



記住我







In the past few years, retinal fundus images have been used to diagnose retinal diseases. Glaucoma is a disease that causes damage to the optic nerve of the eye, resulting in decreased vision, but timely detection can further control the effect of glaucoma. Automated segmentation of the optic disc (OD) and optic cup (OC) in fundus images is helpful for the screening and diagnosis of glaucoma (Fu et al., 2018). The development of deep convolutional neural networks (CNNs) has significantly improved the automatic monitoring of OD and OC. However, traditional CNNs are mostly based on the assumption that the training (source) and testing (target) images have the same distribution. Since the fundus images are obtained from different patients and different imaging equipment, the distribution of the domains is not the same (Wang Z. et al., 2020). Some domain adaptive methods are applied to fundus image segmentation to reduce the distribution mismatch between the source domain and the target domain (Dou et al., 2018; Zhang et al., 2018). However, simple domain adaptation will lack generalization, so how to improve the generalization ability of the model is a problem worth discussing.
Recently, some data augmentation methods (Prakash et al., 2019; Yue et al., 2019; Zhou et al., 2020) used for domain generalization. Nevertheless, these methods are difficult to be extended for medical image segmentation problems due to the structured prediction characteristics of segmentation tasks (Wang S. et al., 2020). In the field of medical image analysis, some of the latest single-source domain generalization methods have explored various data augmentation techniques to improve the generalization ability of CNNs for medical image segmentation in other domains (Chen et al., 2020). At the same time, there is also a method (Zhang et al., 2022) that uses an improved GAN method to segment medical images. Nihal Zaaboub et al. proposed a method (Zaaboub et al., 2022) to localize OD, and vessels were extracted and eliminated. A novel Domain-oriented Feature Embedding (DoFE) framework (Wang S. et al., 2020) has been presented to improve the generalization ability of CNNs on unseen target domains by exploring the knowledge from multiple source domains. A BEAL framework (Wang et al., 2019a) proposed utilizes the adversarial learning to encourage the boundary prediction and mask the probability entropy map of the target domain to be similar to the source ones, generating more accurate boundaries and suppressing the high uncertainty predictions of OD and OC segmentation. Inspired by this boundary method, we propose to use a convolutional auto-encoder to augment the data, and perform adversarial learning on the boundary and entropy maps to generate more accurate boundaries for OD and OC segmentation.
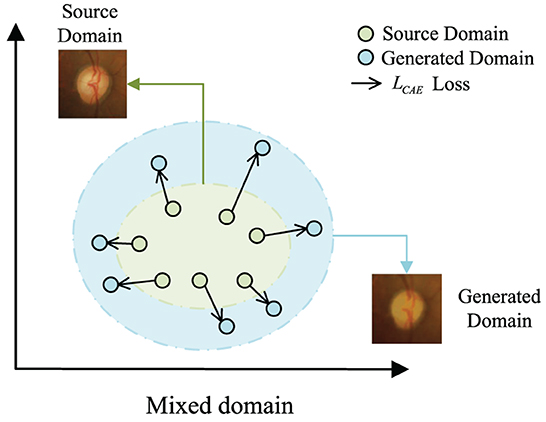
In this work, we propose a novel domain adaptation framework, called Convolutional Autoencoder Joint Boundary and Mask Adversarial Learning (CAE-BMAL), to augment the data and improve OD/OC on the dataset segmentation accuracy. Our method is based on two main observations. First, as depicted in Figure 1, the convolutional autoencoder can generate an image with the same structure as the original image, but it is blurry than the original image, and some structures (such as blood vessels, etc.) have a certain degree of randomness which is helpful to learn the influence of different blood vessel orientations on OD/OC segmentation. This opens up the possibility to train and generalize on the source and target domains. Second, the influence of boundary segmentation also plays a vital role. The generated image has fuzzy boundaries, while the original image has clear boundaries. In this way, boundary segmentation can be performed more accurately on target domain datasets through adversarial learning of boundaries and guided masks. Based on these observations, we develop a boundary and mask adversarial learning based on the convolutional autoencoder method to segment the OD and OC from the target domain fundus images by generating more accurate boundaries and improving model generalization ability. The proposed method was extensively evaluated on three public fundus image datasets, i.e., Drishti-GS (Sivaswamy et al., 2015), RIM-ONE-r3 (Fumero et al., 2011), and REFUGE (Orlando et al., 2020), demonstrating state-of-the-art results. We also conducted an ablation study to show the effectiveness of each component in our method.
Figure 1. The motivation of LCAE. We expect to create out-of-domain augmentations by maximizing the loss LCAE.
Our main contributions are summarized as follows: (1) We propose a new domain-adaptive segmentation framework that uses convolutional autoencoders to enhance source domain images to generate enhanced domains with the same semantics as the source domain images, but with different light and vessel shapes. Then they are put into the network to train together, in the segmentation process, the adaptive segmentation of the network under the influence of surrounding blood vessels is strengthened, and the generalization ability of the model is improved; (2) Our proposed network integrates the ideas of boundary prior and adversarial learning, and the two boundary subnetworks have their functions. Combined, the boundary discrimination can still show good segmentation performance in harsh conditions (such as dark light, and intricate blood vessels around the optic disc). (3) The proposed segmentation method is clinically meaningful in glaucoma screening based on extensive evaluations on three publicly available fundus image datasets.
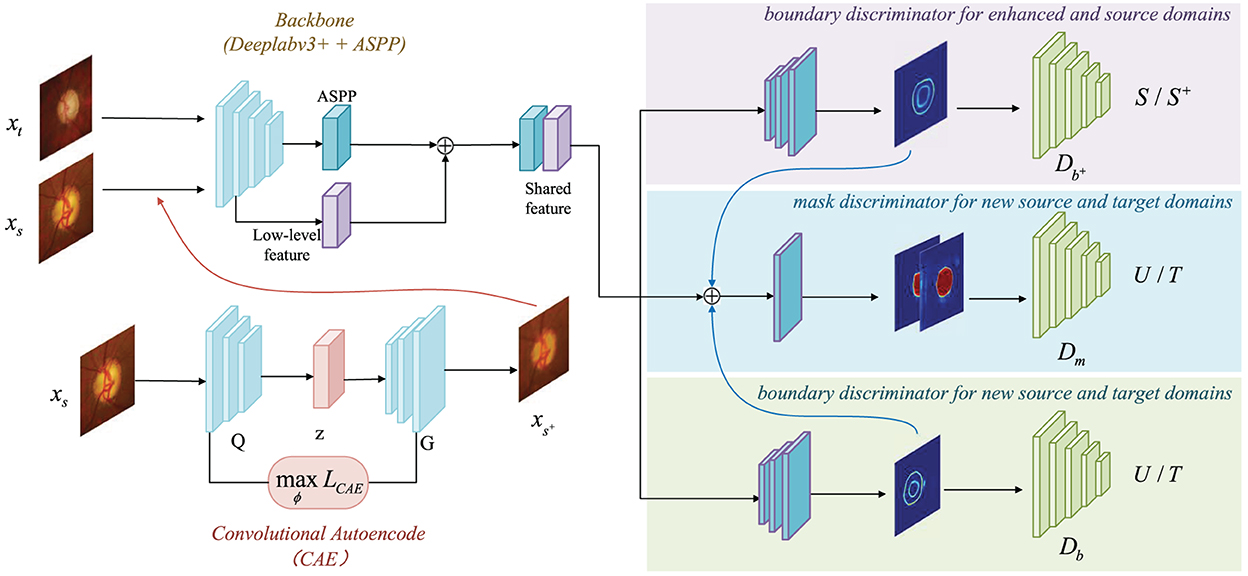
2. Materials and methodsThe network architecture is exhibits in Figure 2. The key technical contribution of our method is a convolutional autoencoder-based boundary and mask adversarial learning framework, which uses both source and target domains to make accurate and confident predictions on the target domain while improving the generalization ability of the model. The proposed procedure is: (1) All source domain images are put into the CAE module for image generation, and all enhanced output images compose the enhanced domain. The enhanced output images retains the variety structure of blood vessels and the brightness with a rich semantic information; (2) The enhanced output images are put into the ASPP module together with the source domain and the target domain for feature extraction; (3) The finally extracted features are processed with three discriminators: boundary discriminator for enhanced and source domains, mask discriminator for new source and target domains, boundary discriminator for new source and target domains, as shown in Figure 2.
Figure 2. Overview of CAE-BMAL framework for domain daptation. The backbone is based on the DeepLabv3+ (Chen et al., 2018) architecture with Atrous Spatial Pyramid Pooling (ASPP) component followed by the adversarial learning branch structure which is used to classify.
2.1. Convolutional autoencoderHow to generate images useful for fundus image segmentation has become a major challenge due to the time-consuming and labor-intensive manual labeling of fundus images and the rarity of labels. To solve this problem, we use a convolutional autoencoder to generate images similar to the original image but different in blood vessel structure and brightness. For the convenience of elaboration, we have added Table 1 as a comparison of mathematical symbols.
Table 1. Mathematical function symbol comparison table.
Formally, we aim at solving the problem of domain adaptation: A model is trained on a source domain XS⊂ℝH×W×3 along with ground truth segmentation maps YS⊂ℝH×W, and a target domain XT⊂ℝH×W×3 without ground truth, but is expected to generalize well on many different target domains XT⊂ℝH×W×3. The convolutional autoencoder is composed of an encoder responsible for dimensionality reduction and a decoder responsible for dimensionality increase. The encoder function is represented by Q, and the decoder function is represented by G. Assuming that the encoder function gets the intermediate code z, the input image is represented by xs ∈ XS, and the output image is represented by xs+∈XS+, then the entire encoder decoding process can be represented as:
z=Q(xs),xs+=G(z) (1)Intuitively, we expect the augmented domain XS+ to be vastly different from the source domain XS in vascular performance and brightness. In other words, we want to maximize the domain discrepancy between XS+ and XS. Therefore, the reconstruction error LCAE for domain augmentation can be formulated as:
LCAE=‖xs−xs+‖2 (2)The pre-trained CAE can better capture the distribution of the source domain and maximize LCAE creates large domain transportation.
The reason for choosing a convolutional autoencoder is that data slicing and data stacking can cause a large amount of information to be lost. The convolutional autoencoder abandons the stacked data, keeps its spatial information unchanged when the image data is input, and gently extracts the information in the convolutional layer. This process aims to preserve the spatial relationship in the data, but it does not generate the same data as GANs (Goodfellow et al., 2014).
2.2. Boundary and mask adversarial learningThe generalization of a model is directly related to the handling of boundaries. Therefore, to make the model more general, it needs to perform better in processing boundaries. We use adversarial learning on the boundaries and masks of the optic cup and optic disc, respectively. The core is to use the max-min game between the generator and the discriminator to obtain the optimal solution to determine whether it belongs to the enhanced source domain or the target domain. At the same time, boundary adversarial learning can be used to regress the boundary, so that the boundary prediction in the augmented domain is close to the source domain. Convolutional autoencoders then generate optic cups and optic discs that approximate the structured semantics of the source domain, but can represent different details (e.g., blurred vessel structures) in the augmentation domain. This method can further expand the source domain so that data from other domains can also perform well when training on the model, achieving the purpose of model generalization.
The source domain is XS⊂ℝW×H×3, which has segmentation labels made by professional ophthalmologists, denoted as YS⊂ℝW×H where W is the width of the picture and H is the height of the picture. And our enhanced domain generated by the convolutional autoencoder CAE is denoted as XS+⊂ℝW×H×3. The source domain and the enhanced domain are mixed to become the enhanced source domain XU⊂ℝW×H×3. Since the source domain and the enhanced domain behave the same semantically, only the details are different, so the labels of the enhanced domain can use the labels corresponding to the source domain, and there is a one-to-one mapping relationship. For each image xs ∈ XS belonging to the source domain, an image xs+∈XS+ in the enhanced domain can be generated, and they share the label ys ∈ YS. When the source domain image is generated by CAE and becomes the enhanced domain, it will be put into our model together with the source domain image and the target domain image for training. The difference is, as shown in Figure 2, the images generated by the CAE module are processed with the first boundary discriminator to distinguish the source domain and the enhanced domain, the second mask discriminator to distinguish the new source domain (the union of the source domain and the enhanced domain) and the target domain, and the third boundary discriminator to distinguish the new source domain and the target domain. The three discriminators corresponding to the three branches will be described in detail below.
There are three discriminators with a different function for each. The first one is the discriminator Db+, which input is judged to belong to the source domain XS (denoted as 1) or belongs to the enhancement domain XS+ (denoted as 0). This setting is to ensure that while the enhancement domain expands on the basis of the source domain, the boundary distribution of the enhancement domain approximates the boundary distribution of the source domain. Therefore, the training objective of the boundary discriminator between the enhancement domain and the source domain can be set as:
LDb+=1N[∑i =1NLD(pxsb,1)+∑i =1NLD(pxs+b,0)] (3)where N is the number of images in the source domain and the enhanced domain. Since the images in the enhanced domain and the source domain are generated with 1:1 (see Section 2.1), the number is N. And LD is a common binary cross-entropy loss. At this time, in order to ensure that the boundary distribution of the enhancement domain will approximate the boundary distribution of the source domain, we need to further optimize the segmentation network:
Ladvb+=1N∑i =1NLD(pxs+b,1) (4)The second one is the discriminator Db, input is judged to belong to the union XU of the source domain XS and the enhanced domain XS+ (marked as 1) or belong to the target domain XT (marked as 0). Henceforth, this union XU is called the new source domain. This setting is to ensure that the boundary distribution of the target domain is close to the boundary distribution of the new source domain, and to improve the prediction accuracy of the target domain in a boundary-driven manner. Therefore, the training objectives of the boundary discriminators of the new source and target domains can be set as:
LDb=1NU∑i=1NULD(pxub,1)+1NT∑i=1NTLD(pxtb,0) (5)where NU is the number of pictures in the new source domain, and NT is the number of pictures in the target domain. At this time, in order to ensure that the boundary distribution of the target domain will approximate the boundary distribution of the new source domain, we still need to further optimize the segmentation network:
Ladvb=1NT∑i =1NTLD(pxtb,1) (6)Finally, there is a discriminator Dm. If only boundary-driven confrontation is used, it is still easy to generate uncertain predictions inside the optic cup and optic disc, resulting in an only good performance at the boundary. However, the goal is to segment the entire optic cup and the optic disc. Therefore, we also need to perform adversarial learning on masks to narrow the distribution difference between the new source and target domains. Specifically, the objectives of our mask discriminator for new source and target domains can be set as:
LDm=1NU∑i =1NULD(pxum,1)+1NT∑i =1NTLD(pxtm,0) (7)At the same time, we still need to optimize the segmentation network and perform adversarial learning to fool the discriminator and make the target domain images generate prediction masks close to the new source domain. The detailed settings are as follows:
Ladvm =1NT∑i =1NTLD(pxtm,1) (8)Combine Ladvm, Ladvb, and Ladvb+ as:
Ladv=Ladvm+Ladvb+Ladvb+ (9) 2.3. Network architecture and loss functionAs it is shown in Figure 2, the backbone is based on the DeepLabv3+ (Chen et al., 2018) architecture and adds the Atrous Spatial Pyramid Pooling (ASPP) component to capture contextual information at multiple scales. The high-level and low-level features are then concatenated, and the boundary and mask prediction branches are added after this. Both the boundary prediction branches are composed of the same structure, which is composed of three convolutional layers, and the output channels are 256, 256, and 1, respectively. The input of the mask branch is the concatenation of the shared features and the boundary prediction. The advantage of this design lies in the ability to bound the fine-grained segmentation masks with the help of boundary supervision.
For the specific structure of the convolutional autoencoder part, see Section 2.1. The last part is the discriminator. The three discriminators Db+, Db and Dm have a similar structure, which contains five convolutional layers, and the number of channels is 64, 128, 256, 512, 1 and in that order. And the kernel size of these five layers is 4 × 4, and the stride size is 2 × 2. After each convolutional layer, there is a LeakyReLU activation function instead of the ReLU (α = 2). But the last layer is special, using the Sigmoid activation function. Through recursive iteration, the receptive field size of each discriminator is 94 × 94. Subsequently, each patch output size is 16 × 16 and is distinguished as true (1) or false (0) by Db+, Db and Dm.
In the loss function, Lm is the mask prediction loss, which takes the form of cross-entropy and performs multi-label classification processing (Wang et al., 2019b) simultaneously, so that the optic cup and optic disc can be segmented at the same time. Lb is the boundary regression loss. The loss functions Lm and Lb are:
Lm=−1N∑i=1N[yxum·log(pxum)+(1−yxum)·log(1−pxum)],Lb=1N∑i=1N(yxub−pxub)2 (10)where p ∈ [0, 1] represents the predicted probability and y ∈ represents the ground truth of the segmentation.
Finally, the overall segmentation network loss is:
L=Lm+Lb+λadvLadv (11)where λadv is the parameter used to balance the loss. The discriminator is then trained according to Equations (3), (5), and (7).
3. Experiments and results 3.1. Experimental setupWe evaluate the proposed method with three public available datasets REFUGE challenge dataset (Orlando et al., 2020), Drishti-GS (Sivaswamy et al., 2015) and RIM-ONE-r3 (Fumero et al., 2011). Since only the optic cup and optic disc are segmented, we processed the original dataset and re-cropped it into ROIs (Wang et al., 2019b) of size 512 × 512, centered on the OD. Following existing experience (Wang et al., 2019b), we apply standard data augmentation strategies to the images, including Gaussian noise, random erasure, rotation, contrast adjustment, elastic transformation, etc. The detailed statistics of the dataset are shown in Table 2.
Table 2. Public fundus datasets used for training and testing in experiments.
We implement CAE-BMAL in Pytorch. The source and enhanced domain boundary discriminator Db+, the source and target domain boundary discriminator Db and the mask discriminator Dm are all optimized by the stochastic gradient descent SGD algorithm, and the initial learning rate is 1e-3 according to experience. The segmentation network is optimized by the Adam algorithm, and the learning rate is set to 2.5e-5 at this time. We train on a GPU server with a single NVIDIA TESLA V100 32G.
3.2. Evaluation indicatorsWe adopt the Dice Similarity Coefficient (DSC) and the Vertical Cup-to-Disk Ratio (CDR) to evaluate the segmentation performance. Among them, DSC and CDR are defined as:
DSC=2×TP2×TP+FP+FN, δ=|CDRp−CDRg|,CDR=d(OC)d(OD) (12)where TP, TN, FP, and FN represent the number of true positives, true negatives, false positives, and false negatives at the pixel level, respectively. d(OC) and d(OD) represent the vertical diameters of OC and OD and are used to represent the error between the predicted cup-to-disk ratio and the cup-to-disk ratio given by the actual clinician. We want the bigger the DSC the better and the smaller the better. The reason why we choose these two evaluation indicators is that the dice coefficient is usually a commonly used evaluation indicator for segmentation tasks, especially for optic cup and optic disc segmentation tasks, and the CDR value is one of the important indicators used in glaucoma screening in clinical medicine.
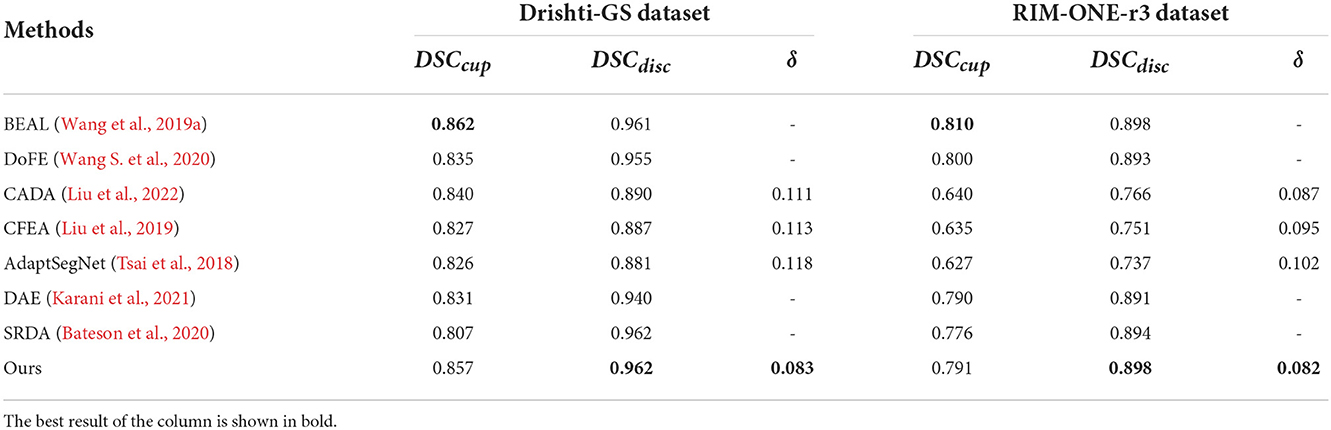
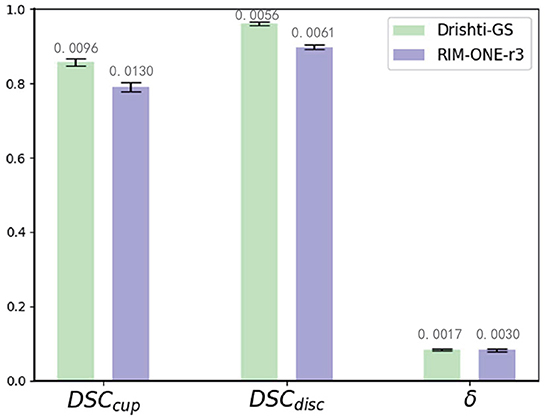
3.3. Performance on Drishti-GS and RIM-ONE-r3 datasetsWe compare our method with state-of-the-art domain adaptation or domain generalization segmentation methods: BEAL (Wang et al., 2019a), DoFE (Wang S. et al., 2020), CADA (Liu et al., 2022), CFEA (Liu et al., 2019), AdaptSegNet (Tsai et al., 2018), DAE (Karani et al., 2021), and SRDA (Bateson et al., 2020) for comparison. We use REFUGE (train) as the source domain and Drishti-GS (train), and RIM-ONE-r3 (train) as the target domain for training, and tested with Drishti-GS (test) and RIM-ONE-r3 (test), respectively. For BEAL, DoFE, CADA and CFEA, we follow the parameters mentioned in these paper and evaluate the performance. For AdaptSegNet, DAE and SRDA, we follow the parameters mentioned in these paper but replace the evaluation metrics to implement the experiments on REFUGE, Drishti-GS and RIM-ONE-r3 datasets. Then all these 7 state-of-the-art are evaluated with the proposed MAE-BMAL method under same metric. The quantitative results are shown in Table 3. It can be seen that the proposed CAE-BMAL method outperforms other domain-adaptive comparison methods on the OD segmentation metrics, which can indicate that our framework has a stronger generalization ability. Although the BEAL method performs better than our method on OC segmentation, it does not evaluate the CDR and therefore cannot screen for glaucoma. And more importantly, due to the influence of light, the OC boundary itself is more difficult to discriminate than the OD boundary of most pictures, and our method partly relies on boundary discrimination. Compared with other methods, our method is at least 2.8% lower in Drishti-GS, and the performance is significantly improved; it is also reduced by at least 0.5% in RIM-ONE-r3, so it can play a better role in the practical application of glaucoma discrimination. Meanwhile, we run the experiment 5 times and report the average performance and standard deviation, as shown in Figure 3. The number on each bar is the standard deviation, the three green bars are the results on the Drishti-GS dataset, and the three blue bars are the results on the RIM-ONE-r3 dataset. The unit of the y-axis is the same as that in Table 3, and the height of each column corresponds to the result of the Ours row in Table 3, that is, the average value after 5 experiments.
Table 3. Comparison of segmentation methods using domain adaptation.
Figure 3. Mean performance and standard deviation on the Drishti-GS dataset and the RIM-ONE-r3 dataset.
Figure 4 shows several qualitative segmentation results of the proposed method compared to BEAL and DoFE. To ensure the fairness of the experiment, we use the same scale to crop the ROI region. As can be seen from the visual contours, the segmentation results of our scheme under various lighting conditions (especially low-light conditions) are better and closer to the ground truth than the other two.
Figure 4. Qualitative segmentation results were trained on REFUGE and tested on Drishti-GS and RIM-ONE-r3 datasets. The samples were randomly selected from their respective datasets. Green and blue outlines represent the boundaries of OD and OC, respectively.
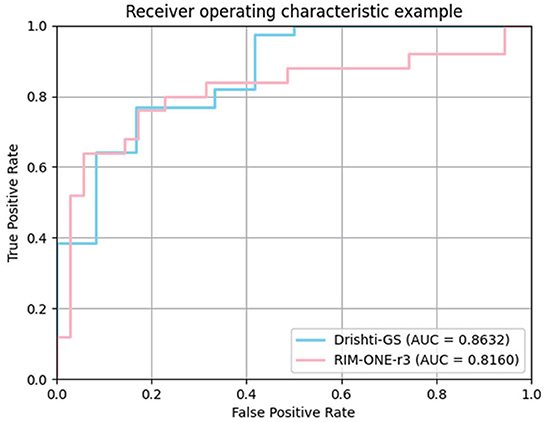
In the medical field, the vertical CDR value is one of the important indicators for glaucoma screening. To verify the correlation between the CDR estimates derived from our model and glaucoma, we further plotted ROC curves on the Drishti-GS and RIM-ONE-r3 datasets. The curve is obtained by calculating the true positive rate and false positive rate by setting different thresholds. The closer the ROC curve is to the upper left corner, the better the performance. AUC (Area Under Curve) is defined as the area under the ROC curve. The larger the area, the better the effect. We plotted the ROC curve in Figure 5 and calculated the AUC.
Figure 5. ROC curves of our method for glaucoma screening on Drishti-GS and RIM-ONE-r3 datasets.
3.4. Performance on REFUGE datasetWe combine the optic cup and optic disc segmentation results of the MICCAI 2018 report REFUGE challenge and use the same dataset. The challenge is weighted according to the following formula, and the individual and total scores are ranked:
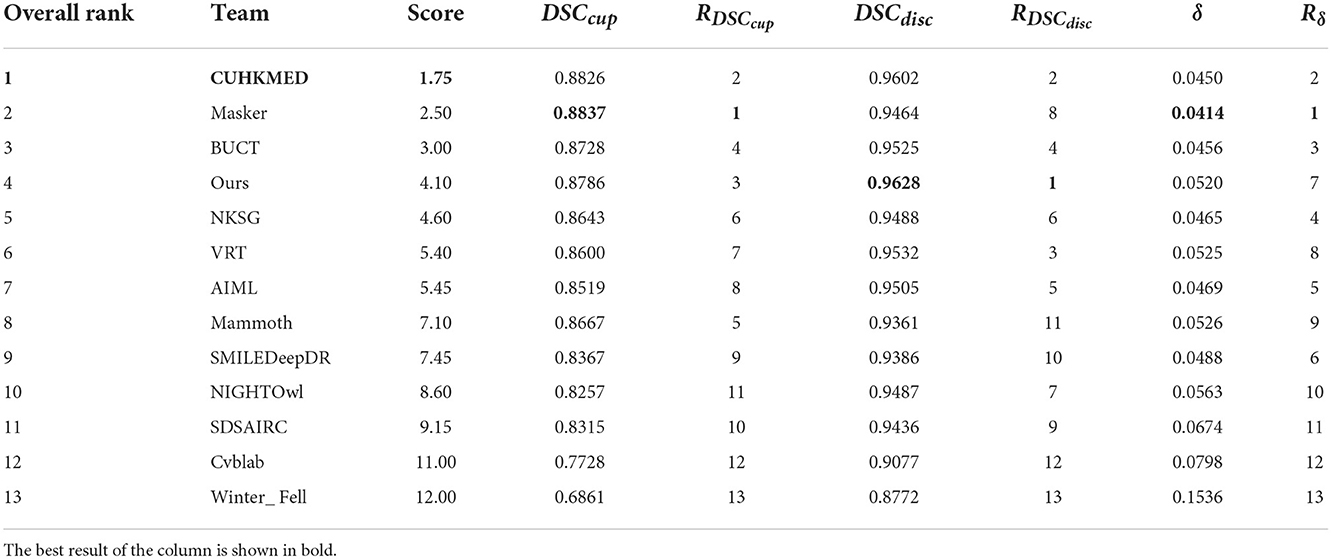
R=0.35×Rcup+0.25×Rdisc+0.4×Rδ (13)A total of 12 teams were selected for this challenge, to which we compared our results and redrawn Table 4. To further improve the segmentation performance, the participating teams ensemble several models to obtain predictions on the images of the test set. For example, the CUHKMED team integrated five models. In contrast, we only took the form of a single model and ranked fourth overall in the absence of third-party data to support it. At the same time, our model achieves the best results on optic disc segmentation, ranking first, and improves the corresponding term by 0.26%; it also achieves good results on optic disc segmentation, ranking third. However, due to the unclear boundary between the optic cup and the optic disc caused by the light, the boundary of the optic cup segmentation is not smooth enough, which further leads to poor performance compared with other teams. Later, we consider adding other attention modules to specifically deal with the cup. But overall, our model achieves good results in dealing with segmentation under the influence of complex blood vessels.
Table 4. Cup/disc segmentation results on the REFUGE test set.
3.5. Ablation studiesIn this section, we discuss the performance
留言 (0)