
記住我



A Brain-Computer Interface (BCI) is a system that allows interactions between a human and a machine using only neurophysiological signals coming from the brain. It aims at rehabilitating, improving, or enhancing the ability of the user by means of a computerized system (Wolpaw et al., 2002). The most common modality used to record neurophysiological signals is electroencephalography (EEG). This is mainly because EEG is affordable, completely safe for the user and because it features a high temporal resolution. EEG signals can be translated into a command to be sent to a computer by means of a decoding algorithm. The loop is often closed by means of a feedback given to the user.
Several BCI applications have emerged to help patients, such as spellers (Yin et al., 2015; Rezeika et al., 2018) or wheelchair controllers (Li et al., 2013). The focus in this line of research is to restore lost communication or movement capabilities. Other applications are designed for the rehabilitation of patients after an incapacitating event such as a stroke (Frisoli et al., 2012; Mane et al., 2020). Non-clinical applications have also been proposed, for example to provide a means of control in video games (Congedo et al., 2011; Bonnet et al., 2013). Mixed approaches are also possible, for example in the Cybathlon BCI Race, where people with complete or severe loss of motor function compete in a video game-based competition (Perdikis et al., 2018).
Several paradigms can be used in order to control a BCI. The most commons are event related potentials (ERP), motor imagery (MI), and steady state visually evoked potentials (SSVEP). The ERP paradigm consists of electrical potentials evoked by sensory stimulations; in MI the user imagines to move body parts, resulting in synchronizations and desynchronizations in the sensory-motor cortex; in SSVEP-based BCIs, the user concentrates on visual stimuli flashed at distinct frequencies, leading to responses at the same frequency in the brain. Regardless of the paradigm, it is necessary to calibrate the BCI system in order to allow proper decoding. The calibration process is time consuming, annoying for the healthy user and problematic for the clinical population, which has limited mental resources (Mayaud et al., 2016). In fact, a calibration is required not only for every new user, but also for every new session of the same user. This is due to the high inter-subject and inter-session variability of the features extracted from the EEG. Such variability is caused by several factors, including, but not limited to, the impedance and placement of EEG electrodes, individual morphological and physiological characteristics of the brain and changing brain states.
One way do deal with this variability is to use transfer learning (TL). This means trying to reuse some of the information we have already gathered on known data that may be coming from either previous subjects or previous sessions. In transfer learning we usually consider two types of data. The source represents the data we already know on a given subject whereas the target consists of a new subject whose some training data may be available, but mostly is unlabeled and is to be used as a test. The aim is to adapt as accurately as possible the data of the target using the few available training data to the source data (or vice versa). In order to do so, several methods have already been developed.
The authors in Jayaram et al. (2016) adapt the weights given to spatial features that are meant to predict the stimulus in order to transfer information from one subject to another or from one session to another. Some other methods adapt the parameters of a neural network. For example the authors in Fahimi et al. (2019) perform a partial retraining of a deep neural network on a small number of samples of a new user, improving significantly the accuracy. Unsupervised domain adaptation methods have also emerged, as in Sun et al. (2015), where the authors perform unsupervised transfer learning in the Euclidean domain, using covariance matrices to align data from different subjects. A well-established approach for classification in the BCI field is to use covariance matrices of the signal since those matrices have many relevant properties (Congedo et al., 2017). The covariance matrices are Symmetric Positive Definite (SPD) and therefore lie in a Riemannian manifold. In this way, some algorithms have been developed to achieve transfer learning in the Riemannian manifold of SPD matrices. For instance, the authors in Zanini et al. (2018) propose a recentering procedure consisting in translating the center of mass of both the source and target data to the identity using parallel transport. This procedure is actually equivalent to a whitening using the Riemannian mean as anchor point. In Yair et al. (2019), both the center of mass of the source and target data are translated to their midpoint along the geodesic, allowing equivalent results. The authors of Rodrigues et al. (2019), inspired by the Procrustes analysis, proposed to add two more steps after recentering: a stretching of the observations, so as to equalize the dispersion of the data in the source and target domain and a rotation, so as to align as much as possible the center of mass of each class between the source and the target data set. The method, named Riemannian Procrustes Analysis (RPA), was shown to allow efficient transfer learning. A later alignment method was discussed in He and Wu (2020). This method is similar to Sun et al. (2015) with improvement related to enhanced dimensions in the Euclidean space. The authors of Zhang et al. (2020) chose another approach by transferring instances of the source close enough to the target in order to enhance the low data availability of the target model. They used MI data and compared the proximity of source and target trials using Hamming distance after preprocessing steps. Another idea proposed in Zhang and Wu (2020) is to find a common subspace between source and target, yielding a projection matrix to reduce the gap between the source and the target. Finally the authors train on the source subspace to test on target subspace.
In this article we introduce a Riemannian transfer learning approach similar in spirit to the RPA approach (Rodrigues et al., 2019), but operating in the tangent space. Our contribution has multiple benefits as compared to previous attempts. First, it lies in a state-of-the-art BCI feature space, the Riemannian tangent space, introduced in the BCI domain by Barachant et al. (2010). Since the tangent space is an Euclidean space, there exists a wide variety of well-established tools to decode the data therein and in general they are faster as compared to a decoding approach in the Riemannian manifold. Second, since it acts on an Euclidean space, it can be used for all kind of feature vectors, not just those obtained in a Riemannian setting. Third, our method is computationally effective, as it only requires one singular value decomposition (SVD). Fourth, it extends naturally to the heterogeneous transfer learning case, i.e., when the number and/or placements of electrodes is not the same in the source and target data set. In a similar previous attempt the SVD has been applied independently on the source and target dataset and the resulting matrices are then used to align the data (Sun et al., 2015). Our method is instead casted as a Procrustes problem and therefore it fulfills a well-known optimality condition for inter-domain alignment.
A previous version of our method has been presented in Bleuze et al. (2021). As compared to that presentation, we have improved it by adding several ways to deal with the rank deficiency of the cross product matrix. Also, here we test it on a very large amount of data, namely, 18 BCI databases comprising a total of 349 subjects. Furthermore, these databases pertain to three BCI modalities: event related potentials (ERP), motor imagery (MI), and steady state visually evoked potentials (SSVEP). Therefore, the present study is a comprehensive test bed, which is a well-grounded way to reach general conclusions when comparing machine learning pipelines.
2. Materials and methods 2.1. NotationsThroughout this article we will denote matrices with upper case bold characters (A), vectors with lower case bold characters (a), indices and scalars by lower case italic characters (a), and constants by upper case italics (A). The function tr(.) will indicate the trace of a matrix, (.)T its transpose, ||.|| the 2-norm or the Frobenius norm, ∘ the Hadamard product, log(.), and exp(.) the matrix logarithm and exponential, respectively. IN will denote the identity matrix in dimension N.
2.2. Riemannian geometryLet us consider a set of trials n∈[1, N] with shape (Nc, Nsample), where Nc is the number of channels, Nsample the number of (temporal) samples and N the number of matrices in the set. A generic trial is simply denoted as X. In order to be as close as possible to a realistic scenario, we consider data with a low level of pre-processing and we do not use any artifact removal method, such as ocular artifacts or outliers removal (Çınar and Acır, 2017; Minguillon et al., 2017).
The (spatial) sample covariance matrix estimation (SCM) writes
C=1Nsample-1XXT. (1)The SCM has shape (Nc, Nc). It lies in a Riemannian manifold of symmetric positive definite (SPD) matrices (Bhatia, 2009). It is therefore possible to classify directly a set of covariance matrices by means of classification algorithms acting on such a manifold, such as the Minimum Distance to Riemannian Mean (MDRM) classifier (Barachant et al., 2012) or its refinement Riemannian Minimum Distance to Means Field (RMDMF; Congedo et al., 2019). It is also possible to project the matrices onto the tangent space of the manifold at a base point M and use Euclidean classifiers therein (Barachant et al., 2012, 2013). The base point M in this work will always be chosen as the Log-Euclidean mean, which is defined as Fillard et al. (2005).
M=exp(1N∑nlog(Cn)). (2)The projection onto the tangent space at base point M is obtained by the logarithmic map operator (Nielsen and Bhatia, 2013).
LogM(C)=M12log(M-12CM-12)M12. (3)The projected matrix is now a (Nc, Nc) symmetric matrix. Since we are concerned with transfer learning (TL), we are interested in matching the position of the source and target data sets in the manifold as much as possible. Following Zanini et al. (2018), we recenter both the source and target data sets by setting their global mean at the identity. This is simply obtained by transforming all trials of a dataset such as
Crec=M−12CM−12, (4)where M is the center of mass of the observations and Crec denotes the recentered trial. After recentering all trials their center of mass becomes the identity matrix, corresponding to the “zero” point in an Euclidean space.
The logarithmic mapping at the identity simplifies, yielding
LogINc(Crec)=INc1/2log(INc−1/2M−12CM−12INc−1/2)INc1/2 =log(M−12CM−12).The above recentering followed by tangent space projection was first proposed in the BCI field in Barachant et al. (2012, 2013) and is nowadays a standard processing procedure, which in this article is carried out systematically, unless explicitly mentioned.
Once projected onto the tangent space the matrices are vectorized. Since they are symmetric, only the upper (or lower) triangle of the matrix is kept and the off-diagonal terms are weighted by 2 so as to preserve the norm of the original matrix. In mathematical notation, the vectorization of tangent vector S reads
s=triu(S ∘ A), (5)with triu(.) the operator vectorizing the upper triangle and A a matrix with the same shape as S, filled with 1 on the diagonal and 2 on the off-diagonal part. Since the matrices have been previously recentered, the resulting vectors are also recentered, that is, the mean tangent vector is the zero vector.
Having obtained the tangent vectors as described here above, it is possible to use all the well know classification algorithms that act in an Euclidean space, the most commonly employed in the BCI community being the linear discriminant analysis (LDA; Barachant et al., 2012), support vector classifier (SVC; Xu et al., 2021) and Lasso logistic regression (LR) (Tomioka et al., 2006). In this study, we use the SVC.
2.3. AlignmentAs anticipated in the introduction, the method here proposed has been inspired by previous Riemannian TL methods, such as in Zanini et al. (2018) and Rodrigues et al. (2019) which focus on covariance matrices in the Riemannian space of SPD matrices. In Rodrigues et al. (2019) the authors consider again the recentering and add two further alignment steps:
1. a rescaling so as to match the dispersion around the mean (center of mass) in both the source and target data sets and
2. a rotation so as to align the mean of each class as much as possible. This effectively results in a Riemannian Procrustes alignment.
In this article, the same steps are undertaken in the tangent space. In particular, we rotate the tangent vectors using an Euclidean Procrustes procedure.
Let us consider the set of centered tangent vectors for the source n∈[1, Ns] and the target n∈[1, Nt] domain. Ns and Nt are the number of vectors for, respectively, the source and the target data set. As we will see, in the following it will not be required that the source and target tangent vectors have the same dimensions. Denoting s and t the generic source and target tangent vectors, the rescaling is obtained setting the average norm within each set to 1, which is readily obtained by transformations
s~=s1Ns∑n||sn|| (6)and
t~=t1Nt∑n||tn||, (7)yielding rescaled source and target data sets n∈[1,Ns] and n∈[1,Nt]. It is also possible to set the norm of the target data set equal to the norm of the source data set if it is sought not to modify the norm of the source data set.
For the rotation (alignment), we propose a supervised method that uses the mean point of the classes. Let us consider K classes that we ought to align. Although other procedures are possible, in the following we always align the target set to the source set. Let y and z be the label vectors of, respectively, n∈[1,Ns] and n∈[1,Nt] with shape Ns and Nt. We start by computing the mean for each class k, given its Nk trials
s¯k=1Nk∑yi=ks~i (8)for the source set and
t¯k=1Nk∑zi=kt~i (9)for the target set. In the supervised procedure these vectors are the anchor points we use for alignment. Therefore, we define
S¯=[s¯k,k∈[1,K]] (10)and
T¯=[t¯k,k∈[1,K]] (11)as the two matrices of shape (Nc(Nc+1)2,K) holding the anchor vectors stacked one next to the other. We can now define the cross-product matrix
of shape (Nc(Nc+1)2,Nc(Nc+1)2). Like any rectangular matrix—or squared when source and target have the same number of channels—Cst can be decomposed by singular value decomposition, such that
with U and V the two orthonormal matrices holding in columns the left and right singular vectors, respectively, and D a diagonal matrix holding the singular values. As usual in signal processing, we will retain a subset of the singular vectors in order to suppress noise. Such a truncation has also the advantage to work for the case where U and V do not have the same shape. As a general rule, we seek the smallest number Nv of singular vectors which corresponding singular values explain at least 99.9% of the variance, resulting in U~ and V~ with shape (Nc(Nc+1)2,Nv). Finally, we are able to align the target vectors previously created n∈[1,N] to the domain of the source vectors n∈[1,N] as
where t^ denotes the aligned target vectors. The newly created set n∈[1,N] is now aligned to the space of source vectors n∈[1,N], therefore it can be classified with algorithms trained on the source domain. As it is well-known, when the cross-product in Equation (12) is full-rank, the unique solution to the Procrustes optimization problem
arg minZ(||ZT¯-S¯||) (15)is indeed Z = UVT. In our case, the solution is not unique. Note that a connection between this problem and the Bures-Wasserstein metric has been recently described in Bhatia et al. (2019).
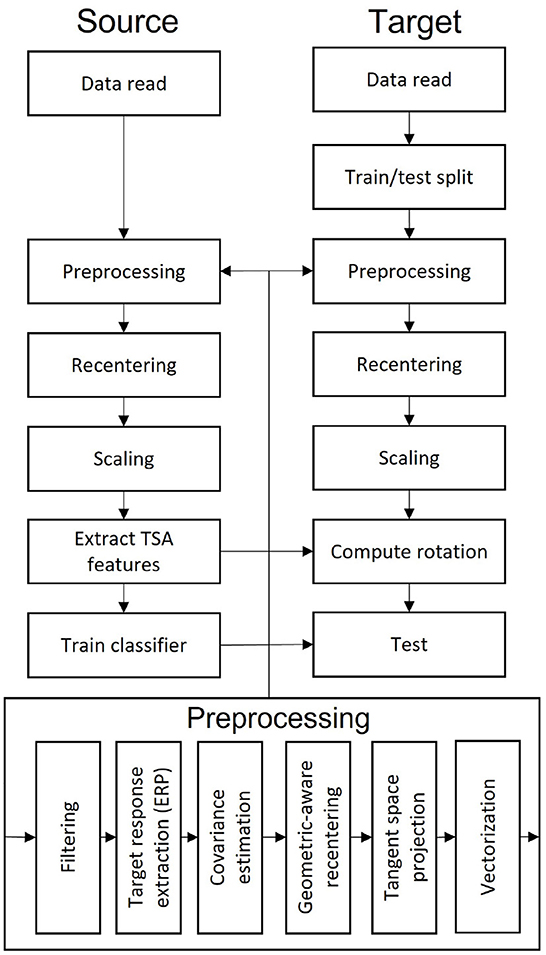
The whole process for our method is summarized in Figure 1.
Figure 1. Flowchart summarizing the analysis pipeline.
2.4. Augmenting/improving CstCross-product matrix Cst is usually rank deficient and its estimation could be improved in several ways. In this section, we will suggest two such improvements. First, as long as a supervised TL is possible, since we are relying on averaging the tangent vectors, it is possible to employ robust average estimators. For instance, we may consider the trimmed means, the median or power means to estimate suitable anchor points. We may also stack several of these average estimators to obtain larger matrices s¯k and t¯k, which may provide more robust information on the actual central tendency of the data.
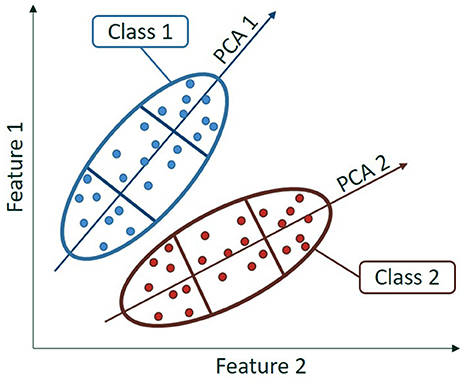
Second, we cluster the data sets in several subsets describing the shape of the data set when considered altogether and compute separate means for each cluster. We may use, for instance, principal component analysis (PCA) on each class independently to create clusters, as depicted in Figure 2. The centroid of those clusters are then computed and used as anchor points. In order to obtain the clustering for both the source and target data set, we consider for each class a PCA trained on the source and used as such on both the source and target data set.
Figure 2. Schematic of a two-class dataset using the first dimension of a PCA for each class.
Using such a clustering procedure, if the source and the target data set display a rather similar shape, their alignment will be very effective, leading to promising transfer learning results. Such a procedure is also possible with unlabeled data in case of unsupervised TL. However, in this case, we have noticed that at least two PCA components are necessary to obtain an efficient transfer learning. Therefore, in the unsupervised case we recommend using at least two PCA components and separate data for each dimensions, creating a Cst matrix with shape [Nc(Nc+1)2,Nd×Ng] with Nd the number of dimensions used and Ng the number of groups created in each dimensions. An effective strategy is to visualize the data and their representations in order to verify whether the chosen reduced dimensionality offers a good approximation of the data as it may be as well totally inaccurate, depending on the data, especially for unsupervised TL. For our results, we chose to create three PCA clusters for each class and use these means to compute the cross-product matrix Cst as it gives enough information without reducing the size of the data used for each mean too much.
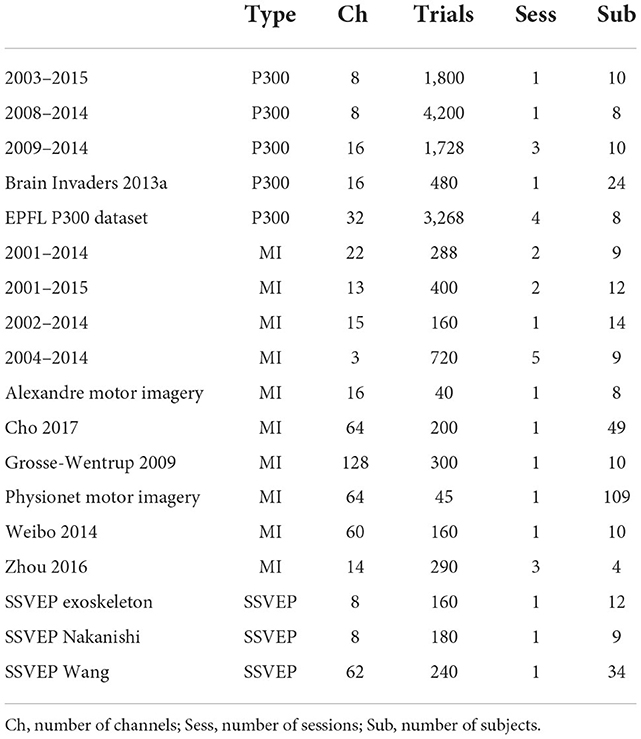
3. ResultsThe TSA algorithm previously introduced has been tested on three well know BCI paradigms: ERP, MI, and SSVEP. We have analyzed 18 open-access BCI databases available on the Mother Of All BCI Benchmark (MOABB; Jayaram and Barachant, 2018). Python library, of which five uses the ERP paradigm, 10 the MI paradigm, and 3 the SSVEP paradigm. The 18 databases include a total of 349 subjects with very high variability between and within datasets. We summarize the data in Table 1, following Congedo et al. (2019).
Table 1. List of the processed databases for event-related potentials, motor imagery paradigms, and steady-state visual evoked potentials.
We execute transfer learning from one subject to the other for all possible source/target pair of subjects within each database. The accuracy is evaluated using balanced accuracy since the number of trials per class is often unbalanced (always for the ERP paradigm).
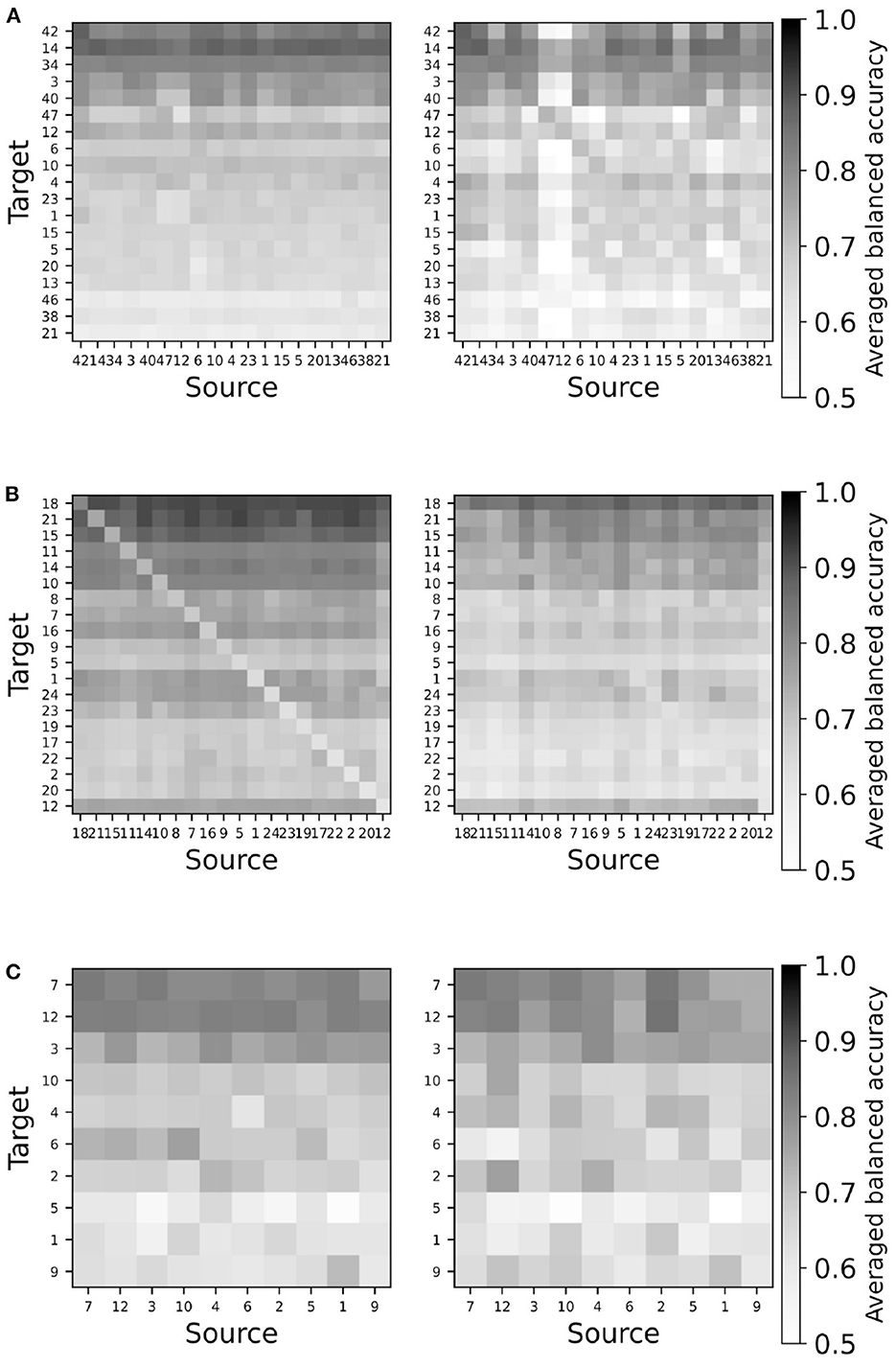
Since the amount of data of all pair-wise comparisons is huge, we start by visually evaluating all balanced accuracies obtained for a given database by means of seriation plots, i.e., plots showing the accuracy for each pair of target and source subject arranged in matrix form. The accuracy is averaged over all numbers of alignment trials for each pair. The case where the target and the source are the same, i.e., on the diagonal, is replaced by the classical train-test cross-validation accuracy, offering a straightforward benchmark. Furthermore, the target and source subjects are sorted on rows by descending order of the train-test cross-validation accuracy. It should be kept in mind that since the train-test procedure is fully supervised and optimized for the train data, it is expected to outperform a transfer learning method. Figure 3 shows a representative seriation plot for each paradigm allowing the visual comparison of the performance of the TSA vs. the RPA transfer learning method; all figures are available as Supplementary material.
Figure 3. Representative seriation plots for TSA (left) and RPA (right) methods for each paradigms. See text for details. (A) Database Cho2017 (MI). (B) Database brain invaders 2013a (ERP). (C) Database SSVEP exoskeleton (SSVEP).
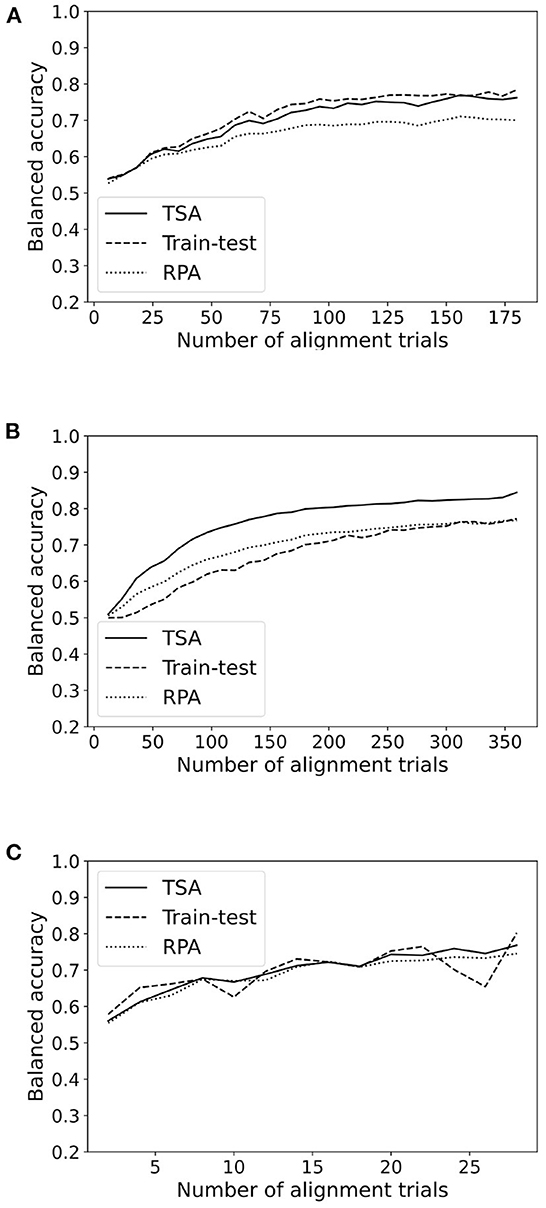
In order to evaluate the average performance, we plot the balanced accuracy averaged across all subjects in a database for each method as a function of the number of alignment trials. Since we are averaging across subjects, for this analysis we include only those subjects featuring at least 60% accuracy in a classical train-test cross-validation. This restriction excludes about half of the subjects, leaving 178 subject out of 349. It's important to note that subjects with an overall 60% accuracy usually have more than 70% accuracy with all available training trials. Figure 4 shows a representative plot for each paradigm. All figures are available as Supplementary material.
Figure 4. Accuracy as a function of the number of alignment trials for TSA and RPA methods for a representative database in each paradigm (MI, ERP, SSVEP). (A) Database Cho2017 (MI). (B) Database brain invaders 2013a (ERP). (C) Database SSVEP exoskeleton (SSVEP).
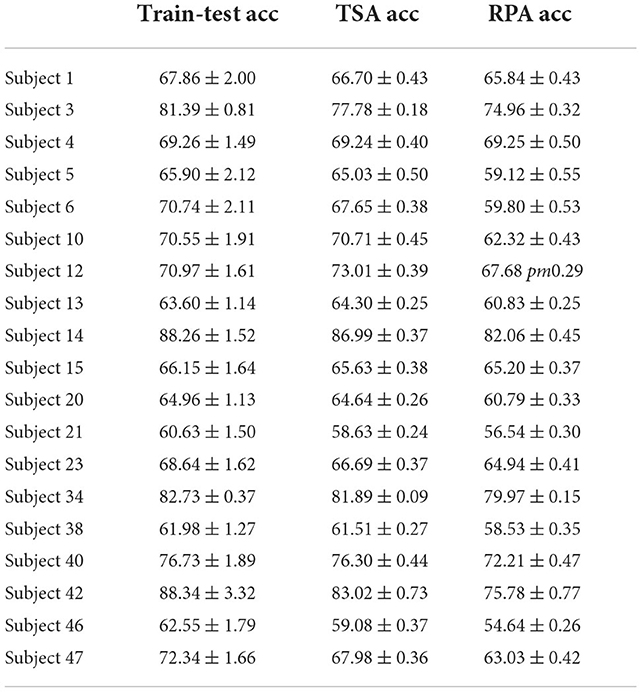
Then, we summarize all the pair-wise accuracy information in the accuracy tables such as Table 2. These tables give for each target subject the accuracy averaged over numbers of alignment trials and source subjects. For this database, there are 30 numbers of alignment trials considered and 18 possible source subjects, which makes an average over 540 values. This makes the standard error low in general. Accuracy tables for all databases are given as Supplementary material.
Table 2. Balanced accuracy ± standard error for the good subjects of database Cho 2017 averaged over number of alignment trials and source for train-test, TSA, and RPA.
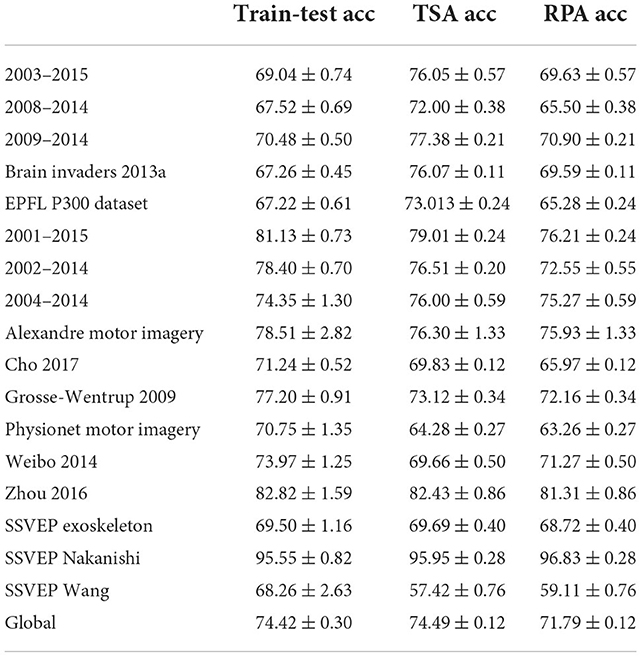
The accuracy tables confirm what can be evaluated visually in the average accuracy plots and seriation plots; on the average there is about 1% difference between classical train-test cross-validation accuracy and TSA and about 5% between classical train-test cross-validation and RPA. This speaks in favor of a clear improvement of the TSA method over the RPA method. Table 3 summarizes all the balanced accuracy for each dataset. On the average across databases there is no loss of accuracy using a TSA as compared to the optimal train-test accuracy. This is not true for the RPA.
Table 3. Balanced accuracy ± standard error for the good subjects of each dataset averaged over number of alignment trials, target and source for train-test, TSA, and RPA.
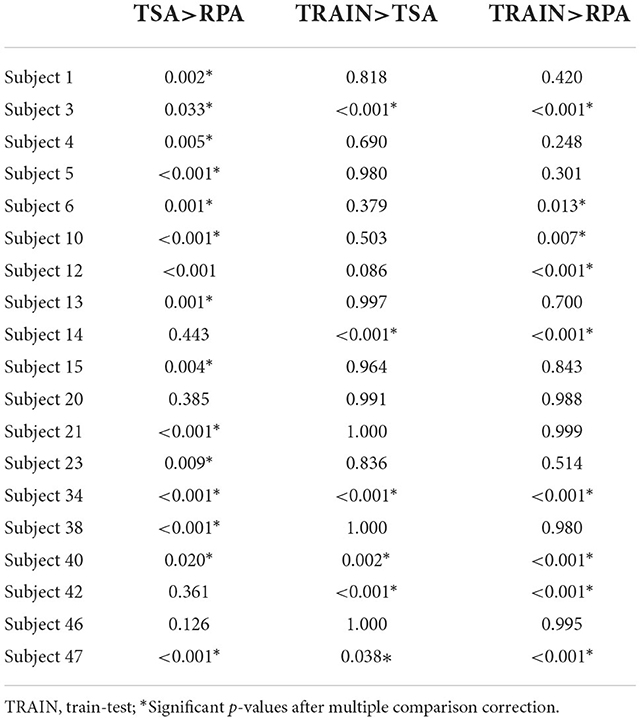
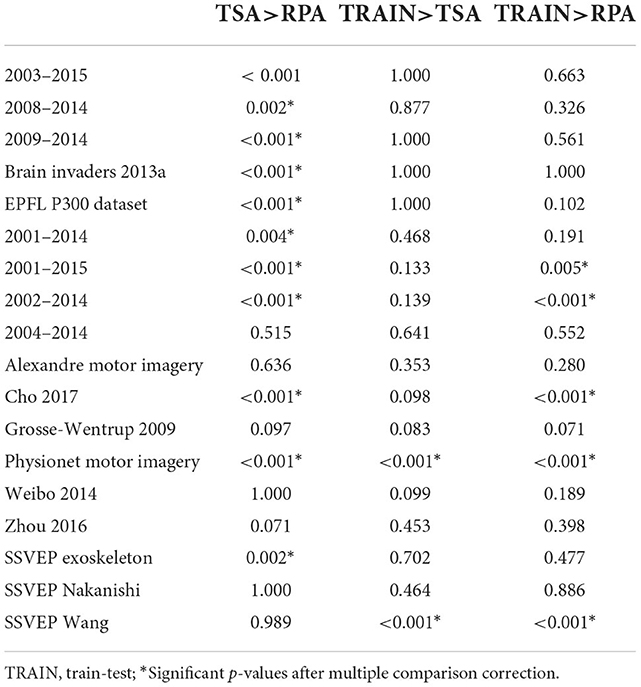
Finally, we performed statistical tests on all pair-wise source/target accuracy results we have collected. To this end, we follow the procedure introduced in Rodrigues et al. (2021). In a nutshell: we first compute signed paired t-test for every target subject comparing the accuracy between methods, yielding T statistics Tm, i and p-values pm, i for each pair of methods m and target subject i. In order to correct for the multiplicity of statistical tests we use Holm's sequential rejection multiple test procedure (Holm, 1979) for each target subject. This produces tables such as Table 4. Corresponding tables for each database are available as Supplementary material. Then, we combine the p-values we obtain using the Stouffer's Z-score method (Zaykin, 2011) for each database, yielding multiple p-values corresponding to each pair of methods for each database. Those p-values are also corrected by means of Holm's procedure and are summarized in Table 5. In this table we can see that among the 18 databases we have analyzed, 11 show a significant improvement of TSA as compared to RPA. No significant difference between the classical train-test cross-validation accuracy and TSA is found with the exception of two databases, for which TSA proves inferior. This number grows to five databases comparing the classical train-test cross-validation accuracy and the accuracy obtained by RPA. Finally, using Stouffer's Z-score method, p-values corresponding to each paradigm are computed and corrected with Holm's procedure (Table 6).
Table 4. Subject-wise p-values for MI database Cho 2017.
Table 5. Database-wise p-values.
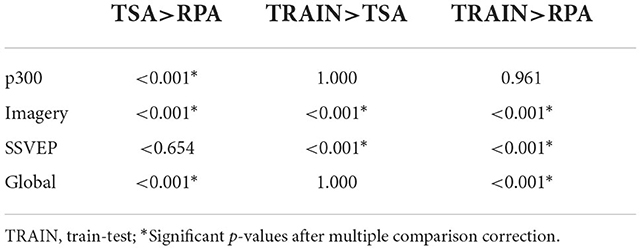
Table 6. p-values for each paradigm and in global for all tests that have been done. The global p-values are the combination of the p-values for all databases regardless of their paradigm.
So far we have focused on cross-subject transfer learning, however the method we propose can also be used to transfer different information, such as from one session to another with the same subject or from one task to the another. In order to ensure the ability of our method to reduce the inter-session variability, we used the dataset having multiple sessions and processed results for inter-session cross-validation. In order to do so, we used the data of one session as a source, then for each other sessions with 80% test and 20% training data split we trained the transfer learning model and tested the results. The processed is then repeated using each session as the source. We compared four different methods:
• Tangent Space Alignment (TSA), our method,
• Riemannian Procrustes Analysis (RPA) used as a comparison in this article,
• Usual train-test method using only target data,
• Direct testing (DCT) using algorithms trained on the source without aligning target data by a rotation (recentering only).
The results are given in Figure 5 and presented numerically in Table 7.
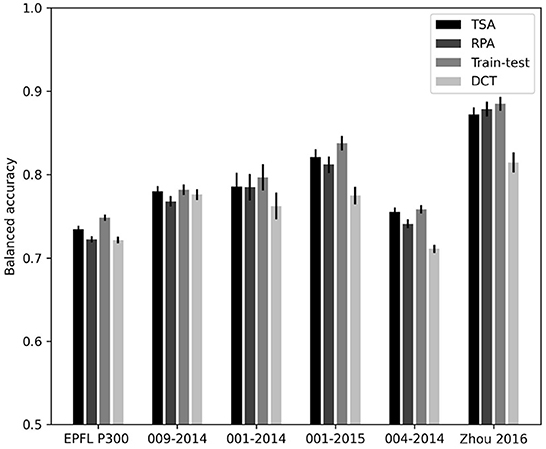
Figure 5. Bar graph giving the inter-session balanced accuracy for the databases possessing multiple sessions.
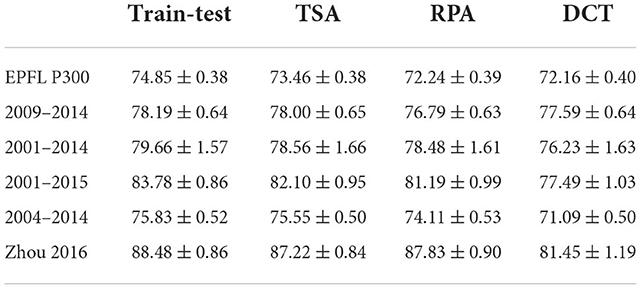
Table 7. Inter-session balanced accuracy table for each dataset and methods.
These results are coherent with the previous ones. They yield accuracies slightly improved as compared to sessions mixed all together, which is expected. Moreover, the proposed method performs better than RPA on all databases with the exception of Zhou 2016.
4. DiscussionThe extensive analysis we have carried out shows that for the ERP paradigm TSA clearly outperforms RPA. For the MI paradigm we observe that TSA performs better than RPA and that the classical train-test cross-validation outperforms both TSA and RPA. For SSVEP, the classical train-test cross-validation outperforms both TSA and RPA. In global, RPA is outperformed by both TSA and the classical train-test cross-validation. Based on Table 6, we do not conclude on the superiority of TSA as compared to train-test in terms of accuracy as the global value that can be found is mainly due to very large values found for the ERP paradigm. To conclude with the results, it has been shown that TSA outperforms RPA for the large majority of the databases we have used in this analysis, reaching an accuracy pretty close to the optimal train-test method. It is also a clear improvement from a methodological point of view in comparison to RPA as it naturally allows transfer learning between datasets with different number of channels, where RPA needs some extensions in order to do so (Rodrigues et al., 2021).
In this paper, we have introduced a new method for transfer learning inter and intra subject for brain computer interfaces. Our study indicates that it outperforms a state-of-the-art analogous method (RPA). However, it still does not reach the same accuracy that can be achieved with a classical test-train cross-validation procedure for the motor imagery and SSVEP paradigm. Further research is needed to understand why the performance of the TSA method is clearly superior for the ERP paradigm.
In terms of computation time, since we have a closed form for the rotation of TSA method, it is way faster than the RPA method, where an optimization on the Grassmann manifold is performed. However, even if our method can be faster by one order of magnitude, with Nc being the size of the pre-covariance signal (number of cha
留言 (0)