2.1. Warships Scheduled Maintenance Cost Prediction
The category of warships maintenance is divided into condition-based preventive maintenance, temporary emergency maintenance and scheduled maintenance. The warships scheduled maintenance can also be divided into different grades according to their scope and depth, such as third-grade maintenance, second-grade, and first-grade maintenance.
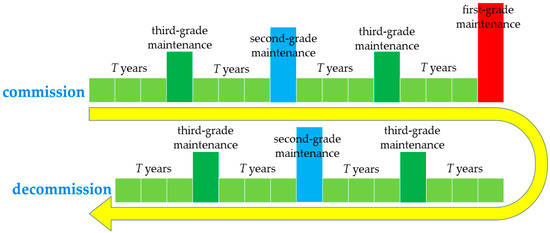
Depending on the mission of the warships, the structure of warships’ scheduled maintenance during their whole life cycle varies. The structural diagram of a general warship’s scheduled maintenance is shown in
Figure 1. During the service period, the warship will undergo several rounds of scheduled maintenance, and the times of scheduled maintenance occur differently for different grades, such as the highest grade of first-grade maintenance is often performed only once in the middle of its commissioning. The higher the maintenance grade, the less time occurs, and the greater the scope and depth of the grade maintenance. The timing of the different scheduled maintenance is relatively fixed, and their corresponding repair times are also determined.
The WSM is a massive and complicated project that involves numerous different systems of the warship, such as the piping system, power system, etc. Moreover, the inter-coupling and complex relationships between maintenance tasks of different systems lead to less quantifiable maintenance information among them. This also makes it difficult to deconstruct the structure of the WSM work; traditional cost forecasting methods based on engineering decomposition have difficulty in achieving satisfactory results. Furthermore, its corresponding data collection also incurs significant labour and time costs.
Consequently, the primary ideology of WSM cost prediction is to establish the regression model by selecting relevant quantifiable feature indicators from the basic information and the corresponding maintenance scenarios of warships, with cost indicators as the output target. The regression model is employed to investigate statistical dependences between input features and costs, and then to estimate WSM costs based on the dependences. As the number of samples increases, these parametric models become more flexible and adaptive, accurate, and reliable, and they can also achieve significant reductions in time in terms of data collection.
Given the small sample size of WSM data, various grey prediction models were introduced to perform cost forecasting such as GM(0, N) [
6], GM(1, 1) [
4] and grey correlation analysis [
2] to construct the time-series model for short-term forecasting of WMS maintenance costs. The GM(0, N) warship maintenance cost prediction model based on the priority accumulation method of similar information is proposed in [
6], to solve the warship maintenance cost prediction problem in the small sample case. In [
5], the grey orthogonal method is proposed to analyze the influencing factors of the naval vessel maintenance cost, and further determine the major and minor influencing factors of maintenance cost. The combined prediction model for warship maintenance cost measurement based on grey correlation ranking was developed in [
3].As an emerging field in artificial intelligence, with its historical experience-based solution mechanism, case-based reasoning (CBR) is well suited to the problem of WSM cost prediction, which has difficulty determining an explicit model and lacks abundant experience, therefore, various CBR-based WSM cost prediction methods have been proposed [
1,
8,
9,
10,
11,
12]. The literature [
8] proposes a similarity retrieval technique and case adaptation technique for WMS cost cases based on CBR so that it can better adapt to the characteristics of WMS cases. Through an active learning strategy, a corresponding maintenance cost case library is formed, which in turn ensures the prediction accuracy of CBR technology on WMS costs. The literature [
11] proposes a CBR system for WMS maintenance cost based on a dual similarity retrieval strategy, to better select similar historical cases to construct a case adaptation model for prediction, and achieve better prediction results in the WMS cost prediction problem.
Although the above-mentioned cost prediction model has solved the WMS cost estimation problem to a degree, there are still some unresolved problems. These methods only perform regression modelling and prediction for the total cost of WMS, they do not utilize the information of subentry costs in original data, and the correlation information contained in different subentry costs is not explored, which limits the accuracy of the prediction model. Meanwhile, while the above model can be trained and learn from small samples with some generalization abilities, it is also susceptible to the influence of abnormal samples and noises.
2.2. MTR AlgorithmThe existing MTR algorithms can be broadly classified into two categories: problem transformation methods and algorithm adaptation methods [
24]. The former is to split the MTR problem into several single-target regression subproblems and solve them independently. The main drawback is that when predicting a single objective independently, the dependency relationship between different objectives is neglected, which affects the overall prediction performance. Therefore, in order to overcome these drawbacks, existing problem transformation methods such as stacked single-target (SST) borrow the idea of stacked generalization in multi-label classification to stack the prediction results of single-target regression [
25]; random linear target combination (RLC) constructs new target variables by random linear combination of targets to improve the regression performance of the model when there are dependencies between targets [
26]; ensemble of regressor chains (ERC) is based on the idea of classifier chains in multi-label learning, by constructing random target chains, linking single target models to make predictions in turn, and solving the chain order sensitivity problem by integration [
25]. Although the above problem transformation methods perform well in some cases, their performance often depends on the chosen regression algorithm, and the complexity of the training process also causes a large computational cost when the data output is of high dimensionality or large size.Unlike the problem transformation approach, the basic idea of algorithm adaptation is to construct a structured model that predicts all outputs simultaneously, and the correlation between inputs and outputs as well as the correlation between different targets can be handled in a single framework so that the model can consider the effects of both factors during the learning process. Most of the existing algorithmic adaptation methods explore the inter-target correlations by imposing corresponding regularization constraints on the regression coefficient matrix, which are often limited to the linear regression case. By assuming a priori knowledge of the output structure, constraints such as low rank, sparsity or streamlining are imposed on the corresponding coefficient matrices [
27]. However, these linear models cannot handle complex nonlinear input–output relationships, and the above prior knowledge assumptions are often only effective in domain-specific problems, which cannot automatically and adaptively extract correlation knowledge from datasets in different domains, resulting in a lack of model adaptability.In recent years, various nonlinear based algorithms have been proposed to better handle the nonlinear correlation between input and output in data. In the literature [
28,
29,
30,
31], kernel methods are introduced to the MTR problem to decouple the highly complex nonlinear input–output relationships. In [
31], a learning output kernels (OKL) algorithm is proposed to reveal the complex correlation structure in the output space through kernel methods to improve the learning performance of the algorithm. In [
32], the coefficient matrix in multitask regression is reshaped into a vector to explore the correlation between task goals, which not only fails to distinguish the correlation between task goals and intra-task correlation, but also ignores the negative correlation between goals. However, the covariance matrix needs to satisfy the a priori assumption that the matrix variables obey normal distribution. In [
33], the covariance structure of the potential model parameters and the conditional covariance structure between the outputs are learned from the data so that the algorithm does not require the corresponding a priori knowledge. In the literature [
27], a multi-layer multi-target regression (MMR) algorithm is proposed by combining robust low-rank learning methods and kernel methods. MMR takes advantage of the kernel approach of nonlinear feature learning and the structure of multilayer learning in latent variable space, while modeling the intrinsic target correlations and nonlinear input–output relationships, and explicitly encodes the correlations between targets using the structure matrix, providing a flexible and general multilayer learning paradigm for the field of multi-target regression. The Multi-Target Sparse Latent Regression (MSLR) algorithm proposed in [
34] has a similar structure to MMR and achieves explicit sparse learning of inter-target correlations by imposing regularization constraints on the structure matrix.
Most of the existing MTR algorithms focus on exploring and mining the correlation among targets to improve the regression performance of different outputs simultaneously. Compared with the problem transformation method, the family of algorithm adaptation methods can well encode the correlation of targets to be easily interpreted. However, MTR modelling based on a single framework is often affected by noises, and it is often difficult to effectively extract the dependencies between different subentry costs of WSM for existing algorithm adaptation methods. Based on this, this paper proposes the corresponding MTR algorithm, while explicitly coding and learning the structured noises among the outputs in the latent variable layer, in order to better solve the problem of handling the structured noises in MTR.


留言 (0)