
記住我










Attention deficit hyperactivity disorder (ADHD) is a neurodevelopmental disorder characterised by a persistent pattern of inattention, hyperactivity and impulsive behaviour.1 Although symptoms emerge in preschool, ADHD tends to lead to clinical levels of impairment during the first few years of statutory education.2 ADHD can lead to poor outcomes across social, educational and health domains.3 4 It can be treated,5 but substantial diagnostic delays preclude effective early intervention.6 It is therefore vital that adequate resources are made available for timely ADHD detection, diagnosis and intervention. To effectively allocate adequate resources for ADHD, commissioners need accurate information on the level of need in schools, services and geographical regions.
Pooled estimates from population surveys suggest that 5.3% of the global population meet criteria for ADHD.2 This could be taken as a broad indicator of level of need in any given population, but some cases identified via population surveys will not be sufficiently severe or complex to require input from clinical services. Therefore, prevalence estimates from population surveys likely overestimate the true level of need in the population. Alternatively, level of need could be estimated from the prevalence of ADHD cases presenting to clinical services. However, only a fraction of cases requiring input seek help, receive a referral, diagnosis and treatment from clinical services.7 Therefore, prevalence estimates from clinical services likely underestimate the true level of need in the population.
Overall, there remains a need for accurate indicators of level of need which can inform commissioning and resource distribution. At the school level, mental health screening questionnaires administered by teachers can be used to identify pupils at risk of ADHD, which in could turn provide an estimate of ADHD prevalence for that school.8 However, this approach is resource intensive, and cannot practically be scaled up to larger populations to estimate burden of need in a wider geographical area.9 Machine learning techniques may be able to predict ADHD diagnosis at the individual level, but existing approaches again use data sources which cannot be practically scaled up to larger populations, such as MRI and electroencephalography data.10–13 Such models might also be prone to systematic biases14: ADHD is underdiagnosed and undertreated among ethnic minority groups, who are therefore unlikely to be adequately represented in the data on which such models are built, unless efforts are made to adjust for such biases.15 16
Therefore, there remains a need for accurate and unbiased ADHD prediction methods which are scalable to large populations or geographical regions. Administrative pupil-level data are already routinely collected and curated by most schools, and are available for whole populations.17 If machine learning approaches can be effectively applied to these data to build validated and unbiased models predicting childhood ADHD, they could be used to estimate burden of need and guide resource allocation at area, school and service levels. In this study, we applied machine learning approaches to a large, linked administrative school and clinical dataset to: (1) classify pupils in the population with a high likelihood of clinical ADHD, (2) differentiate pupils with ADHD from pupils with other clinical disorders, (3) explore the contribution of demographic, socioeconomic and education features to an ADHD diagnosis, and (4) evaluate a potential method to reduce sociodemographic biases.
MethodsStudy designThis was a retrospective cohort study, using an existing data linkage between the National Pupil Database (NPD) and South London and Maudsley National Health Service Foundation Trust Child and Adolescent Mental Health Services (SLaM CAMHS) (online supplemental table S1).18 19
SLaM is one of Europe’s largest providers of mental healthcare, serving the London boroughs of Croydon, Lambeth, Lewisham and Southwark. SLaM is the monopoly provider of local CAMHS services, including ADHD diagnostic services.18 Anonymised individual-level clinical data for these services are accessible for research via the Clinical Record Interactive Search (CRIS).
CRIS data for SLaM CAMHS services have been linked at the individual level to the NPD. The NPD is a longitudinal database of pupil-level and school-level data.17 The NPD pupil census is collected annually and contains a snapshot of pupils attending state-maintained schools in England, while NPD attainment datasets hold data for all statutory assessments that pupils complete during primary and secondary education.
The CRIS-NPD linkage process has been described in detail elsewhere.18 19 Linkage was conducted for referrals to SLaM between 2007 and 2013, for children and adolescents aged 4–18 years. Fuzzy deterministic matching was conducted based on personal identifiers in CRIS, which were sent to the Department for Education for linkage to the NPD. The match rate was 82.5%. As a result of this data linkage, we had access to educational records for pupils who were referred to SLaM from both inside and outside the catchment area, and local pupils who were not referred to SLaM.
ParticipantsThe analysed sample comprised children aged between 6 and 7 years, who were enrolled in mainstream state educational services (not specialist or alternative educational facilities), and who had education and attainment characteristics as captured at the Early Years Foundation Stage Profile (EYFSP; typically aged 4–5 years) and at Key Stage 1 (KS1; typically aged 6–7 years). Pupils were included if they were resident of the SLaM catchment area from 1 September 2007 to 31 August 2013. A resulting n=57 149 pupils were eligible for inclusion.
Main outcomeIndividual-level diagnosis of ADHD was measured from both structured and unstructured diagnosis fields in CRIS between September 2007 and August 2013. In structured fields, ADHD diagnosis was defined as International Classification of Diseases 10th Revision codes F90.0, F90.1, F90.8 or F90.9 (hyperkinetic, other hyperkinetic disorders, attention deficit disorder, hyperkinetic conduct disorder).20 In unstructured fields, ADHD diagnosis was identified and manually evaluated using previously established natural language processing techniques (positive predictive value ~0.82).21–24
Educational features and other covariatesSchool performance indicators were collected from EYFSP and KS1 datasets in the NPD. The EYFSP comprises teacher-assessed social, linguistic, physical and cognitive development at the end of the first year of schooling.25 KS1 comprises teacher-assessed English, maths and science at the end of the third year of formal education.26 Gender, age, ethnicity, free school meal eligibility (eFSM; a proxy measure for deprivation), attendance, first language, special educational need (SEN) and looked after child (LAC) status were also measured from the NPD. In total, 45 characteristics were included (online supplemental tables S2 and S3).
Predictive model preparation and buildingTo minimise the potential for reverse causality, we excluded pupils who were diagnosed with ADHD prior to their KS1 assessment (n=77; 10.5% of ADHD cases). We used a complete case approach, excluding pupils with missing data from our eligible sample (n=814; 1.4%). The resulting n=56 258 formed our population cohort.
To develop and compare machine learning classifiers, the dataset was randomly divided into a training set (n=42 192; 75.0%), validation set (n=7033; 12.5%) and test set (n=7033; 12.5%) with a similar proportion of ADHD cases (~1%) in each set. The training set was used to train the algorithms, while the validation set was used for model refinement (eg, hyperparameter tuning) and comparison. Final performance was evaluated on the test set. We compared several machine learning algorithms to classic statistical logistic regression (LR) approaches, and also a supervised approach based on neural networks, using a multilayer perceptron (MLP). The following classifiers were compared: LR, random forest (RF), support vector machines (SVM), Gaussian Naive Bayes (GNB) and the MLP. For GNB, we first tested that continuous features associated with each class were distributed according to a Gaussian distribution. For the neural network, we used a four-layer architecture (input layer, two hidden layers, output layer).27
Selection procedure for machine learning algorithmsModel performances were measured with the area under the receiver operator characteristics curve (AUC). We also report precision, recall and F1-score with a fixed classification threshold of 0.5. The F1-score was calculated using the ‘weighted’ option, which calculates metrics for each label and finds their average weighted by support. For each given value, a 95% CI of the outcome measure was estimated by bootstrapping 100 times the subjects in the set. We also examined the precision-recall curve (PRC) with precision (y-axis) and recall (x-axis) plotted for different probability thresholds. All the experiments with machine learning algorithms were conducted in Python with functions from the scikit learn library for classification (V.0.20.3).28 The MLP was implemented using the Keras framework (V.2.2.4).
Tuning, resampling and ensemble methods for classificationFor LR and RF, tuning of the hyperparameters was made using grid search with 10-fold cross-validation on the validation set (full details available by request to the author). The GNB classifier had no parameters to tune. Tuning of SVM was done empirically (online supplemental table S4). To compensate for class imbalance of ADHD outcomes, we compared two different methods: random subsampling and Tomek links.29 For random subsampling, we successively fitted our model to multiple subsamples. Each sample contained all ADHD cases and 1000 subjects without any ADHD diagnosis. We calculated the AUC for each fitted model and took the average value of AUC. For Tomek links, we used two approaches—removing all links from the dataset and removing the majority class samples that were part of a Tomek link. In an attempt to improve classification performance, ensemble methods were used on selected machine learning methods.
Selection and testing the final modelsTwo criteria were defined for the final models’ selection: performance and transparency, that is, the models’ ability to determine feature contribution, which enabled examination of potential biases inherent to the data resources used. High-performing models were considered a priori as having AUC ≥0.85 on the validation set.
Models which were both transparent and performed well were tested for diagnostic efficiency, the purpose being to assess whether the predictive performance from the population sample could generalise to clinical populations. To test the specificity of the best models for ADHD from other clinical mental health problems, we repeated our approach on a purely clinical cohort containing only the children who were present in the CRIS dataset, thus containing samples of children who presented with ADHD and non-ADHD diagnoses. Once all models were tested on the full set of features, we then refined the models to improve accuracy, reduce overfitting and increase potential for translation into busy clinical settings—making the model less vulnerable to missing information. To identify the most important features for LR models, we used beta coefficients, while RF feature importance represents the decrease in node impurity on a given branch within a decision tree, weighted by the probability of reaching that node.
Bias reductionWe investigated bias reduction for the LR and RF models trained on the population cohort using the AI Fairness 360 toolkit.30 We used a pre-processing algorithm as we could access and modify the data directly and the data were inherently biased due to unfair clinical case ascertainment. Pre-processing algorithms learn a new representation based on protected attributes, that is, features that partition the dataset into groups that should have equal probability of getting a favourable label.31 In our case, protected attributes were represented by ethnicity and language status, while the favourable label is an ADHD diagnosis. The reweighting algorithm was chosen for its ability to treat two protected attributes at the same time and for the transparency of its fairness process.32 This algorithm modified the dataset by generating different weights for the training examples in each (group, label) combination, to ensure fairness before classification.
Online supplemental figure S1 displays the pre-processing fairness pipeline. We defined white and English speaking as the ‘privileged’ group, and non-white and non-English speaking as the ‘unprivileged’ group, thus obtaining two non-overlapping groups to be weighted differently. Other combinations (non-white and English speaking, white and non-English speaking) were not explicitly reweighted.
ResultsCohort characteristicsIn total, n=652 pupils in our sample were diagnosed with ADHD (1.16% of the population cohort; 15.6% of the clinical cohort) (table 1). In the population cohort, gender was evenly balanced, and pupils were predominantly black (n=22 904, 40.71%) and spoke English as a first language (n=37 432, 66.54%). However, males were over-represented in the clinical cohort (n=2848, 68.17%), as were white ethnic groups (n=1712, 40.98%) and English first language speakers (n=3390, 81.14%). This is consistent with national surveys which report greater psychiatric morbidity among boys aged 5–10 years, and higher rates of help-seeking and detection among white, English-speaking groups.33 34 Compared with the population cohort, the clinical cohort also had a lower EYFSP and KS1 attainment, lower attendance, and higher rates of exclusion, eFSM, LAC and SEN.
Table 1Characteristics of the population cohort and clinical cohort
Model performance: identifying ADHD from population cohortOnce all models were tested on the full set of 68 features, we refined the models to improve accuracy, reduce overfitting and increase potential for translation into busy clinical settings. Table 2 displays AUC, precision, recall and F1-score, including confidence parameters for all tuned models on both validation and test sets, for classifying ADHD from the population cohort (figure 1 for receiver operator characteristics (ROC) analysis). Hyperparameter tuning improved RF significantly. Precision was high (above 0.985 on both the validation and test set) for LR, RF and GNB. LR, RF and the MLP all had an AUC ≥0.85 on both the validation and the test set. SVM did not discriminate ADHD diagnosis as well (AUC <0.82). Overall, LR and RF were the highest performing and transparent models.
Table 2Comparison of models: (1) predictive performance of all trained models on the population cohort; (2) performance of LR and RF in identifying ADHD from other child-onset psychiatric disorders within the clinical cohort (median and 95% CI)
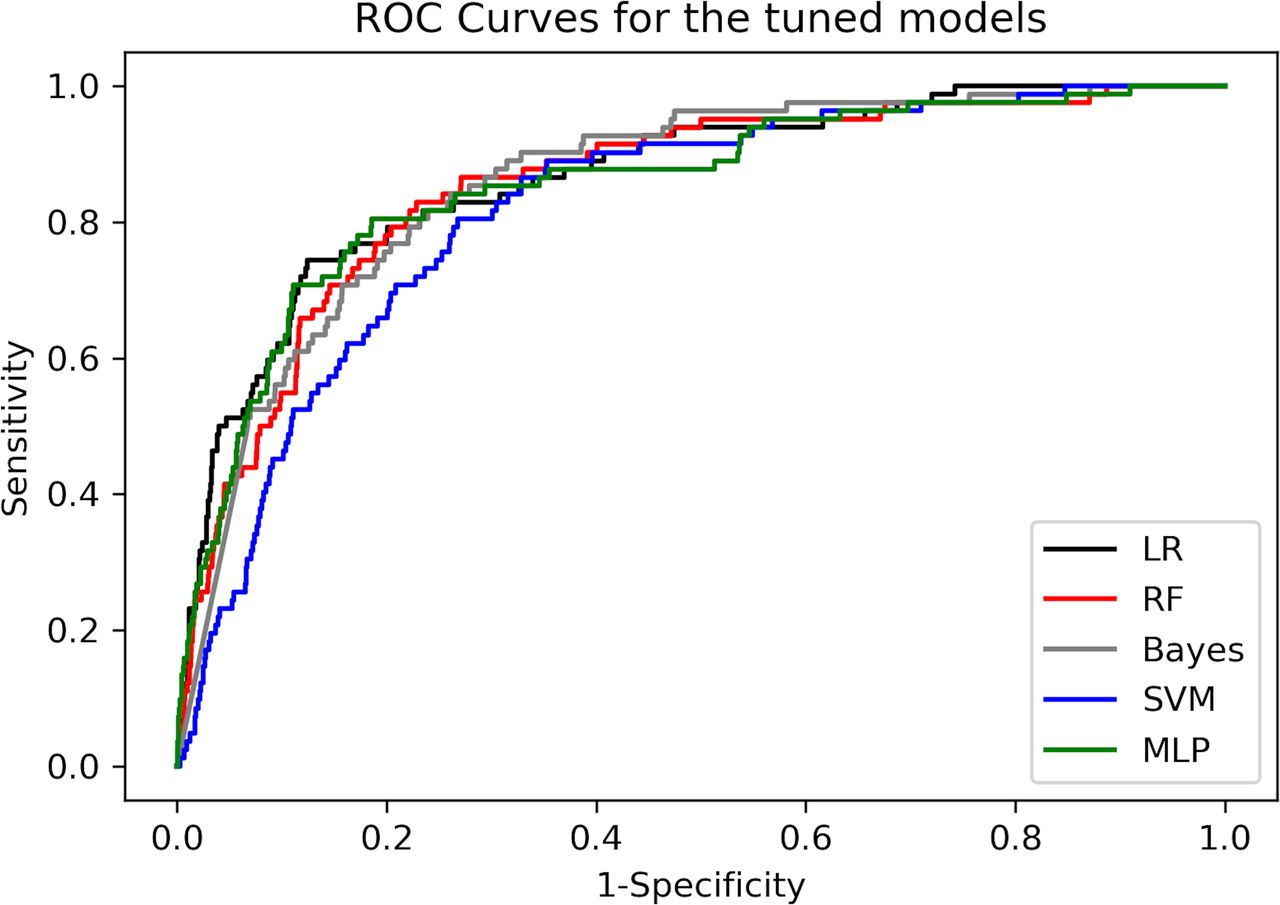 Figure 1
Figure 1 ROC curves for the tuned models. LR, logistic regression; MLP, multilayer perceptron; RF, random forest; ROC, receiver operator characteristics; SVM, support vector machines.
Model performance: identifying ADHD from clinical cohortTable 2 displays precision, recall, F1-score and final hyperparameters trained, validated and tested on the clinical cohort. Precision was ~0.80 for ADHD on both the validation and test set for both models on the clinical cohort. Both models’ overall predictive performance (AUC 0.70) was much lower relative to their performance on the population cohort.
Resampling methods used to deal with class imbalance did not improve the performances significantly. Overall, random subsampling performed better than Tomek links. As for ensemble approaches, a slight improvement in performance was noticed for RF only, while LR obtained better performance when using resampling methods. The PRCs for both population and clinical cohorts are displayed in online supplemental figures S2 and S3. The models show significantly lower performance than ROC curve results, although they do demonstrate greater performance than a random classifier, based on PRC metrics as summarised in online supplemental table S5 comparing the PRC and ROC for LR, RF and random classification.
Bias reduction using English language and white ethnicity as protective attributesTable 3 displays results on the population cohort (test set) when using the LR and RF models trained on transformed data (ie, with instance weights from the fairness reweighting algorithm). The disparate impact score displays the ratio of the probability of a favourable outcome for unprivileged instances and the probability of a favourable outcome for privileged instances (close to 1 in a fair dataset). The reweighting algorithm obtained a considerable improvement of the disparate impact (from 0.15-0.60 to 1), without harming the models’ performance on ADHD classification: for the LR/RF models, the AUC remained above 0.880/0.858 in all cases.
Table 3Model performance on the reweighted fair dataset resulting from the bias reduction algorithm
Feature contribution for ADHD prediction in population and clinical cohortsTable 4 displays the most important features overall, plus ethnicity, for LR and RF models in the population and clinical cohorts (all features in online supplemental table S6). KS1 writing performance was a strongly protective/discriminant factor against ADHD. Gender, KS1 attendance, SEN status, and personal, social and emotional development were also strongly discriminant features, while the importance of English language and ethnicity was reduced following reweighting.
Table 4Feature contribution for ADHD prediction and the impact of fairness reweighting
DiscussionThis study aimed to predict pupils with a high likelihood of ADHD diagnosis using data available at the population level. To our knowledge, it is the first study to apply machine learning approaches to large-scale, routinely collected linked health and education data. These innovative methods show that ADHD in general population and clinical cohorts can be predicted with high levels of accuracy. Promisingly, this level of predictive accuracy is comparable with traditional survey-based screening methods in ADHD, and with other studies using routinely collected data to predict health outcomes.35–38
These findings suggest that machine learning approaches can accurately predict ADHD in large general population and clinical cohorts using existing and widely available administrative data. These models may therefore be suited to provide health intelligence to local policymakers at low cost, and inform decisions on the allocation of disorder-specific resources at an area, school or service level. Tentatively, these models may also offer a means to predict ADHD at the individual level, although greater precision would be desirable for this purpose—this is an area for future work.
We also demonstrate that sociodemographic biases inherent in the data and algorithms can be reduced with a fairness reweighting step to ensure that pupils from certain backgrounds are not systematically overlooked as being at risk of ADHD. In a geographical area with a large proportion of people from ethnic minority and non-English-speaking backgrounds, minimising such biases is crucial for accurately predicting need for ADHD provision in the population.24
This therefore highlights the need to build fairness measures which weight for limited access to diagnosis in certain ethnic and social groups. However, it is important to note that these statistical approaches are unlikely to remove all potential biases inherent to service provision data: for example, parents also influence help-seeking for ADHD, but their characteristics are not fully captured in datasets like the NPD, and so could not be used in reweighting processes.39 Subset scanning could be a means to detect biases in certain subgroups.32 It should also be noted that the reweighting algorithm we used was based on the assumption that different ethnic and language groups should have equal probability of a favourable label (ie, ADHD): under these parameters, optimised pre-processing could also have been applied, as it ensures both group fairness and individual fairness, where similar individuals are treated similarly.40 Further work could explore these methods.
Strengths and limitationsOur study benefited from a large and novel data linkage capturing almost all pupils from a defined geographical catchment. This reduces the risk of building models on biased and non-representative samples. These approaches are also scalable, as they use information already routinely collected by schools. We used a set of machine learning algorithms that are state-of-the-art techniques and are representative of the wide spectrum of machine learning methods: an ensemble method (RF), a kernel-based method (SVM), a Bayesian method (Naive Bayes) and a neural network (MLP).
However, some limitations should be highlighted. While we sought to address biases in clinical data using reweighting algorithms, biases in the education data (such as inconsistent representation of private or home-schooled pupils) have not been addressed. We also handled missing data using a complete case analysis, which can introduce bias if the missing data are not randomly distributed. An alternative would have been to explore imputation methods; however, given that we compare models of varying complexities (from LR to MLPs), we would have had to adapt the imputation method to the model, resulting in varied datasets. The comparison between the resulting models would therefore have been unfair. Encouragingly, the proportion of missing data was very low, and therefore unlikely to materially bias the findings. Nonetheless, further validation of these models is warranted.41
We have assumed that diagnostic and treatment discrepancies between different ethnicities and language groups are due to disparity. It could be argued that such discrepancies are in fact reflective of genuine underlying differences in ADHD prevalence in these populations. However, existing evidence suggests that ADHD is underdiagnosed and undertreated in certain ethnic groups; plausible mechanisms along the care-seeking pathway which may result in these disparities have been discussed elsewhere.15 16
For reweighting, we dichotomised ethnicity as white/non-white, and language as English/non-English—conducting a more granular reweighting procedure using more precise groupings would be an important area for future research. We also did not conduct reweighting on the basis of any other sociodemographic characteristics such as gender or deprivation, and make no assumptions as to their role in differential diagnoses—again, these could be areas for future work.
To identify ADHD cases, we used diagnostic codes recorded in structured fields. Evidence suggests that ADHD can be classified from diagnostic codes in electronic health records with a high degree of accuracy; however, such methods of ascertainment are imperfect, and the possibility of diagnostic or administrative misclassification does remain.42 43
Replication in other regions or populations would also be important to assess the generalisability of these models, although at present, other educational and clinical data linkages on this scale are scarce. Finally, some of the features used in the analysis had very few observations for the ADHD cases. The potential impact of this is understudied and warrants further investigation.44 45
ConclusionsOverall, this study demonstrates that machine learning approaches using readily available education and clinical data show promise in predicting ADHD in source populations. It also highlights that biases inherent in routinely collected data can be mitigated using fair weighting processes. With further validation and replication work, these methods have the potential to estimate burden of need for ADHD provision, thereby informing resource allocation and policy decisions.
留言 (0)