

記住我









All the view features are stitched together to obtain the following Equation:
M=∑i=1i=20ResNest(vi) (2)To satisfy the data input requirements for the subsequent SoftPool attention convolution processing (Section 2.2.2), we propose a combination of ResNest and adaptive pooling for view feature extraction. In this method, ResNest removes the final fully-connected layer and adds an AdaptiveAvgPool2d process. This is because adaptive pooling can obtain the output of a specified size based on an input, and the number of features in the input and output does not change. Therefore, the output of ResNest after adaptive pooling ensures that the view feature information extracted by the network remains unchanged and also satisfies the input requirements for the subsequent SoftPool attention convolution.
The view features extracted by ResNest are processed by the adaptive pooling layer to obtain F, as shown in Equation (3):
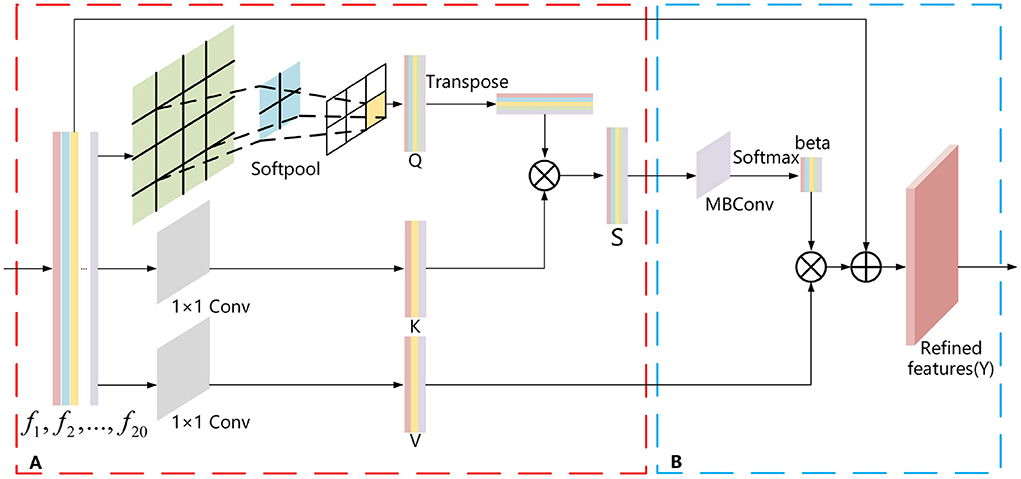
2.2.2. Refined feature extraction based on SoftPool attention convolutionThere is also some unnecessary information in the view features (F) extracted using ResNest with the adaptive pooling method. This information is redundant for aggregation into a global descriptor. For this purpose, we propose a SoftPool attention convolution method to accomplish refined feature extraction. This method mainly relies on the self-attention mechanism (Zhang et al., 2019). As self-attention can process the entire input view feature information globally, its strong global perception capability enables global feature extraction of view features. However, it is deficient in the refinement extraction of local features of the view. Moreover, it lacks the inductive bias property, so it has poor generalization. Also, our proposed SoftPool attention convolution method solves these problems and can achieve fine-grained extraction of view features. It contains the following two modules: Refinement feature extraction based on the SoftPool self-attention method; and Model generalization enhancement based on self-attention convolution (Figure 2).
Figure 2. SoftPool attention convolution method. (A) Refinement feature extraction based on SoftPool. (B) Model generalized enhancement based on self-attention convolution.
2.2.3. Refined feature extraction based on softPool self-attention methodThe pooling layer used in most neural networks is either max pooling or average pooling. Max pooling selects only the max activation values in the region, resulting in a large amount of information loss. In contrast, average pooling averages all activation values, which reduces the overall region characteristics. Therefore, it is not appropriate to choose either max pooling or average pooling for view feature extraction. The SoftPool method (Stergiou et al., 2021) first selects the activation graph, divides the individual activation values in the activation graph by the sum of the natural exponents of all activation values to obtain the corresponding weight values, multiplies all the weights by the corresponding activation values, and sums them to obtain the output. This makes all activation values of the feature map act on the final output, which is the greatest difference between SoftPool and max and average pooling. To this end, this paper proposes the SoftPool self-attention method, which makes full use of the strong global perception capability of self-attention and preserves the detailed information of multi-view features by using SoftPool. The self-attention mechanism obtains the corresponding V-value after calculating the similarity between Q and K vectors, and then the V-value is weighted and summed to obtain the value of the self-attention method. In this method, SoftPool uses the processed view feature F-value as the Q value of self-attention, which can refine the multi-view feature downsampling process and retain more multi-view feature detail information to achieve refined feature extraction (Figure 2A). It effectively overcomes the shortage of the self-attention mechanism in viewing the local feature refinement extraction and helps to generate ultimate global descriptors with discriminative ability.
The process is divided into two steps:
(1) For the F = view features extracted by ResNest with the adaptive pooling method, fi denotes the feature of the i-th view. We take the view feature (F) as input and generate a feature map (Q) by SoftPool (Stergiou et al., 2021) processing. Two 1 × 1 convolutions are also used to generate the feature maps K and V. See Equations (4), (5), and (6):
where F denotes the feature vector of size m × n, Conv1×1 is a 1 × 1 convolution kernel, K and V are the feature vectors obtained by the 1 × 1 convolution operation, and Q is the feature vector obtained by the output of the SoftPool operation.
(2) The vector S is obtained by multiplying the vector K with the transpose vector QT, as shown in Equation (7):
where T is the transpose operation, × is the product operation between two vectors, and S denotes the matrix vector of the multiplication of K and QT.
2.2.4. Model generalization enhancement based on self-attention convolutionThe self-attention mechanism has weak generalization owing to the lack of inductive bias (Dai et al., 2021). In contrast, convolution has good generalization ability owing to its convolution kernel, which is static and possesses translational invariance. To this end, we introduce the mobile inverted bottleneck convolution (MBConv) (Sandler et al., 2018), which is currently the most advanced convolution, in the self-attention mechanism to enhance the generalization (Figure 2B). The main principle of MBConv is that the input features are first up-dimensioned using 1 × 1 convolution, and then the information between their length and width is extracted by depth-separable convolution. The dimensionalized input feature information is downscaled by point convolution to obtain information across channels. A linear activation function is adopted in the dimensionality reduction process to prevent information loss. To prevent network degradation, a reversal residual block is added at the end to sum the reduced-dimensional features with the input features, which significantly improves the generalization performance of the model.
The process is divided into two steps.
(1) Input the vector S into MBConv (Sandler et al., 2018) and use the SoftMax function for scaling and normalization to obtain the attention weight values, as follows:
beta=Softmax(MBConv(S)dk) (8)(2) Take this attention weight value and multiply it with the V vector to obtain the result of the self-attention calculation O :
where beta denotes the attention weights obtained by passing the S matrix through the SoftMax function, SoftMax is the activation function, and dk is used to prevent the S value from being too large when the dimensionality is large.
We combine ResNest with the multi-view features (F) obtained by the adaptive pooling method with the result of the self-attention calculation (O) to finally obtain the refined features (Y) extracted by the SoftPool attention convolution method:
Y=F+gamma*O (10)where gamma is the parameter, and Y denotes the refined features.
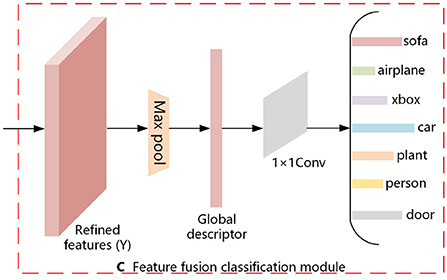
2.3. Feature fusion classificationIn this section, we describe the multi-view feature fusion classification module. It is shown in Figure 3. For the refined features (Y) obtained from the above equation, Maxpooling is utilized to aggregate the features and thus generate a compact global descriptor (Global), as shown in Equation (11). The 1 × 1 convolution allows the number of channels to be reduced by controlling the number of convolution kernels, and it does not limit the size of the input features. Therefore, we input the generated global descriptor (Global) to the 1 × 1 convolution to obtain the result of the 3D model classification, as shown in Equation (12).
Global=Max(Y) (11) Z=Conv1×1(Global) (12)where Z denotes the result of the determination of N classes of objects, Max denotes the pooling aggregation operation, Global denotes the resulting global descriptor, and Conv1×1 denotes the convolution operation with a 1 × 1 convolution kernel.
Figure 3. Feature fusion classification.
3. Experiment 3.1. DatasetsTo evaluate the performance of our proposed MVMSAN network, we conducted extensive classification comparison experiments using the ModelNet40 and ModelNet10 datasets. ModelNet40 includes 3D CAD models in 40 common grid forms, including 9,843 training models and 2,468 testing models. ModelNet10 contains 10 categories of 3D CAD models, with 3,991 training models and 908 testing models.Since the number of models varies across categories, we chose the overall accuracy OA (Uy et al., 2019; Equation 13) for each sample and the average accuracy AA (Zhai et al., 2020) (Equation 14) for each category as metrics to evaluate the classification performance. It is noteworthy that OA is the ratio of the number of correctly classified samples to the total number of samples, and AA is the average of the ratio of the number of correct predictions to the total number of predictions for each category. See Equations (13) and (14) for details.
OA=1N∑i=1cxii (13) AA=sum(recall)C (14)where N is the total number of samples, xii is the number of correct classifications, and C denotes the category of the dataset, and recall denotes the ratio of predictions to samples.
3.2. Experimental setup and analysisWe conducted our experiments using a computer with Windows 10, Inter 8700K CPU, 64 GB RAM, and the RTX2080 graphics card. In all experiments, our environment was set to PyTorch 1.2 (Paszke et al., 2017) and Cuda 10.0. The experiment was divided into two training phases. The first phase classified only a single view to enable fine-tuning of the model while removing the SoftPool attention convolution module. The second stage added SoftPool attention convolutional blocks to train all views of the 3D model, which was used to train the whole classification framework. We only performed test experiments in the second stage and set 20 epochs. We optimized the entire network architecture using the Adam (Zhang, 2018) optimizer. The initial learning rate and L2 regularization weight decay parameters were set to 0.0001 and 0.001, respectively, to accelerate model convergence and reduce model overfitting.
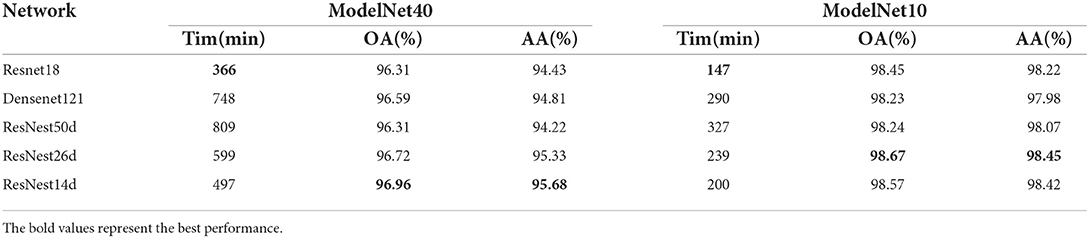
3.3. Impact of CNN on classification performanceA pretrained CNN is used as a backbone model to improve the performance of various tasks, e.g., classification and segmentation. To extract view feature information more quickly and effectively, we connected the SoftPool attention convolution module to the encoders, such as ResNet18 (He et al., 2016), Densenet121 (Huang et al., 2017), ResNest50d, ResNest26d, and ResNest14d, in the ModelNet40 and ModelNet10 datasets. The experimental results are shown in Table 1. On the ModelNet40, the whole network had the shortest training time when using ResNet18, while the network deepened and the training time prolonged when using DenseNet121 and ResNest50d. In particular, the training process of the ResNest50d network model took 809 min (312 min more than ResNest14d). Employing ResNest14d as the backbone model, the OA and AA metrics of the MVMSAN network reached 96.96% and 95.68%, respectively, achieving the best classification performance. Hence, we chose ResNest14d as the backbone model for extracting multi-view features.
Table 1. Effects of different backbone models on classification performance.
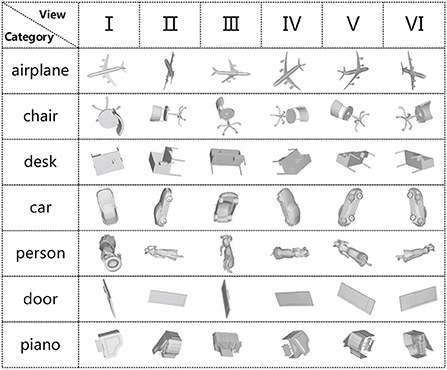
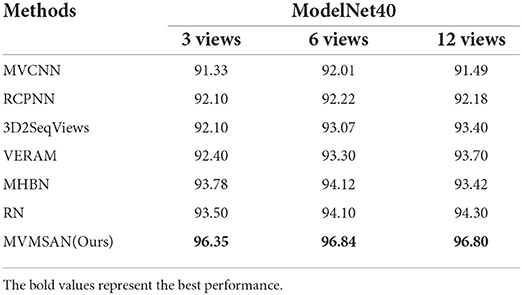
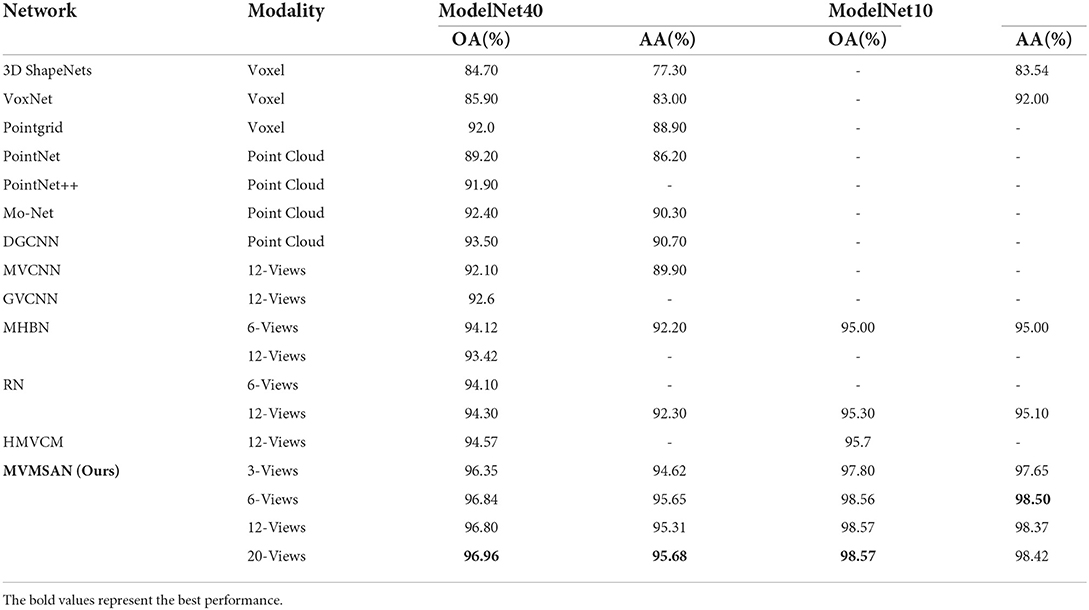
3.4. The effect of different number of views on classification performanceTo more intuitively observe the view feature information in different angles, we selected 2D views of seven different categories of 3D models for display. As shown in Figure 4, the view V in the piano category ignores the key feature information of the keys; therefore, if a single view is used for experiments, the loss of feature information will affect the classification accuracy. Multiple views can fuse the feature information of different views to make up for the loss of single view feature information. To further investigate the effect of the number of views on the model classification performance, we randomly selected 3, 6, and 12 views from the 20 views obtained from 20 viewpoint angles for each 3D model in experiments. At the same time, the classification performance of MVMSAN was also compared with other advanced methods [such as MVCNN (Su et al., 2015), RCPCNN (Wang C. et al., 2019), 3D2SeqViews (Han et al., 2019a), VERAM (Chen et al., 2019), MHBN (Yu et al., 2018), and RN (Yang and Wang, 2019)] under 3, 6, and 12 number of views. The experimental results are shown in Table 2.
Figure 4. Six views of different models.
Table 2. The effect of the number of views on classification performance.
On the ModelNet40 dataset, MVMSAN network outperformed other methods (such as MVCNN, RCPCNN, 3D2SeqViews, VERAM, MHBN, and RN). Compared with the RN network, our network improved OA by 3.0, 2.8, and 2.6% in each view configuration. In comparison with the classic MVCNN network, it improved by 5.2, 5.0, and 5.5%, respectively. From Table 2, we can see that the classification accuracy did not increase with the number of views; for example, our method achieved the best experimental results in six views. Meanwhile, it can be seen from the Table 2 that OA of our MVMSAN model can still reached 96.35, 96.84, and 96.80% in 3, 6, and 12 views. This experiment shows that our network has high robustness.
The high robustness achieved by the MVMSAN model is mainly attributed to our proposed SoftPool attention convolution method. SoftPool uses the processed view feature value as the Query value of the self-attended to obtain refined view feature information. Under any number of 1–20 views, these fine-grained view features can hold salient features related to model categories. Subsequent Mobile inverted bottleneck convolution (MBConv) can process the Query and Key of self-attentive, which significantly improve the generalization performance of MVMSAN model. The learning ability for our model also becomes stronger, so that it can achieve high classification accuracy with any number of 1–20 views.
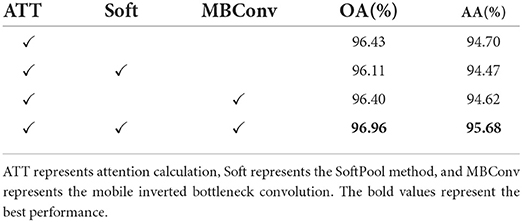
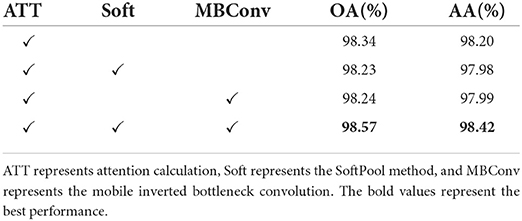
3.5. Ablation experimentsWe supplement a set of ablation experiments to demonstrate the generalization performance of SoftPool attentional convolution method proposed by us (see Tables 3, 4). The experimental results on the ModelNet40 dataset show that our proposed SoftPool attentional convolution method achieved the best classification performance on ModelNet40 (96.96% for OA and 95.68% for AA). The OA and AA obtained by applying only the output of SoftPool as the Query vector of attention were 96.11 and 94.47%, respectively, which were lower than those of the SoftPool attention convolution method. This is because the network model at this point is less generalizable, i.e., the classification ability learned by this network from the training set performs poorly. Adopting only MBConv to process the computational results of Query and Key of attention led to an insufficient feature extraction capability of the network. The loss of this feature information further reduced the classification accuracy (96.40 and 94.62% for OA and AA, respectively). We also obtained consistent experimental results on the ModelNet10 dataset (see Table 4).
Table 3. Ablation study (ModelNet40).
Table 4. Ablation study (ModelNet10).
It further proves that the best performance of the entire model can be achieved with the output result of SoftPool as the Query value of attention and MBConv to process the computational results of Query and Key of attention. It is worth noting that our algorithm can achieve 96.96% on OA and 95.68% on AA. The result is closely related to the refined feature extraction of SoftPool self-attention method and the model generalization enhancement of self-attention convolution method. The above two factors are indispensable.
We also employed a 1 × 1 convolution alternative to the fully connected layer that the network ends up using for classification. As shown in Table 5, the OA and AA using 1 × 1 convolution reached 96.96 and 95.68%, respectively, which is 0.17 and 0.48% improvement compared with fully connected layers. By using 1 × 1 convolution with fewer parameters, the training time in the same environment was also reduced by 27 min.
Table 5. Comparison of the effect of 1 × 1 convolution on classification performance.
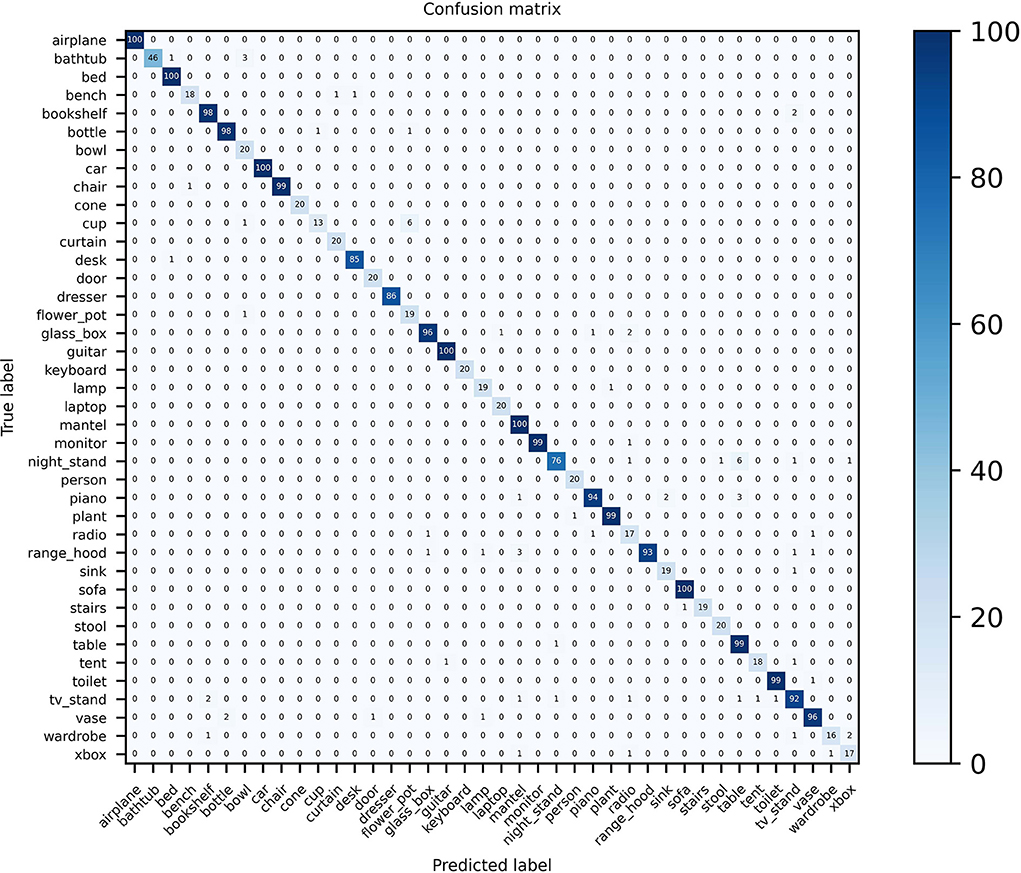
3.6. Confusion matrix visualizationConfusion matrix visualization can intuitively demonstrate the advanced performance of the MVMSAN method on the 3D model classification task. Especially in the case that some view features have high similarity, our method still has high classification prediction performance. We plot the confusion matrix on the ModelNet40 and ModelNet10 datasets. On ModelNet40, it can be seen from Figure 5 that MVMSAN achieved 100% classification accuracy on categories such as airplane, bed, sofa, and guitar. In some harder categories, such as night stand, table, and xbox, some views have high similarity. In this case, our MVMSAN model can also classify correctly. It can be seen from Figure 5 that 76 samples are correctly classified among the 86 the night stand models.
Figure 5. Confusion matrix visualization of MVMSAN on ModelNet40.
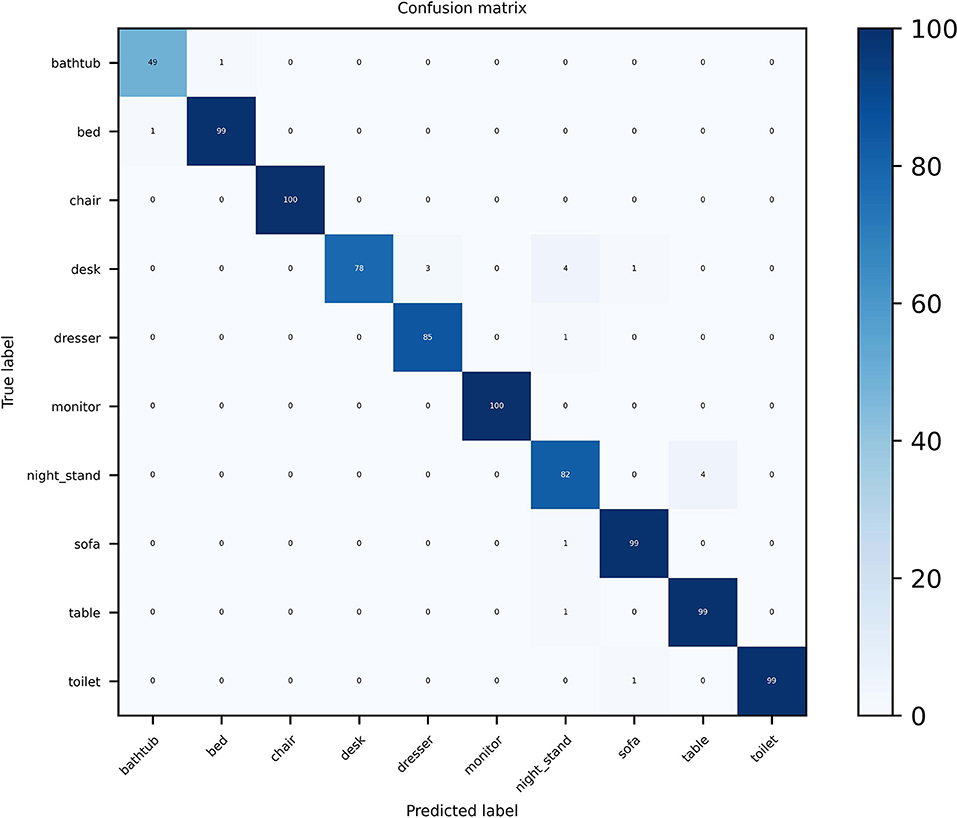
For the ModelNet10 dataset, it can be seen from Figure 6 that our MVMSAN also achieved 100% classification accuracy on the chair and monitor categories. In some views, desk, dresser, sofa and other 3D models have high similarity. The existing networks will confuse the feature information of 3D models and cause classification errors. However, our MVMSAN model still has high classification performance for this situation. For example, 78 samples are correctly classified among the 86 the desk models in Figure 6.
Figure 6. Confusion matrix visualization of MVMSAN on ModelNet10.
The data in the figure is enough to demonstrate the superiority of our approach on the model classification task. Especially for view features with high similarity, our network model is still able to achieve high classification prediction performance.
3.7. Comparison with other methodsWe compared the classification performance of voxel-based methods [3DShapeNets (Wu et al., 2015), VoxNet (Maturana and Scherer, 2015), and Pointgrid (Le and Duan, 2018)], point cloud-based methods [PointNet (Qi et al., 2017a), PointNet++ (Qi et al., 2017b), MO-Net (Joseph-Rivlin et al., 2019) and DGCNN (Wang Y. et al., 2019) and view-based methods [MVCNN (Su et al., 2015)], GVCNN (Feng et al., 2018), MHBN (Yu et al., 2018), RN (Yang and Wang, 2019), and HMVCN (Liu et al., 2021)]
As shown in Table 6, the proposed MVMSAN outperformed other deep learning methods. Compared with the most classical multi-view-based model classification method (MVCNN), MVMSAN improved OA and AA by 5 and 6%, respectively. Compared with the GVCNN, MHBN, and RN methods, MVMSAN showed considerable improvement. HMVCN is a recently proposed model classification method based on bidirectional LSTM, and its OA reached 94.57%. Our method achieved 2.5% higher OA compared to HMVCN. On the ModelNet10 dataset, the MVMSAN method also achieved the best classification performance (98.57% for OA and 98.42% for AA).
Table 6. Classification performance comparison with other methods.
The excellent performance of our MVMSAN method on the two ModelNet datasets is attributed to three factors: (1) ResNest removes the last fully connected layer and adds an adaptive pooling layer. It can prove that the relationship between view channels can increase the receptive field of view feature extraction, so that the network obtains more detailed features from the input data related to the output. (2) Using the output result of SoftPool as the Query vector of attention can realize the refined down-sampling processing of view feature information, and effectively solve the problem of insufficient extraction and loss of detailed information in the process of view feature extraction. (3) MBConv is employed to process the calculation results of Query and Key of attention. It can enhance the generalization of the model, thereby improving the classification accuracy.
4. ConclusionIn this paper, we proposed a multi-view SoftPool attention convolutional network framework, MVMSAN, for 3D model classification. The traditional method does not treat each view equally in the view feature extraction process, and only extracts the feature information that is considered important. This causes the problem of insufficient extraction of the view refinement feature information and loss. Our proposed SoftPool attention convolution framework could achieve refined down-sampling processing for all view features equally, thereby obtaining more useful information from the input data related to the output results, improving the generalization of the model, and achieving high-precision 3D model classification. To better evaluate our network framework, we conducted several experiments to validate the impact of each component of the framework. The experimental results demonstrate that our framework has achieved better classification accuracy on the ModelNet40 and ModelNet10 datasets compared to other advanced methods.
Data availability statementPublicly available datasets were analyzed in this study. This data can be found here: http://modelnet.cs.princeton.edu/.
Author contributionsWW and XW brought up the core concept and architecture of this manuscript. XW wrote the paper. GC and HZ corrected the sections of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
FundingThis study was supported by the Natural Science Foundation of Shanghai under Grant No. 19ZR1435900.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesAdikari, S. B., Ganegoda, N. C., Meegama, R. G., and Wanniarachchi, I. L. (2020). Applicability of a single depth sensor in real-time 3d clothes simulation: augmented reality virtual dressing room using kinect sensor. Adv. Hum. Comput. Interact. 2020, 1314598. doi: 10.1155/2020/1314598
CrossRef Full Text | Google Scholar
Chen, S., Zheng, L., Zhang, Y., Sun, Z., and Xu, K. (2019). Veram: view-enhanced recurrent attention model for 3D shape classification. IEEE Trans. Vis. Comput. Graph. 25, 3244–3257. doi: 10.1109/TVCG.2018.2866793
PubMed Abstract | CrossRef Full Text | Google Scholar
Dai, Z., Liu, H., Le, Q. V., and Tan, M. (2021). “Coatnet: marrying convolution and attention for all data sizes,” in Advances in Neural Information Processing Systems, Vol. 34, eds M. Ranzato, A. Beygelzimer, Y. Dauphin, P. Liang, and J. W. Vaughan (Montreal: Curran Associates, Inc.), 3965–3977
Feng, M., Zhang, L., Lin, X., Gilani, S. Z., and Mian, A. (2020). Point attention network for semantic segmentation of 3D point clouds. Pattern Recognit. 107, 107446. doi: 10.1016/j.patcog.2020.107446
CrossRef Full Text | Google Scholar
Feng, Y., Zhang, Z., Zhao, X., Ji, R., and Gao, Y. (2018). “Gvcnn: group-view convolutional neural networks for 3D shape recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Salt Lake City, UT: IEEE).
Grenzdörffer, T., Günther, M., and Hertzberg, J. (2020). “Ycb-m: a multi-camera rgb-d dataset for object recognition and 6D of pose estimation,” in 2020 IEEE International Conference on Robotics and Automation (ICRA) (Paris: IEEE), 3650–3656.
Han, Z., Lu, H., Liu, Z., Vong, C.-M., Liu, Y.-S., Zwicker, M., et al. (2019a). 3d2seqviews: aggregating sequential views for 3d global feature learning by cnn with hierarchical attention aggregation. IEEE Trans. Image Process. 28, 3986–3999. doi: 10.1109/TIP.2019.2904460
PubMed Abstract | CrossRef Full Text | Google Scholar
Han, Z., Shang, M., Liu, Z., Vong, C.-M., Liu, Y.-S., Zwicker, M., et al. (2019b). Seqviews2seqlabels: learning 3D global features via aggregating sequential views by rnn with attention. IEEE Trans. Image Process. 28, 658–672. doi: 10.1109/TIP.2018.2868426
PubMed Abstract | CrossRef Full Text | Google Scholar
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Las Vegas, NV: IEEE).
PubMed Abstract | Google Scholar
Hu, Q., Yang, B., Xie, L., Rosa, S., Guo, Y., Wang, Z., et al. (2020). “Randla-net: efficient semantic segmentation of large-scale point clouds,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Seattle, WA: IEEE).
PubMed Abstract | Google Scholar
Huang, G., Liu, Z., van der Maaten, L., and Weinberger, K. Q. (2017). “Densely connected convolutional networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Honolulu, HI: IEEE).
Joseph-Rivlin, M., Zvirin, A., and Kimmel, R. (2019). “Momen(e)t: Flavor the moments in learning to classify shapes,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops (Seoul: IEEE).
Kanezaki, A., Matsushita, Y., and Nishida, Y. (2018). “Rotationnet: joint object categorization and pose estimation using multiviews from unsupervised viewpoints,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Salt Lake City, UT: IEEE).
Kästner, L., Frasineanu, V. C., and Lambrecht, J. (2020). “A 3D-deep-learning-based augmented reality calibration method for robotic environments using depth sensor data,” in 2020 IEEE International Conference on Robotics and Automation (ICRA) (Paris: IEEE), 1135–1141.
Lalonde, J., Unnikrishnan, R., Vandapel, N., and Hebert, M. (2005). “Scale selection for classification of point-sampled 3D surfaces,” in Fifth International Conference on 3-D Digital Imaging and Modeling (3DIM'05) (Ottawa), 285–292.
Le, T., and Duan, Y. (2018). “Pointgrid: a deep network for 3D shape understanding,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Salt Lake City, UT: IEEE).
Liang, Z., Yang, M., Deng, L., Wang, C., and Wang, B. (2019). “Hierarchical depthwise graph convolutional neural network for 3D semantic segmentation of point clouds,” in 2019 International Conference on Robotics and Automation (ICRA) (Montreal), 8152–8158.
Liu, A.-A., Zhou, H., Nie, W., Liu, Z., Liu, W., Xie, H., et al. (2021). Hierarchical multi-view context modelling for 3D object classification and retrieval. Inf. Sci. 547, 984–995. doi: 10.1016/j.ins.2020.09.057
CrossRef Full Text | Google Scholar
Liu, C.-H., Lee, P., Chen, Y.-L., Yen, C.-W., and Yu, C.-W. (2020). Study of postural stability features by using kinect depth sensors to assess body joint coordination patterns. Sensors 20, 1291. doi: 10.3390/s20051291
PubMed Abstract | CrossRef Full Text | Google Scholar
Ma, C., Guo, Y., Yang, J., and An, W. (2019). Learning multi-view representation with lstm for 3D shape recognition and retrieval. IEEE Trans. Multimedia 21, 1169–1182. doi: 10.1109/TMM.2018.2875512
CrossRef Full Text | Google Scholar
Ma, Y., Guo, Y., Lei, Y., Lu, M., and Zhang, J. (2018). “3dmax-net: a multi-scale spatial contextual network for 3D point cloud semantic segmentation,” in 2018 24th International Conference on Pattern Recognition (ICPR) (Beijing), 1560–1566.
Maturana, D., and Scherer, S. (2015). “Voxnet: a 3D convolutional neural network for real-time object recognition,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Hamburg: IEEE), 922–928.
Niemeyer, J., Rottensteiner, F., and Soergel, U. (2014). Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogram. Remote Sens. 87, 152–165. doi: 10.1016/j.isprsjprs.2013.11.001
CrossRef Full Text | Google Scholar
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., et al. (2017). Automatic differentiation in pytorch.
Pontes, J. K., Kong, C., Eriksson, A. P., Fookes, C., Sridharan, S., and Lucey, S. (2017). Compact model representation for 3D reconstruction. CoRR, abs/1707.07360. doi: 10.1109/3DV.2017.00020
CrossRef Full Text | Google Scholar
Qi, C. R., Su, H., Mo, K., and Guibas, L. J. (2017a). “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Honolulu: IEEE).
Qi, C. R., Yi, L., Su, H., and Guibas, L. J. (2017b). “Pointnet++: deep hierarchical feature learning on point sets in a metric space,” in Advances in Neural Information Processing Systems, Vol. 3, eds I. Guyon, U. Luxburg, V. S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Long Beach, CA: Curran Associates, Inc.).
Qiu, S., Anwar, S., and Barnes, N. (2021). “Dense-resolution network for point cloud classification and segmentation,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (Waikoloa: IEEE), 3813–3822.
Riegler, G., Osman Ulusoy, A., and Geiger, A. (2017). “Octnet: learning deep 3d representations at high resolutions,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Honolulu, HI: IEEE).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and Chen, L.-C. (2018). “Mobilenetv2: inverted residuals and linear bottlenecks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Salt Lake City, UT: IEEE).
Stergiou, A., Poppe, R., and Kalliatakis, G. (2021). “Refining activation downsampling with softpool,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (Montreal: IEEE), 10357–10366.
Su, H., Maji, S., Kalogerakis, E., and Learned-Miller, E. (2015). “Multi-view convolutional neural networks for 3D shape recognition,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Santiago: IEEE).
PubMed Abstract | Google Scholar
Sun, K., Zhang, J., Liu, J., Yu, R., and Song, Z. (2021). Drcnn: dynamic routing convolutional neural network for multi-view 3D object recognition. IEEE Trans. Image Process. 30, 868–877. doi: 10.1109/TIP.2020.3039378
留言 (0)