
記住我

Gastrectomy with adequate lymphadenectomy provides a potential opportunity of cure for resectable gastric cancer (GC) (Smyth et al., 2020); however, a substantial proportion of patients still develop recurrence or metastasis afterward (Chen et al., 2021; Hisamori et al., 2021). The prognosis of metastatic GC is expected to be poor; the survival time after relapse varies from 3–15 months (Smyth et al., 2020), depending on the metastatic site (Chau et al., 2004; Lee et al., 2007; Kim et al., 2008; Custodio et al., 2017), performance status (Chau et al., 2004; Lee et al., 2007; Kim et al., 2008; Custodio et al., 2017), palliative chemotherapeutic regimen, and other factors (Custodio et al., 2017; Zhu et al., 2022). Several models have been established based on clinical trials or real-world data, aiming to precisely estimate the survival probability in these patients (Chau et al., 2004; Lee et al., 2007; Kim et al., 2008; Koo et al., 2011; Custodio et al., 2017). Although different sets of variables have been incorporated, the ability of survival prediction in the traditional model is dissatisfactory. A Spanish multicenter study (the AGAMENON study) developed a nomogram-based model to predict the survival of patients with advanced GC (AGC), with an accuracy of 0.67 in the validation set (Custodio et al., 2017). A Korean single-center study constructed a score-based model with an accuracy of 0.58 (Koo et al., 2011), then externally validated another three models (Chau et al., 2004; Lee et al., 2007; Kim et al., 2008), and showed similar performances in the same population (Koo et al., 2011). Our previous work also developed a score-based model in a Chinese cohort with a c-index of 0.67 (Ma et al., 2021). Meanwhile, we validated seven published models (Chau et al., 2004; Lee et al., 2007; Kim et al., 2008; Koo et al., 2011; Takahari et al., 2014; Wang et al., 2016; Kim et al., 2020) in a Chinese population, and the results showed that the area under receiver operating characteristic (AUROC) curves was only about 0.60 (Xu et al., 2021).
The traditional prognostic model is frequently built by the logistic or Cox regression analysis on the basis of the well-known clinical and pathological variables, for example, performance status (Chau et al., 2004; Lee et al., 2007; Kim et al., 2008; Takahari et al., 2014), tumor differentiation (Custodio et al., 2017; Kim et al., 2020), metastatic sites (Kim et al., 2008; Takahari et al., 2014; Wang et al., 2016), and routine laboratory tests (Koo et al., 2011; Custodio et al., 2017; Kim et al., 2020; Ma et al., 2021). The selection of candidate variables is typically guided by the clinical experience and previous literature. In the era of digital medicine, the electronic medical record (EMR) and laboratory information system (LIS) make massive medical data readily available; nevertheless, we are still far from taking full advantage of them. One possible reason is the incompetence of the classic statistical method in dealing with numerous independent variables, which emphasizes the need for adopting a new strategy of statistics.
Machine learning (ML) is increasingly used for data mining due to its capacity to tackle big data. In order to utilize the abundant digital medical records and further improve model performance in predicting the survival of GC patients with recurrence or metastasis after radical gastrectomy, we enroll eligible participants from a retrospective GC cohort, build a high-dimensional dataset from the EMR and LIS, identify the most relevant prognostic factors, and implement modeling using several ML algorithms.
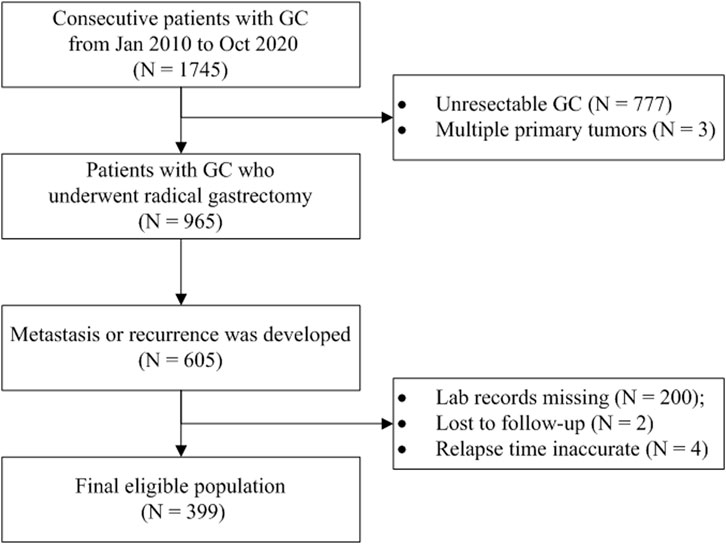
Materials and methodsStudy setting and populationIn this retrospective study, we trained ML models using different algorithms to predict if a GC patient would die within 12 months after the first metastasis or recurrence because 12 months is typically recognized as the median survival time for patients with AGC (Smyth et al., 2020). The participants were enrolled from a registered hospital-based GC cohort (ChiCTR1800019978, http://www.chictr.org.cn/). The consecutive gastric or esophagogastric junction carcinoma patients who underwent radical gastrectomy and developed disease recurrence or metastasis were included and followed up in the cohort. Those patients with multiple primary malignant tumors or with no records of laboratory examinations at the time of metastasis were excluded. The EMR and LIS were retrieved to obtain data for analysis. The survival information was acquired from the death register system or by telephonic follow-up conducted every 3 months. The overall survival (OS) was defined as the interval between the first metastasis and death or the last follow-up. The workflow of the study is illustrated in Figure 1.
FIGURE 1. Flow diagram of patient selection. Abbreviation: GC, gastric cancer.
All procedures performed in the study involving human participants were in accordance with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. The studies involving human participants were reviewed and approved by the Ethics Committee of The First Affiliated Hospital of Anhui Medical University (reference number: Quick-PJ-2021-05-19). The Ethics Committee waived the requirement of written informed consent for participation.
Dataset and feature engineeringAll features are listed in Supplementary Table S1. Briefly, the dataset included information about demography, histopathology, surgical resection, postoperative adjuvant chemotherapy, first-line palliative chemotherapy, radiotherapy, baseline laboratory records at the time of metastasis (routine blood test, biochemistry, coagulation, immunology, and tumor biomarkers), and survival. Each aspect had several items to record the details, so a high-dimensional dataset was generated.
Categorical features were transformed by one-hot encoding. Numerical features were standardized, normally transformed, or grouped where appropriate. In our dataset, missing values generally occurred at random, so they were deleted (the fraction of the missing values over the total cases was more than 30%) or imputed using decision tree algorithm.
ML model performance may suffer from high dimensionality, so, here, some features were filtered out prior to modeling. A feature with zero or near-zero variance was first dropped because it provided no useful information to a model. The rule of detecting a near-zero variance feature was (Smyth et al., 2020) that the fraction of unique values over the sample size was less than 10% and (Hisamori et al., 2021) the ratio of the frequency of the most prevalent value to the frequency of the second most prevalent value was more than 20% (Boehmke and Greenwell, 2019). Next, we used the importance value calculated by the random forest (RF) algorithm to rank the features and select a number of them that contributed most to the model. The specific number was tuned by a random search during model development. All these data-dependent preprocessings were conducted in isolation of each resampling iteration in order to avoid data leakage.
Model developmentFirst, the entire dataset was randomly split into a training set and a validation set (8:2) as the outer layer. Then, the training set was further randomly split by 10-fold cross-validation (CV) as the inner layer. The inner layer was used to tune hyperparameters by random search, and the best configuration was passed on the validation set from the outer layer to evaluate the model performance. The nested CV design reduced the risk of overestimation of the model because the information of the training set was not leaked into the validation set. The whole process was repeated five times for averaging the effect of randomness, so we used the mean value to measure the model performance. The AUROC curve was the primary indicator to evaluate the model because it did not have any bias toward classifiers on balanced or imbalanced binary prediction problems (He and Ma, 2013). Precision and recall were also crucial as they reflected the false-positive error and the false-negative error of the model, respectively. In addition, accuracy and F1 score (the harmonic mean of precision and recall) were also calculated.
We used eight common classification algorithms for modeling: kernel K-nearest neighbor (KKNN), linear discriminant analysis (LDA), support vector machine (SVM), RF, XGBoost, ridge regression, LASSO regression, and elastic net regression. For each algorithm, the hyperparameters that needed to be tuned and the optimal settings are given in Supplementary Table S2. The whole project was deployed using RStudio 1.4.1717 with packages “mlr3verse” (modeling pipeline and framework), “kknn” (KKNN algorithm), “e1071” (SVM algorithm), “MASS” (LDA algorithm), “ranger” (RF algorithm), “xgboost” (XGBoost algorithm), and “glmnet” (ridge, LASSO, and elastic net regression). To make a comparison with the traditional method, we used the logistic regression as a reference algorithm.
A learning curve is used to diagnose if the sample size is adequate for modeling and if an overfitting or underfitting problem occurs. It comprises two lines that represent the errors of the training set and the validation set, respectively, in relation to the sample size. The training learning curve shows how well the model is learning, and the validation curve shows how well the model is generalizing. If a model is underfitting, the error of the training set is close to that of the validation set, so obtaining more samples is unlikely to improve the performance. In contrast, if a model is overfitting, the gap between the errors of the training set and validation set is large, so adding more samples is likely to be helpful.
Model interpretationOnly the selected models were interpreted, which comprised the LDA, the SVM, and the RF-based model. The model interpretation was based on the final model built on the entire dataset with the tuned hyperparameters or model configuration. The general theories of the three algorithms were briefly demonstrated. The LDA aims to learn a new line, called the discriminant function (DF) that combines the original features in a linear fashion, weighting greater for “better” predictors and less for “poorer” predictors. The value that gives the weight for each feature is called the DF coefficient, which indicates how much it contributes to class discrimination. The DF separates the centroid of each class (OS longer than or equal to 12 months versus shorter than 12 months in the case) by maximizing the difference between the class centroids and minimizing the within-class variance when the data being projected onto the DF (Rhys, 2020).
The SVM and the RF algorithms are more alike “black-box” models. The SVM algorithm finds an optimal linear hyperplane that best separates the two classes and is penalized for having cases inside its decision boundary defined by the support vectors. The algorithm can also add a kernel, namely, an extra dimension, to deform the feature space, so that a linear hyperplane can separate the classes (Rhys, 2020). The RF algorithm is an implementation of a bagging technique for decision tree algorithm. It randomly samples cases and features to create a large number of tree classifiers on a binary prediction task that are highly uncorrelated. Then, new data are passed to the trees to make their own prediction, and the model prediction is made based on the majority of the predictions from each tree (Rhys, 2020).
Global surrogate is a common global model-agnostic method to interpret a black box model (e.g., SVM or RF model) by using a surrogate model with a good intuition. In this case, we train a linear regression model or a decision tree model to fit the black box-predicted probability or response, respectively. R-square was used to measure how close the surrogate model is to the black box model (Elshawi et al., 2019).
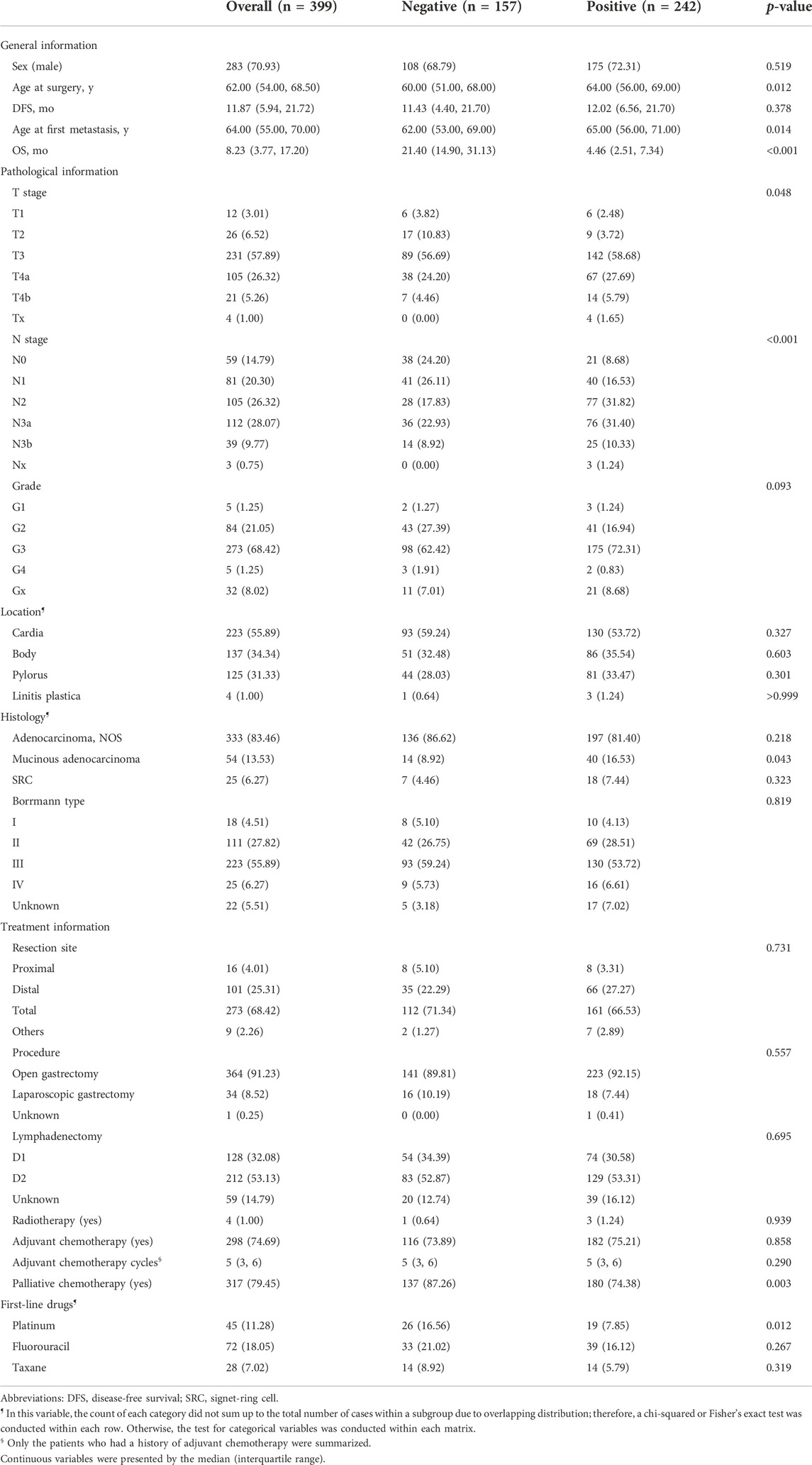
ResultsAs shown in Figure 1, 399 GC patients developing metastasis or recurrence after curative intent gastrectomy were enrolled for modeling. The median survival after metastasis was 8.2 months. Two lost to follow-up cases were removed. Fourteen patients were still alive (survival time ranged from 20.7 to 144.0 months, median 95.1 months), so all the living patients had an OS of no less than 12 months and were assigned to the negative subgroup. Of 385 patients who reached the endpoint (mOS = 7.8 months), 143 patients survived for no less than 12 months (negative subgroup). Overall, the negative subgroup consisted of 157 cases, and the positive subgroup (post-metastatic survival time <12 months) consisted of 242 cases. The ratio of the majority to the minority was 1.54:1. The five most frequent metastasis sites were 46.1% for distant lymph nodes (n = 184), 26.8% for the liver (n = 107), 19.8% for the peritoneum (n = 79), 15.8% for bone (n = 63), and 15.5% for the chest (n = 62). The baseline information is briefly presented in Table 1. No missing value existed.
TABLE 1. Baseline characteristics of the patients enrolled for modeling.
After excluding some features with massive missingness, a total of 62 laboratory indexes were in the feature space, and the distribution of missing values was generally at random (Supplementary Figure S1A). No clear pattern was observed when comparing these indexes between the positive and the negative subgroups (Supplementary Figure S1B,C). The feature filter process returned a feature list ordered by the RF importance and then passed it into further modeling. Interestingly, the highly important features were generally the laboratory information at metastasis, i.e., inflammatory index, blood cell test, and biochemistry. Supplementary Figure S1C illustrates the 30 most important features for brevity.
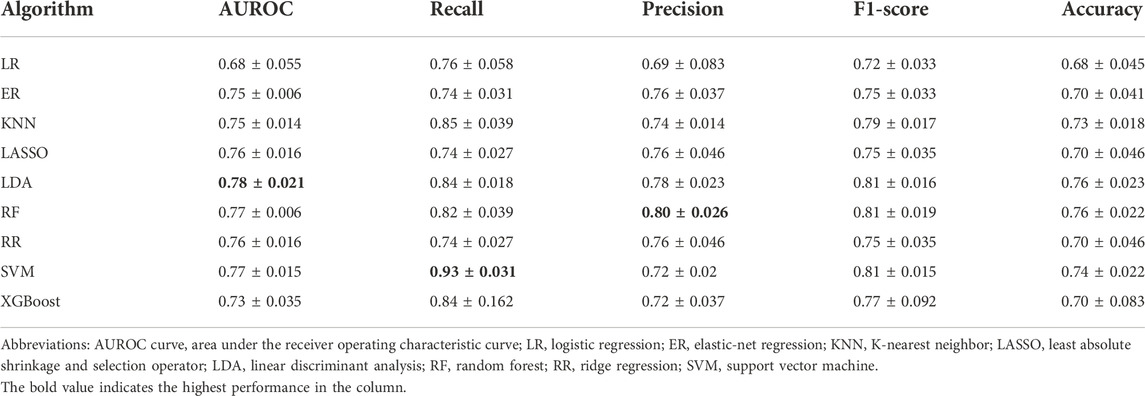
After tuning the optimal number of the features and the hyperparameters, the model performances are shown in Table 2. The LDA model had the highest AUROC (m ± sd; 0.78 ± 0.021), followed by the SVM model with an AUROC of 0.77 ± 0.014 and the RF model with an AUROC of 0.77 ± 0.0064. The SVM model ranked first with respect to recall (0.93 ± 0.031), and the RF model ranked first with respect to precision (0.80 ± 0.026). So, we further look into these three models.
TABLE 2. Comparison of model performance across different machine learning algorithms for predicting 12-month survival in patients with metastatic gastric cancer.
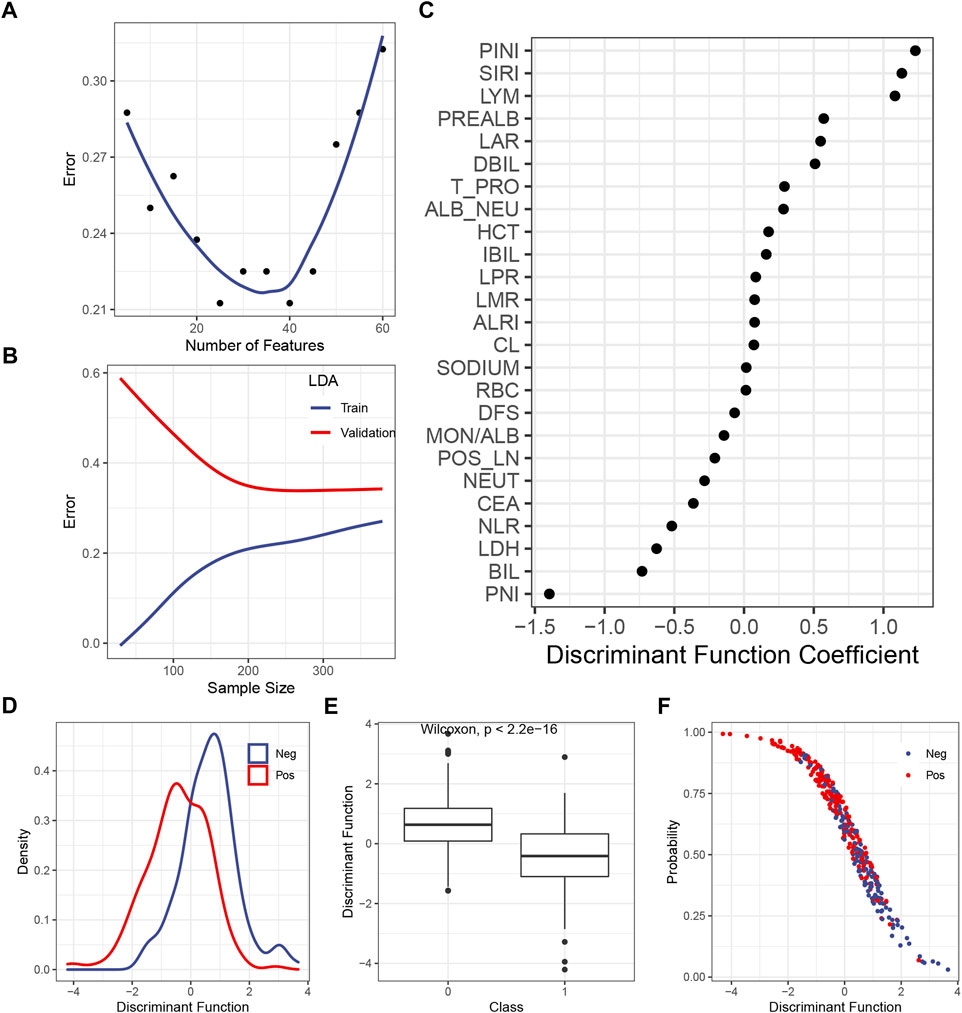
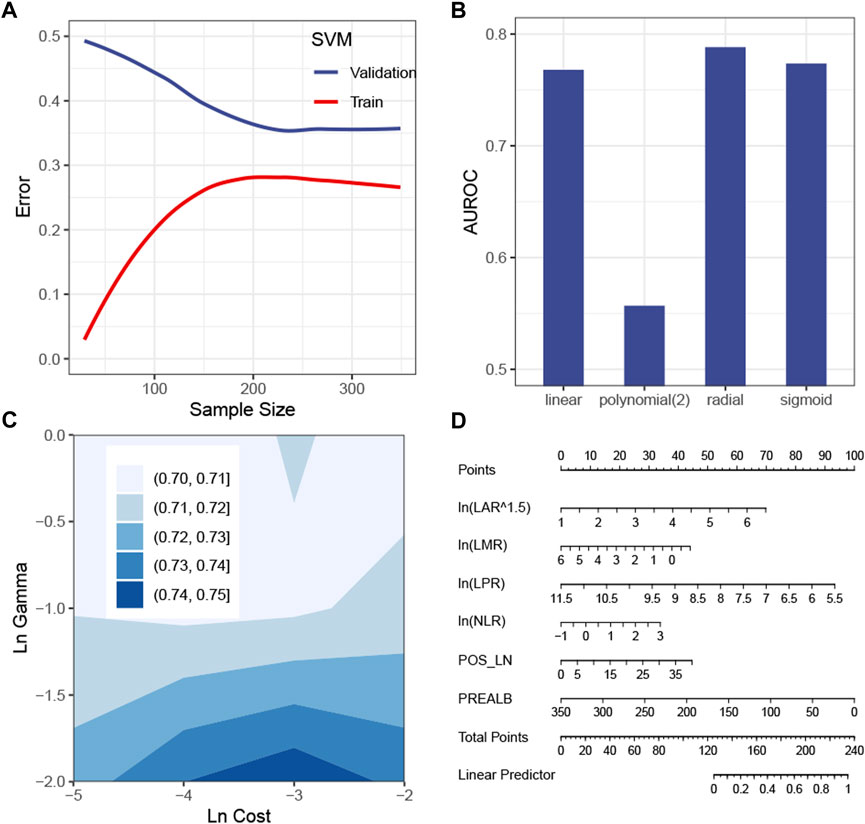
The LDA itself had no hyperparameter to be tuned, so only the number of the included features should be tested. Figure 2A shows that the inclusion of the first 25 or 40 features yielded the lowest error in the validation set, so 25 was chosen to make the model simpler. The learning curve illustrated that, with 25 features being considered, the gap between the train and the validation error became steady as the sample size exceeded 200 (Figure 2B). The DF coefficient for each included feature is shown in Figure 2C. The absolute value of the coefficient reflected the contribution of the feature to the model. By summing up the product of the DF coefficient and the feature, a DF was calculated for each case. The distribution of the DF in each class was a bell-shaped curve, with a clearly distinct summit from each other (Figure 2D). As expected, the mean of the DF in each class was statistically different (Figure 2E). The plot of the DF (x-axis) over the probability of being predicted as positive by the final model (y-axis) demonstrated that, as the DF became greater, the probability of being predicted as positive declined (Figure 2F), which was consistent with the DF distribution across the classes (Figure 2E).
FIGURE 2. Construction of the LDA model. (A) Correlation between the predicted error in the validation set and the number of features. (B) Learning curve of the LDA model. (C) DF coefficient of the features in the model. All the features were scaled, so the absolute value of the coefficient reflected the contribution of a feature to the model. (D) Distribution of the DF in the positive or the negative subgroup. (E) Difference of the median DF in each subgroup was examined by the Wilcoxon test. (F) Plot of the DF over the predicted probability of being positive by the final LDA model. Abbreviations: LDA, linear discriminant analysis; DF, discriminant function; PINI, prognostic inflammatory nutrition index; SIRI, systemic inflammation response index; LYM, lymphocyte; PREALB, prealbumin; LAR, lymphocyte–albumin ratio; DIBL, direct bilirubin; T_PRO, total protein; NEU, neutrophil; HCT, hematocrit; IBIL, indirect bilirubin; LPR, lymphocyte platelet ratio; LMR, lymphocyte–monocyte ratio; ALRI, aspartate aminotransferase–lymphocyte ratio index; RBC, red blood cell; DFS, disease-free survival; MON, monocyte; ALB, albumin; POS_LN, number of positive lymph node; CEA, carcinoembryonic antigen; NLR, neutrophil–lymphocyte ratio; LDH, lactic dehydrogenase; BIL, bilirubin; PNI; prognostic nutrition index.
The SVM model with the tuned hyperparameters (Supplementary Table S2) performed best with respect to recall. Figure 3A shows that the sample size was sufficient to stabilize the validation error from the SVM model. Figures 3B,C simulate hyperparameter tuning by grid search, showing that a combination of a radial kernel function, a natural log-transformed cost of about -3 and a natural log-transformed gamma of about -2, gave the highest AUROC in the validation set. It was consistent with the configuration of the actual model tuned by random search (Supplementary Table S2). Because this model only picked the first eight features, it is possible and more intuitive to interpret the SVM model by a linear regression model visualized by a nomogram (Figure 3D). Of the eight features, the linear model, namely, the surrogate model, automatically chose six features by a stepwise method (Figure 3D). The R-square was 0.68.
FIGURE 3. Construction of the SVM model. (A) Learning curve of the SVM model. (B) Simulation test of the tuning kernel function measured by the AUROC. (C) Simulation test of tuning cost and gamma measured by the AUROC. (D) Global surrogate model visualized by a nomogram to approximate the predicted probability of being positive by the SVM model. Abbreviations: SVM, support vector machine; AUROC curve, area under the receiver operating characteristic curve; LAR, lymphocyte–albumin ratio; LMR, lymphocyte–monocyte ratio; LPR, lymphocyte–platelet ratio; NLR, neutrophil–lymphocyte ratio; POS_LN, number of positive lymph node; PREALB, prealbumin.
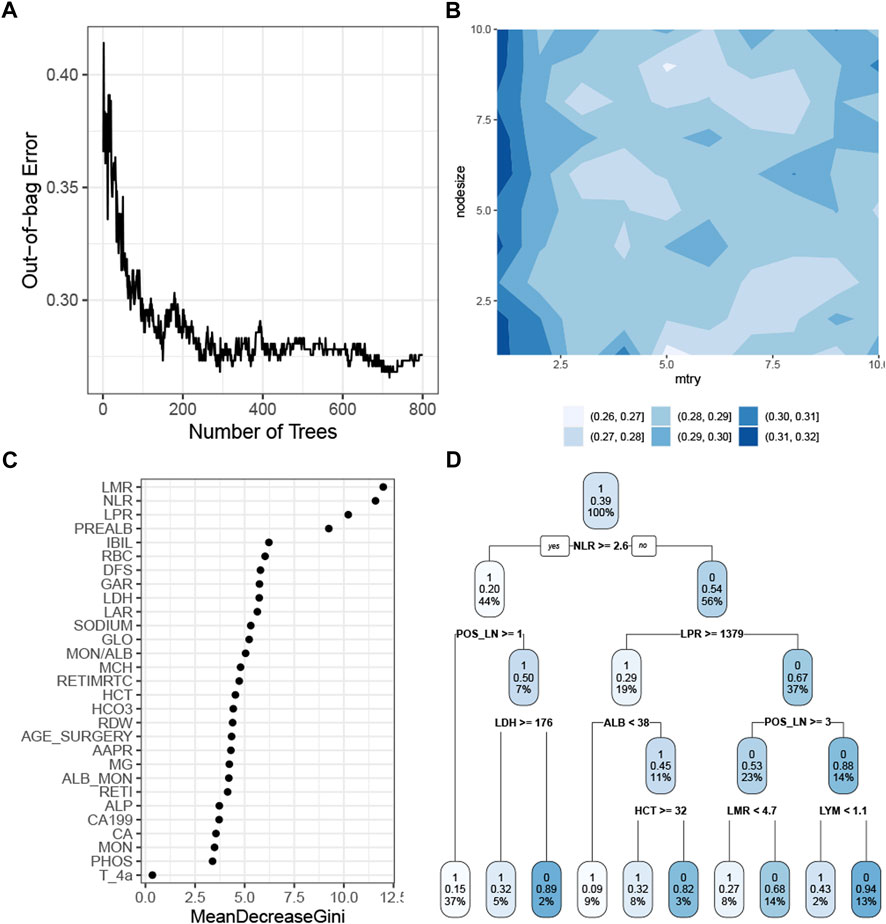
The RF model with the tuned hyperparameters (Supplementary Table S2) had the highest precision. Figure 4A shows that the model performance stabilized when the number of trees was greater than 400 and reached the best when approximately 700 trees were aggregated. The simulation test showed the optimal combination of the mtry and the nodesize by grid search (Figure 4B). The rank of the feature demonstrated that the baseline white cell count, platelet count, and prealbumin were the most crucial predictors in the RF model (Figure 4C). This model chose 29 features, so it was more appropriate to use a decision tree algorithm, with a cp of 0 and a maxdepth of 4, as a surrogate model to approximate the response predicted by the RF model (Figure 4D). The R-square was 0.57.
FIGURE 4. Construction of the RF model. (A) Correlation of the out-of-bag error with the number of trees. (B) Simulation test of tuning mtry and nodesize measured by the AUROC. (C) Feature importance as measured by the RF algorithm. (D) Global surrogate model visualized by a decision tree to approximate the predicted response by the RF model. Abbreviations: RF, random forest; AUROC curve, area under the receiver operating characteristic curve; LMR, lymphocyte–monocyte ratio; NLR, neutrophil–lymphocyte ratio; PREALB, prealbumin; IBIL, indirect bilirubin; RBC, red blood cell; DFS, disease-free survival; GAR, γ-glutamyl transpeptadase–albumin ratio; LDH, lactic dehydrogenase; LAR, lymphocyte–albumin ratio; GLO, globulin; MON, monocyte; ALB, albumin; MCH, mean corpuscular hemoglobin; RETIMRTC, moderate fluorescence–reticulocyte ratio; HCT, hematocrit; RDW, red cell distribution width; AAPR, albumin-to-alkaline phosphatase ratio; RETI, reticulocyte count; ALP, alkaline phosphatase; PHOS, phosphorus.
DiscussionThis study demonstrates that the LDA, SVM, and RF models outperform other algorithms in predicting the survival of patients with metastatic GC. The model performance assessed by a single holdout CV is not reliable because of the effect of randomness in splitting data into training and validation sets. Here, this issue is addressed by repeating the holdout CV five times, so the performance is unbiased in the local cohort, as measured by AUROC, recall, and precision. All the AUROCs of the three models exceed 0.75, which is higher than those in the previous reports (Koo et al., 2011; Custodio et al., 2017; Ma et al., 2021). In addition, our earlier work selected the patients with AGC receiving first-line chemotherapy from the same local cohort and compared the performances of seven survival prediction models on it, showing the best model having an AUROC of 0.60 (Xu et al., 2021). The present study does not impose restrictions on treatment or other factors, so the population is of wider heterogeneity, which may help the model generalize well due to closely reflecting the characteristics of the patients in a real-world setting.
The LDA model performs the best as measured by the AUROC. This model is relatively the most interpretable model among the algorithms tested because it constructs a single and intuitive DF from the original features for classification, which is similar to the well-known logistic regression. In contrast, the SVM and RF models are less explainable; however, they perform the best as measured by recall and precision, respectively. In clinical practice, if we want to identify as many patients as possible with less than 1-year survival by the model, i.e., avoid a false-negative event, we should consider the SVM model because it has the highest recall. If we want to be confident with the ML’s prediction, i.e., avoid a false-positive event, we should consider the RF model due to its highest precision. Therefore, model selection is closely related to the specific practical scenario.
Almost all the features included for modeling are the baseline index of systemic inflammation and malnutrition, albeit with a few exceptions, which is in line with the previous studies. For patients receiving first-line treatment, Kim et al. (2020) identified the clinically relevant features as NLR, neutrophil count, alkaline phosphatase, albumin, lymphocyte count, and white blood cell count. The AGAMENON nomogram weights the neutrophil-to-lymphocyte ratio (NLR) greater than tumor differentiation, metastasis site, or HER2+-treated (Custodio et al., 2017). Hsieh et al. (2016) selected NLR, modified Glasgow prognostic score (mGPS), and Patient-Generated Subjective Global Assessment (PG-SGA) as the most relevant predictors (all of them are inflammation- or nutrition-based scores), compared with age, physical status, differentiation, and metastasis site. In fact, the laboratory index is frequently adopted in models for predicting the survival of metastatic GC patients (Chau et al., 2004; Lee et al., 2007; Kim et al., 2008; Takahari et al., 2014; Wang et al., 2016; Kim et al., 2020), as extra information added on the well-recognized predictors. The present study further emphasizes the prediction value of the index in a setting of a more heterogeneous population with GC. In other words, the ML model “considers” that the post-metastasis survival is mainly attributed to the characteristics of the patients at the time of metastasis, other than the history of staging, surgery, adjuvant chemotherapy, and so on. This may explain the prognoses of the patients with metachronous or synchronous GC being the same as long as the cancer is at an advanced stage (Patel et al., 2007).
The current study has several limitations. First, the models are confident to generalize well in the local population because they are unbiasedly evaluated by repeated CV; however, the case is uncertain in other situations due to lack of external validation. Second, the ensemble technique, a common method to enhance model performance (Rhys, 2020), is not utilized for modeling. We consider there is a trade-off between model complexity and model performance: using ensemble is very likely to improve the model at the cost of long running time and poor interpretability and vice versa. So, here we prefer an easier model, at the cost of performance, in order to facilitate real clinical practice. Third, there are still over 20 features in some models, albeit feature filtering has been conducted. This would impede the models from being used as a quick screening tool for practitioners.
In conclusion, on the basis of the readily available information from the EMR and LIS, the mainstream ML method can produce satisfactory models for predicting survival in patients with metastatic GC who experienced prior radical gastrectomy. The algorithm should be selected according to the measurement and its meaning in a practical scenario.
Data availability statementThe raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Ethics statementThe studies involving human participants were reviewed and approved by the Ethics Committee of The First Affiliated Hospital of Anhui Medical University. The Ethics Committee waived the requirement of written informed consent for participation.
Author contributionsConceptualization: CF and TM; data curation: YZ, M-MX, X-PZ, CF, Z-JW, YF, and Y-HY; formal analysis: CZ, YZ, and Y-HY; funding acquisition: TM; investigation: M-MX, YZ, X-PZ, CF, Z-JW, YF, and Y-HY; methodology: CF and TM; project administration: CF and TM; resources: M-MX, YZ, X-PZ, CF, Z-JW, YF, and Y-HY; supervision: CF and TM; validation: M-MX, YZ, X-PZ, CF, Z-JW, YF, and Y-HY; writing—original draft: CZ, YZ, and Y-HY; writing—review and editing: CZ, HX, TM, M-MX, YZ, X-PZ, CF, Z-JW, YF, and Y-HY.
FundingThis work was supported by the Anhui Provincial Key Research and Development Program [grant number 1804b06020351], The First Affiliated Hospital of Anhui Medical University Clinical Research Project [grant number LCYJ2021YB015], and the Research Fund from Anhui Medical University [grant number 2022xkj160].
AcknowledgmentsThe authors are grateful to Mr. Zhen-Hui He for his help in data electronization.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary materialThe Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmolb.2022.937242/full#supplementary-material
ReferencesBoehmke, B., and Greenwell, B. (2019). Hands-on machine learning with R. Boca Raton, Florida, United States: CRC Press.
Chau, I., Norman, A. R., Cunningham, D., Waters, J. S., Oates, J., and Ross, P. J. (2004). Multivariate prognostic factor analysis in locally advanced and metastatic esophago-gastric cancer-pooled analysis from three multicenter, randomized, controlled trials using individual patient data. J. Clin. Oncol. 22 (12), 2395–2403. doi:10.1200/JCO.2004.08.154
PubMed Abstract | CrossRef Full Text | Google Scholar
Chen, M., He, F. Q., Liao, M. S., Yang, C., and Chen, X. D. (2021). Gastrectomy with omentum preservation versus gastrectomy with omentectomy for locally advanced gastric cancer: A systematic review and meta-analysis. Int. J. Surg. 96, 106176. doi:10.1016/j.ijsu.2021.106176
PubMed Abstract | CrossRef Full Text | Google Scholar
Custodio, A., Carmona-Bayonas, A., Jimenez-Fonseca, P., Sanchez, M. L., Viudez, A., Hernandez, R., et al. (2017). Nomogram-based prediction of survival in patients with advanced oesophagogastric adenocarcinoma receiving first-line chemotherapy: A multicenter prospective study in the era of trastuzumab. Br. J. Cancer 116 (12), 1526–1535. doi:10.1038/bjc.2017.122
PubMed Abstract | CrossRef Full Text | Google Scholar
Elshawi, R., Al-Mallah, M. H., and Sakr, S. (2019). On the interpretability of machine learning-based model for predicting hypertension. BMC Med. Inf. Decis. Mak. 19 (1), 146. doi:10.1186/s12911-019-0874-0
PubMed Abstract | CrossRef Full Text | Google Scholar
He, H., and Ma, Y. (2013). Imbalanced learning. Foundations, algorithms, and applications. Hoboken, New Jersey, United States: Wiley-IEEE Press.
Hisamori, S., Okabe, H., Tsunoda, S., Nishigori, T., Ganeko, R., Fukui, Y., et al. (2021). Long-term outcomes of laparoscopic radical gastrectomy for highly advanced gastric cancer: Final report of a prospective phase II trial (KUGC04). Ann. Surg. Oncol. 28 (13), 8962–8972. doi:10.1245/s10434-021-10373-8
PubMed Abstract | CrossRef Full Text | Google Scholar
Hsieh, M. C., Wang, S. H., Chuah, S. K., Lin, Y. H., Lan, J., and Rau, K. M. (2016). A prognostic model using inflammation- and nutrition-based scores in patients with metastatic gastric adenocarcinoma treated with chemotherapy. Med. Baltim. 95 (17), e3504. doi:10.1097/MD.0000000000003504
PubMed Abstract | CrossRef Full Text | Google Scholar
Kim, J., Hong, J. Y., Kim, S. T., Park, S. H., Jekal, S. Y., Choi, J. S., et al. (2020). Clinical scoring system for the prediction of survival of patients with advanced gastric cancer. ESMO Open 5 (2), e000670. doi:10.1136/esmoopen-2020-000670
PubMed Abstract | CrossRef Full Text | Google Scholar
Kim, J. G., Ryoo, B. Y., Park, Y. H., Kim, B. S., Kim, T. Y., Im, Y. H., et al. (2008). Prognostic factors for survival of patients with advanced gastric cancer treated with cisplatin-based chemotherapy. Cancer Chemother. Pharmacol. 61 (2), 301–307. doi:10.1007/s00280-007-0476-x
PubMed Abstract | CrossRef Full Text | Google Scholar
Koo, D. H., Ryoo, B. Y., Kim, H. J., Ryu, M. H., Lee, S. S., Moon, J. H., et al. (2011). A prognostic model in patients who receive chemotherapy for metastatic or recurrent gastric cancer: Validation and comparison with previous models. Cancer Chemother. Pharmacol. 68 (4), 913–921. doi:10.1007/s00280-011-1561-8
PubMed Abstract | CrossRef Full Text | Google Scholar
Lee, J., Lim, T., Uhm, J. E., Park, K. W., Park, S. H., Lee, S. C., et al. (2007). Prognostic model to predict survival following first-line chemotherapy in patients with metastatic gastric adenocarcinoma. Ann. Oncol. 18 (5), 886–891. doi:10.1093/annonc/mdl501
PubMed Abstract | CrossRef Full Text | Google Scholar
Ma, T., Wu, Z., Zhang, X., Xu, H., Feng, Y., Zhang, C., et al. (2021). Development and validation of a prognostic scoring model for mortality risk stratification in patients with recurrent or metastatic gastric carcinoma. Bmc Cancer 21 (1), 1326. doi:10.1186/s12885-021-09079-7
PubMed Abstract | CrossRef Full Text | Google Scholar
Patel, P. R., Yao, J. C., Hess, K., Schnirer, I., Rashid, A., and Ajani, J. A. (2007). Effect of timing of metastasis/disease recurrence and histologic differentiation on survival of patients with advanced gastric cancer. Cancer 110 (10), 2186–2190. doi:10.1002/cncr.23046
PubMed Abstract | CrossRef Full Text | Google Scholar
Rhys, H. I. (2020). Machine Learning with R, the tidyverse, and mlr. Shelter Island, New York, United States: Manning.
Smyth, E. C., Nilsson, M., Grabsch, H. I., van Grieken, N. C., and Lordick, F. (2020). Gastric cancer. Lancet 396 (10251), 635–648. doi:10.1016/S0140-6736(20)31288-5
PubMed Abstract | CrossRef Full Text | Google Scholar
Takahari, D., Boku, N., Mizusawa, J., Takashima, A., Yamada, Y., Yoshino, T., et al. (2014). Determination of prognostic factors in Japanese patients with advanced gastric cancer using the data from a randomized controlled trial, Japan clinical oncology group 9912. Oncologist 19 (4), 358–366. doi:10.1634/theoncologist.2013-0306
PubMed Abstract | CrossRef Full Text | Google Scholar
Wang, J., Qu, J., Li, Z., Che, X., Zhang, J., Liu, J., et al. (2016). A prognostic model in metastatic or recurrent gastric cancer patients with good performance status who received first-line chemotherapy. Transl. Oncol. 9 (3), 256–261. doi:10.1016/j.tranon.2016.04.004
PubMed Abstract | CrossRef Full Text | Google Scholar
Xu, H., Zhang, X., Wu, Z., Feng, Y., Zhang, C., Xie, M., et al. (2021). Performances of prognostic models in stratifying patients with advanced gastric cancer receiving first-line chemotherapy: A validation study in a Chinese cohort. J. Gastric Cancer 21 (3), 268–278. doi:10.5230/jgc.2021.21.e26
PubMed Abstract | CrossRef Full Text | Google Scholar
Zhu, X. D., Huang, M. Z., Wang, Y. S., Feng, W. J., Chen, Z. Y., He, Y. F., et al. (2022). XELOX doublet regimen versus EOX triplet regimen as first-line treatment for advanced gastric cancer: An open-labeled, multicenter, randomized, prospective phase III trial (EXELOX). Cancer Commun. 42 (4), 314–326. doi:10.1002/cac2.12278
留言 (0)