


記住我







The role of human emotion in cognition is vital and has been studied for a long time with different experimental and behavioral paradigms. Psychology researchers have tried to understand human perception through surveys for a long time. Recently, with the increasing need to learn about human perception, without human biases and conception of various emotions across people (Ekman, 1972), we observe the increasing popularity of neurophysiological recordings and brain imaging methods. Since emotions are triggered almost instantly, Electroencephalography (EEG) is an attractive choice due to its better temporal resolutions and mobile recording devices (Lang, 1995; Moss et al., 2003; Koelstra et al., 2012; Katsigiannis and Ramzan, 2018; Ko et al., 2021; Tuncer et al., 2021).
The algorithmic pipeline of decoding user intentions through neurophysiological signals consists of denoising, pre-processing, feature extraction, electrode and feature selection, and classification. Although there are deep-learning algorithms (Haselsteiner and Pfurtscheller, 2000; Übeyli, 2009; Schirrmeister et al., 2017; Karlekar et al., 2018; Zhou et al., 2018; Jeevan et al., 2019; Jin and Kim, 2020; Tao et al., 2020) which claim to do the frequency decomposition, feature extraction, and classifier training in the hidden layers, their explainability is limited, and amount of training data required is huge. Machine learning with time-domain features performs weighted spatial-temporal averaging of EEG signals with pattern recognition. Feature extraction methods (Ting et al., 2008; Al-Fahoum and Al-Fraihat, 2014; Oh et al., 2014; Zhang et al., 2016) require human effort, and expertise is required in identifying the appropriate features and electrode location depending on the modality, stimulus, recording instrument, and participant. Moreover, current feature extraction and selection method benchmarks (Song et al., 2018; Dar et al., 2020) for emotion recognition are focused on eliciting emotions through video-based stimuli, and the applicability of the proposed methods for static-image elicited emotional response is limited. Most pattern recognition benchmarks (Placidi et al., 2016; Kusumaningrum et al., 2020; Dhingra and Ram Avtar Jaswal, 2021) for decoding human emotions from EEG signals have been performed with research-grade EEG recording systems with large setup times, sophisticated recording setup, and cost. Although a portable EEG headset has a lesser signal-to-noise ratio, its low-cost and easy use makes it an attractive choice for collecting data from a wider population sample and overcoming the problem of insufficient uniform EEG data for algorithmic research.
In this study, first, we propose a protocol for eliciting emotions by presenting selected images from the OASIS dataset (Kurdi et al., 2016) and signal recording through a low-cost, portable EEG headset. Second, we create a pipeline of pre-preprocessing, feature extraction, electrode and feature selection, and classifier for emotional response (Valence and Arousal) decoding and evaluate it for our dataset and two open-source datasets; incremental training to demonstrate the dependence of performance on population sample size is presented. Third, we rank different categories of feature extraction techniques to evaluate the applicability of feature extraction techniques for highlighting the patterns indicative of emotional responses. Moreover, we analyze the electrode importance and rank different brain regions for their importance. The electrodes' relative importance can help explain the significance of different regions for emotion elicitation, lead to optimized electrode configuration while conducting neural-recording studies, and inspire the development of advanced feature extraction techniques for emotional response decoding. Fourth, we ask if we can automate the feature selection and electrode selection techniques for BCI pipeline engineering and validate the procedure with a qualitative and quantitative comparison with neuroscience literature. Importantly, we validate the pipeline for two open-source datasets based on video-based stimuli and recorded signals through the proposed protocol for eliciting emotions through images. The variety of stimuli, recording instruments, and demography of the population sample aids in eliminating bias and rigorous analysis of different pipeline components. Lastly, we publish the proposed pipeline and recorded dataset for the community.
In the past, the scope of using electrophysiological data for emotion prediction has widened and led to standardized 2D emotion metrics of valence and arousal (Russell, 1980) to train and evaluate pattern recognition algorithms. Human brain-recording experiments have been conducted to associate emotion quantitatively with words, pictures, sounds, and videos (Lang, 1995; Lane et al., 1999; Gerber et al., 2008; Eerola and Vuoskoski, 2011; Leite et al., 2012; Moors et al., 2013; Warriner et al., 2013; Kurdi et al., 2016; Mohammad, 2018). EEG frequency band is dominant during different roles, corresponding to various emotional, and cognitive states (Klimesch et al., 1990; Klimesch, 1996, 1999, 2012; Bauer et al., 2007; Berens et al., 2008; Jia and Kohn, 2011; Kamiński et al., 2012). Besides using energy spectral values, researchers use many other features such as frontal asymmetry, differential entropy and indexes for attention, approach motivation and memory. “Approach” emotions, such as happiness, are associated with left hemisphere brain activity, whereas “withdrawal,” such as disgust, emotions, are associated with right hemisphere brain activity (Davidson et al., 1990; Coan et al., 2001). The left-to-right alpha activity is therefore used for approach motivation. The occipito-parietal alpha power has been found to have correlations with attention (Smith and Gevins, 2004; Misselhorn et al., 2019). Fronto-central increase in theta and gamma activities has been proven essential for memory-related cognitive functions (Shestyuk et al., 2019). Differential entropy combined with asymmetry gives out features such as differential and rational asymmetry for EEG segments are some recent developments as forward-fed features for neural networks (Duan et al., 2013; Torres et al., 2020).
In an attempt to classify emotions using EEG signals, many time-domain, frequency-domain, continuity, complexity (Gao et al., 2019; Galvão et al., 2021), statistical, microstate (Lehmann, 1990; Milz et al., 2016; Shen X. et al., 2020), wavelet-based (Jie et al., 2014), and Empirical (Patil et al., 2019; Subasi et al., 2021) features extraction techniques have been proposed. We have summarized the latest studies using EEG to recognize the emotional state in Table 1.
Table 1. Table summarizing various machine learning algorithms and features used to classify emotions on various datasets, reported with accuracy.
This paper is organized as follows. Section 2.1 describes the three datasets used for our analysis. The theoretical background and the details of pre-processing steps (referencing, filtering, motion artifact, and rejection and repair of bad trials) are discussed in Section 2.2. Section 2.3 addresses the feature extraction details and provides an overview of the features extracted. Section 2.4 describes the feature selection procedure adopted in this work. Section 3 presents our experiments and results. This is followed by Section 4 for discussion of experiments performed and results obtained in this work. Finally, Section 5 summarizes this work's conclusion and future scope.
2. Materials and methods 2.1. Datasets 2.1.1. OASIS EEG dataset 2.1.1.1. Stimuli selectionThe OASIS image dataset (Kurdi et al., 2016) consists of a total of 900 images from various categories, such as natural locations, people, events, and inanimate objects with various valence and arousal elicitation values. Out of 900 images, 40 were selected to cover the valence and arousal rating spectrum, as shown in Figure 1.
Figure 1. Valence and arousal ratings of OASIS dataset. Valence and arousal ratings of the entire OASIS (Kurdi et al., 2016) image dataset (blue) and the images selected for our experiment (red). The images were selected to represent each quadrant of the 2D space.
2.1.1.2. Participants and deviceThe experiment was conducted in a closed room, with the only light source being the digital 21” Samsung 1,080 p monitor. Data was collected from fifteen participants of mean age 22 with ten males and five females using an EMOTIV Epoc EEG headset consisting of 14 electrodes according to the 10–20 montage system at a sampling rate of 128 Hz, and only the EEG data corresponding to the image viewing time was segmented using markers and used for analysis.
The study was approved by the Institutional Ethics Committee of BITS, Pilani (IHEC-40/16-1). All EEG experiments/methods were performed in accordance with the relevant guidelines and regulations as per the Institutional Ethics Committee of BITS, Pilani. All participants were explained the experiment protocol, and written consent for recording the EEG data for research purposes was obtained from each subject.
2.1.1.3. ProtocolThe subjects were explained the meaning of valence and arousal before the start of the experiment and were seated at a distance of 80–100 cm from the monitor.
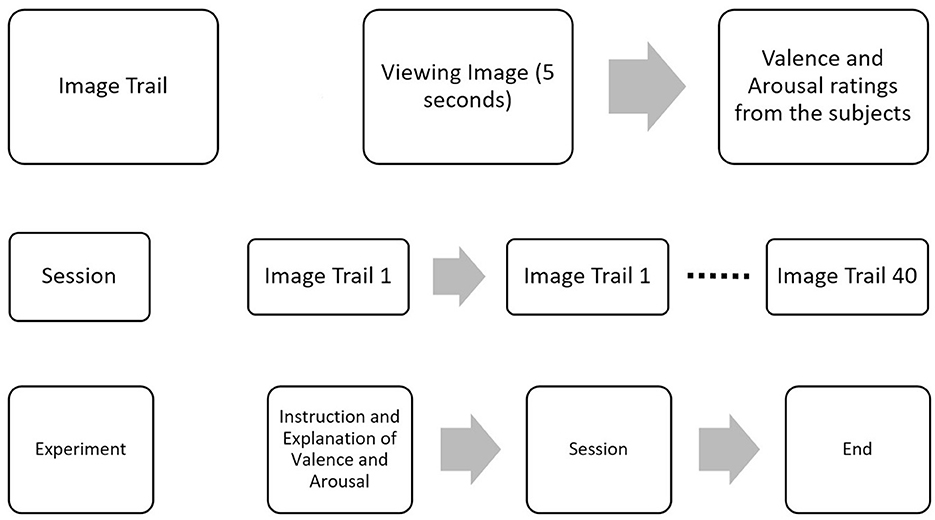
The images were shown for 5 s through Psychopy (Peirce et al., 2019), and the participants were asked to rate valence and arousal on a scale of 1–10 before proceeding to the next image, as shown in Figure 2. Additionally, the participants' ratings were compared to the original ratings provided in the OASIS image dataset as shown in Supplementary Figure 1, and MSE between the two was 1.34 and 1.39 for valence and arousal, respectively.
Figure 2. EEG data collection protocol. Experiment protocol for the collection of EEG data. Forty images from the OASIS dataset were shown to elicit emotion in the valence and arousal planes. After presenting each image, ratings were collected from participants.
2.1.2. DEAPDEAP dataset (Koelstra et al., 2012) has 32 subjects; each subject was shown 40 music videos one min long. Participants rated each video in arousal, valence, like/dislike, dominance, and familiarity levels. Data was recorded using 40 EEG electrodes placed according to the standard 10–20 montage system. The sampling frequency was 128Hz. This analysis considers only 14 channels (AF3, F7, F3, FC5, T7, P7, O1, O2, P8, T8, FC6, F4, F8, AF4) for the sake of uniformity with the other two datasets.
2.1.3. DREAMERDREAMER (Katsigiannis and Ramzan, 2018) dataset has 23 subjects; each subject was shown 18 videos at a sampling frequency 128 Hz. Audio and visual stimuli in the form of film clips were employed to elicit emotional reactions from the participants of this study and record EEG and ECG data. After viewing each film clip, participants were asked to evaluate their emotions by reporting the felt arousal (ranging from uninterested/bored to excited/alert), valence (ranging from unpleasant/stressed to happy/elated), and dominance. Data was recorded using 14 EEG electrodes.
2.2. PreprocessingRaw EEG signals extracted from the recording device are continuous, unprocessed signals containing various kinds of noise, artifacts and irrelevant neural activity. Hence, a lack of EEG pre-processing can reduce the signal-to-noise ratio and introduce unwanted artifacts into the data. In the pre-processing step, noise and artifacts presented in the raw EEG signals are identified and removed to make them suitable for analysis in the further stages of the experiment. The following subsections discuss each pre-processing step (referencing, filtering, motion artifact, and rejection and repair of bad trials) in more detail.
2.2.1. ReferencingThe average amplitude of all electrodes for a particular time point was calculated and subtracted from the data of all electrodes. This was done for all time points across all trials.
2.2.2. FilteringA Butterworth bandpass filter of 4th order was applied to filter out frequencies between 0.1 and 40 Hz.
2.2.3. Motion artifactMotion artifacts were removed by using Pearson Coefficients (Onikura et al., 2015). The gyroscopic data (accelerometer readings) and EEG data were taken corresponding to each trial. Each of these trials of EEG data was separated into its independent sources using Independent Component Analysis (ICA) algorithm. For the independent sources obtained corresponding to a single trial, Pearson coefficients were calculated between each source signal and each axis of accelerometer data for the corresponding trial. The mean and standard deviations of Pearson coefficients were then calculated for each axis obtained from overall sources. The sources with Pearson coefficient 2 standard deviations above the mean for any one axis were high pass filtered for 3 Hz using a Butterworth filter as motion artifacts exist at these frequencies. The corrected sources were then projected back into the original dimensions of the EEG data using the mixing matrix given by ICA.
2.2.4. Rejection and repair of bad trialsAuto Reject is an algorithm developed by Jas et al. (2017) for rejecting bad trials in Magneto-/Electro- encephalography (M/EEG data), using a cross-validation framework to find the optimum peak-to-peak threshold to reject data.
• We first consider a set of candidate thresholds ϕ.
• Given a matrix of dimensions (epochs × channels × time points) by X ∈ R N×P, where N is the number of trials/epochs and P is the number of features. P = Q*T, Q is the number of sensors, and T is the number of time points per sensor.
• The matrix is split into K-folds. Each of the K parts will be considered the training set once, and the rest of the K-1 parts become the test set.
• For each candidate threshold, i.e., for each
we apply this candidate peak to peak threshold (ptp) to reject trials in the training set known as bad trials, and the rest of the trials become the good trials in the training set.
where Xi indicates a particular trial.
• A is the peak-to-peak threshold of each trial, Gl is the set of trials whose ptp is less than the candidate threshold being considered
• Then, the mean amplitude of the good trials (for each sensor and their corresponding set of time points) is calculated
• While the median amplitude of all trials is calculated for the test set X~valk
• Now, the Frobenius norm is calculated for all K folds, giving K errors ek ∈ E; the mean of all these errors is mapped to the corresponding candidate threshold.
• The following analysis was done considering all channels at once; thus, it is known as auto-reject global
• Similar process can be considered where analysis can be done for each channel independently, i.e., data matrix becomes(epochs × 1 × time points) known as the local auto-reject, where we get optimum thresholds for each sensor independently.
• The most optimum threshold is the one that gives the least error
T*=Tl* with l*=argmin l1K∑i=1KeklAs bad trials were already rejected in the DEAP and DREAMER datasets, we do not perform automatic trial rejections.
2.3. Feature extractionIn this work, the following set of 36 features was extracted from the EEG signal data with the help of EEGExtract library (Saba-Sadiya et al., 2020) for all three datasets:
• Shannon Entropy (S.E.)
• Subband Information Quantity for Alpha [8–12 Hz], Beta [12–30 Hz], Delta [0.5–4 Hz], Gamma [30–45 Hz], and Theta[4–8 Hz] band (S.E.A., S.E.B., S.E.D., S.E.G., S.E.T.)
• Hjorth Mobility (H.M.)
• Hjorth Complexity (H.C.)
• False Nearest Neighbor (F.N.N)
• Differential Asymmetry (D.A., D.B., D.D., D.G., D.T.)
• Rational Asymmetry (R.A., R.B., R.D., R.G., R.T.)
• Median Frequency (M.F.)
• Band Power (B.P.A., B.P.B., B.P.D., B.P.G., B.P.T.)
• Standard Deviation (S.D.)
• Diffuse Slowing (D.S.)
• Spikes (S.K.)
• Sharp spike (S.S.N.)
• Delta Burst after Spike (D.B.A.S.)
• Number of Bursts (N.B.)
• Burst length mean and standard deviation (B.L.M., B.L.S.)
• Number of Suppressions (N.S.)
• Suppression length mean and standard deviation (S.L.M., S.L.S.).
These features were extracted with a 1 s sliding window and no overlap. The extracted features can be categorized into two different groups based on the ability to measure the complexity and continuity of the EEG signal. The reader is encouraged to refer to the work done by Ghassemi (2018) for an in-depth discussion of these features.
2.3.1. Complexity featuresComplexity features represent the degree of randomness and irregularity associated with the EEG signal. Different features in the form of entropy and complexity measures were extracted to gauge the information content of non-linear and non-stationary EEG signal data.
2.3.1.1. Shannon entropyShannon entropy (Shannon, 1948) is a measure of uncertainty (or variability) associated with a random variable. Let X be a set of finite discrete random variables X=,xi∈Rd, Shannon entropy, H(X), is defined as
H(X)=-c∑i=0mp(xi)ln p(xi) (1)where c is a positive constant and p(xi) is the probability of (xi) (ϵ) X such that:
∑i=0mp(xi)=1 (2)Higher entropy values indicate high complexity and less predictability in the system (Phung et al., 2014).
2.3.1.2. Subband information quantitySub-band Information Quantity (SIQ) refers to the entropy of the decomposed EEG wavelet signal for each of the five frequency bands (Jia et al., 2008; Valsaraj et al., 2020). In our analysis, the EEG signal was decomposed using a butter-worth filter of order 7, followed by an FIR/IIR filter. This resultant wave signal's Shannon entropy [H(X)] is the desired SIQ of a particular frequency band. Due to its tracking capability for dynamic amplitude change and frequency component change, this feature has been used to measure the information in the brain (Shin et al., 2006; Kanungo et al., 2021).
2.3.1.3. Hjorth parametersHjorth Parameters indicate time-domain statistical properties introduced by Hjorth (1970). Variance-based calculation of Hjorth parameters incurs a low computational cost, making them appropriate for EEG signal analysis. We use complexity and mobility (Das and Pachori, 2021) parameters in our analysis. Horjth mobility signifies the power spectrum's mean frequency or the proportion of standard deviation. It is defined as:
HjorthMobility=var(dx(t)dt)var(x(t)) (3)where var(.) denotes the variance operator and x(t) denotes the EEG time-series signal.
Hjorth complexity signifies the change in frequency. This parameter has been used to measure the signal's similarity to a sine wave. It is defined as:-
HjorthComplexity=Mobility(dx(t)dt)Mobility(x(t)) (4) 2.3.1.4. False nearest neighborFalse Nearest Neighbor is a measure of signal continuity and smoothness. It is used to quantify the deterministic content in the EEG time series data without assuming chaos (Kennel et al., 1992; Hegger and Kantz, 1999).
2.3.1.5. Asymmetry featuresWe incorporate Differential Entropy (DE) (Zheng et al., 2014) in our analysis to construct two features for each of the five frequency bands, namely, Differential Asymmetry (DASM) and Rational Asymmetry (RASM). Mathematically, DE [h(X)] is defined as:
h(X)=-∫-∞∞12πσ2exp(x-μ)22σ2log12πσ2 exp(x-μ)22σ2dx=12log2πeσ2 (5)where X follows the Gauss distribution N(μ,σ2), x is a variable and π and exp are constant.
Differential Asymmetry (or DASM) (Duan et al., 2013) for each frequency band was calculated as the difference of differential entropy of each of seven pairs of hemispheric asymmetry electrodes.
DASM=h(Xileft)-h(Xiright) (6)Rational Asymmetry(or RASM) (Duan et al., 2013) for each frequency band was calculated as the ratio of differential entropy between each of seven pairs of hemispheric asymmetry electrodes.
RASM=h(Xileft)/h(Xiright) (7) 2.3.2. Continuity featuresContinuity features signify the clinically relevant signal characteristics of EEG signals (Hirsch et al., 2013; Ghassemi, 2018). These features have been acclaimed to serve as qualitative descriptors of states of the human brain and are important in emotion recognition.
2.3.2.1. Median frequencyMedian Frequency refers to the 50% quantile or median of the power spectrum distribution. Median Frequency has been studied extensively due to its observed correlation with awareness (Schwilden, 1989) and its ability to predict imminent arousal (Drummond et al., 1991). It is a frequency domain or spectral domain feature.
2.3.2.2. Band powerBand power refers to the signal's average power in a specific frequency band. The powers of the delta, theta, alpha, beta, and gamma frequency bands were used as spectral features. Initially, a butter-worth filter of order seven was applied to the EEG signal to calculate band power. IIR/FIR filter was applied further on the EEG signal in order to separate out signal data corresponding to a specific frequency band. The average of the power spectral density was calculated using a periodogram of the resulting signal. Signal Processing sub-module (scipy.signal) of SciPy library (Virtanen et al., 2020) in python was used to compute the band power feature.
2.3.2.3. Standard deviationStandard Deviation has proved to be an important time-domain feature in past experiments (Panat et al., 2014; Amin et al., 2017). Mathematically, it is defined as the square root of the variance of the EEG signal segment.
2.3.2.4. Diffuse slowingPrevious studies (Boutros, 1996) have shown that diffuse slowing correlates with impairment in awareness, concentration, and memory; hence, it is an important feature for estimating valence/arousal levels from EEG signal data.
2.3.2.5. SpikesSpikes (Hirsch et al., 2013) refers to the peaks in the EEG signal up to a threshold, fixed at mean + 3 standard deviation. The number of spikes was computed by finding local minima or peaks in EEG signal over seven samples using scipy.signal.find_peaks method from SciPy library (Virtanen et al., 2020).
2.3.2.6. Delta burst after spikeThe change in delta activity after and before a spike is computed epoch-wise by adding the mean of seven elements of the delta band before and after the spike, used as a continuity feature.
2.3.2.7. Sharp spikeSharp spikes refer to spikes which last <70 ms and is a clinically important features in the study of electroencephalography (Hirsch et al., 2013).
2.3.2.8. Number of burstsThe number of amplitude bursts(or simply the number of bursts) constitutes a significant feature (Hirsch et al., 2013).
2.3.2.9. Burst length mean and standard deviationStatistical properties of the bursts, mean μ and standard deviation σ of the burst lengths, have been used as continuity features.
2.3.2.10. Number of suppressionsBurst Suppression refers to a pattern where high voltage activity is followed by an inactive period and is generally a characteristic feature of deep anesthesia (Ching et al., 2012). We use the number of contiguous segments with amplitude suppressions as a continuity feature with a threshold fixed at 10μ (Saba-Sadiya et al., 2020).
2.3.2.11. Suppression length mean and standard deviationStatistical properties like mean μ and standard deviation σ of the suppression lengths are used as a continuity feature.
2.4. Feature selectionAfter feature extraction, feature selection is performed to optimize the selection and ranking of features, reduce model complexity, decrease computation time and enhance learning precision. The feature selection step plays a crucial role in eliminating redundant features that do not contribute to model performance while preserving the relevant information of EEG signals. Hence, selecting the correct predictor variables or feature vectors can improve the learning process in any machine learning pipeline. In this work, initially, zero-variance or constant features were eliminated from the set of 36 extracted EEG features using the VarianceThreshold feature selection method using sci-kit learn package (Pedregosa et al., 2011). Next, a subset of 25 features common to all 3 datasets (DREAMER, DEAP, and OASIS EEG) was selected after applying the VarianceThreshold method for further analysis. This was done to validate our approach on a common set of features. The set of 11 features (S.E., F.N.N., D.S., S.K., D.B.A.S., N.B., B.L.M., B.L.S., N.S., S.L.M., S.L.S.) were excluded from further analysis. Hence, we reduce the feature space from a set of 36 extracted features to this subset of 25 features. Corresponding to each feature, a feature matrix of shape [nc, ns] is generated. We append all these feature matrices to create a new matrix of shape [nc*nf, ns]. This matrix is inverted to get features as columns for each segment, i.e., a matrix of shape [ns, nc*nf] where nc is the number of channels, nf is the number of features and ns is the number of segments. These feature column vectors serve as input for the SelectKBest algorithm for performing feature selection and ranking for all three datasets. SelectkBest (Pedregosa et al., 2011) is a filter-based, univariate feature selection method intended to select and retain first k-best features based on the scores produced by univariate statistical tests. In our work, f_regression was used as the scoring function since valence and arousal are continuous numeric target variables. It uses Pearson correlation coefficient as defined in Equation (8) to compute the correlation between each feature vector in the input matrix, X and target variable, y, as follows:
ρi=(X[:,i]-mean(X[:,i]))*(y-mean(y))std(X[:,i])*std(y) (8)The corresponding F-value is then calculated as:
Fi=ρi21-ρi2*(n-2) (9)where n is the number of samples.
SelectkBest method then ranks the feature vectors based on F-scores returned by the f_regression method. Higher scores correspond to better features.
2.5. Regression and evaluation 2.5.1. Random forest regressorRandom forest is an ensemble estimator that fits many classifying decision trees on various sub-samples of the data set and uses averaging over this ensemble of trees to improve the predictive accuracy and control over-fitting (Pedregosa et al., 2011). Moreover, it has been found to be suitable for high-dimensional data. In this experiment, a random forest regressor was implemented with 100 tree estimators and squared-error criterion as base parameters using the sci-kit learn library.
2.5.2. Evaluation metricsThe following regression evaluation metrics were assessed to gauge the model performance as part of this experiment:
2.5.2.1. Root mean squared error (RMSE)Root Mean Square Error (RMSE) can be defined as the standard deviation of residual errors as shown in Equation (10). Hence, RMSE estimates the deviation of actual values from the predicted regression line. Lower RMSE corresponds to accurate predictions and smaller residual errors by the model. RMSE is more sensitive toward outliers than MAE since the error difference is squared.
RMSE(y,y^)=(1n)∑i=1n(y^i−yi)2 (10) 2.5.2.2. R2 scoreR2 score is a statistic that denotes the proportion of variance in the dependent variable (y) explained by independent variables (x) of the machine learning model. Higher values of R2 score correspond to greater ability of independent variables in explaining the variance in the dependent variable. Since the R2 score depends on the sample size of the dataset and the number of predictor variables, the R2 score is not meaningfully comparable across datasets of different dimensionality (MAR, 2021). R2 score can be computed as:
R2(y,ŷ)=1-∑i=1n(yi-ŷi)2∑i=1n(yi-ȳ)2 (11) 2.5.2.3. Mean absolute error (MAE)Mean Absolute Error or l1 loss is the mean of the absolute difference between the predicted value (yi^) and the actual value (yi) of the dependent variable as shown in Equation (12). MAE is a popular linear regression metric that uses the same scale of the observed value. Like RMSE, MAE is also a negatively oriented metric; thus, lower values correspond to more accurate predictions by the model.
MAE(y,ŷ)=1nsamples∑i=0nsamples-1|yi-ŷi| (12) 2.5.2.4. Explained variance (EV)Explained variance is a part of total variance that acts as a measure of discrepancy between the model and actual data. EV is different from the R2 score in computation as it does not account for systematic offset and uses biased variance to explain the spread of data points. Hence, if the mean error of the predictor is unbiased, the EV score and R2 score should become equal. EV can be calculated as:
EV(y,ŷ)=1-VarVar (13)where Var is the variance operator for variable θ.
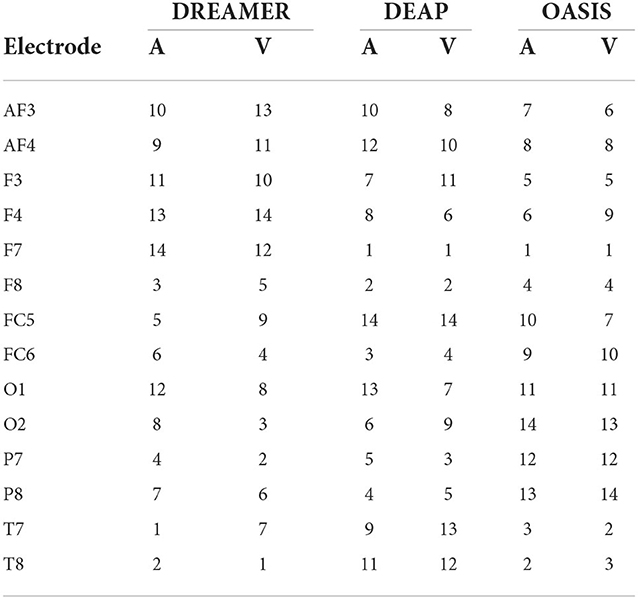
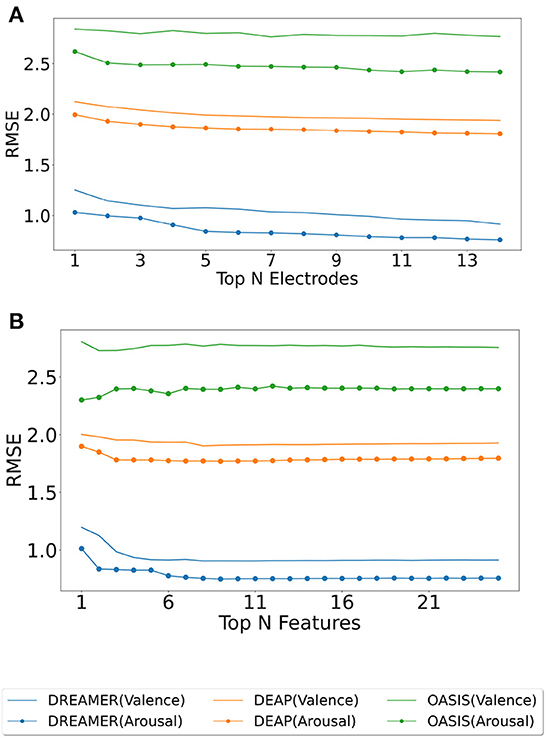
3. Results 3.1. Electrodes ranking and selectionThe electrodes were ranked for the three datasets using the SelectKBest method, as discussed in Section 2.4, and the ranks are tabulated for valence and arousal labels in Table 2. To produce a ranking for Top N electrodes, feature data for top N electrodes were initially considered. The resultant matrix was split in the ratio 80:20 for training and evaluating the random forest regressor model. The procedure was repeated until all 14 electrodes were taken into account. The RMSE values for the same are shown in Figure 3A. It should be noted that, unlike feature analysis, data corresponding to five features each of DASM and RASM was excluded from the Top N electrode-wise RMSE study since these features are constructed using pairs of opposite electrodes.
Table 2. Electrode ranking for valence label (V) and arousal label (A) based on SelectKBest feature selection method.
Figure 3. Model evaluation for feature and electrode selection. The random forest regressor was trained on the training set (80%) corresponding to top N electrodes (ranked using SelectKBest feature selection method), and RMSE was computed on the test set (20%) for valence (plain) and arousal (dotted) label on DREAMER, DEAP, and OASIS EEG datasets as shown in (A). A similar analysis was performed for top N features for DREAMER, DEAP, and OASIS EEG datasets, as shown in (B).
3.2. Features ranking and selection
留言 (0)