
記住我


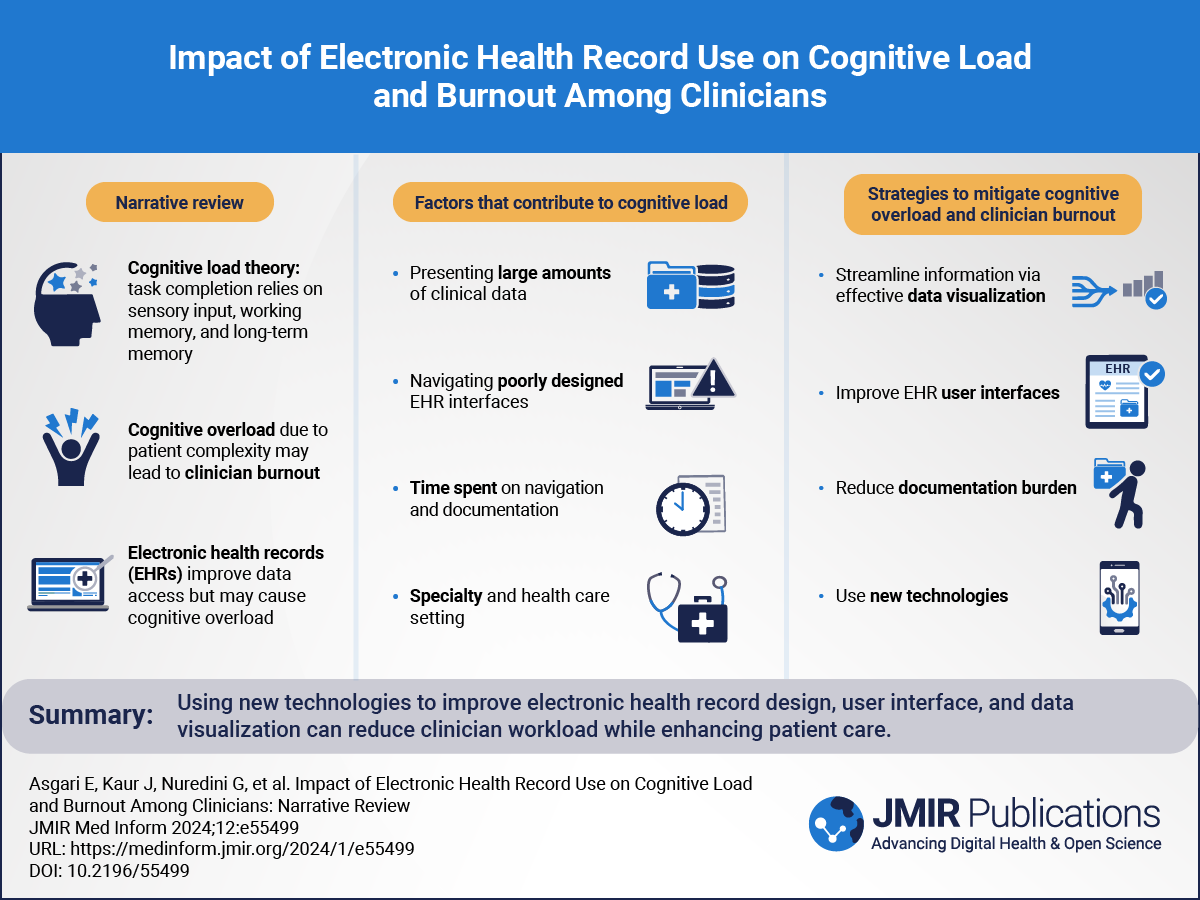






Clinical risk prediction models can provide decision-making support on therapeutic interventions and resource allocation, and thus can improve patient outcomes and reduce medical costs []. Along with the increasing availability and volume of electronic health record (EHR) data, these models are evolving from rule-based to data-driven probability-based tools, for example, machine learning–based patient outcome prediction models []. One of the critical challenges is performance drift over time, which results from either gradual or quick data shifts in the patient population, such as changing patient outcome rate, evolving clinical practices, and improving measurement accuracy [].
To correct temporal performance drift, a range of model updating approaches are available, including recalibration, model-specific adaptation (eg, reweighting the leaf nodes of each tree in a random forest [RF] model and an incremental learning method for a neural network model), model extension (eg, incorporating new predictors), and full model refitting []. These updating approaches vary in analytical complexity, old data and updated sample requirements, and computational demands. Usually, full model refitting is not the leading choice, especially in clinical use, owing to the risk of overfitting when new (and often smaller) data are used alone, while old data are completely discarded []. The essence of model updating is to create models that are constantly updated and adapted to the new incoming data, while balancing between both new and old knowledge [-].
Acute kidney injury (AKI) is a potentially life-threatening clinical syndrome, for which the only effective treatments are supportive care and dialysis, and it affects 10%-15% of all inpatients and more than 50% of critical care patients, and results in high mortality [,]. For AKI prediction, Davis et al [] developed 7 common regression and machine learning models, and found that discrimination performance declines were statistically significant but small for all models. Since they collected data solely from US Department of Veterans Affairs hospitals, it is not a typical scenario of population drift. Using data collected from Royal London Hospital, which hosts Europe’s largest kidney treatment facility, Haines et al [] developed risk prediction models for AKI after trauma, with the area under the receiver operating characteristic curve (AUROC) declining from 0.77 (0.72-0.81) in the development set (February 2012 to October 2014) to 0.70 (0.64-0.77) in the validation set (November 2014 to May 2016), and significant temporal performance drift.
In this study, we developed a clinical risk prediction model for hospital-acquired AKI. The model has been named transfer learning gradient boosting machine (TransferGBM), which is based on a transfer learning paradigm and maintains a stacking ensemble of 2 base gradient boosting machine (GBM) learners. Transfer learning has been proven to be one of the most effective ways to deal with data scarcity (eg, in the scenario where new data are not sufficient or available at a low cost) and data distribution discrepancies in many areas [-]. Transfer learning aims to selectively reuse data or knowledge from the source domain to assist the modeling process on the target domain, and it can be used to tackle the performance drift problem by regarding the old data as the source domain and the new data as the target domain. Since existing transfer learning approaches focus on optimizing performance only in the target domain, we still need a well-designed mechanism to incorporate and balance the old and new knowledge learned from the source and target domains.
According to the Kidney Disease Improving Global Outcomes (KDIGO) clinical practice guidelines for AKI, we adopted serum creatinine (SCr)-based criteria to stage the severity of AKI []. We did not use urine output to define AKI because it is less likely to be accurate outside the critical care environment [,]. Mild AKI (“AKI stage 1”) is defined as an increase in SCr of 1.5 to 1.9 times the baseline value within 7 days or an increase in SCr to 0.3 mg/dL (26.5 μmol/L) or more within 48 hours. The baseline creatinine value is defined as the most recent SCr if available; otherwise, it is the admission SCr. Moderate AKI (“AKI stage 2”) is defined as an increase in SCr of 2.0 to 2.9 times the baseline value within 7 days. The most severe AKI (“AKI stage 3”) is defined as an increase in SCr of 3.0 or more times the baseline value within 7 days or an increase in SCr to 4 mg/dL (353.5 μmol/L) after an acute increase of at least 0.3 mg/dL within 48 h or initiation of renal replacement therapy.
Study CohortThe study constructed a retrospective cohort using deidentified EHR data from 2010 to 2017 in the University of Kansas Medical Center. The data have been used in a previous study [] including a total of 141,696 adult patients (121,537 non-AKI patients; 20,159 any AKI patients; 3150 AKI stage ≥2 patients; and 1491 AKI stage 3 patients). To reflect the inpatient population shift, patients enrolled in different years were regarded as distinct individuals (ie, we handled the data at the patient-encounter level).
As shown in , the proportion of elderly patients (ie, age ≥65) generally increased every year, from 31.7% in 2010 to 36.5% in 2017. The proportion of patients between the ages of 46 and 55 years decreased every year, while the proportion of patients in other age groups remained the same. The ratio of male to female patients did not change much over time, and was basically maintained at 1:1. The proportion of White patients always ranked first, accounting for more than 70% of the total number of samples in each year, while the proportion of Native Hawaiians was the least (only 0.1%). Only the proportion of patients from different ethnicities remained stable over time, without obvious changes. The proportion of African Americans was more in 2010 than in all other years, and the proportion of White patients was slightly less in 2010 than in all other years. In addition, the incidence of AKI (any AKI) showed a clear downward trend, from 16.9% in 2010 to 12.8% in 2017.
Table 1. Demographic information.FeatureYearaAKI: acute kidney injury.
Data PreprocessingFor each patient, we collected all currently populated variables in the PCORNet common data model (CDM) schema, including demographic details (ie, age, gender, and race); structured clinical variables, including comorbidities (International Classification of Diseases-9 and International Classification of Diseases-10 codes), procedures (International Classification of Diseases and Current Procedural Terminology codes), laboratory tests (Logical Observation Identifiers Names and Codes), and medications (RxNorm and National Drug Code); and several vital signs (eg, blood pressure, height, weight, and BMI) []. All variables are time stamped, and each sample in the data set is represented by a series of clinical observation vectors aggregated on a daily basis. Therefore, the feature set formed by the data before or on day t can be used to predict AKI within days [t, t+1] for 24-h prediction (or within days [t+1, t+2] for 48-h prediction).
We preprocessed the data set as follows. First, for numerical features, such as laboratory measurement values and vital signs, we systematically removed the extreme values exceeding 1% and 99%. Second, we performed one-hot coding on categorical variables, such as diagnosis and procedure, to convert them into binary representations. Third, for medication codes, we converted data to cumulative exposure days before the prediction time rather than binary representations. Fourth, the most recent measurement value was chosen when repeated records were available within a certain time interval. Fifth, we used the “sample-and-hold” method to retrieve earlier available measurement values, when measurements were missing for a certain time span. Sixth, we introduced additional features, such as daily blood pressure trend or length of hospital stay, which have been shown to be useful for predicting AKI []. Seventh, we excluded all forms of SCr and blood urea nitrogen as they have a high correlation with AKI diagnosis and are not suitable for continuous prediction. Finally, a total of 28,306 features were obtained for model development.
We adopted the discrete-time survival framework [] to preprocess the time-stamped EHR data, as shown in . We divided the patient’s entire stay period into L nonoverlapping daily windows (ie, L=Δt, 2Δt, ..., T), where T is the length of hospital stay or a specific censor point. Based on expert knowledge, we chose a censor point T=7, which represents 7 days since admission. The interval value Δt is the prediction window selected according to clinical needs. For example, Δt=1 means 1-day (24-h) prediction and Δt=2 means 2-day (48-h) prediction. We would use all available data up to time t-Δt to predict AKI risk in time t. We treated the data corresponding to the AKI-onset day as positive samples based on the criteria of different prediction tasks, while the data after the first positive sample day and between different AKI-stage days were discarded since we could not judge the true AKI stages within these periods because physicians might have intervened and the patient’s condition might have improved. All remaining data were regarded as negative samples. For patients who never developed AKI during hospitalization, all available data within 7 days since admission were used to construct negative samples, and other data after 7 days since admission were discarded for the sake of alleviating data imbalance. Under the discrete-time survival framework, we can train a model more in line with real-world clinical practice, where the rolling prediction of AKI risk for a patient on a daily basis is essential [].
 Figure 1. Data processing strategy based on the discrete-time survival framework. The red triangle represents the actual stage of acute kidney injury (AKI). "Δt" indicates the prediction time in advance, “−“ indicates negative sample, “+” indicates positive sample, and “*” indicates excluded sample. View this figureTransferGBM Modeling Framework
Figure 1. Data processing strategy based on the discrete-time survival framework. The red triangle represents the actual stage of acute kidney injury (AKI). "Δt" indicates the prediction time in advance, “−“ indicates negative sample, “+” indicates positive sample, and “*” indicates excluded sample. View this figureTransferGBM Modeling FrameworkTo correct temporal performance drift, we propose a transfer learning–based modeling framework named TransferGBM, as shown in .
 Figure 2. Illustration of the TransferGBM modeling framework. AdaptedGBM: adapted gradient boosting machine; AKI: acute kidney injury; RefittedGBM: refitted gradient boosting machine; SourceGBM: source gradient boosting machine; TransferGBM: transfer learning gradient boosting machine. View this figure
Figure 2. Illustration of the TransferGBM modeling framework. AdaptedGBM: adapted gradient boosting machine; AKI: acute kidney injury; RefittedGBM: refitted gradient boosting machine; SourceGBM: source gradient boosting machine; TransferGBM: transfer learning gradient boosting machine. View this figureFrom the perspective of the transfer learning paradigm, we regard the old data as the source domain or source data, and the new data as the target domain or target data. We designed TransferGBM based on several fundamental ideas. First, the base learner is GBM, which has been applied in a wide range of clinical prediction modeling studies [,]. GBM has been chosen because (1) it is robust to high-dimensional and collinearity data, (2) it can automatically process missing values, and (3) it embeds a unique feature selection scheme in the model training process, making its output more interpretable [,]. Second, we treated the new and old data in different ways, with 2 independent GBM models representing the new and old knowledge, respectively. Third, we transferred old knowledge to the target domain while balancing new and old knowledge in the prediction through an ensemble of the above 2 GBM models. Fourth, we periodically updated the 2 GBM models and their relative weights in the prediction function using target data, in order to adapt to the changing data distribution.
The TransferGBM modeling framework included 5 steps. First, we constructed the source model (ie, source gradient boosting machine [SourceGBM]) using all source data, with a cross-validation–based procedure searching the optimal feature engineering scheme and hyperparameters of GBM (eg, depth of trees, learning rate, minimal child weight, and early stopping). Second, we applied the above optimal feature engineering scheme to the target data and then adapted SourceGBM to the processed target data using the built-in incremental learning mechanism and obtained the adapted model (ie, adapted gradient boosting machine [AdaptedGBM]). Third, we constructed the target model (ie, refitted gradient boosting machine [RefittedGBM]) using the original development set of the target domain while reusing the optimal feature engineering scheme and hyperparameters of GBM from SourceGBM. Fourth, we constructed the predicted probability value matrix for stacking ensemble learning [], by combining the predicted probability values of AdaptedGBM and RefittedGBM for each sample from the target domain’s development set and the true label of the sample into a vector, and pooling all vectors into a matrix H. Fifth, we applied the stacking ensemble learning method with the logistic regression (LR) learner to the matrix H to obtain the final prediction model, which integrated the old and new knowledge from the AdaptedGBM and RefittedGBM models, respectively.
From the viewpoint of the target domain, the modeling procedure involved 3 distinct sets of features, including (1) the common features that indicate the intersection of the source and target domain features, (2) the unique features that indicate the features belonging to the target domain but not the source domain, and (3) the important features selected by the GBM learner from the target data. When we adapted SourceGBM, we used the common features extracted from the target data combined with missing values of source domain–specific features, so that we could transfer the old knowledge of SourceGBM to the target domain. Considering the value of the target domain–specific knowledge (ie, the new knowledge), we allowed the GBM learner to select the most important features from both the common and unique features of the target data, so that we could obtain the new knowledge of the target domain without constrains on the feature space. The pseudocode of the TransferGBM modeling framework is shown in .
 Figure 3. Pseudocode of the TransferGBM modeling framework. AdaptedGBM: adapted gradient boosting machine; GBM: gradient boosting machine; RefittedGBM: refitted gradient boosting machine; TransferGBM: transfer learning gradient boosting machine. View this figureExperimental Design
Figure 3. Pseudocode of the TransferGBM modeling framework. AdaptedGBM: adapted gradient boosting machine; GBM: gradient boosting machine; RefittedGBM: refitted gradient boosting machine; TransferGBM: transfer learning gradient boosting machine. View this figureExperimental DesignWe designed the following 3 prediction tasks: any AKI prediction (ie, AKI stage ≥1), moderate-to-severe AKI prediction (ie, AKI stage ≥2), and severe AKI prediction (AKI stage 3). For any AKI prediction, the prediction window was set to 48 hours, while it was 24 hours for the other 2 tasks, according to general clinical needs.
We pooled the 2010 and 2011 data, and used them as old data (ie, a fixed source domain). The data from 2012 to 2017 were used as new data independently, yielding 6 target domains. We applied stratified random sampling to the source and target domain independently, with division into a development set (80%) and a validation set (20%). We tuned the hyperparameters of GBM, including depth of trees (2-10), learning rate (0.01-0.1), minimal child weight (1-10), and number of trees determined by early stopping, on the training set using 10-fold cross-validation. We measured model performance in terms of the AUROC [], with a mean value from the 95% CI.
It should be noted that the performance of SourceGBM on the target domain’s validation set indicated temporal validation and the performance of RefittedGBM (trained using the target domain’s development set) on the target domain’s validation set indicated internal validation. To validate TransferGBM, we first explored whether there was performance drift over time and then whether TransferGBM could maintain performance.
Ethical ConsiderationsThe study did not require approval from an institutional review board because the data used met the de-identification criteria specified in the Health Insurance Portability and Accountability Act Privacy Rule []. The HERON Data Request Oversight Committee approved the data request.
We examined 5 common machine learning models based on 5-fold cross-validation on each year’s data for any AKI prediction. These models included LR, decision tree (DT), RF, K-nearest neighbor (KNN), and GBM. The model parameters were customized as shown in , in addition to the default parameters provided in the scikit-learn package []. The AUROC performances of the 5 models’ internal validations in different years are shown in . The AUROCs of both GBM and RF reached 0.7 or above, indicating that these models had a certain predictive ability for AKI, while the performances of the other 3 models (DT, LR, and KNN) were generally poor. Given that GBM performed the best, we chose it as a base learner in the subsequent experiments.
Table 2. Model parameter setting.ModelParameter setting (except defaults)Gradient boosting machine (XGBoost)Tune the hyperparameters (depth of trees: 2-10; learning rate: 0.01-0.1; minimal child weight: 1-10) within the development set based on 10-fold cross-validationLogistic regressionpenalty=“L2;” max_iter=300; C=3.0Random forestn_estimators=400; bootstrap=TrueK-nearest neighborn_neighbors=40Decision treecriterion=“entropy” Figure 4. Internal validation of different machine learning models. AUROC: area under the receiver operating characteristic curve; DT: decision tree; GBM: gradient boosting machine; KNN: K-nearest neighbor; LR: logistic regression; RF: random forest. View this figurePerformance Shift Over Time
Figure 4. Internal validation of different machine learning models. AUROC: area under the receiver operating characteristic curve; DT: decision tree; GBM: gradient boosting machine; KNN: K-nearest neighbor; LR: logistic regression; RF: random forest. View this figurePerformance Shift Over Timedepicts the AUROC gain (ie, ΔAUROC) between the internal validation of RefittedGBM relative to the temporal validation of SourceGBM across 3 prediction tasks. The ΔAUROC shows a linear growth trend over time, implying that the transported model (ie, direct transport of SourceGBM to the target domain without any adaptation) was not the best choice for new data due to the change in data distribution over time. From another point of view, the performance gain was within 0.051, implying that the transported model still contained some general knowledge that can be reused in the new data.
 Figure 5. Performance gain by refitting the model. AKI: acute kidney injury; AUROC: area under the receiver operating characteristic curve. View this figurePerformance Validation of TransferGBM
Figure 5. Performance gain by refitting the model. AKI: acute kidney injury; AUROC: area under the receiver operating characteristic curve. View this figurePerformance Validation of TransferGBMTransferGBM maintained a stacking ensemble of 2 GBM models representing new and old knowledge learned from new and old data, respectively, with the former trained using data from 2010 and 2011, and the latter trained using the updated data of each year from 2012 to 2017. Using the validation set of the target domain from 2012 to 2017, we compared model performance between TransferGBM, transported gradient boosting machine (TransportedGBM, ie, direct transport of SourceGBM to the target domain without any adaptation), and RefittedGBM (ie, refitting SourceGBM using the target domain data). To better simulate the process of EHR accumulation in clinical applications, we further investigated different sizes of the available training set (ie, updated data) ranging from 25% to 100% of the target domain’s development set via stratified random sampling without replacement. shows the performance in terms of AUROC (95% CI) of TransportedGBM, RefittedGBM, and TransferGBM across different target years and different training set sizes for 3 prediction tasks.
We assessed the impact of different sizes of available training sets on model performance from the perspective of modeling framework selection. illustrates the case of the target year 2012 as an example. The performance of TransportedGBM was better than that of RefittedGBM when the training set size was small. As the amount of training data increased, RefittedGBM gradually improved and finally outperformed TransportedGBM. Overall, regardless of the size of the available training set, the performance of TransferGBM was always better than that of TransportedGBM and RefittedGBM.
Next, we investigated the joint impact of training set size and data distribution shift on model performance regarding the modeling framework selection, as shown in .
For any AKI prediction, when the training set size was 25%, TransportedGBM outperformed RefittedGBM in the first 3 years (from 2012 to 2014). However, in the subsequent 3 years (from 2015 to 2017), the prediction of TransportedGBM rapidly declined, and it underperformed RefittedGBM. During the whole 6 years, TransferGBM consistently outperformed TransportedGBM and RefittedGBM, with the AUROC ranging from 0.759 (95% CI 0.732-0.766) to 0.804 (95% CI 0.778-0.812), and an average AUROC gain of 0.03 compared to RefittedGBM and 0.02 compared to TransportedGBM. When the training set size was 100%, RefittedGBM significantly outperformed TransportedGBM over all 6 years, but still underperformed TransferGBM. The AUROC of TransferGBM ranged from 0.783 (95% CI 0.757-0.792) to 0.828 (95% CI 0.802-0.834), with an average AUROC gain of 0.04 compared to RefittedGBM and 0.02 compared to TransportedGBM.
For AKI stage ≥2 prediction, even though the training set size was only 25%, RefittedGBM outperformed TransportedGBM (except for target year 2012), and a larger training set was associated with better prediction. This means that the data distribution of the target domain was significantly different from that of the source domain, and directly transporting an external model into the target domain was not a wise choice. Again, TransferGBM was the best model among the 3 models, regardless of the training set size and target year. The AUROC of TransferGBM ranged from 0.830 (95% CI 0.795-0.851) to 0.921 (95% CI 0.893-0.932) when the training set size was 25%, and ranged from 0.866 (95% CI 0.835-0.877) to 0.946 (95% CI 0.920-0.959) when the training set size was 100%.
For AKI stage 3 prediction, when the training set size was 25% or 50%, RefittedGBM significantly underperformed TransportedGBM in the first 3 years (from 2012 to 2014), but the prediction became close in the subsequent 3 years (from 2015 to 2017). When the training set size was 50% or 100%, RefittedGBM and TransportedGBM performed very close to each other. This result implies that direct transportation of an external model was a good choice (ie, there is no need to refit the model, especially when training data on the target domain is not sufficient). TransferGBM was still the best model, and the AUROC ranged from 0.920 (95% CI 0.890-0.936) to 0.948 (95% CI 0.921-0.962) when the training set size was 25%, and ranged from 0.866 (95% CI 0.854-0.911) to 0.959 (95% CI 0.932-0.973) when the training set size was 100%.
 Figure 6. Impact of training set size on performance (target year 2012). AKI: acute kidney injury; AUROC: area under the receiver operating characteristic curve; RefittedGBM: refitted gradient boosting machine; TransferGBM: transfer learning gradient boosting machine; TransportedGBM: transported gradient boosting machine. View this figure
Figure 6. Impact of training set size on performance (target year 2012). AKI: acute kidney injury; AUROC: area under the receiver operating characteristic curve; RefittedGBM: refitted gradient boosting machine; TransferGBM: transfer learning gradient boosting machine; TransportedGBM: transported gradient boosting machine. View this figure Figure 7. Joint impact of training set size and data distribution shift on performance. AKI: acute kidney injury; AUROC: area under the receiver operating characteristic curve; RefittedGBM: refitted gradient boosting machine; TransferGBM: transfer learning gradient boosting machine; TransportedGBM: transported gradient boosting machine. View this figure
Figure 7. Joint impact of training set size and data distribution shift on performance. AKI: acute kidney injury; AUROC: area under the receiver operating characteristic curve; RefittedGBM: refitted gradient boosting machine; TransferGBM: transfer learning gradient boosting machine; TransportedGBM: transported gradient boosting machine. View this figureExperimental results showed that TransferGBM can consistently outperform TransportedGBM and RefittedGBM, regardless of the amount of available training data from the target domain. We also confirmed that old data are important, and should not be discarded, especially in the case of insufficient new data. There exist differences between old and new knowledge, and thus, there is a need to achieve balance.
With regard to the candidate base learners for the proposed transfer learning–based modeling framework, we considered several commonly used linear and nonlinear machine learning algorithms, and among them, RF has good robustness to overfitting and high-dimensional feature variables [,]. XGBoost can consider multiple potentially relevant predictors simultaneously and can handle potentially nonlinear correlations [-]. DT is a nonparametric learning algorithm with fast computation and accuracy, can handle continuous and type fields, and is very suitable for high-dimensional data []. LR is a linear algorithm that is very suitable for sparse data sets, and the model performance remains stable when only a few variables in the model are valuable predictors. KNN is simple to implement, does not require a data training process, and is very suitable for high-dimensional data. According to the experiment results, the XGBoost algorithm had superior performance. The performance of RF was very close to that of XGBoost, and both were tree-based ensemble approaches. DT may ignore the correlation between variables and experience some large noise, resulting in very poor model performance []. The poor performance of LR might be due to the nonlinear correlation between AKI risk factors. KNN may be affected by a large amount of noise in the EHR data, resulting in very poor performance.
The choice of TransportedGBM, RefittedGBM, or TransferGBM depends on or is affected by the actual situation regarding data distribution, modeling cost, available training data from the target domain, etc. TransportedGBM is trained on source data and then is directly applied to the target data without any adaptation and additional cost, which is appropriate for clinical scenarios where the distribution between the source and target domains is very similar. When the distribution is not similar, RefittedGBM would be a better choice than TransportedGBM, and it only requires refitting of the model on the target data, except for the requirement of sufficient training data from the target domain. TransferGBM is no doubt a more complicated solution, which needs to adapt an existing model, refit a new model, and construct an ensemble of these 2 models. This makes TransferGBM more suitable for clinical scenarios where the distribution of the source domain is partially similar to that of the target domain or where the degree of similarity changes significantly.
With regard to the adaptiveness of TransferGBM, it is clear that TransferGBM is a flexible and adaptive extension to the combination of AdaptedGBM and RefittedGBM (AdaptedGBM is obtained by updating TransportedGBM/SourceGBM to the target domain). This also means that TransferGBM might degrade to AdaptedGBM or RefittedGBM due to the stacking ensemble learning mechanism under certain situations. Taking some extreme cases as examples, when the target domain is under the same distribution as the source domain, TransferGBM would degrade to AdaptedGBM and even TransportedGBM since there is little change after updating the model with new data from the target domain. On the contrary, when the target domain is under a distribution completely different from the source domain, TransferGBM would degrade to RefittedGBM, since in this case, AdaptedGBM would be almost useless, and even negative and suppressed under the stacking ensemble learning process. In most cases that TransferGBM is designed for, that is, when the distributions of the source and target domains are more or less similar but not completely different, TransferGBM would adaptively achieve a balance between AdaptedGBM and RefittedGBM.
MotivationsConventionally, transfer learning is applied to the scenario of data scarcity and distribution disparity, with the underlying idea of selectively reusing data or knowledge from the source domain to assist the modeling process on the target domain. As for the scenario of temporal performance drift, we proposed to regard the old data as the source domain and the new data as the target domain, which might make transfer learning suitable, and we attempted to confirm its effectiveness.
We believe that transfer learning can provide insights from another perspective for correcting temporal performance drift, compared to common approaches such as recalibration and incremental training. For example, when the data distribution significantly changes, transfer learning can immediately discard the old knowledge/model and reselect a new suitable training sample from the source domain to learn, while incremental training suffers from slow progressive adaptation.
Since the primary objective of our study was not to build a high-performance AKI prediction model under the common modeling scenario, we divided the data into different years and adopted a simple and clear modeling process without comprehensive feature engineering, class balancing, hyperparameter searching, etc.
LimitationsThere are several limitations associated with our study. First, we used retrospective data in model training and validations, and had not validated our model externally. Thus, our results do not indicate the performance in actual clinical practice. Second, we have not adopted state-of-the-art transfer learning algorithms, such as gapBoost, distant domain transfer learning, selective learning algorithm, multilinear relationship networks, and transitive transfer learning, that have been discussed in systematic reviews [,]. These algorithms might yield better prediction performance. Third, we have not compared our method with other correction approaches for temporal performance drift and detection mechanisms of temporal performance drift, such as those proposed by Davis et al [,,]. Fourth, we have not considered prevalent time-series models, such as recurrent neural networks and long short-term memory [,], as well as adding historical aggregate feature representations (eg, average laboratory test results and vital signs for the past 48 h) []. These methods may yield effects equivalent to those of the transfer learning approach.
ConclusionsThis study addressed the problem of performance drift in clinical prediction models. We proposed a novel transfer learning–based modeling framework and validated it using real EHR data from the University of Kansas Medical Center for AKI prediction. The proposed TransferGBM model overcomes the problems of insufficient target data and drifting data distribution through transferring old knowledge and integrating old and new knowledge models. The results showed that TransferGBM is superior to both transported and refitted models.
This research was supported by the Major Research Plan of the National Natural Science Foundation of China (Key Program, grant number 91746204), the Science and Technology Development in Guangdong Province (Major Projects of Advanced and Key Techniques Innovation, grant number 2017B030308008), and Guangdong Engineering Technology Research Center for Big Data Precision Healthcare (grant number 603141789047). ML is supported by the National Institutes of Health (NIH)/National Institute of Diabetes and Digestive and Kidney Diseases (award R01DK116986), National Science Foundation Smart and Connected Health (award 2014554), and NIH/National Center for Advancing Translational Sciences (NCATS) Clinical Translational Science Award (CTSA; grant number UL1TR002366). The clinical data set used in this study was obtained from the University of Kansas Medical Center’s HERON clinical data repository, which is supported by institutional funding and by the NIH/NCATS CTSA (grant number UL1TR002366).
YH and ML initiated the project and designed the overall study. ML extracted the data used in this study. XZ and KL designed the algorithm. YX, SC, and XS designed the initial training and testing setup, and performed the experiments. YX drafted the paper, with critical revisions by YH, ML, XZ, KL, and WC.
None declared.
Edited by T Hao; submitted 17.03.22; peer-reviewed by H Li, K Zheng, H Sun; comments to author 15.05.22; revised version received 31.07.22; accepted 12.10.22; published 09.11.22
©Xiangzhou Zhang, Yunfei Xue, Xinyu Su, Shaoyong Chen, Kang Liu, Weiqi Chen, Mei Liu, Yong Hu. Originally published in JMIR Medical Informatics (https://medinform.jmir.org), 09.11.2022.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in JMIR Medical Informatics, is properly cited. The complete bibliographic information, a link to the original publication on https://medinform.jmir.org/, as well as this copyright and license information must be included.
留言 (0)