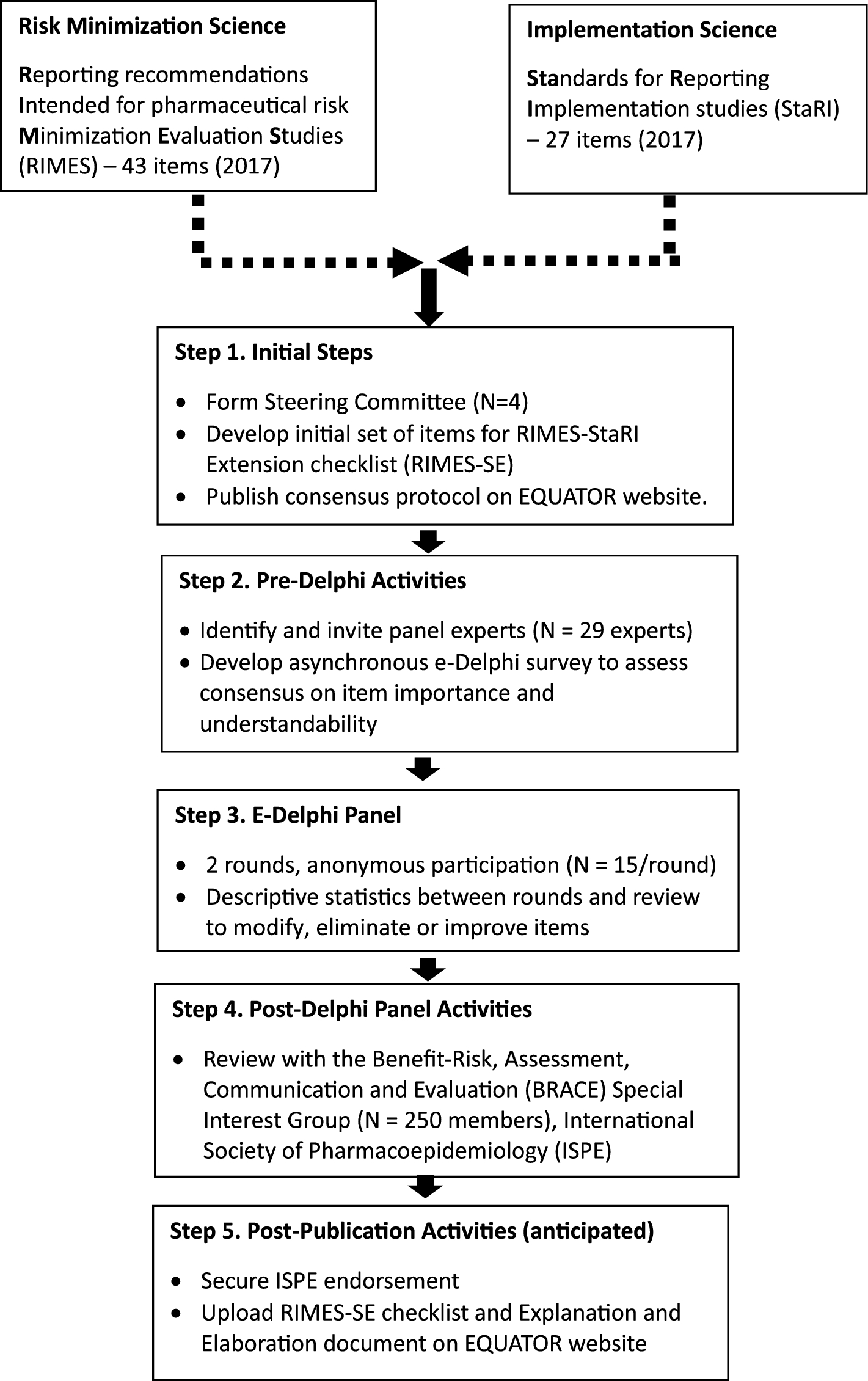
Development of Draft Items for the Delphi Panel
We drafted a set of items to present to the panel. Seven experts on real-world evidence (RWE) algorithms from different organizations drafted the initial set of items, informed by existing tools to evaluate diagnostic studies [3, 4], tools to evaluate observational studies on RWE [5, 6], and relevant published literature on the topic [8,9,10], including regulatory documents from the FDA [7, 11], European Medical Agency [12,13,14], and government organizations such as the Agency for Health Care Research and Quality [15] and the Patient Centered Outcomes Research Institute [16]. These included items from a recent stakeholder review by some of our team members [10] and were also informed by algorithms identified from a scoping review on ischemic stroke.
The initial list of items was intended to stimulate discussion by the Delphi panel. It was intended to be comprehensive and inclusive of all items potentially relevant to the objectives, data sources, study design, accuracy, reference standards, and limitations of algorithm validation studies. We also included items related to the assessment of external validity to a target study. These items were intended to be generic and outcome independent. All the authors, representing different organizations and different areas of expertise, were involved in drafting the items.
Selection of Safety Outcome of Ischemic Stroke
We selected the safety outcome of ischemic stroke to motivate the development of draft items. We selected ischemic stroke because of its importance to regulators and other stakeholders, the heterogeneity of operational definitions for “ischemic stroke,” and the availability of several validated algorithms. We had initially intended to evaluate algorithms on the composite endpoint of major adverse cardiovascular outcome, which comprises the endpoints of myocardial infarction, stroke, and cardiovascular death. However, most available algorithms reported on the individual endpoints rather than the composite.
Scoping Review for Ischemic Stroke
We conducted a scoping review to identify EHR or medical claims-based algorithms for ischemic stroke. The results of this review informed the development of draft items for the Delphi panel. We excluded studies that did not validate algorithms against a reference standard. We included studies that evaluated the diagnostic accuracy, i.e., sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) of International Classification of Disease (ICD)-9- or ICD-10-based administrative algorithms for ischemic stroke. We included studies that reported on any of these parameters. We excluded prognostic utility studies, randomized controlled trials, case series, review articles, and systematic reviews or studies with no original data.
Delphi Process and Consensus
The Delphi process synthesizes opinions of experts into group consensus [17, 18] through the provision of structured feedback and statistical group response, with the responses of each individual reflected anonymously in final ratings [19]. A reproducible method for selection of participants, prespecification of the definition of consensus, and prespecification of the number of rounds are key qualities to ensure a robust Delphi study [17]. The required level of consensus for keeping an item needs to be prespecified prior to each round. It has varied from as low as 50% agreement [20] to more than 80% agreement [21]. Percent agreement (e.g., > 80%) has been the most commonly used definition of consensus, followed by proportion of participants agreeing on a particular rating [17]. Given the small size of our expert panel and the need for a tool that prioritizes sensitivity of items over specificity, we selected > 70% agreement as the definition of consensus for the selection of the final round of items. We conducted three sequential rounds of review and evaluated the level of agreement and open-ended responses to decide which items to include in subsequent rounds. We combined items with similar concepts when possible. We planned to stop the Delphi process after three rounds regardless of the level of agreement or stability of ratings.
Identification and Recruitment of the Delphi Panel
We considered the following areas of expertise critical to our panel: (1) regulatory expertise from the FDA Office of Surveillance and Epidemiology as well as the Office of Medical Policy; (2) cardiovascular methodology; (3) development and validation of algorithms in large databases; and (4) causal inference and pharmacoepidemiology. We also identified experts from pharmaceutical sponsors who conduct validation studies. We identified experts from relevant networks, membership of societies (e.g., International Society of Pharmacoepidemiology), and relevant publications on the topic. All were invited to participate by email. All but one expert agreed to participate. The expert who refused to participate identified another relevant expert from his/her perspective. The final seven-member panel included two regulators, four members from academia, including a cardiovascular epidemiologist, cardiologists, and pharmacoepidemiologists, and regulatory representatives. One member from industry provided expertise in the conduct of validation studies.
First Round of the Delphi Panel
We generated items for the first round based on domains and items informed by the tools and guidance documents noted above. To assist the panelists, we also presented a hypothetical vignette for a proposed safety study of a hypothetical product for ischemic stroke for regulatory surveillance (see Table 1). We presented the results of the draft tool to the panel after a 90-min online orientation session. The panel rated the importance of the draft items and proposed additional items independently and anonymously to reduce the risk of bias. The tool included items relevant to internal validity, external validity, ethics, and transparency of reporting. The panelists provided categorical responses to whether the selected items should be included to accurately identify the construct of interest (internal validity) or support the use of the algorithm in a target, i.e., safety surveillance study (external validity). They also provided open ended responses about additional items to evaluate algorithm validation studies. There was no limit to the number of items that could be generated. We conducted a qualitative analysis and grouped similar items together, removed redundant items, and included new items generated by the panel in the participants’ words as much as possible. We clarified concepts and terms and reorganized the structure of the tool (e.g., moving items from one section to another). The items were structured in the form of sufficiently complex questions for the next round to minimize ceiling effects.
Second Round of the Delphi Panel
In the second round, the panel rated the revised set of items on a 5-level scale (strongly disagree, disagree, neutral, agree, or strongly agree) to determine agreement for inclusion of items. A rating of strongly agree signified that item was important and needed to be included in the tool, whereas a rating of strongly disagree indicated that the item was not important and should not be included. We quantified the level of agreement and disagreement among all rated items. As prespecified, all items that were rated as being agree or strongly agree (≥ 4) by >70% of the panel were retained for the next round of the survey [21].
Third Round of the Delphi Panel
The objective of the third round of the Delphi panel was to achieve consensus on the final list of items and stability of ratings, if possible. The panel reviewed and rated the items using similar methods as round 2 above. All items rated as being agree or strongly agree (≥ 4) by > 70% of the panel were retained for the final tool [21].
Operationalizing the ACE-IT
Five pairs of experts in clinical epidemiology, pharmacoepidemiology, and validation independently used the final version of the tool to evaluate two selected ischemic stroke studies from the final list of included studies [22, 23]. There was no overlap between members of the Delphi panel and these experts. We selected two studies on ischemic stroke for appraisal for pragmatic considerations [22, 23]. These studies were selected from the final list of included studies by the study team as they were deemed appropriate for further testing of the ACE-IT. These two studies provided sufficient heterogeneity in data sources, population, and reporting of accuracy metrics. One study measured the PPV of acute ischemic stroke among intravenous immunoglobin users in the Sentinel Distributed Network [22]. The other study validated ischemic stroke among women in Medicare using the Women’s Health Initiative Cohort [23]. One study reported precision around accuracy parameters [22], whereas the other study did not report any precision around these estimates [23]. One study was conducted in an administrative claims database and validated stroke outcomes against chart reviews [22]. The other study was conducted among Medicare participants and validated stroke outcomes compared to stroke diagnoses in the Women’s Health Initiative Study [23].
The objective of this evaluation was to clarify ambiguous terms and concepts. When items included more than one component, (e.g., an item on the data source included considerations on data cleaning and data quality), raters made their best judgment and provided a rationale for their ratings. Raters used the above vignette to guide their work and assess the FFP of the two validation studies to a target data source (IQVIA PharMetrics® Plus database) (January 2010–September 2019) for the target study [24]. Using the hypothetical vignette shown in Table 1, the raters were asked to evaluate the internal validity, external validity, and reporting of the two ischemic stroke algorithms to the target study population [24]. This rigorous evaluation by a team of experts allowed us to test the performance of the tool.
Evaluation by the Stakeholder Panel
We convened 16 independent experts in the field for a 2-h virtual meeting via Zoom. There was one member of the Delphi panel, who provided the regulatory perspective, who also participated in the stakeholder panel. The members in attendance included researchers from academic institutions, representatives from pharmaceutical companies, healthcare technology companies, and the FDA. Participants’ expertise spanned epidemiology, pharmacoepidemiology, regulatory, and RWE analytics. The meeting was recorded and transcribed for note taking purposes and followed a semi-formal guide moderated by a member that was not part of the core research team. Stakeholders were provided the tool and user guide prior to the meeting for review and were asked to provide their input on four key questions: (1) What factors affect a decision about whether a given RWE algorithm is FFP? (2) What is your general reaction to the ACE-IT? (3) What are the limitations of the tool? and (4) How do you see you or your organization using this tool? We transcribed their comments and summarized their responses to the above questions with representative quotes.
Development of the ACE-IT and User Guide
We developed the final version of the tool, which included an explanation and elaboration document. Each item included in the tool was followed by an explanation and elaboration section, which included the rationale for inclusion of the item and the essential and additional elements needed to inform the assessment. We distinguished between elements that were essential to assess the validity of the study findings versus additional elements that may enhance study credibility and may only be applicable in certain scenarios. We also included a verbatim excerpt from an example validation study followed by an example of the assessment by a user.
Data Collection and Analysis
The tool was completed via REDCap, a secure data management system [25, 26]. We assessed percent agreement in rounds 2 and 3.

留言 (0)