
記住我

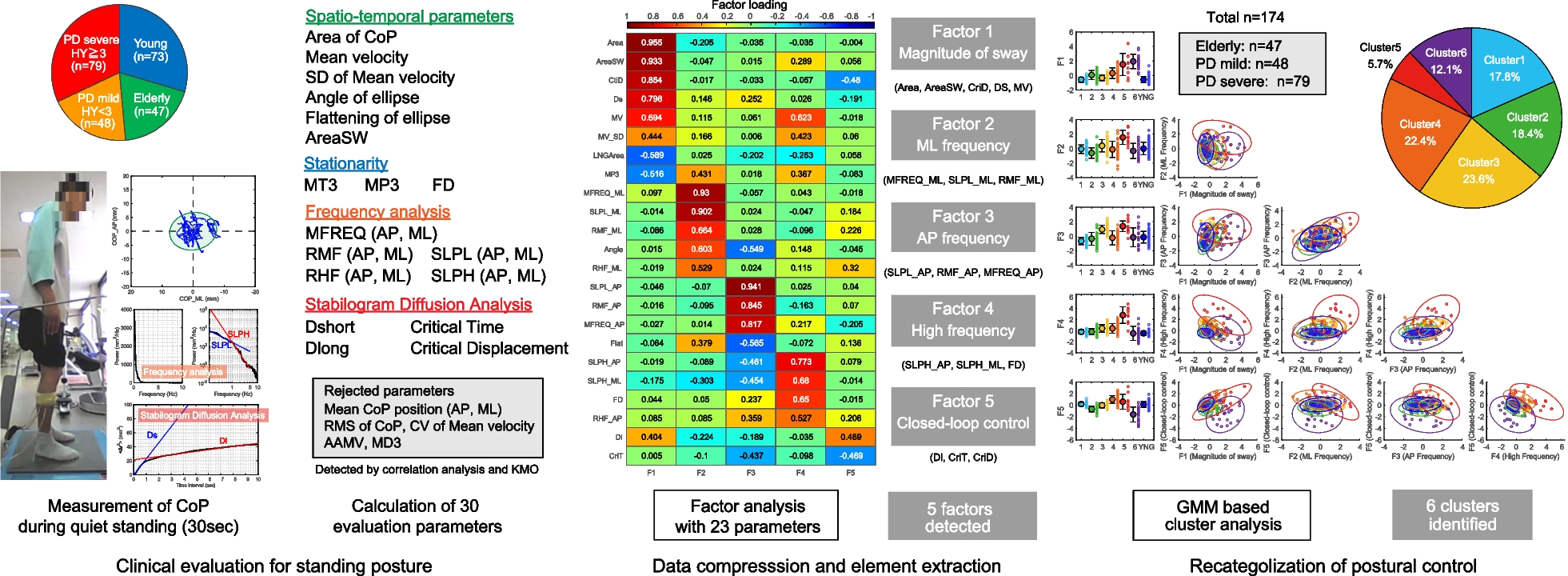




This section is divided as follows. We first present the simplified robotic rehabilitation gym scenario in plain English (Scenario description) and using mathematical formulations (Mathematical scenario formulation). We then present the mixed-integer programming algorithms used for dynamic patient-robot assignment (Optimization algorithms) and multiple evaluation scenarios in which the performance of these algorithms was evaluated (Evaluation methodology).
Scenario descriptionIn our simplified scenario, the robotic rehabilitation gym consists of M patients exercising with N robots for a period of G time steps. Each patient has K motor skills that they need to improve; these can be considered to be, for example, different upper limb and lower limb abilities as separated by clinical scales such as the Motor Assessment Scale [27] or the Fugl-Meyer Assessment [28], but are kept general for purposes of the simplified scenario. Similarly, a robot could also be a passive sensorized rehabilitation device but is kept as a general ‘robot’ for purposes of our scenario.
For the current paper, multiple simplifications and constraints of the scenario were implemented. The scope of these simplifications and ways in which they could be expanded are examined further in the Discussion. First, there were several constraints on robot use that we consider reasonable:
At any given time, only a single patient can use a given robot. While competitive and cooperative two-robot setups could be modeled as a single robot that can be used by two patients [7,8,9,10,11,12], such setups are currently a minority.
At any given time, a given patient can only use a single robot. While there are some setups where a patient can train with two robots simultaneously (e.g., an arm and leg robot [29]), they are relatively rare.
Each robot has an associated nonnegative time required to ‘exit’ the robot after training that is constant across patients and does not contribute to skill improvement. Realistically, there is both an ‘enter’ and an ‘exit’ time for each robot, which represents the time needed to, e.g., adjust the lengths of the robot’s segments to the patient, strap the patient to the robot before exercise, and unstrap them after exercise. The time may in practice be different for different patients and may vary depending on the temporal sequence of patients (e.g., if a patient is followed by a patient of roughly the same size, reducing readjustment time). However, we consider simplifying this as an overall ‘exit’ time to be reasonable for the current study.
As a result of the above exit time, a patient cannot enter a new robot until they have exited their current robot, and a patient cannot enter a robot until the previous patient has exited that robot.
Second, there were two constraints on training schedules that we also consider relatively reasonable:
All patients begin and finish training simultaneously; none can train before the starting time or after the end time. In practice, patients may arrive and leave one by one.
A patient may only train with a given robot once for a single uninterrupted period. For example, they cannot leave the robot, train with another robot, and come back to the first robot; as a second example, they cannot train with the robot, take a break where they do nothing, and continue training with the same robot. This is likely reasonable if the time period to be modeled is a single session, and can be expanded later.
Third, there were five simplifications related to skill acquisition, of which the last two are quite major and are discussed extensively in the Discussion:
Each robot only trains a single motor skill. Larger robots can train multiple skills simultaneously (e.g., both distal and proximal upper extremity function in the ARMin [2]), and there is evidence that training one skill generalizes to improvements in other skills (e.g., distal to proximal [30]), but we consider this a reasonable initial simplification that can easily be expanded later.
Each skill is only trained by a single robot. In practice, a robotic gym may have multiple robots that all train the same skill (e.g., multiple identical robots), but we again consider this a reasonable initial simplification that can easily be expanded later.
Once a patient is assigned to a robot, no further choices need to be made for that robot. In practice, rehabilitation robots have adjustable difficulty settings and control strategies [5] that are set either manually by the therapist or automatically by an intelligent algorithm.
Each skill improves as a deterministic function of time spent training on a robot that trains that skill, and depends on no other factors. This is a strong simplification; while such learning functions have been described in the literature [31, 32], they are not deterministic, and improvement is influenced by numerous other factors (e.g., forgetting [25]).
Each patient’s current skill levels are available to the patient-robot assignment algorithms at all times, and the functions that relate improvement to training time are also known. This is a very strong simplification: while rehabilitation robots can assess patient motor function using built-in sensors, this estimate is not completely accurate [21,22,23,24]; furthermore, standardized clinical tests of motor function such as the Fugl-Meyer Assessment [28] are not perfectly accurate and cannot be conducted during a rehabilitation session since they require significant time. Similarly, the learning function is not known to rehabilitation robots and can only be imperfectly estimated.
Mathematical scenario formulationFor the scenario described in the previous subsection, we define a set of rehabilitation robots, \(R:=\_,\dots ,_\}\), a group of patients, \(P:=\_,\dots ,_\}\), and a set of motor skills, \(S:=\left\_,\dots ,_\right\}\), to be trained for each patient. Let \(N\) be the number of robots, \(M\) be the number of patients and \(K\) be the number of skills. To follow the simplifications above, \(N = K\) and each skill is trained by exactly one robot. The training session consists of \(G\) discrete time steps, i.e., \(G\) is the final time training can be done. We also define \(H\) as the final time a patient may start training on a new robot. Both \(G\) and \(H\) are non-negative integers, and \(G\ge H\). In our specific case, we set \(H = G\), allowing a patient to start training on a robot at the last time step and train for a single time step. The time steps can be used to represent any amount of time as long as the duration of each time step is the same. For each robot \(_\in R\), the robot’s exit time is defined as a non-negative integer \(__}\). When no time is needed to exit a robot, \(__}\) = 0. For each patient \(_\in P\), we are given skill curves that determine skill improvements as a function of time spent training on different robots. This encapsulates the last two simplifications in the previous subsection. The objective of dynamic patient-robot assignment and training planning is to find a schedule of the patients’ skill training on the robots that optimizes the total skill gain across the patients.
The scheduling problem can be framed as a mixed-integer nonlinear programming (MINLP) problem. There are three basic MINLP formulations: the time-indexed formulation, the disjunctive formulation, and the rank-based formulation [33]. The choice of MINLP formulations is based on their flexibility to model a problem and the computational efficiency to solve the problem. We applied both time-indexed (Time-indexed model) and disjunctive (Disjunctive model) models to our scheduling problem. After presenting broad models, we applied several simplifications for the current study, described in “Simplifications for our study”.
Time-indexed modelIn time-indexed models, a schedule is created by determining, for each time step \(t\le H\), whether a patient starts training on a given robot and how long the patient trains on the robot. The decision variables used for the time-indexed model are defined as follows:
\(__,_,t}\) is a Boolean variable that is equal to 1 if patient \(_\) starts training on robot \(_\) at time step \(t\).
\(__,_}\) is a nonnegative integer that represents the amount of time patient \(_\) trains on robot \(_\).
Unlike the original time-indexed models for process engineering [34] where the duration of a task is known a priori, our model introduces the variable \(__,_}\) to determine when a patient should stop training on a given robot as part of the decision-making. The time-indexed MINLP model is then formulated as maximizing objective function (1), subject to constraints (2)–(8):
$$\mathrm\sum_^\sum_^\sum_^__,_,t},__,_})$$
(1)
subject to
$$_^__,_,t }\le 1, \forall _\in R, t\le H$$
(2)
$$_^__,_,t }\le 1, \forall _\in P, t\le H$$
(3)
$$\sum_\sum___,_}}^__,_}+__,_}+__}-1 }__,_,t} \le 1, \, \forall \, _,\,_\in R \text _ \ne _, \, _\in P,$$
(4)
$$\sum___,_}}^__,_}+__,_}+__}-1}\sum___,_,t} \le 1,\, \forall \, _,\,_\in P \text _ \ne _, \,_\in R,$$
(5)
$$__,_,t}*t+__,_}-1\le G, \forall _\in R, _\in P, t\le H$$
(6)
$$_^\sum___,_}}^__,_}+__,_}+__a}-1}__,_,t}= \sum___,_}}^__,_}+__,_}+__a}-1}__,_,t}=1,\forall _,_\in R, _\in P, t\le H$$
(7)
$$\sum_^__,_,t}\le 1, \forall _\in R, _\in P$$
(8)
The objective (1) maximizes the total skill gain across all patients during the training session, where
$$f(__,_,t},__,_})=\frac__,_}*(__,_} + __,_}*(__,_}*__,_,t}+__,_}))}__,_}+__,_}*(__,_}*__,_,t}+__,_})+__,_}} -\frac__,_}*(__,_} + __,_}*__,_})}__,_}+__,_}*__,_}+__,_}}$$
(9)
is the skill curve function with \(__,_},__,_},__,_}\) determining the shape of the skill curve and \(__,_}\) determining how far along the skill curve a patient advances per time step. Each \(c\) value changes depending on the patient \(_\) and robot \(_\) pairing to create a custom skill curve. \(_\) is the number of training time steps previously performed by patient \(_\) with robot \(_\) in previous sessions, plus one (with the plus one used to calibrate the function). The basic function is common to all patients and skills while the parameters may differ between patients and skills. It models a modified hyperbolic skill curve where patients tend to have rapid gains when first training a skill, then diminished returns as they train more [31, 32]. The \(\frac__,_}*(__,_} + __,_}*__,_})}__,_}+__,_}*__,_}+__,_}}\) portion of the equation represents the patient’s initial skill value before the current training session.
Constraints (2)–(5) are imposed on robot use. Constraint (2) ensures that only a single patient can start using a given robot at any given time. Constraint (3) ensures that a given patient can only start using a single robot at any given time. Constraint (4) ensures that a patient \(_\) cannot begin training on a new robot \(_\) until after they have exited their current robot \(_\) (i.e., \(__,_}+__,_}+__ }-1\), where \(__,_}\) is a nonnegative integer that represents the time when patient \(_\) starts training on robot \(_).\) This constraint is ignored if patient \(_\) does not train on robot \(_\) during the session. Constraint (5) ensures that a patient \(_\) cannot start training on a robot \(_\) until after the previous patient \(_\) on robot \(_\) has exited that robot and patient \(_\) has entered the robot (i.e., \(__,_}+__,_}+__}_)\). Again, this constraint is ignored if patient \(_\) does not train on robot \(_\) during the session. Constraint (6) ensures that no one can start training or continue to train after the final time step—i.e., no one can train at \(G+1\). Constraint (7) ensures that a person can only train on a single robot at a time. Constraint (8) ensures that a patient may only train with a given robot once for a single uninterrupted period.
Disjunctive modelIn disjunctive models, a schedule is created by determining what time a patient starts and finishes training on a given robot. The start and end times together implicitly capture the amount of time spent training on a robot. The decision variables used in the disjunctive model are defined as follows:
\(__,_}\) is the integer start time of patient \(j\) on robot \(i\).
\(__,_}\) is the integer end time of patient \(j\) on robot \(i\).
\(__,_,_}\) is a Boolean precedence indicator that is equal to 1 if patient \(_\) is on robot \(_\) before patient \(_\) and is equal to 0 otherwise.
\(__,_,_}\) is a Boolean precedence indicator that is equal to 1 if patient \(_\) is on robot \(_\) before robot \(_\) and is equal to 0 otherwise.
\(__,_}\) is a Boolean activation variable that is equal to 1 if patient \(_\) uses robot \(_\) during the training session and is equal to 0 otherwise.
The disjunctive MINLP model is formulated as maximizing objective (10), subject to constraints (11)–(15):
$$\mathrm\sum_^\sum_^f(__,_},__,_})$$
(10)
subject to
$$1\le __,_}\le __,_}\le G, \forall _\in R, _\in P$$
(11)
$$\left(__,_}-(__,_}+_-V*__,_,_})\right)*__,_}*__,_}\ge 0, \forall _\in R, _,_\in P$$
(12)
$$\left(__,_}-(__,_}+__}-V*(1-__,_,_}))\right)*__,_}*__,_}\ge 0, \forall _\in R,_,_\in P$$
(13)
$$\left(__,_}-(__,_}+__}-V*__,_,_})\right)*__,_}*__,_}\ge 0, \forall _,_\in R, _\in P$$
(14)
$$\left(__,_}-(__,_}+__}-V*(1-__,_,_}))\right)*__,_}*__,_}\ge 0, \forall _,_\in R, _\in P$$
(15)
The objective (10) maximizes the total skill acquisition across all patients during the training session, where
$$_,_)=\frac__,_}*(__,_}+__,_}*(1+__,_}-__,_}+__,_}))}__,_}+__,_}*(1+__,_}-__,_}+__,_})+__,_}}-\frac__,_}*(__,_} + __,_}*__,_})}__,_}+__,_}*__,_}+__,_}}$$
(16)
is the skill improvement function. While function (16) appears slightly different than function (9), this is only because of the difference in the variables used to model the disjunctive and time-indexed models. Both Eqs. (9) and (16) represent a modified hyperbolic function that models the learning curves [31, 32]. Passing a schedule represented in time-indexed model form through function (1) results in an equal value as passing that same schedule in disjunctive model form through function (10).
Constraint (11) ensures that the start and end times of a patient training on a given robot are between \(1\) and \(G\), and the start time is not later than the end time. Constraints (12) and (13) are disjunctive constraints on robot use and ensure that two patients’ training activities requiring the same robot cannot overlap in time. Specifically, for any two patients \(_,_\in P\), the start time of patient \(_\) on a given robot must be at least \(__}\) greater than the end time of patient \(_\) on the same robot if patient \(_\) precedes \(_\). This requirement accounts for the time, i.e., \(__}\), taken for patient \(_\) to exit the robot. This is analogous to constraint (5) in the time-indexed model. The Boolean variable \(__,_,_}\) is introduced to indicate the precedence of two patients \(_\) and \(_\) on robot \(_\). \(V\) is a sufficiently large multiplier [35] that ensures that either (12) or (13), but not both, will hold depending on the precedence indicated by \(__,_,_}\). Note that the two constraints are taken into account only if both patient \(_\) and \(_\) use the robot \(i\) during the training session, i.e., \(__,_}= __,_}=1\). For any two patients \(_\) and \(_\) who do not both use robot \(_\) at any time during the training session, i.e., \(__,_}=0\) or \(__,_}=0\), constraints (12) and (13) are always satisfied. Similarly, constraints (14) and (15) are disjunctive constraints on the schedule of a given patient that ensure that the start time of patient \(_\) on robot \(_\) must be at least \(__}\) greater than the end time of patient \(_\) on robot \(_\) if patient \(_\) uses robot \(_\) before robot \(_\). The two constraints hold only if both robot \(_\) and \(_\) are used by patient \(_\) during the training session, i.e., \(__,_}=__,_}=1\).
Simplifications for our studyWhile Eqs. (9) and (16) allow general representations of possible skill curves, our specific study held several variables constant for simplicity. \(__,_}\) represents the maximum skill value that can be achieved with an infinite amount of training (e.g., maximum score on a clinical assessment scale); this was set to 100 for every skill. \(__,_}\) determines how many “units” of training a patient gains in a skill when training that skill for one time step. This could be used to represent, e.g., more or less efficient robots for the same skill, but was not considered critical for the current study, and \(__,_}\) was thus set to 1. Finally, we focused only on scenarios where patients have not previously trained with the robots, and \(__,_}\) was thus set to 1. The skill function for the time-indexed model, Eq. (9), thus simplified to:
$$__,_,t},__,_})=\frac__,_} + __,_}*__,_,t}+1)}__,_}+__,_}*__,_,t}+1+__,_}} -\frac__,_}+1)}__,_}+1+__,_}}$$
(17)
and Eq. (16) thus simplified to:
$$__,_},__,_})=\frac__,_}+2+__,_}-__,_})}__,_}+2+__,_}-__,_}+__,_}}-\frac__,_}+1)}__,_}+1+__,_}}$$
(18)
Optimization algorithmsThe Branch-And-Reduce Optimization Navigator (BARON) optimizer (The Optimization Firm LLC, USA) [36] was applied to both time-indexed and disjunctive models. BARON was chosen due to its ability to find global solutions to nonlinear and mixed-integer nonlinear problems. As the name implies, BARON specifically uses branch-and-bound optimization that always finds the global optimum under specific conditions (e.g., having a finite lower and upper bound on the nonlinear constraints, having enough optimization iterations to complete the search). Additionally, the OPTI toolbox for MATLAB 2021a (MathWorks, USA) was used to interface with the BARON optimizer, and IBM’s ILOG CPLEX optimization studio [37] was used to increase the effectiveness of the BARON optimizer. The OPTI toolbox can accept constraints in both linear and nonlinear format. Initially, we wrote all constraints in nonlinear format; for the final evaluation, linear constraints were written in linear format since this (on average) reduced optimization duration.
While the BARON optimizer is guaranteed to find a solution close to the global maximum, this is only if it has enough time to do so. As the number of optimization iterations is always limited, the optimizer may be unable to find the optimal schedule within that limit. Therefore, the optimization was combined with an algorithm that scans the schedule in each optimization iteration for obvious weaknesses and removes them. Specifically, the algorithm looks for situations where a patient is idle and scheduled to be assigned to a robot in later time steps, but that robot is already available earlier; in such situations, the algorithm changes the schedule so the patient begins training on that robot as soon as it is available. A similar process is applied to the end time: if a patient is scheduled to exit a robot but the robot and patient would then both be idle, the training time on the robot is extended. Despite this algorithm, repeated optimization of the same scenario may still lead to slightly different results due to the finite number of optimization iterations.
Evaluation methodologyOur optimization strategy aims to maximize the total amount of skill gained during a session: the difference between the skill value at the end and the start of the session, summed across all patients and skills. This total skill gain depends on the patients’ initial skill level and their skill curves (modeled with Eqs. 17 and 18 for each patient-robot pairing). The skill curves have diminishing returns, similar to real-world situations where it becomes harder to improve a skill the more a patient has trained it [31, 32]. To evaluate the effectiveness of the optimization strategy, we first evaluated multiple scenarios where all patients have the same skill curve for all skills (Equal skill curves) and then multiple scenarios where the patients have different skill curves (Different skill curves). Finally, to evaluate the computational cost of the optimization, we measured how optimization duration depends on the number of patients, robots, and time steps (Effect of patients, robots and time steps on optimization duration).
Equal skill curvesIn this situation, all skill curves of all patients are described using Eqs. (17) and (18) and the parameter values are \(__,_}\) = 10, \(__,_}\) = 1 and \(__,_}\)= 1 for each patient and skill. Three possible combinations of patients and robots were tested:
5 patients and 5 robots,
6 patients and 5 robots,
5 patients and 7 robots.
Each of these was tested in three time variants:
7 time steps total, robots have no exit time,
12 time steps total, robots have no exit time,
12 time steps total, robots have an exit time of 1 time step.
There was thus a total of 9 evaluation scenarios with equal skill curves.
In the last variant (1-step exit time), a patient must wait (remain idle) for one time step after training on a robot before they can be assigned to a new robot (\(__}\)= 1 \(\forall _\in R\)). Furthermore, no other patient can train with that robot until the previous patient has completed the idle period. Such exit times were not evaluated with a 7-time-step duration since the short duration would strongly favor not switching robots. The difference in computational complexity between 7 and 12 time steps was expected in advance to be greater for the time-indexed model since that model’s parameter count scales proportionally higher with respect to time while the disjunctive model’s does not.
For both models, the optimization was allowed to run for 1000 iterations. Additionally, two ‘baseline’ approaches were evaluated for each scenario:
Best robot only: Each patient was assigned to a single robot for the entire session. This was selected as the robot that would result in the highest individual skill gain over the session for that patient. In case of conflicts (two patients would get highest gain from same robot), the robot was assigned to the patient who would receive a greater gain, and the other patient was assigned to their “second-best” robot.
Switch halfway: Each patient was assigned to one robot for the first half of the session and a second robot for the second half of the session. These were again selected as the two robots that would result in the two highest individual skill gains over the session for that patient, and conflicts between patients were resolved similarly to the previous case. As the skill curves have diminishing returns, this was expected to lead to higher overall skill gain than not switching robots and is similar to a recent robotic gym paper where patients switched midway through the session [6].
As a basic statistical test, a one-way repeated-measures analysis of variance (ANOVA) with Holm-Sidak post-hoc tests was calculated with four conditions (disjunctive, time-indexed, best robot only, switch halfway) and nine samples per condition (the nine evaluation scenarios). A priori, both disjunctive and time-indexed models were expected to outperform both baseline schedules: optimization should yield a superior result unless the naïve schedules are already optimal. No significant difference was expected between disjunctive and time-indexed schedules; given infinite optimization iterations, both models should converge to the same schedule. It should be noted that the ANOVA independence assumption is violated since the “best robot only” result is the same in the “12 time steps” and “12 time steps and exit time” scenarios; we considered this acceptable since the ANOVA is simply a quick validation of the results rather than the primary outcome measure.
Different skill curvesRealistically, patients have different initial skill levels before training (e.g., different impairment levels after neurological injury) and learn skills at different rates. To represent these differences, every patient-robot pairing was assigned a different skill curve by varying variables \(_\) and \(_\) in Eqs. (17) and (18). These variables affect both the rate of growth and initial skill value.
42 different skill curves with different values of \(__,_}\) and \(__,_}\) were created and randomly distributed to patients and robots in a group. \(__,_}\) ranged from 0.01 to 100 while \(__,_}\) ranged from 5 to 1000. This was done three times to create three ‘groups’ of patients with different skill curves, allowing us to determine whether the system could consistently create a good schedule that was not dependent on a very specific set of skill distributions. For each of the three groups, the same 9 scenarios as in the previous subsection were simulated, and the two baseline approaches were evaluated as well. Again, optimizations ran for 1000 iterations.
As a basic statistical test, a two-way mixed ANOVA was conducted with one within-subject factor (schedule: disjunctive, time-indexed, best robot only, switch halfway), one between-subjects factor (group: 1–3) and nine samples per bin (nine evaluation scenarios). Holm-Sidak post-hoc tests were used to compare schedules, and effect size was reported as partial eta-squared. Significant differences between schedules were expected a priori since optimization should yield a superior result unless the naïve schedules are already optimal. Thus, the ANOVA serves as a quick check of the optimization rather than as the primary outcome.
Effect of patients, robots and time steps on optimization durationThe optimization duration is expected to increase as the number of patients, robots, and time steps increases. To determine the effect of each of these parameters, we applied both disjunctive and time-indexed models to the “equal skill curves” scenario, varied the three parameters, and measured the optimization duration. The following variations were tested:
At 5 patients and 5 robots, test 1, 2, 3, 4, 5, and 12 time steps,
At 5 robots and 5 time steps, test 1, 2, 3, 4 and 5 patients,
At 5 patients and 5 time steps, test 1, 2, 3, 4, and 5 robots.
All optimizations were run on a personal computer with an 8-core 3600-MHz Ryzen 7 3700X central processing unit (AMD, Santa Clara, CA).
留言 (0)