
記住我
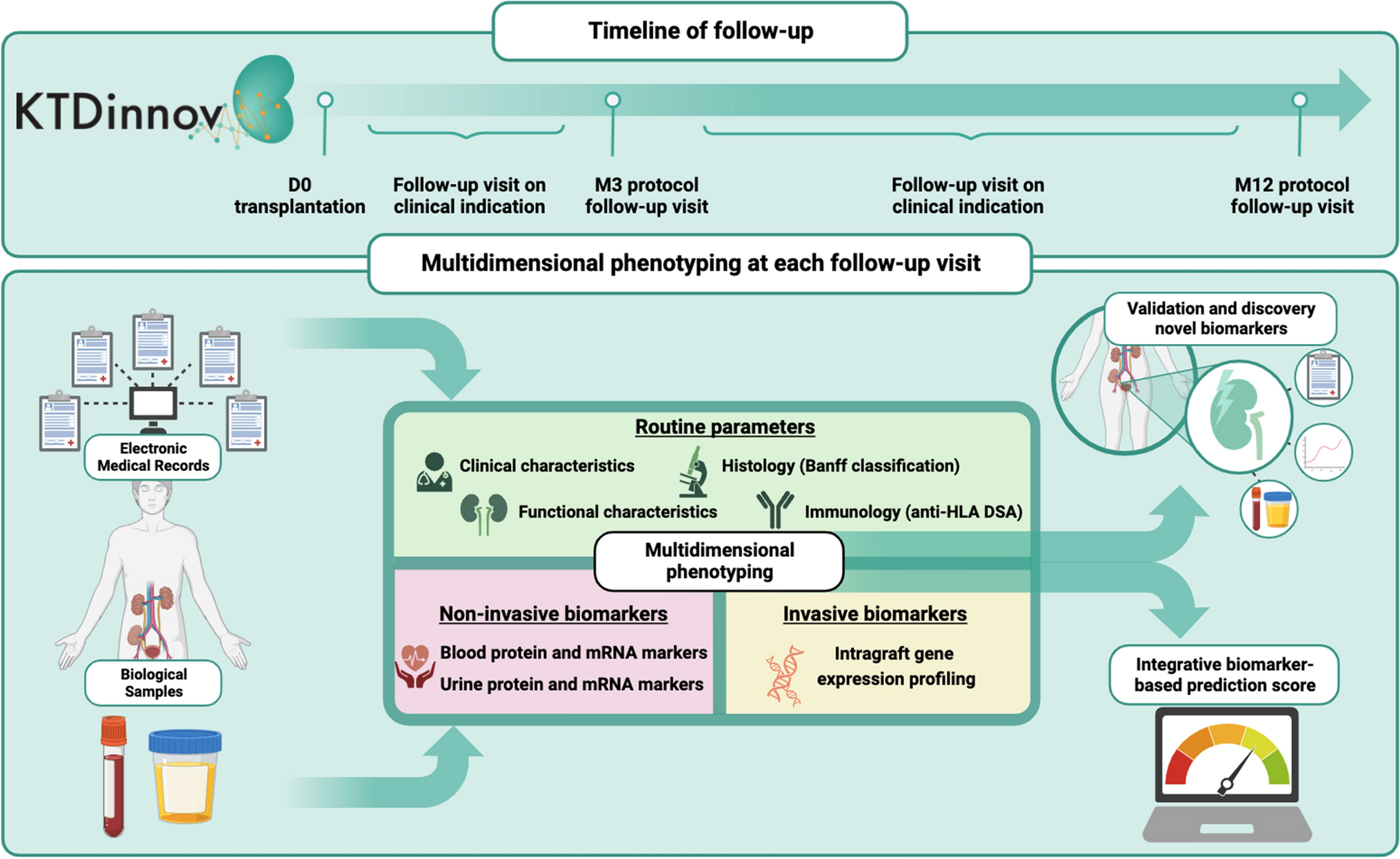


In many research areas, the gold standard for recruiting participants is to use probability-based sampling to draw representative inferences for a given population [1,2,3]. Unfortunately, such efforts are often costly or unfeasible. Other methods, such as convenience-based sampling, are useful alternatives but can risk introducing significant sampling bias [4]. This concern has been particularly salient during the COVID-19 pandemic, as most COVID-19 research has relied on non-representative (e.g., convenience-based) observational samples [5,6,7].
A common, and in theory valid, approach to reduce the impact of sampling bias is to adjust analyses using covariates thought to influence study participation (e.g., adding covariates to a regression, using propensity scores, or sample weights) [8,9,10]. However, there remains substantial uncertainty about which factors drive participation (or lack thereof) and, therefore, how to adequately account for sampling bias. Commonly, researchers default to adjusting analyses for select demographic variables (e.g., sex, age, education), but the extent to which this practice has been successful is unknown. We address these ideas theoretically and empirically within the context of online COVID-19 behavioural and public health research.
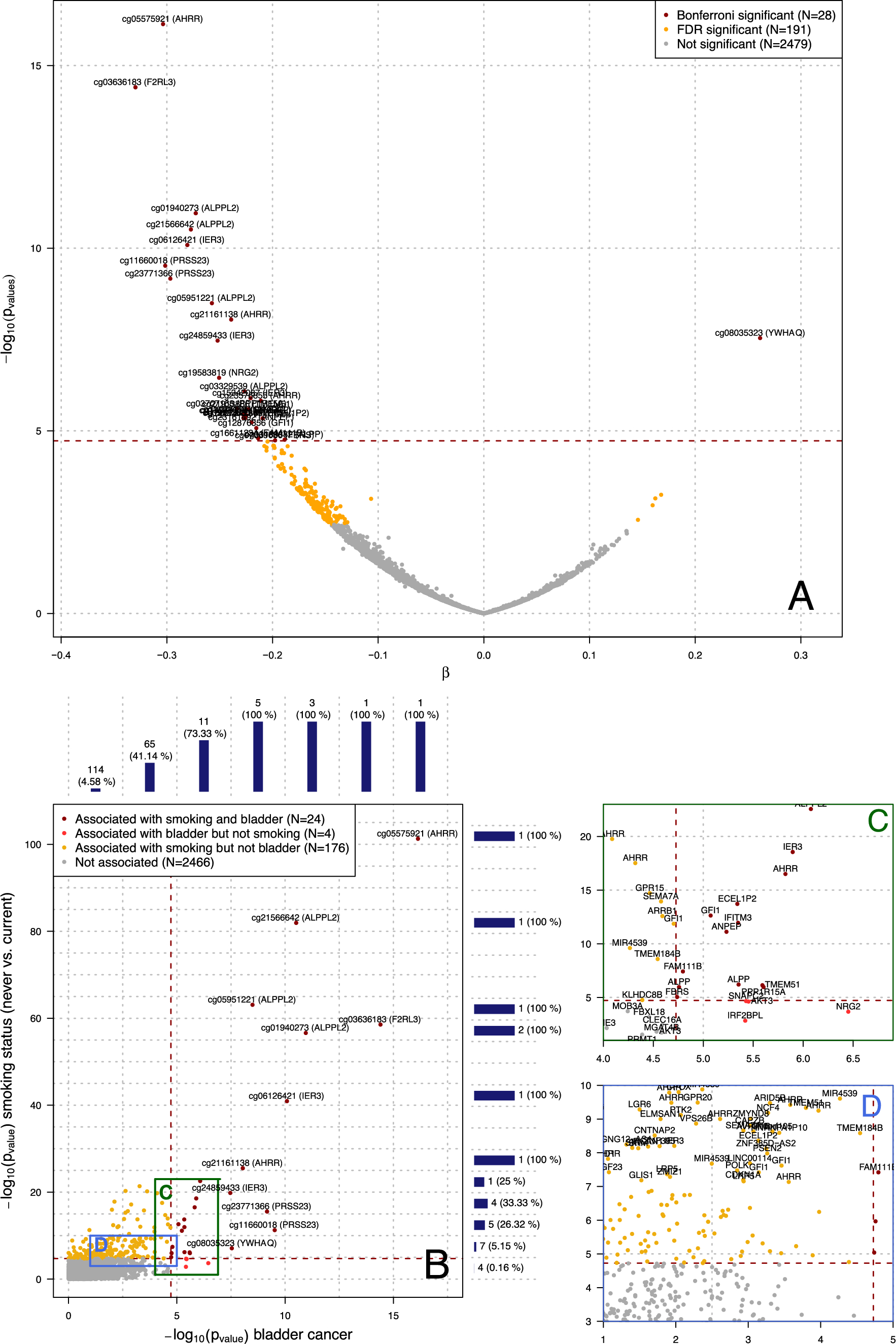
Sampling bias: a non-technical explanationSampling bias occurs when different members of a population have unequal probabilities of being included in a study. This can occur for many reasons, such as when recruitment strategies have unequal reach for different groups, or when groups, once reached, differ in their response rates. Sampling bias can impact estimates of prevalence/incidence rates as well as of the link between exposure-outcome pairs. To understand sampling bias, and how to counter it, we can represent the phenomenon using causal diagrams such as Panel A of Fig. 1 [11, 12].
Fig. 1
Examples of sampling bias and the roles of covariates. The black square around selection indicates that analyses are limited to individuals who participated (either through selection by a study’s design or through self-selection). Selection is a collider, a common effect of other variables. Panel A is an example of sampling bias shown through a causal diagram. Here, recruitment strategy (convenience vs. probability), along with an exposure (sex) and an outcome (vaccine acceptance) each influence a person’s selection into a study. Though the three variables are not causally linked, conditioning on selection (a collider) leads them to be associated through a process known as collider bias. Panel B is a simulated example of the dynamic in Panel A where 50% of a population is accepting of vaccination, and this ratio is equivalent for male and female individuals. However, both vaccine acceptance and sex predict selection. Having data only from people who participate will lead an analyst to overestimate vaccine acceptance and see a spurious association between sex and vaccine acceptance such that female (vs. male) participants show lower levels of acceptance (also see Box 1). Panel C provides example roles covariates can play in an association between an outcome (vaccine acceptance) and selection. Adjusting analyses for a mediator (confirmation seeking) or a confounder (education) can both reduce sampling bias. However, adjusting for another collider (employment) can introduce further collider bias. Thus, analysts must be mindful of the causal role of covariates in relation to their exposure-outcome links of interest
Using Fig. 1, consider an illustrative example. Imagine we are conducting research to estimate rates of COVID-19 vaccine acceptance (i.e., our outcome, defined as vaccine receipt or intentions to get vaccinated) in a community, and wish to explore how sex (our exposure) influences acceptance. In this study, we compare two recruitment strategies: a convenience-based and a probability-based sampling method. Importantly, our analyses are restricted to the selection of responses we obtain (we have no data on non-respondents). How might we expect sampling to affect our findings under these circumstances?
First, recruitment strategies will influence the selection of responses we obtain (path p1). In an ideal probability-based design, all population members would have an equal likelihood of being reached and efforts would be made (e.g., using incentives) to ensure high participation rates. In contrast, in convenience-based samples, reach is usually skewed towards certain groups (e.g., social media users for a study advertised on social media) and small/absent incentives can skew participation further [13, 14]. Second, participant characteristics can impact responses, either in conjunction with, or independently from recruitment strategy. For our example, research has shown that female (vs. male) individuals are more likely to volunteer for research (path p2) [15, 16] and we could anticipate that people are more likely to participate in vaccine-related research if they hold favourable attitudes towards vaccines (due to human tendencies to seek information in line with pre-existing beliefs; path p3) [17, 18].
The result of these forces (of paths p1, p2, p3) is that we will observe a series of biased findings if we attempt to use the convenience sample to draw inferences about the population (compared to using the probability sample). Specifically, we will overestimate the degree to which participants are female and accepting of vaccines (paths p4 and p5) and will also spuriously find that vaccine acceptance is lower among female (vs. male) participants (path p6)—even if, in the overall population, no such association exists (see Box 1). These three biased findings are spurious and are manifestations of sampling bias.
Box 1 Three ways of understanding how collider bias creates spurious findingsGenerally, sampling bias emerges through a process known as collider bias, whereby an association is induced (or distorted) between two variables because analyses are conditioned on a common outcome of those variables—known as a collider [5, 11, 12, 19]. In Fig. 1, selection is a collider (a common outcome) of recruitment strategy, sex, and vaccine acceptance. Conditioning analyses on selection—by limiting analyses to participants—is at the root of the biased observations (paths p4, p5 and p6). An example of this dynamic is provided in Panel B of Fig. 1, demonstrating how limiting analyses to participants induces a spurious (and inverse) association between sex and vaccine acceptance (path p6). Given the importance of collider bias for understanding sampling bias, Box 1 provides three ways of conceiving/understanding this concept.
How to reduce/eliminate sampling biasOf central interest to researchers is the question: how can we reduce or eliminate (the effects of) sampling bias? One way is to rely on representative sampling, but this will often be unfeasible and sometimes even undesirable [20, 21]. Alternatively, we can disrupt the dynamic that leads to sampling bias analytically by using covariates within statistical models (e.g., adding covariates to a regression, or by using propensity scoring) [8,9,10]. For instance, in Fig. 1, the spurious path p6 (between sex and vaccine acceptance) occurs because analyses are conditioned on selection (Box 1). If we can analytically keep selection from acting as a collider, we can eliminate this bias. To do so, we can disrupt path p3, so that there is no effect from vaccine acceptance to selection (i.e., in the absence of p3, selection is no longer a common cause of sex and vaccine acceptance) or disrupt path p2 so that there is no effect from sex to selection. Likewise, we can also eliminate the spurious paths p4 (or p5) by disrupting the causal effects p1 and p2 (or p1 and p3). Unfortunately, identifying covariates for these tasks is easier said than done. In practice, covariates play a multitude of causal roles, each of which have unique implications for disrupting/amplifying paths leading to selection.
Panel C of Fig. 1 demonstrates this complexity. If a causal link exists between an outcome and a collider (p3 from Panel A), adjusting for a variable that accounts for this causal link (a mediator) can reduce sampling bias. In our example, we reasoned that vaccine acceptance would cause self-selection because people seek attitude-confirming information. Thus, we could measure and adjust for confirmation-seeking behaviour. To fully disrupt the association between an outcome and self-selection, however, we should also adjust for confounders. In Panel C, higher education promotes participation in research [15, 22] and greater vaccine acceptance [23]; education should therefore be adjusted for. That said, one should also avoid adjusting for additional colliders as doing so can introduce further collider bias. For example, if vaccine mandates exist for employment [24, 25] (i.e., vaccination predicts employment) and certain personality factors like conscientiousness facilitate both survey participation [26] and employment [27], then adjusting for employment may increase bias. Consequently, researchers must be very careful in their choice of covariates (and similar cautions could be made for disrupting any causal pathway in Fig. 1; i.e., p1, p2, or p3).
These concerns are not novel, and many articles give guidance on how to use causal theory/diagrams to select covariates [4, 5, 11, 12, 19]. Unfortunately, systematic reviews find that it remains rare for research to adequately justify covariate selection choices, especially by using a causal perspective [28,29,30,31,32]. Instead, researchers frequently rely on heuristics/norms (e.g., always adjusting for demographics variables like sex, age, socioeconomic status), focus on variables for which population-data is readily accessible (also typically demographic variables), use all available covariates in their data, or rely on simple statistical rules such as controlling for any covariate known to relate to either the exposure or the outcome [30,31,32,33,34]—with each of these criteria failing to distinguish between confounders, mediators, and colliders [11, 12].
Researchers also vary widely in their selection of covariates even when examining similar research questions [32,33,34,35]. For instance, nutritional epidemiology work studying the same outcomes rarely adjust for the same sets of covariates [32]. This issue was particularly well-captured in two methodological studies [34, 35] which recruited 29 and 120 research teams, respectively, and tasked teams to independently answer the same research question using the exact same dataset. In both studies, most teams opted for unique selections of covariates (distinct from all other teams). Clearly, there is much uncertainty as to which covariates investigators should and shouldn’t include in analyses, and relatedly, as to whether most covariate choices in the literature are useful for attenuating bias.
Goals of the current studyBeing able to identify and adjust for sampling bias is an important goal for science. This is particularly true in contexts like the COVID-19 pandemic, when urgency in decision-making can allow biased findings to have undue repercussions on scientific/public discourse and on policy making [5,6,7]. With this in mind, we set out with two primary goals.
First, we sought to inform future efforts to attenuate sampling bias by qualifying who gets recruited through online convenience sampling in COVID-19 research. Given research on selective-exposure to attitude-congruent information [17, 18], we hypothesised that participants recruited using convenience methods (versus those recruited through more representative means) would display higher levels of concerns about COVID-19, hold beliefs that prevention behaviours are more important, and show greater adherence to behavioural recommendations (e.g., social distancing, mask wearing, vaccination).
Second, given that adjusting analyses for demographic covariates (e.g., adding variables in a regression) is a common method for addressing sampling bias, we sought to evaluate the frequency with which this technique successfully accounts for and attenuates sampling bias within online surveys. To account for how researchers make different choices on which covariates to adjust for, we made use of multiverse analyses [36, 37], an analytical perspective that urges analysts to evaluate how all plausible study choices can influence their results (i.e., by running and reporting results for all analytic choices they could have justifiably made). In our case, this entailed evaluating the degree to which all combinations of a set of plausible and common demographic covariates (e.g., sex, age, education) were successful in attenuating sampling bias in a set of convenience samples.
留言 (0)