the adversarial candidate xt can fool the target model. Finally, apply the optimized flow field f to the image's latent counterpart z and do the inverse operation of normalizing flow to obtain the adversarial image. The whole process is shown in Figure 2.
Figure 2. The framework of proposed DualFlow. x represent the image, among them, x0 is the benign image, xadv is the corresponding adversarial counterpart; z is the hidden representation of the image; F is the well-trained Normalize Flow model and C is the pre-trained classifier; f is the flow field need to be optimized and ⊗ represents the spatial transform operation.
4.2. Normalizing flow model trainingAs introduced in Section 3.2., the training of the normalizing flow is to maximize the likelihood function on the training data with respect to the model parameters. Formally, assume that the collected dataset is denoted by x~X. The hidden representation follows the Gaussian distribution, i.e., z~N(0,1). The flow model is denoted by F, parameterized θ, which have x = Fθ(z) and z = F−1(x). Then, the loss function to be minimized is expressed as:
L(θ;z,x)=−logp(x|z,θ)=−logpz(Fθ−1(x))−log|det∂Fθ−1(x)∂x|, (7)By optimizing the above objective, the learned distribution p(x|z, θ) characterizes the data distribution as expected.
In the training process, we use the Adam algorithm to optimize the model parameters; while the learning rate is set as 10−4, the momentum is set to 0.999, and the maximal iteration number is 100,000.
4.3. Generating adversarial examples with DualFlowFor a clean image x, to obtain its corresponding adversarial example xadv, we first calculate its corresponding latent space vector z by performing a forward flow process via z = Fθ(x). Once the z is calculated, we can disturb it with the spatial transform techniques, the core is to optimize the flow filed vector f, which will be applied to z to get the transformed latent representation zst according to x. In this paper, the flow filed vector f is directly optimized with the Adam optimizer iteratively. We will repeat the above process to optimize flow field f until zst becomes an eligible adversarial latent value, that is, make the zst becomes zadv. Finally, when the optimal flow filed f is calculated, we restore the transformed latent representation zadv to the image space through the inverse operation of the normalizing flow model, that is, xadv = Fθ(zadv), to get its perturbed example xadv in pixel level.
Moore specifically, the spatial transform techniques using a flow field matrix f = [2, h, w] to transform the original image x to xst (Xiao et al., 2018). In this paper, we adopt the spatial transform from the pixel level to the latent space. Specifically, assume the latent representation of input x is z and its transformed counterpart zst, for the i-th value in zst at the value location (usti,vsti), we need to calculate the flow field matrix fi=(Δui,Δvi). So, the i-th value zi's location in the transformed image can be indicated as:
(ui,vi)=(usti+Δui,vsti+Δvi). (8)To ensure the flow field f is differentiable, the bi-linear interpolation (Jaderberg et al., 2015) is used to obtain the four neighboring values surrounding the location (usti+Δui,vsti+Δvi) for the transformed latent value zst as:
zsti=∑q∈ N(ui,vi)zq(1−|ui−uq|)(1−|vi−vq|), (9)Where N(ui,vi) is the neighborhood, that is, the four positions (top-left, top-right, bottom-left, bottom-right) tightly surrounding the target value (ui, vi). In our adversarial attack settings, the calculated zst is the final adversarial latent representation zadv. Once the f has been computed, we can obtain the zadv by applying the calculated flow field f to the original z, which is given by:
zadv=∑q∈N(ui,vi)zq(1−|ui−uq|)(1−|vi−vq|)), (10)and the adversarial examples xadv can be obtained by:
xadv=clip(F-1(zadv),0,1), (11)Where clip(·) is the clip operation to keep the generated value belonging to [0, 1].
4.4. Objective functionsTaking the attack success rate and visual invisibility of the generated adversarial examples into account, we divide the objective function into two parts, where one is the adversarial loss and the other is a constraint for the flow field. Unlike other flow field-based attack methods, which constrain the flow field by the flow loss proposed in Xiao et al. (2018), in our method, we use a dynamically updated flow field budget ξ (a small number, like 1*10−3) to regularize the flow field f. For adversarial attacks, the goal is making C(xadv)≠y. We give the objective function as follows:
for un-targeted attacks:
ℒadv(X,y,f)=max[C(Xadv)y−maxk≠yC(Xadv)k,k], s.t.‖f‖≤ξ. (12)for target attacks:
ℒadv(X,y,t,f)=min[maxk=tC(Xadv)k−C(Xadv)y,k], s.t.‖f‖≤ξ. (13)The whole algorithm of LFFA is listed in Algorithm 1 for easy reproducing of our results, where lines 11-18 depict the core optimization process.
5. ExperimentsIn this section, we evaluate the proposed DualFlow on three benchmark image classification datasets. We first compare our proposed method with several baseline techniques concerned with Attack Success Rate (ASR) on clean models and robust models on three CV baseline datasets (CIFAR-10, CIFAR-100 and ImageNet). Then, we first provide a comparative experiment to the existing attack methods in image quality aspects with regard to LPIPS, DISTS, SCC, SSIM, VIPF and et al. Through these experimental results, we show the superiority of our method in attack ability, human inception and image quality.
5.1. Settings DatasetWe verify the performance of our method on three benchmark datasets for computer vision task, named CIFAR-10 (Krizhevsky and Hinton, 2009), CIFAR-100 (Krizhevsky and Hinton, 2009) and ImageNet-1k (Deng et al., 2009). In detail, CIFAR-10 contains 50,000 training images and 10,000 testing images with the size of 3x32x32 from 10 classes; CIFAR-100 has 100 classes, including the same number of training and testing images as the CIFAR-10; ImageNet-1K has 1,000 categories, containing about 1.3M samples for training and 50,000 samples for validation. In particular, in this paper, we extend our attack on the whole images in testing datasets of CIFAR-10 and CIFAR-100, in terms of ImageNet-1k, we are using its subset datasets from ImageNet Adversarial Learning Challenge, which is commonly used in work related to adversarial attacks.
All the experiments are conducted on a GPU server with 4 * Tesla A100 40GB GPU, 2 * Xeon Glod 6112 CPU, and RAM 512GB.
ModelsFor CIFAR-10 and CIFAR-100, the pre-trained VGG-19 (Simonyan and Zisserman, 2015), ResNet-56 (He et al., 2016), MobileNet-V2 (Sandler et al., 2018) and ShuffleNet-V2 (Ma N. et al., 2018) are adopted, with top-1 classification accuracy 93.91, 94.37, 93.91, and 93.98% on CIFAR-10 and 73.87, 72.60, 71.13, and 75.49% on CIFAR-100, respectively, all the models' parameters are provided in the GitHub Repository. For ImageNet, we use the PyTorch pre-trained clean model VGG-16, VGG-19 (Simonyan and Zisserman, 2015), ResNet-152 (He et al., 2016), MobileNet-V2 (Sandler et al., 2018) and DenseNet-121 (Huang et al., 2017), achieving 87.40, 89.00, 94.40, 87.80, and 91.60% classification accuracy rate on ImageNet, respectively. And in terms of robust models, they include Hendrycks2019Using (Hendrycks et al., 2019), Wu2020Adversarial (Wu et al., 2020), Chen2020Efficient (Chen et al., 2022) and Rice2020Overfitting (Rice et al., 2020) for CIFAR-10 and CIFAR-100, And Engstrom2019Robustness (Croce et al., 2021), Salman2020Do_R18 (Salman et al., 2020), Salman2020Do_R50 (Salman et al., 2020), and Wong2020Fast (Wong et al., 2020) for ImageNet. All the models we use are implemented in the robustbench toolbox (Croce et al., 2021) and the models' parameters are also provided in Croce et al. (2021). For all these models, we chose their Linf version parameters due to most baselines being extended Linf attacks in this paper.
BaselinesThe baseline methods are FGSM (Goodfellow et al., 2015), MI-FGSM (Dong et al., 2018), TI-FGSM (Dong et al., 2019), Jitter (Schwinn et al., 2021), stAdv (Xiao et al., 2018), Chroma-Shift (Aydin et al., 2021), and GUAP (Zhang et al., 2020). The experimental results of those methods are reproduced by the Torchattacks toolkit and the code provided by the authors with default settings.
MetricsUnlike the pixel-based attack methods, which only use Lp norm to evaluate the adversarial examples' perceptual similarity to its corresponding benign image. The adversarial examples generated by spatial transform always use other metrics referring to image quality. To be exact, in this paper, we follow the work in Aydin et al. (2021) using the following perceptual metrics to evaluate the adversarial examples generated by our method, including Learned Perceptual Image Patch Similarity (LPIPS) metric (Zhang et al., 2018) and Deep Image Structure and Texture Similarity (DISTS) index (Ding et al., 2022). LPIPS is a technique that measures the Euclidean distance of deep representations (i.e., VGG network Simonyan and Zisserman, 2015) calibrated by human perception. LPIPS has already been used on spatially transformed adversarial examples generating studies (Jordan et al., 2019; Laidlaw and Feizi, 2019; Aydin et al., 2021). DISTS is a method that combines texture similarity with structure similarity (i.e., feature maps) using deep networks with the optimization of human perception. We used the implementation of Ding et al. for both perceptual metrics (Ding et al., 2021). Moreover, we use other metrics like Spatial Correlation Coefficient (SCC) (Li, 2000), Structure Similarity Index Measure (SSIM) and Pixel Based Visual Information Fidelity (VIFP) (Sheikh and Bovik, 2004) to assess the generated images' qualities. SCC reflects the indirect correlation based on the spatial contiguity between any two geographical entities. SSIM is used to assess the generated images' qualities concerning luminance, contrast and structure. VIFP is used to assess the adversarial examples' image quality. The primary toolkits we used in the experiments of this part are IQA_pytorch and sewar.
5.2. Quantitative comparison with the existing attacksIn this subsection, we will evaluate the proposed DualFlow and the baselines FGSM, MI-FGSM, TI-FGSM (Dong et al., 2019), Jitter, stAdv, Chroma-shift and GUAP in attack success rate on CIFAR-10, CIFAR-100 and the whole ImageNet dataset. We set the noise budget as ϵ = 0.031 for all Linf-based attacks baseline methods. The other attack methods, such as stAdv and Chroma-shift, follow their default settings in the code provided by the authors.
Tables 2–4 show the ASR of DualFlow and the baselines on CIFAR-10, CIFAR-100 and ImageNet, respectively. As the results illustrated, DualFlow can perform better in most situations on the three benchmark datasets. Take the attack results on ImageNet as an example, refer to Table 3. The BIM, MI-FGSM, TI-FGSM, Jitter, stAdv, Chroma-shift and GUAP can achieve 91.954, 98.556, 93.94, 95.172, 97.356, 98.678, and 94.606% average attack success rate on ImageNet dataset, respectively, vice versa, our DualFlow c
留言 (0)