
記住我





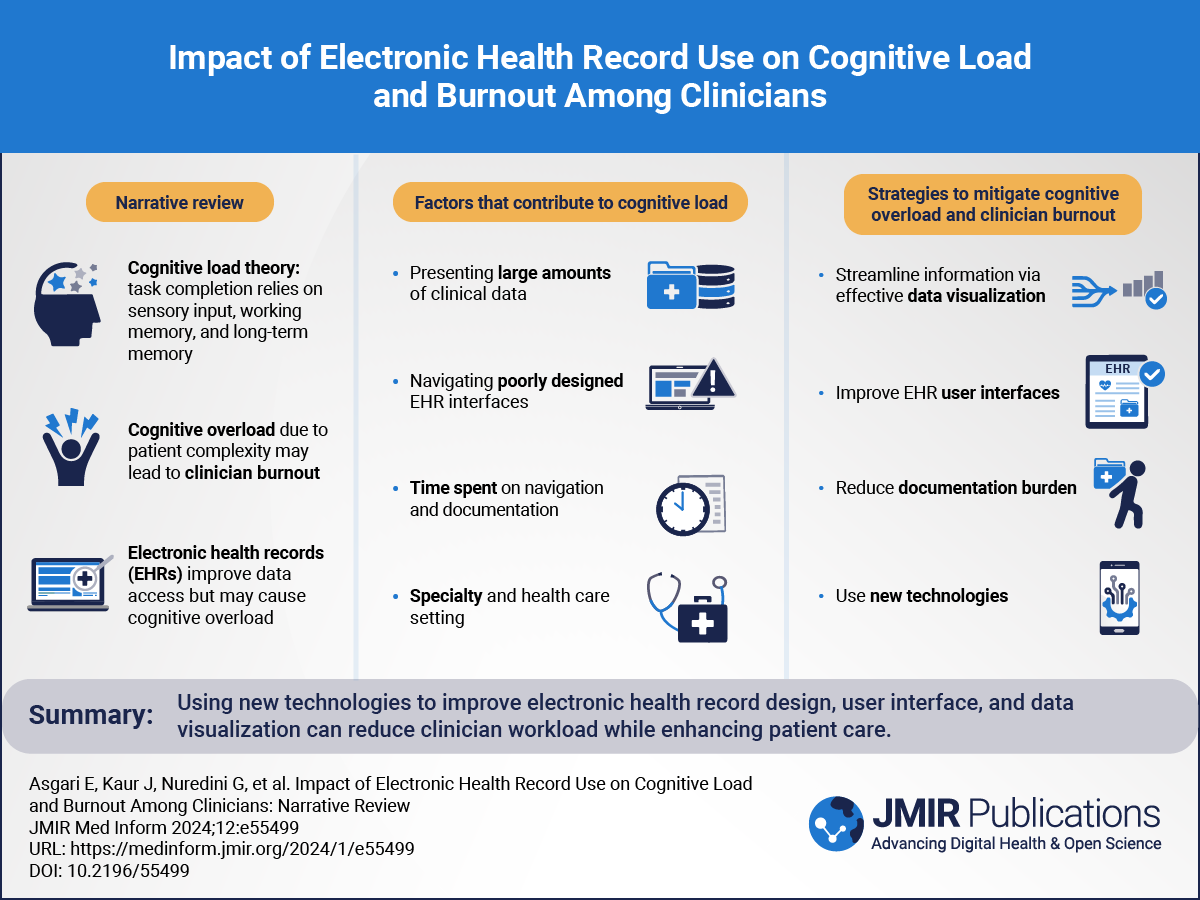



Recent innovations in natural language processing (NLP) techniques and software have resulted in the emergence of numerous conveniently accessible and open-source analytical tools for the efficient evaluation of free-text data [-]. Textual data constitute a rich source of information, allowing the capture of unique perspectives, experiences, and individual needs through a broad range of different sources of information (eg, health-related content and emotional tone) [,]. While larger positive emotion vocabulary is linked to more mental well-being and better physical health, larger negative emotion vocabulary is associated with distress and decreased physical health [].
In health research, the increasing availability of “real-world data” in the form of, for example, written text, constitutes a promising avenue to gain valid insights into themes that concern persons with chronic diseases in everyday life and thus are key to tailor individual support [-]. Many studies rely on interview techniques to gain such insights [-]. While conducting interviews represents the “gold standard” for gaining qualitative insights into individual experiences and perspectives, they may not always be feasible to assess individuals on a large scale. Scalable methods, which are very well suited for standardized quantitative assessments, may instead miss important information because they consist of predetermined items. Surveys that include open-ended text assessments can therefore be an appropriate way to qualitatively explore individual-level experiences and perspectives on a large scale in real-world environments.
Concurrently, practical guidelines for applied researchers concerning processing and evaluation procedures for textual information at a magnitude that is not feasible for manual analyses seem to be lacking. Given the novelty of the NLP method in the field of health research, we aim to share our work and experience in this manuscript to support applied researchers in implementing the NLP method in their own research. Therefore, the high-level aims of this study pertain to the investigation of the feasibility, usability, and scientific value of an NLP pipeline applied to the exploration of important life topics and themes in a large sample of persons with multiple sclerosis (MS) collected during a major health crisis. This study aims to provide practical guidance for applied researchers and leverages textual data from 639 well-documented persons with MS who described their live experiences during the first COVID-19 lockdown in Switzerland, as well as the availability of easy-to-use open-source tools for NLP.
At the content level, we addressed several specific research questions. We aimed to (1) identify cluster groups of persons with MS based on reported COVID-19–related topics; (2) determine the emotional tone underlying participants’ text entries; and (3) describe persons allocated to the same cluster group. For validation purposes, our analysis results were complemented by including independently collected information from the same database and a critical review by experts from the clinical or epidemiological research field.
As laboratory-confirmed SARS-CoV-2 infections increased to up to almost 1500 cases daily (population size: 8.6 million inhabitants), the Swiss government implemented an initial lockdown between March 16 and April 27, 2020, to flatten the infection curve. On April 27, 2020, hairdressers, garden centers, flower shops, building supplies stores, and massage and beauty salons could reopen. In addition, entry requirements had been relaxed. On May 11, 2020, shops, restaurants, markets, libraries, and primary and secondary schools were reopened. The relaxations were accompanied by protection concepts. At the beginning of June 2020, all tourist facilities could open in compliance with protection measures. Events with up to 300 people could be held again, and gatherings with a maximum of 30 people were allowed again. On June 15, 2020, Switzerland lifted the entry regulations concerning all European Union/European Free Trade Association states and the United Kingdom. On June 19, 2020, the Swiss Federal Council lifted the state of emergency. Most COVID-19 measures were lifted from June 22, 2020 (exception: large events with over 1000 people remained forbidden until the end of August 2020). All places open to the public needed to have a protection concept [,]. This first lockdown in Switzerland due to the COVID-19 pandemic resulted in pervasive and high levels of distress and isolation in the general population. These repercussions had a disproportionate effect on vulnerable subgroups of the population already burdened with pre-existing chronic diseases, such as MS. During the early stages of the pandemic, MS was also considered a risk factor for more severe COVID-19 symptoms, and persons with MS were advised to strictly adhere to preventive measures (ie, staying at home and keeping physical distance). At the end of April 2020, the lockdown measures were gradually lifted.
Data SourcesTo assess the impact of the lockdown on the everyday lives of persons with MS, the Swiss MS Registry conducted a COVID-19–focused online survey among its over 2500 participants (). The Swiss MS Registry is a nationwide survey-based registry encompassing adults with MS who reside in or receive MS-related care in Switzerland.
 Figure 1. Flow diagram displaying the assessment procedure and subsequent selection procedure for online participants. Only online participants who described the experienced impact of COVID-19 on their personal life with at least 10 words were included in the text analysis. View this figure
Figure 1. Flow diagram displaying the assessment procedure and subsequent selection procedure for online participants. Only online participants who described the experienced impact of COVID-19 on their personal life with at least 10 words were included in the text analysis. View this figureThe “COVID-19 survey” was a brief online survey released by the Swiss MS Registry in response to the lockdown measures for the first wave, which assessed mental well-being and difficulties in accessing health care in times of COVID-19. The complete survey is provided in . The COVID-19 survey starts with a short introduction, followed by a section on mental well-being, in which depressive symptoms are assessed using the Beck Depression Inventory FastScreen questionnaire []. This is followed by an assessment of physical well-being (ie, possible worsening of health or MS symptoms), fear of the presence of a serious illness (eg, coronavirus) in addition to MS, and perceived loneliness. The survey finally assesses general changes in individuals’ life situations due to the coronavirus. The open question, which is analyzed in the present, concerned the pandemic’s perceived impact on respondents’ daily lives. Specifically, participants were asked the following question: “How does the current coronavirus situation affect your personal life (eg, in terms of social contacts, everyday tasks, and health care provision)?” Participants were invited to document their answers without a maximum word limit in either German, French, or Italian (ie, the 3 official languages of the Swiss MS Registry). The COVID-19 survey was released online on April 10, 2020, and remained accessible until October 31, 2020. The current analysis includes all data collected until September 7, 2020.
For this study, the COVID-19 survey data were combined with sociodemographic and health-related data collected as part of the semiannual Swiss MS Registry assessments preceding the COVID-19 survey. Specifically, we employed the Self-Reported Disability Status Scale (SRDSS) to determine MS physical gait impairments. In this regard, the SRDSS classifies gait impairments based on 2 self-report questions that assess walking distance and the use of assistance devices []. Further, we determined health-related quality of life using the EuroQol 5-dimension scale (EQ-5D; index and visual analog scale) [].
Ethics ApprovalApproval has been obtained from the Cantonal Ethics Committee Zurich (PB-2016-00894). All participants enrolled in the Swiss MS Registry provided written (paper-pencil participants) or electronic (online participants) informed consent [,].
Descriptive StatisticsTo characterize and compare online participants from the Swiss MS Registry participating in the COVID-19 survey with nonparticipants, sociodemographic and health characteristics were analyzed by means of N (%) for categorical data and medians (IQR) for continuous data. Descriptive statistics were based on the brief entry questionnaire, which is mandatory for all Swiss MS Registry participants and includes information on age, sex, MS type, diagnosis date, and any disease-modifying treatments.
Preprocessing and Analysis Pipeline for Free-Text EntriesThis research implemented and evaluated a preprocessing and analysis pipeline to characterize and cluster free-text entries. To this end, we applied this pipeline to free-text entries about the impact of COVID-19 on the everyday lives of persons with MS. The entries were collected as part of the Covid-19 survey. The text preprocessing and analysis pipeline to be examined in this research consists of the following 5 interlinked consecutive steps: (1) text preprocessing; (2) descriptive text analysis; (3) sentiment analysis; (4) topic modeling; and (5) results interpretation and validation. An overview of the tools used in each step of the NLP pipeline can be found in .
Step 1: Text PreprocessingAs the first step of the preprocessing procedure, Italian and French texts were translated into German using “DeepL Pro” [], a tool for automatic text translation. Initially, we specified a cutoff for the minimum number of words for a text entry to be considered in the subsequent pipeline. As there are no generally valid guidelines applicable for our research in this regard, we based our decision on prior screening of the text entries and determined 10 words as cutoff to ensure sufficient informative content for the research question that we were interested in. Translation accuracy was checked manually and found to be very high. Further, punctuations and stop words (ie, common words without specific meaning like “the”) were removed using a publicly available German stop word list []. The remaining words were lemmatized (ie, changed to their root such as “studies” to “study”). Words not listed in dictionaries were converted into generic terms (eg, “Skype” to “video call”). This part of the pipeline was implemented using the Python library “spaCy” (version 2.3.2) [].
Step 2: Descriptive Text AnalysesThe second step of the pipeline concerned descriptive text analyses that involved determination of word frequencies as well as their visualization. For word frequency visualization, “word clouds” were compiled, which position all words into a graph where their relative size is determined by their overall frequency (ie, more frequent words are displayed larger in the plot) using the Python library “Wordcloud” (version 1.7.0) [].
Step 3: Sentiment AnalysisThe next step in pipeline pertained to the determination of linguistic indicators of overall text emotionality through sentiment analysis. To this end, 2 different text analysis resources were used: the well-established text analysis software “Linguistic Inquiry and Word Count” (LIWC) and further “SentimentWortschatz” (short “SentiWS”), a publicly available German-language resource for sentiment analysis. Sentiment analysis implemented in LIWC involved determining the text entries’ overall “emotional tone.” [] “Emotional tone” is a summary variable provided by LIWC and represents the overall emotional coloration of a text. Scores range from 0 (negative tone) to 100 (positive tone), where a score of 50 indicates an even balance between positive and negative emotion words. Furthermore, we quantified text-based emotionality through “polarity scores” using the SentimentWortschatz sentiment-analysis resource (“SentiWS”) []. Polarity scores computed by SentiWS assess whether a word has a positive or negative connotation, ranging between −1 and 1. They are computed through a dictionary-based scoring algorithm that identifies words reflecting a negative or positive emotion. The SentiWS dictionary does not contain any polarity “shifters” or “intensifiers,” that is, words with an amplifying function, which weaken, intensify, or even reverse the meaning of an emotional word (eg, “not happy” or “very happy”). Since such amplifying words are key to accurately determine the polarity of a sentence, a German-language extension dictionary was used.
Step 4: Unsupervised Machine Learning–Topic ModelingThe final step of the pipeline concerns the implementation of “topic modeling,” which is an unsupervised text classification method with the aim to identify distinct clusters of common topics underlying free text (ie, underlying participants’ text entries) []. To determine distinct topic clusters, we implemented nonnegative matrix factorization, which is a topic modeling approach based on dimension reduction. Such dimension-reduction models are based on understanding a text corpus as a compilation of term frequencies. Nonnegative matrix factorization is based on a “bag of words” model, where text elements are represented in an unordered fashion. We further worked with unigrams, which means that each word corresponds to a text element (contrary to, for example, a bigram where a text element consists of 2 consecutive words). The reason for this methodological decision is that the majority of the words in the present data are meaningful in themselves in terms of co-occurrence and frequency.
We implemented this step using the Python libraries “scikit-learn” and “gensim” [,]. To determine the most suitable solution in terms of the number of distinct topics, we used the commonly used coherence score “C_v” as a criterion. “C_v” ranges from 0 (no topic coherence) to 1 (complete topic coherence). “C_v” scores for a modeling solution with 1 to 30 distinct topics are presented in . We also computed the coherence score “UMass” but based the final topic modeling solution on “C_v” as it has been shown to be more appropriate for text data consisting of few words []. For sensitivity purposes, we repeated our analysis based on all available entries (ie, without word count restriction) in order to verify that topic clusters were stable.
Step 5: Results Interpretation and ValidationFinally, we labeled each of the distinct topic clusters with the term that occurred most often within the specific topic cluster. To further characterize individuals allocated to the distinct topic clusters, we compared independently collected sociodemographic measures across the groups through descriptive analyses. Given the descriptive nature of this research, we present 95% CIs instead of P values. We further linked emotional tone to the SRDSS score and years since diagnosis, which were both assessed as part of the previous biannual registry surveys. We also calculated the associations between emotional tone and the occurrence of new symptoms, the worsening of old symptoms, the presence of depressive symptoms, and the feeling of loneliness. For associations between interval-scaled variables, we calculated the Pearson correlation coefficient. For associations with ordinal variables, we computed the Spearman correlation coefficient. For correlations between interval-scaled and binary variables, we calculated the biserial point correlation coefficient. All associations were computed using the R package “psych” []. CIs for the Spearman correlation coefficient were computed using the R package “DescTools” []. Finally, the findings were critically reviewed by a team of experts coauthoring this study. The experts’ backgrounds and specialist knowledge include neurology, neuropsychology, and epidemiology, as well as a personal health history of MS.
A total of 885 Swiss MS Registry participants (44.5% of all participants) completed a questionnaire pertaining to COVID-19 (). As presented in , COVID-19–related survey respondents had a median age of 48 years, 70.3% (622/885) were female, and 67.9% (601/885) had relapsing-remitting MS (that is, with intermittent recovery of acute MS symptoms as opposed to continuously worsening primary and secondary progressing MS). Overall, participants who completed the COVID-19 survey were similar to nonparticipants (n=1149) in terms of their baseline characteristics (median age 47 years, 72.6% [834/1149] female, and 66.9% [769/1149] relapsing-remitting MS). From the overall sample of available survey responses (n=885; study flow chart provided in ), this study focused on entries of at least 10 words (n=639; A). As there are no generally valid guidelines applicable for our research in this regard, we based our decision on prior screening of the text entries and determined 10 words as cutoff to ensure sufficient informative content for the research question that we were interested in. From this data source, 639 entries were used for the text analyses in this study.
The following sections describe the results obtained from the text preprocessing and analysis pipeline, which was applied to a sample of 639 COVID-19–related text entries provided by the Swiss MS Registry participants. The rationale for the methodological decisions of this study is provided in the Methods section.
Table 1. Description of Swiss Multiple Sclerosis Registry online participants and nonparticipants.CharacteristicaNonparticipants (did not complete the COVID-19 survey; N=1149)Participants (completed the COVID-19 survey; N=885)AgeaPercentages were rounded and may thus not add up to 100%.
bMS: multiple sclerosis.
cCIS: clinically isolated syndrome.
dPPMS: primary progressive MS.
eRRMS: relapsing-remitting MS.
fSPMS: secondary progressive MS.
gVAS: visual analog scale.
hQLS: quality of life scale.
iEQ-5D: EuroQol 5-dimension scale.
 Figure 2. Survey responses included in this study. (A) Histogram depicting the text entries of different word lengths on the self-reported daily-life impact of COVID-19 (n=885). The number of words per text entry are plotted along the y-axis. (B) Amount of completed surveys across time (April 8, 2020, to August 27, 2020). Overall, 86.9% (555/639) of the responses were collected during the first lockdown (ie, before April 27, 2020). The number of completed surveys is displayed on the y-axis. Time (ie, days) is plotted along the x-axis. View this figureDescriptive Text Analyses
Figure 2. Survey responses included in this study. (A) Histogram depicting the text entries of different word lengths on the self-reported daily-life impact of COVID-19 (n=885). The number of words per text entry are plotted along the y-axis. (B) Amount of completed surveys across time (April 8, 2020, to August 27, 2020). Overall, 86.9% (555/639) of the responses were collected during the first lockdown (ie, before April 27, 2020). The number of completed surveys is displayed on the y-axis. Time (ie, days) is plotted along the x-axis. View this figureDescriptive Text AnalysesAmong all text responses used in this study, 86.9% (555/639) were collected during the first lockdown (before April 27, 2020; B). In total, 80.1% (512/639) of these text entries were in German, 16.0% (102/639) in French, and 3.9% (25/639) in Italian. The median number of words per entry was 26 (IQR 16-44; following translation to German if necessary). visualizes the 15 most frequent keywords across the sample of text entries examined in this research. The most frequent words were “contact” (n=621), “errand” (n=364), “family” (n=307), “work” (n=307), and “home” (n=220).
 Figure 3. Most frequent keywords across free-text descriptions on participants’ perceived impact of COVID-19 on their personal life. Only text entries with at least 10 words in total were considered (n=639). “Stop words” (eg, “and” and “the”) were removed prior to the analysis. View this figureSentiment Analysis
Figure 3. Most frequent keywords across free-text descriptions on participants’ perceived impact of COVID-19 on their personal life. Only text entries with at least 10 words in total were considered (n=639). “Stop words” (eg, “and” and “the”) were removed prior to the analysis. View this figureSentiment AnalysisThe possible full range of emotional tone of text entries ranged from 0 (negative) to 50 (neutral) up to 100 (positive). The mean emotional tone of participants’ text entries was 34.7 (SD 37.7), thus reflecting an overall negative emotional tone. The distribution of emotional tone quartiles (1st quartile: 0-24; 2nd quartile: 25-49; 3rd quartile: 50-74; 4th quartile: 75-100) revealed that most of the 639 entries fell into the 1st quartile and thus were of overall negative quality (439/639, 68.7%). Importantly, most of the remaining text entries fell into the 4th quartile and thus were unambiguously of positive quality (160/639, 25.0%), while only few text entries were allocated to the intermediate quartiles (2nd quartile: 7/639, 1.1%; 3rd quartile: 33/639, 5.2%). The skewed distribution of the emotional tone of the participants’ text entries explains the large standard deviation.
In terms of changes in COVID-19 measures across time, the average emotional tone across text entries did not differ during the lockdown (April 6 to 27; n=555; mean 35.32, SD 37.98; 95% CI 32.16-38.48) compared to the period during which restrictive measures were gradually lifted (April 28 to September 07; n=84; mean 30.58, SD 35.68; 95% CI 22.95-38.21).
Text-based polarity scores (ranging from −1 to 1) were comparable to those for emotional tone. Polarity scores were of overall negative valence (mean −0.10, SD 0.65), and 38.8% (248/639) of the entries had a polarity score below 0. Polarity scores based on text entries collected during first lockdown did not differ from those based on text entries collected during the time when measures were eased (following the lockdown; mean −0.13, SD 0.62).
Unsupervised Learning–Topic ModelingFinally, the 639 text entries were grouped into distinct clusters through an unsupervised topic modeling procedure. Results revealed that a 4-group solution would be most suitable for the data structure. A word cloud visualizing the most frequent keywords related to the impact of COVID-19 on participants’ personal lives across the complete study sample can be found in . Word clouds for the 4 distinct topic groups are provided in . The 4 distinct “topic groups” were labeled with the most frequent keywords (group 1: “contacts/communication,” group 2: “social environment,” group 3: “work,” and group 4: “errands/daily routines”). A table characterizing the 4 distinct “topic groups” is provided in . Text entries that were allocated to the “contacts/communication” group (group 1; 14.6% [119/639] of all text entries) captured how persons with MS experienced the contact restrictions. One of the most frequent words in this topic group was “miss.” Importantly, text entries allocated to this group were of increasingly negative polarity. On the other hand, polarity scores in the “social environment” group (group 2; 21.4% [174/639] of all entries) and “work” group (group 3; 17.9% [146/639] of all entries) were more balanced. Finally, the “errands/daily routines” group (group 4; 24.5% [200/639] of all entries) included keywords that reflected daily routines (eg, “errands” and “going for a walk”). This group included the largest percentage of positive polarity scores (56.5%, 113/200). Repetition of the topic modeling analyses using all available text entries consistently found modeling 4 topic clusters to be ideal.
 Figure 4. Word cloud visualizing the most frequent keywords related to the impact of COVID-19 on participants’ personal lives across the complete study sample. Word size reflects the relative frequency of a specific word in comparison to the total number of analyzed words. Only text entries with at least 10 words in total were considered (n=639). View this figureSociodemographic and Health Characteristic Profiles
Figure 4. Word cloud visualizing the most frequent keywords related to the impact of COVID-19 on participants’ personal lives across the complete study sample. Word size reflects the relative frequency of a specific word in comparison to the total number of analyzed words. Only text entries with at least 10 words in total were considered (n=639). View this figureSociodemographic and Health Characteristic ProfilesAdditionally, we examined whether different sociodemographic and health characteristics were linked to distinct topic groups. The “contacts and communication” topic group tended to be older (median age: 49.5 years), live alone (27.7%, 33/119), be employed (second most; 63.9%, 76/119), and have lower levels of ambulatory disability (ie, persons who can move around without walking aids as measured with the self-reported disability scale [SRDSS], scores ranging between 0 and 3.5; 76.5%, 91/119). This group also reported the second highest health-related quality of life (median visual analog scale score: 80). Individuals allocated to the “social environment” topic group were more likely to have children (highest percentage; 50.6%, 88/174) who were typically under 18 years old (27.0%, 47/174). Further, pronounced mobility restrictions (ie, SRDSS scores greater than 3.5, thus requiring walking aids such as crutches or a wheelchair) were more frequent in this group, while health-related quality of life was comparatively lower (median EQ-5D: 0.65; median visual analog scale score: 75). Individuals allocated to the “work” topic group were most often employed compared to individuals in the other 3 topic groups (87.0%, 127/146), had SRDSS scores in the 0-3.5 range (highest proportion; 82.2%, 120/146), and had overall good quality of life (median EQ-5D index: 0.75; median visual analog scale score: 81). The “errands/daily routines” topic group had the most number of female research volunteers (79.0%, 158/200) and the highest proportion of persons on disability benefits (36.5%, 73/200). Quality of life in this group was higher as indicated by the visual analog scale (median score: 81). Finally, we examined the characteristics of online participants whose text entries had to be excluded as they were too short (n=176 entries). Individuals whose text entries had to be excluded were comparable to those of topic group 2 in terms of their sociodemographic characteristics (data not shown). Notably, the 3 most frequent keywords in the excluded entries (ie, “contacts,” n=64; “errands,” n=13; and “work,” n=10) were also present in the 4 topic groups.
We further examined whether emotional tone was linked to measures of physical or mental well-being. Emotional tone was not linked to the SRDSS score (rho=−0.02, 95% CI −0.09 to 0.06; S=39575496, P=.69) or the number of years since the initial MS diagnosis (r=−0.03, 95% CI −0.11 to 0.05; t628=−0.68333; P=.49). It was also not linked to the occurrence of new symptoms (r=−0.04, 95% CI −0.12 to 0.03; t633=−1.121; P=.26) or the worsening of new symptoms (r=−0.07, 95% CI −0.14 to 0.01; t636=−1.67; P=.09). However, emotional tone was significantly correlated with the presence of depressive symptoms (r=−0.10, 95% CI −0.19 to −0.02; t627=−2.49; P=.01) and feelings of loneliness (r=−0.12, 95% CI −0.18 to −0.02; t630=−2.92; P=.004). For all measures, less than 4% of the values were missing.
Here, we illustrate the application and subsequent evaluation of an NLP pipeline for the analysis of free-text data. Specifically, we applied this pipeline to text data on the experienced impact of the first COVID-19 lockdown from the perspectives of persons with MS collected by the Swiss MS Registry. Our study thus sheds light on individual daily-life experiences of the first COVID-19 lockdown in a vulnerable population.
In this study, we demonstrated both the feasibility and scientific value of an automated text preprocessing and NLP analysis pipeline based on existing open-source software in Python suitable for large-scale text data. The pipeline allows to preprocess real-world text data in an efficient fashion and to conduct timely and innovative analyses, including unsupervised machine learning. In light of a dearth of practical guidance for such real-world text data preprocessing and analysis procedures suitable for applied researchers, this pipeline has the potential to contribute to the dissemination of methodological knowledge, allowing to tap the potential of free-text data to capture individual perspectives and needs in health research. This study is embedded into the Swiss MS Registry, which is a large-scale well-documented longitudinal study. The registry’s data thus constitute an optimal use case for the application and evaluation of such a pipeline and the broad range of available data sources allowed that characterize individuals allocated to the distinct topic cluster groups in terms of specific characteristics. This study demonstrates the potential of open-ended questions in complementing traditional standardized assessment methods to capture unexplored information from individuals’ own words and thereby may spark new hypotheses and future avenues in health research. This type of language processing would essentially constitute a synergy between structured data collection and other forms of qualitative assessments, which tend to be more time-consuming in terms of processing and analysis (eg, interviews). Real-world data are afflicted with a broad range of challenges (eg, typos and dialect), which need elaborate consideration through text preprocessing to ensure the validity of subsequent complex analyses. Our study is thus timely and innovative in nature given its focus on key challenges when leveraging text data sources originating from a real-world setting through an efficient pipeline programmed in Python.
In terms of individual experiences of the first COVID-19 lockdown, the themes that concerned persons with MS most during the first COVID-19 lockdown differed substantially across study participants. Specifically, our study identified the following 4 distinct COVID-19–related topic groups, which participants could be assigned to based on their experiences: “contacts/communication” (group 1); “social environment” (group 2); “work” (group 3); and “errands/daily routines” (group 4). It is important to mention that between-group comparisons of sociodemographic and health-related characteristics corroborate the disparity of the 4 topic groups. This new topic-based approach to characterize persons with MS provides a novel perspective on individual experiences of the first COVID-19 lockdown and further highlights heterogeneity in terms of individual needs. To the best of our knowledge, there are no comparable in-depth studies researching the individually perceived impact of COVID-19 using participants own words. With regard to the overall emotional tone underlying the text entries, our findings revealed that most text entries reflected negative emotional states. This adds to research emphasizing the high burden of COVID-19–related restrictions for persons with MS given their prior vulnerability []. Further, from a methodological perspective, the context of our study was ideal for the identification of distinct topic commonalities of wide-ranging relevance as the spectrum of topics that participants were concerned with was confined. On the contrary, studies researching mundane everyday life situations of persons with MS are likely to identify considerably more diverse topics (with smaller population sizes per topic group), which results in the necessity of more data and participants, as suggested by an ongoing analysis of health diary entries collected before the COVID-19 pandemic from the same study population (manuscript in preparation).
In parallel with this finding, the 4 topic groups also differed in terms of the emotional tone underlying their text descriptions. It is important to mention that the emotional tone was determined through an independent analysis approach (sentiment analysis). A correlation analysis revealed that emotional tone was not associated with MS traits or measures of physical well-being, but with psychological well-being in the form of depressive symptoms and feelings of loneliness. This result suggests that “emotional tone” in this study primarily reflects emotions that are directly related to the content of the text and the individual’s situation. The most negative entries occurred in topic groups whose text entries predominately pertained to contacts and communication themes (group 1). In the topic groups concerning social environment (group 2) and work (group 3), the underlying emotional tone was more balanced, while in the topic group pertaining to errands and daily routines (group 4), the entries’ emotional tone was predominantly positive. This observed heterogeneity in emotional tonality underlying the reported experiences of the first COVID-19–related lockdown is likely to reflect differences in emotional burden, individual circumstances, and ways of coping with the pandemic, which is in line with previous research in this matter. For instance, a US telephone survey on persons with MS conducted during the first lockdown found that a higher perceived impact of the pandemic on individuals’ self-reported psychological well-being was linked to a higher impact of MS symptoms on individuals’ daily lives. Further, by conducting interviews, a recent study found that persons reporting no or even a positive impact of the pandemic on their lives tended to cope with the pandemic situation with active problem-focused strategies [-]. In terms of personal values, however, another study examining young persons with MS also reported perceived positive effects of the pandemic situation in the form of personal, relational, and existential growth []. Accordingly, participants allocated to the “contacts and communication” topic group made the highest number of negative text entries and reported the lowest quality of life (median). Taken together, these findings are foreground to the burdensome effects of the pandemic in terms of isolation, and reduction or even loss of social contact/activities and personal exchange in vulnerable individuals such as persons with MS. Based on the sociodemographic and disease characteristics of topic group 1, feelings of isolation appeared exacerbated in persons with MS who were comparatively less impaired or living alone. This finding might be related to the fact that persons with high disease burden are more accustomed to daily life restrictions compared to those with less impairments.
LimitationsDespite its notable strengths, the present research has some limitations, which merit consideration. First, there is a dearth of well-established guidelines for NLP that consider the specificities of health research. Consequently, the implementation of different text classification modeling approaches might have resulted in slightly divergent clusters and overarching topics. As such, to examine the robustness of our findings, we reanalyzed our data using the well-established Latent Dirichlet Allocation approach, which yielded similar patterns compared to those reported (not shown in this article) and thus corroborates the robustness of the presented results. Topic modeling further groups frequently co-occurring words into clusters (ie, “topics”). This method is suitable for identifying topics underlying large-scale text data in a data-driven fashion to thereby generate novel insights that might have been missed by standardized quantitative assessments. Our study does, however, not provide information to specifically tailor MS treatment to the needs of an individual person. The emotional tone indicates a general trend of the overall valence of a topic, while there may be variations at the individual level. Our findings have revealed experiences and burdens of persons with MS during the COVID-19 pandemic that may be relevant to future treatments or may provide insights for future research. Further limitations pertain to the generalizability of the findings of the sample population to the total population of persons with MS in Switzerland. Participants of this study constitute a subsample of the Swiss MS Registry’s participants. The registry itself covers the diversity of the Swiss population of persons with MS in terms of a broad range of characteristics []. The participants of the MS Registry subsample who completed the “COVID-19 survey” were comparatively younger, less disabled, and residing more often in the German-speaking region of Switzerland than the nonparticipants of the registry. However, we did not find any indications for systematic differences between the linguistic regions. The translation of non-German text entries into German through an automated translation software is afflicted with the risk of potential mistranslations, misinterpretations, and biases. However, it is important to mention that both exploratory count comparison of the most frequent keywords and manual spot-checking were not suggestive of any systematic differences across languages.
ConclusionWe demonstrated the potential of a preprocessing and NLP analysis pipeline for large-scale text data and applied it to COVID-19–related data collected by the Swiss MS Registry, which constitutes an optimal use case for the pipeline. Above and beyond providing practical guidance for applied researchers, our study has implications for efficiently leveraging large-scale textual data in health care settings. Electronic health records and clinical notes have received increasing attention as rich sources of information, which are accessible through the application of NLP techniques [-].
Our study further demonstrates an approach that complements structured and standardized assessments through individual participant perspectives and hence provides ecologically valid information. We provide practical guidance for applied health researchers who wish to follow a similar approach by (1) demonstrating the processing and analysis process using large-scale real-world data and (2) providing a detailed description of the pipeline, which is based (apart from LIWC) on freely available open-source software. Interested researchers can follow both the entire process and the software we use. Given the novelty of the emerging NLP field, we are, in this way, contributing to the establishment of good practice standards and the dissemination of knowledge around NLP methodology among applied researchers, especially those from the health sciences.
We thank Oliver Widler who developed an initial version of the natural language processing pipeline. We further thank the members of the Swiss Multiple Sclerosis (MS) Registry “Begleitgruppe” who contributed to text analysis validation. We are also most grateful to all participants of the Swiss MS Registry who dedicated their time and thereby made a crucial contribution to this research. Further, our gratitude goes to the Swiss MS Society for funding the Swiss MS Registry and for the continuous support. We are also very thankful to those study participants who, above and beyond providing their data, contributed essentially to all aspects of the Swiss Multiple Sclerosis Registry, including study design and implementation. Finally, we would like to thank the members of the Swiss MS Registry data center at the Institute for Epidemiology, Biostatistics and Prevention, University of Zurich. The members of the Swiss MS Registry are as follows: Bernd Anderseck, Pasquale Calabrese, Andrew Chan, Claudio Gobbi, Roger Häussler, Christian P Kamm, Jürg Kesselring (President), Jens Kuhle (Chair of the Clinical and Laboratory Research Committee), Roland Kurmann, Christoph Lotter, Marc Lutz, Kurt Luyckx, Patricia Monin, Stefanie Müller, Krassen Nedeltchev, Caroline Pot, Milo A Puhan, Irene Rapold, Anke Salmen, Klaas Enno Stephan, Zina-Mary Manjaly, Claude Vaney (Chair of the Patient and Population Research Committee), Viktor von Wyl (Chair of the IT and Data Committee), and Chiara Zecca. The Swiss MS Registry is supported by the scientific advisory board of the Swiss MS Society.
This research was funded by the Swiss Multiple Sclerosis Society and by seed grants from the Digital Society Initiative and the Participatory Science Academy of the University of Zurich.
CPK has received honoraria for lectures as well as research support from Biogen, Novartis, Almirall, Bayer Schweiz AG, Teva, Merck, Sanofi Genzyme, Roche, Eli Lilly, Celgene, and the Swiss Multiple Sclerosis (MS) Society (SMSG). AS has received speaker honoraria and/or travel compensation for activities with Almirall Hermal GmbH, Biogen, Merck, Novartis, Roche, and Sanofi Genzyme, and research support from the Swiss MS Society, none related to this work. The employer Department of Neurology, Regional Hospital Lugano [EOC], Lugano, Switzerland received financial support for CZ and CG's speaking and educational, research, or travel grants from Abbvie, Almirall, Biogen Idec, Celgene, Sanofi, Merck, Novartis, Teva Pharma, and Roche. AC has received speaker/board honoraria from Actelion (Janssen/J&J), Almirall, Bayer, Biogen, Celgene (BMS), Genzyme, Merck KGaA (Darmstadt, Germany), Novartis, Roche, and Teva, all for hospital research funds. He received research support from Biogen, Genzyme, UCB, the European Union, and the Swiss National Foundation. He serves as associate editor of the European Journal of Neurology, is on the editorial board for Clinical and Translational Neuroscience, and serves as topic editor for the Journal of International Medical Research. RH has received honoraria from Janssen, Lundbeck, Mepha, and Neurolite. SW has received honoraria from Janssen, Lundbeck, Mepha, Neurolite, and Sunovion. MS reports employment by Roche from February 2019 to February 2020. KS has received honoraria from from Janssen, Lundbeck and Mepha.
Edited by C Lovis; submitted 17.03.22; peer-reviewed by U Scholz, HJ Dai; comments to author 07.09.22; accepted 02.10.22; published 10.11.22
©Deborah Chiavi, Christina Haag, Andrew Chan, Christian Philipp Kamm, Chloé Sieber, Mina Stanikić, Stephanie Rodgers, Caroline Pot, Jürg Kesselring, Anke Salmen, Irene Rapold, Pasquale Calabrese, Zina-Mary Manjaly, Claudio Gobbi, Chiara Zecca, Sebastian Walther, Katharina Stegmayer, Robert Hoepner, Milo Puhan, Viktor von Wyl. Originally published in JMIR Medical Informatics (https://medinform.jmir.org), 10.11.2022.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in JMIR Medical Informatics, is properly cited. The complete bibliographic information, a link to the original publication on https://medinform.jmir.org/, as well as this copyright and license information must be included.
留言 (0)