

記住我






Systematic parameter exploration is an unmet need for model building in neuroscience. Complete specification of models in neuroscience or systems physiology requires identification of several parameters. For single neurons, these typically include geometric and electrical properties of the cell body, dendrites, and axons. Even with the sophistication of modern experimental techniques, however, measuring all the necessary parameters is almost always impossible. Additionally, many single-neuron properties exhibit remarkable context-dependent variability, even within the same animal. For example, changes in the neuromodulatory environment alter the spiking dynamics of spinal motoneurons (Heckman et al., 2009) and thalamocortical neurons (Pape and McCormick, 1989) by influencing their ionic conductances. Thus, any single measurement at one time instance would be insufficient to inform all single-neuron/network properties because it cannot account for the wide spectrum of behaviors observed in vivo.
To complicate matters further, redundancy in biological systems leads to similar activity profiles that can be produced by many different neurons or neuronal networks with dissimilar properties (Swensen and Bean, 2005; Schulz et al., 2007; Roffman et al., 2012). For example, lateral pyloric neurons in the crab stomatogastric ganglion exhibit as much as two- to four-fold interanimal variability in three different ion channel densities and their corresponding mRNA levels (Schulz et al., 2006). Therefore, even averaging a parameter from multiple experimental preparations may fail to generate the desired behavior in the computational models constructed from them (Golowasch et al., 2002). Systematic exploration of the parameter space is obligatory to fit a neuron model to experimental data. Additionally, this systematic exploration may reveal deeper insights and motivate future experiments by unraveling undiscovered parameter combinations that might reproduce the same experimentally observed behavior.
Fitting experimental data to neuron models has been a major challenge for neuroscientists. In fact, the parameters of the first biologically realistic quantitative description of the neuronal membrane were hand fitted by Hodgkin and Huxley (1952). This approach has remained popular; for example, the peak conductances of ion channels in a model of an elemental leech heartbeat oscillator were hand tuned by Nadim et al. (1995). Likewise, both the single compartment and network parameters of a small group of neurons used to model the crustacean pyloric network were hand tuned by Soto-Trevino et al. (2005) to reproduce a variety of experimentally observed behaviors. However, the ever-increasing dimensionality and complexity of neuron model (Hodgkin and Huxley's description contained only three membrane currents), accompanied by the concomitant increase in computational resources, have made hand tuning of parameters a near infeasible task. Besides, hand tuning of parameters also introduces potentially undesired experimenter bias, because different parameters are assigned preconceived roles during the tuning process (Van Geit et al., 2008). Nevertheless, manual exploration of parameter sets may be unavoidable because the initial range of values of different parameters over which the automated search is to be performed must be determined by the experimenter based on physiological constraints.
1.1. Computational inference for neural modelsThe body of research on parameter estimation for models of neural dynamics for single cells or circuits spans across various scientific communities, approaches, and neuron models. A gap exists, however, between researchers with rich physiological knowledge, on the one hand, and researchers working on new solution algorithms for inference, on the other hand. This gap presents opportunities to create a bridge between physiologists, engineers, computational scientists, and mathematicians by exploring existing and developing new inference techniques for neuron dynamics of single cells and circuits.
1.1.1. Multiple realizability: The dilemma of many truthsSingle-neuron activities that are amenable to easy measurement (e.g., spike trains, voltage traces, local field potentials) can often be identical for different parameter combinations. Just as this situation renders experimental determination of parameter values infeasible, it also poses an incredible challenge to systematically infer a model from experimental data. For example, Prinz et al. (2004) found indistinguishable network activity from widely disparate deterministic models. Similarly, Amarasingham et al. (2015) reported statistically indistinguishable spike train outputs for different statistical processes that model the firing rate of networks. Hartoyo et al. (2019) stressed that, for models of dynamical systems, very different parameter combinations can generate similar predictions/outputs. Additionally, the authors showed that sensitivities of predicted parameters can exhibit wide variability, leading to the conclusion that modeling in neuroscience is confronted by the major challenge of identifiability of model parameters. The demonstrative model used in our present work shows a bursting neuron producing similar neural activities from multiple sets of conductance densities (Alonso and Marder, 2019).
1.1.2. Approaches for estimating parametersComputational approaches for estimating parameters of neuron models based on ordinary differential equations (ODEs) include (brute-force) grid search (Prinz et al., 2003) as well as more advanced techniques using heuristics or trial-and-error approaches, which may consist of intricate sequences of regression steps (Achard and De Schutter, 2006; Van Geit et al., 2007, 2008; Buhry et al., 2011). The latter include simulated annealing, differential evolution, and genetic algorithms. These approaches can have the disadvantage of slowly converging to an optimal set of parameters and thus becoming computationally expensive. Using gradient-based optimization to accelerate convergence (Doi et al., 2002; Toth et al., 2011; Meliza et al., 2014), on the other hand, can suffer from the non-convexity and the strong non-linearities in the objective manifold and require good initial guesses in order not to stagnate in local minima (thereby resulting in suboptimal parameter sets). Another shortcoming of recovering only a single set of parameters (also called point estimates) is the lack of knowledge about the uncertainties or error bounds for the inferred parameters. These can be obtained with a subsequent sensitivity analysis and, as a consequence, require employing additional algorithms and computational resources.
Recently the use of machine learning techniques based on artificial neural networks (ANNs) became popular. For instance, in the context of the FitzHugh–Nagumo model (Rudi et al., 2021), an ANN was constructed and optimized to generate an inverse map that is able to predict model parameters from observational data. Bittner et al. (2021) developed generative models from deep learning. Retrieving associated uncertainties for inferred parameters has been performed by Gonçalves et al. (2020), using normalizing flows with Gaussian mixtures in order to generate approximations of posterior distributions for Hodgkin–Huxley-based inverse problems. However, machine learning techniques require generating large sets of data for training the artificial neural networks, where each training sample entails the numerical solution of the ODE system of the neuron model.
Theoretical neuroscientists have been developing and utilizing statistical methods for inference and uncertainty quantification (Van Geit et al., 2007; Vavoulis et al., 2012) and have been relying on Bayesian inference frameworks (Ahmadian et al., 2011; Doruk and Abosharb, 2019) in order to estimate parameters and quantify uncertainties of the recovered parameters. The uncertainties in recovered parameters with Bayesian inference frameworks are represented by posterior density functions, which describe a “landscape” of more likely parameters (“peaks in the landscape”) and less likely parameters (“valleys in the landscape”; see Section methods for details). Bayesian likelihoods or their approximations are constructed, which in turn enables direct maps to posterior densities without numerical solutions of neuron models to evaluate objective (or loss) functions. Chen (2013) provides an overview of Bayesian methods for neural spike train analysis. René et al. (2020) and Schmutz et al. (2020) have utilized Markov chain Monte Carlo for inference from spike train data of population models.
1.2. Using Markov chain Monte Carlo (MCMC) algorithms for inferenceMCMC algorithms play a critical role in our approach for parameter estimation. For a brief introduction and background information about MCMC algorithms, we refer to the Section methods.
1.2.1. Benefits and limitations of using MCMC for parameter searchesOne of the main benefits of using MCMC is the detailed picture or “landscape” of the posterior density that it can provide. By analyzing the posterior, the uncertainty in the inferred parameters can be quantified, and the dependencies between different parameters in the model can be identified. Another benefit is that MCMC does not require derivatives of neuron models or the loss function (measuring misfit of the data and model output). This is an important property in the case of the complex model and non-differentiable loss function used by Alonso and Marder (2019), which our present work utilizes. We propose to utilize a specific MCMC method called parallel tempering MCMC. It has the key advantage of efficiently exposing multimodality in the posterior (see Section methods for more details), which other MCMC methods can potentially leave undiscovered.
As with many other computational methods for parameter estimation, the efficiency scaling with the number of parameters (dimensionality) is a potential limitation with MCMC-based methods. Generally speaking, as the number of parameters increase, the dimensionality of the search space increases, and more iterations of MCMC may be required, leading to a longer total computation time. In the inference that we are targeting in this work, the number of inferred parameters remains at amounts where these limitations do not occur for parallel tempering MCMC. We note here that parallel tempering MCMC is able to find the multimodal posterior successfully where many other Bayesian inference methods, including Approximate Bayesian Computing with Sequential Monte Carlo, could not. Future work will determine the dimensionality limits of this computational method.
1.2.2. Applications of MCMC in the context of biological modelingIn fields related to neuroscience, MCMC-based methods have been a popular choice for solving inverse problems in a Bayesian framework, where one is interested in uncertainties in addition to optimal solutions (Smith, 2013). In the context of dynamic systems in biology, MCMC techniques have been successfully employed, as described in review articles by Ballnus et al. (2017) and Valderrama-Bahamo (2019). Moreover, tempering MCMC methods have been shown to recover the multimodality of solutions in systems biology (Caranica et al., 2018; Gupta et al., 2020). However, in the context of neural dynamics with complex Hodgkin–Huxley models, such as in Alonso and Marder (2019), on which we built this work, tempering MCMC methods have not been attempted to our knowledge.
1.3. Contributions of this workIn this study, we address the issue of multiple realizability of specific models in neuroscience. In particular, we present the computational inference for one three-channel and one eight-channel HH neuron model with a parallel tempering MCMC algorithm as the method for inference. We successfully estimate the parameters in these models, describe the multimodality in the parameter space, and quantify the parameters' uncertainties. Additionally, we present visualizations of the high-dimensional inference solutions taking the form of posterior densities.
We discuss how these multimodal posteriors (solution maps) are produced by this method for large parameter dimensions. While the posteriors are inherently tied to both the chosen neuron model and chosen loss function, we believe, this method could allow an experimentalist the ability to explore different desired features and models.
As an alternative to manually adjusting the metric measuring fitness between data and model outputs, we present inference setups that use different stimulus currents to further constrain the algorithmically recovered parameters obtained with MCMC.
2. MethodsWe design the parameter estimation problem in a Bayesian framework: (i) parameter values of the neuron model are treated as (multivariate) probability distributions rather than the solution being a single optimal parameter set; and (ii) the posterior distributions of parameter values can exhibit dependencies between each other, rather than assuming each parameter to be independent from others. Note that the Bayesian framework does not assume that a single independent optimum can be reached. The density of the posterior distribution is proportional to the product of a likelihood and a prior term. The likelihood is given implicitly in the form of a loss function between observational data and model output, hence requiring the numerical solution of the model for each new set of parameters. Whereas the prior is a known density function (e.g., a Gaussian with known mean and covariance) and is provided from knowledge about the parameters of the model. As a solution algorithm we utilize an extension of MCMC, the parallel tempering MCMC method, which is critical for recovering distributions of parameter sets that are Subsequently, we introduce the HH-based neuron models that we consider for computational inference.
2.1. Inference of parameters in a three-channel Hodgkin-Huxley neuron modelWe introduce the algorithmic approach of our choice for solving an inverse problem involving a neural model. We utilize the parallel tempering MCMC method, which is described in detail below. To illustrate the type of solutions that parallel tempering MCMC can deliver, we first consider a three-channel (Na, K, and leak channels) Hodgkin-Huxley model, which is a classic and well-known conductance-based model (Hodgkin and Huxley, 1952; Mainen et al., 1995). While this model is less complex than the eight-channel model we focus on subsequently, this simpler model nevertheless exhibits the key difficulties and challenges of parameter estimation in neural dynamics. The mean squared error (MSE) between voltage traces from the model and simulated observational data serves as the loss function to measure the fit between model outputs and data for this example. To set up the inverse problem, we simulate the voltage trace for a given set of sodium and potassium conductances, denoted as the “true” parameter set, which is gNa = 200 pS/μm2 for sodium and gK = 50 pS/μm2 for potassium. This simulated voltage trace generated by the HH model serves as the data for our inverse problem; and the sodium and potassium conductances are the parameters that we aim to infer. The numerical results of the inference are presented in Section results.
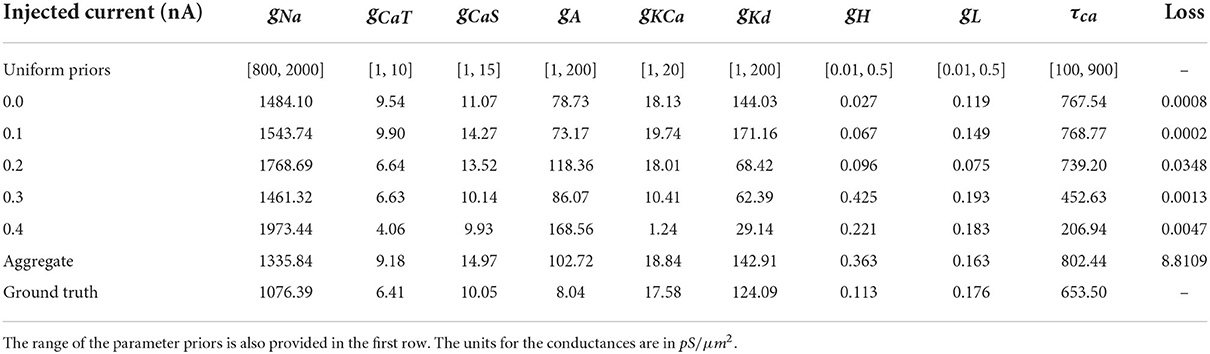
2.2. Inference of parameters in an eight-channel Hodgkin–Huxley neuron modelThe model that this work focuses on is the bursting neuron model from Alonso and Marder (2019). The model is a system of ODEs describing the time evolution of the membrane potential voltage coupled with kinetic equations for the eight voltage-gated conductances; for more details, see Equations (5–7) of Alonso and Marder (2019). We choose to analyze specifically this model because of its recently documented challenges with regards to parameter estimation, multiple candidate solutions, and complex dependencies of parameters on one another. We select the parameter values for the ground truth to be from “Model A” of Alonso and Marder (2019) for consistency. The definitions, units, and values used to generate ground truth voltage traces of the nine parameters that we seek to infer are in Table 1.
The voltage traces of the AM model are obtained numerically with the BDF and LSODA solvers for ODEs from the SciPy library (Petzold, 1983; Virtanen et al., 2020). BDF and LSODA were used because of their overall convergence performance compared with other ODE solvers for stiff biological ODE models; for instance, LSODA has been analyzed for biological systems in Städter et al. (2021). The voltage trace generated by the ground truth parameters is shown in Figure 7 in orange color. The output models of this work are available in ModelDB with accession number 267583.
2.3. Loss function for measuring fit between data and model outputsThe main loss function used in the present study involving the AM model is the loss of Equation (4) of Alonso and Marder (2019), namely,
E(g)=αEf+βEdc+γEmid+δEsw+ηElag,where we use the following coefficients: α = 1, 000, β = 1, 000, and γ = δ = η = 0. Ef is the mismatch of the inter-burst frequency (frequency between bursts), Edc is the mismatch of the inter-burst duty cycle (the ratio of the time bursting vs. not bursting per cycle), Esw and Emid handle slow-wave mismatches, and Elag is the lag between the upward crossings and downward crossings.
We purposefully eliminate several components of the loss (i.e., γ = δ = η = 0) to avoid manual penalization between certain terms in the general form of the loss function. Our study uses the same loss function with fixed coefficient values throughout all numerical experiments, because our focus is to compare inference results and it avoids possible bias. As such, our approach differs from the objectives of Alonso and Marder (2019), where the coefficients in the loss are adjusted depending on the inference setup. Here we focus on the two components of the loss function that we observed to be dominant, associated with α, the burst frequency mismatch Ef, and with β, the duty cycle mismatch Edc. The intra-burst frequency mismatch and duty cycle mismatch components are visible in Figure 7. Our objective is to test the multimodality of the inverse problem with parallel tempering MCMC methods.
2.4. Loss function for individual and aggregate constraintWe use the loss function (detailed in Section loss function for measuring fit between data and model outputs) to solve inverse problems, where one particular injected current is present; these studies are referred to as the individual current constraint. The individual current constraint (or “individual constraint” in short) is when the loss function value for a single current injection value (i.e., one of 0.0, 0.1 nA, …) is used for measuring the fit between data and model outputs.
In addition, we carry out numerical experiments with multiple injected currents, referred to as the aggregate current constraint. The aggregate current constraint (or “aggregate constraint” in short) is when the maximal loss function value for the entire set of injected currents (i.e., nA) is used for the misfit between data and model outputs. The aggregate current constraint is motivated by its similarity to fitting against a frequency-current (F-I) curve (Hultborn and Pierrot-Deseilligny, 1979).
2.5. Introduction and background to MCMCIn this work we choose the Bayesian formulation (also called Bayesian framework), which is based on Bayes' theorem:
P(θ∣y)=P(y∣θ)P(θ)P(y), (1)where θ denotes the parameters of the ODE model and y is the data. θ and y can be scalars or, more commonly, vectors. On the left-hand side of (1), P(θ ∣ y) is the unknown posterior (i.e., conditional probability for the model parameters θ given the data y). On the right-hand side of (1), P(y ∣ θ) is the known but often intractable likelihood (i.e., conditional probability for the data y given the model parameters θ). The likelihood term is responsible for measuring the fit between data and model outputs. Hence the loss function, which we detailed above, is evaluated each time the likelihood is computed. The likelihood being intractable means that it requires the solution of a model and cannot be accessed (or sampled from) directly. Further on the right-hand side, P(θ) is the known and typically tractable prior (i.e., probability of the model parameters θ). The term P(y) is called evidence (i.e., total probability of the data y); and since it is constant with respect to θ, it simply scales the posterior by a constant and can, in practice, remain unknown.
To provide an intuition, one goal of an MCMC algorithm, such as the Metropolis–Hastings algorithm (Metropolis et al., 1953; Hastings, 1970), is to find the most likely model parameters, θ, that will produce the largest posterior (the highest probability of the model parameters to reproduce the data) through sampling. Another goal is to quantify parameter uncertainties. To this end, the algorithm visits smaller locations in the posterior (i.e., lower probabilities of the model parameters to reproduce the data). However, these visits to lower-probability locations of the posterior happen adaptively and automatically at smaller frequencies. The concept of MCMC visiting locations of high probability at greater frequencies and locations of lower probability at smaller frequencies is a key property of the algorithm.
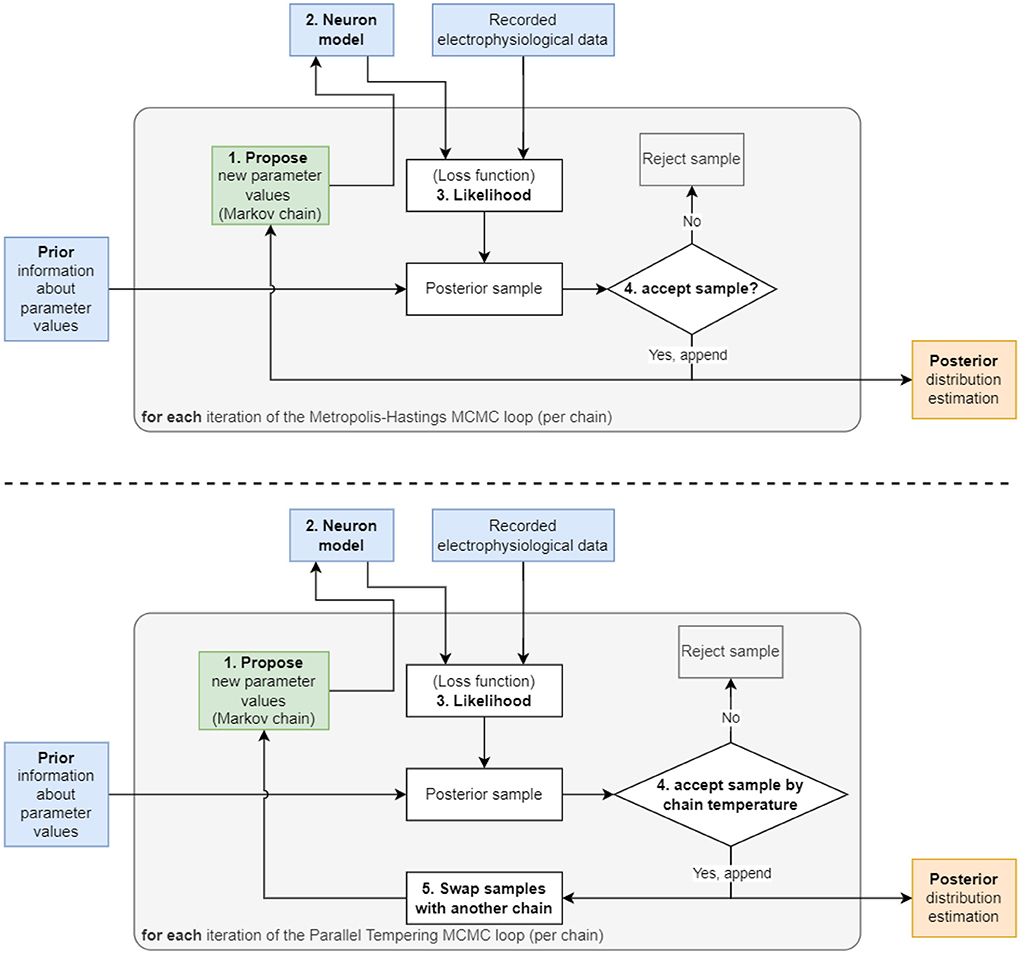
In detail, at each iteration of MCMC, the algorithm first proposes a new value for (one or multiple) parameters, θproposal, by randomly choosing from a proposal distribution (e.g., a normal distribution centered at the value of the previous iteration θprevious) (Figure 1). The likelihood P(y ∣ θproposal) and prior P(θproposal) are evaluated at the proposed value and multiplied to obtain a new value of the posterior. In the second MCMC iteration, the algorithm includes the proposed θproposal in a sequence of visited points or discards it, where the aim is to more frequently keep points of higher probability. To determine whether θproposal is accepted or rejected relative to the previous θprevious, the algorithm takes the ratio of the proposed posterior to the current posterior. If the ratio is greater than one, θproposal must have a higher probability, and therefore this new parameter is saved because it is producing a better outcome. If the ratio is below one, then the algorithm applies a randomized rejection criterion such that some θproposal is stored at lower frequencies. Subsequently, this cycle repeats, where θproposal becomes the new θprevious, if acceptance was successful. Note that in this algorithm, dividing the new value by the previous value of the posterior, P(y) cancels out, thus showing that constant scaling factors are irrelevant for MCMC.
Figure 1. Two diagrams depicting the flow of the two algorithms used in this work. (Top) The Metropolis–Hastings MCMC algorithm begins with a “1. Propose” step, where the algorithm selects an initial set of parameters to be used in the “2. Neuron model” step. The model is then solved using the parameters and its output compared to recorded data to produce the “3. Likelihood”. This likelihood is then multiplied with the prior to generate the probability value used in the “4. accept sample?” step to accept or reject the sample. This cycle is repeated until the number of preset iterations is reached. (Bottom) The Parallel Tempering MCMC algorithm used for the 9 parameter AM model. This algorithm utilizes an additional “5. Swap samples with another chain” step to increase mixing between multiple chains and to encourage the chains to sample in more remote areas of the parameter space, hence, detect multimodality.
The Metropolis–Hastings algorithm constructs a sequence, also called a chain, of parameters (also called samples) that it visits during the iterations (Figure 1). This method is suitable for unimodal posterior distributions. However, it is not designed to capture multimodal posteriors (i.e., posterior with multiple peaks). Therefore, extensions of MCMC have been developed to deal with multimodal distributions. Early work by Marinari and Parisi (1992); Geyer and Thompson (1995) employed simulated tempering, which is akin to simulated annealing algorithms from the field of optimization. More recently, parallel tempering MCMC (Łacki and Miasojedow, 2016; Vousden et al., 2016) was proposed. This builds on ideas from simulated tempering and, additionally, uses multiple chains of single-chain methods, such as Metropolis–Hastings, in parallel. The key idea of tempering, which enables MCMC to discover multimodalities in posteriors, is that the posterior is taken to a power with an exponent, γ, between zero and one: 0 < γ < 1. Hence we obtain Pγ(θ ∣ y). This has the effect that smaller locations in the posterior are elevated and can be visited more frequently by Metropolis–Hastings.
2.6. MCMC method for estimating parameters in AM modelThis section provided details about our implementation for estimating parameters and their uncertainties in AM models. Our AM model and MCMC methods constitute the following components:
• Neuron model component: Computes voltage traces for the AM model and a given set of candidate parameters
• Likelihood component: Computes the Bayesian likelihood using the loss function based on the voltage trace obtained by neuron model component
• Prior component: Evaluates the prior based on the candidate set of parameters
• Estimator component: Proposes candidate parameters at random (the proposal sampler)
The sampler used was the adaptive parallel tempering sampler (Miasojedow et al., 2013) within the PyPESTO library (Stapor et al., 2018). Parallel tempering runs independent Markov chains at various temperatures and performs swaps between the chains. Each individual chain runs adaptive Metropolis–Hastings MCMC.
The loss functions for individual and aggregate constraints are evaluated for each candidate parameter in the MCMC algorithm within the likelihood term. The prior term is defined as a uniform distribution (i.e., unbiased prior) within predetermined boundaries, which were chosen sufficiently wide to permit physiologically relevant model parameters.
2.7. Numerical experiment setupTo investigate the robustness of parallel tempering MCMC on the inverse problem governed by the AM model, we use model A from Alonso and Marder (2019), which is defined by the parameters that are listed in Section inference of parameters in an eight-channel Hodgkin–Huxley neuron model, as ground truth data. We use this model to generate five voltage traces each using different injected currents: 0.0, 0.1, 0.2, 0.3, and 0.4 nA. Noise to simulate physical measurement noise was not added to the voltage trace of the ground truth, for several reasons. To have a numerical experiment setup similar to Alonso and Marder (2019), we also did not alter the ground truth trace data.
The conductances for the ion channels and the time constant for the calcium channel are the nine parameters that we target for inference. Each inference with individual current constraint consisting of running the MCMC algorithm for a predetermined number of iterations/samples. Additionally, for the inference with aggregate current constraint, a single run of MCMC was performed. Each MCMC run used 24 to 32 parallel chains and 10,000 to 14,000 samples per chain. Geweke's convergence diagnostic was used to determine the burn-in of each chain (Stapor et al., 2018). The burn-in is an initial phase of MCMC where the gathered samples do not satisfy certain statistical properties to be considered adequate samples of the posterior. In certain cases, despite parallel tempering, there are MCMC chains that can remain static through the parameter space. Results from chains that did not move sufficiently (ratio of standard deviation to mean) were filtered out in postprocessing.
2.8. Software improvements for accelerating parallel tempering MCMCWe reduced the computational time of the MCMC inference by carrying out various improvements of the source code. Increasing the number of Markov chains benefits the detection and exploration of multimodal posteriors; however, it also increases the computation time. To shorten the computation time, we parallelized the MCMC algorithm to run on each CPU core concurrently using multiprocessing packages (Conda-Forge Community, 2015). This approach significantly decreased computation time because of the parallel nature of the chains. The total runtime for each MCMC run was between 24 and 48 h. We utilized three different machine architectures: (1) the Broadwell nodes (36-core, 128 GB RAM) on the parallel cluster Bebop at Argonne National Laboratory, (2) a workstation equipped with a dual 16-core Intel Xeon 4216 CPU (total of 32 cores and 64 threads) with 128 GB of RAM, and (3) a workstation with a 32-core (64-thread) AMD Ryzen 3970x CPU with 128 GB of RAM.
3. ResultsThe results of our study show that our design of the inverse problem combined with parallel tempering MCMC for solving the inverse problem is able to successfully overcome the inference challenges. The algorithm can recover large numbers of parameter sets where data and model output are consistent. Parallel tempering MCMC returns posterior distributions of parameter sets, called the posterior in short, and we visualize the multidimensional posterior by showing solution maps in one and two dimensions where the non-visible dimensions have been integrated out (i.e., showing a marginal distribution). With these solution maps physiologists can investigate the results from MCMC in order to decide which parameters warrant more investigation from a physiological perspective. This is a main advantage of solution maps compared with solution points (i.e., a single set of “optimal” parameters) obtained from optimization algorithms. Additionally, the robustness of parameters can be assessed, because solution maps indicate by how much parameters can be perturbed while still delivering model outputs that are consistent with data.
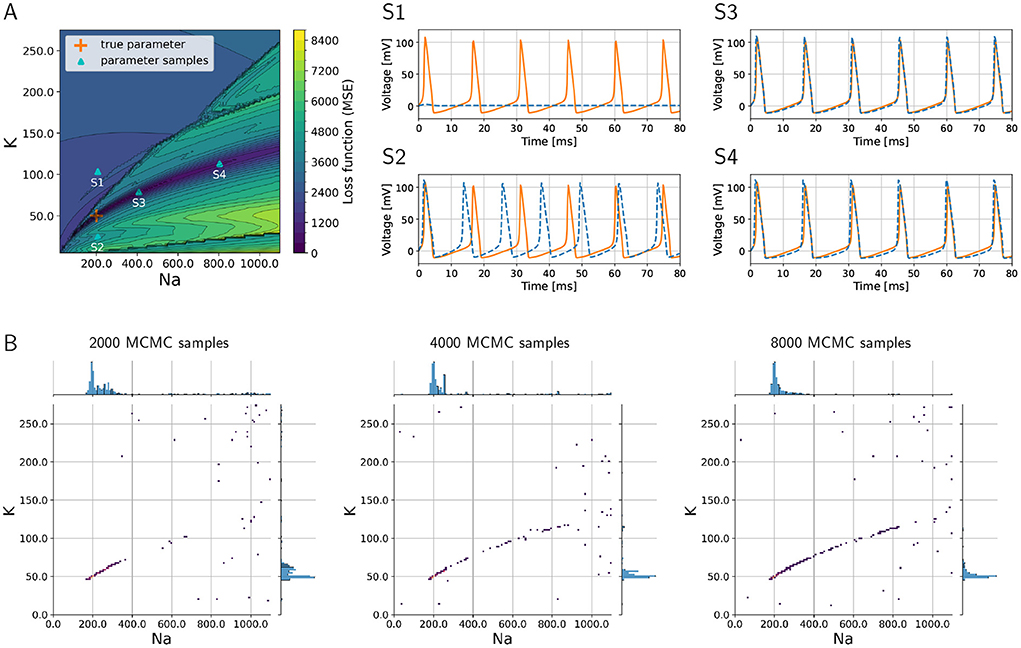
3.1. Inference proof of concept with the three-channel Hodgkin–Huxley modelAs a proof of concept, we consider the inverse problem where the goal is to recover the sodium and potassium conductances in an HH model. To demonstrate the challenges of the problem, we visualize the loss function that would have to be minimized to find the optimum in Figure 2A, where the colors indicate the (positive) loss value. The true parameter set is located in a “valley” in the loss “landscape,” whereas the loss is large for parameters that produce large discrepancies between model output and data such as shown in graph S1 corresponding to point S1 in Figure 2A. However, multiple sets of parameters exist that are local minima in this landscape, and these multiple local minima pose major challenges because optimization algorithms may present one of them as the “optimal” solution. These local minima will not give a sufficiently good fit of model outputs vs. data, as is illustrated in graph S2 of Figure 2 that corresponds to point S2 in the landscape (Figure 2A). Such local minima are known to be problematic for numerical optimization algorithms (Nocedal and Wright, 2006).
Figure 2. Loss function corresponding to the inverse problem with a three-channel HH model and how MCMC is able to successfully recover multiple optimal parameter sets and quantify uncertainties and parameter trade-offs. (A) Loss function landscape (colors) over the parameters, sodium (gNa) and (gK) potassium conductances. The “true” parameter set represents a global minimizer of the loss; the valley of the loss along points S3 and S4 (in dark blue color of loss) translates to parameter uncertainties (or trade-offs). Graphs S1–S4 depict voltage traces at corresponding points in (A). (B) Densities of MCMC samples, where the dark purple color of highest density overlaps with the true parameter set. As the number of MCMC samples increases, the the method recovers the valley of the loss landscape A and hence quantifies uncertainties in the parameters.
Additionally, we aim to quantify the uncertainty with respect to the parameters associated with sodium and potassium conductances, and we would like to understand the sensitivities of the model with respect to these parameters. In Figure 2, the graphs S3 and S4 illustrate how different parameters produce voltage traces similar to the data, while at the same time this uncertainty in the parameters is visible in the landscape as a valley (dark blue color in Figure 2A, which corresponds to low values of the loss function).
The numerical solution of the Bayesian inverse problem with parallel tempering MCMC successfully provides a probability density spanned by the two-dimensional parameter space. The density is large, where the loss function in Figure 2A has its major valley. We show the progress of the MCMC algorithm in Figure 2B as the number of collected samples increases from 2,000 to 8,000. As the sample count (i.e., iteration count of MCMC) grows, the algorithm generates a longer tail along the valley, showing a clearer picture of the parameter uncertainties. The true parameter values are clearly visible in the high-density region as a dark blue area around 200 and 50 pS/μm2 for sodium and potassium conductances, respectively. Furthermore, the tail to the upper right of the true parameter set shows the trade-off between sodium and potassium, when model outputs keep being consistent with data even though the values of the parameters deviate from the truth.
These results serve as a proof of concept that the parallel tempering MCMC algorithm can successfully tackle multimodal losses. Next we transition to a more complex model for neural dynamics, which is the focus and the main result of the present work.
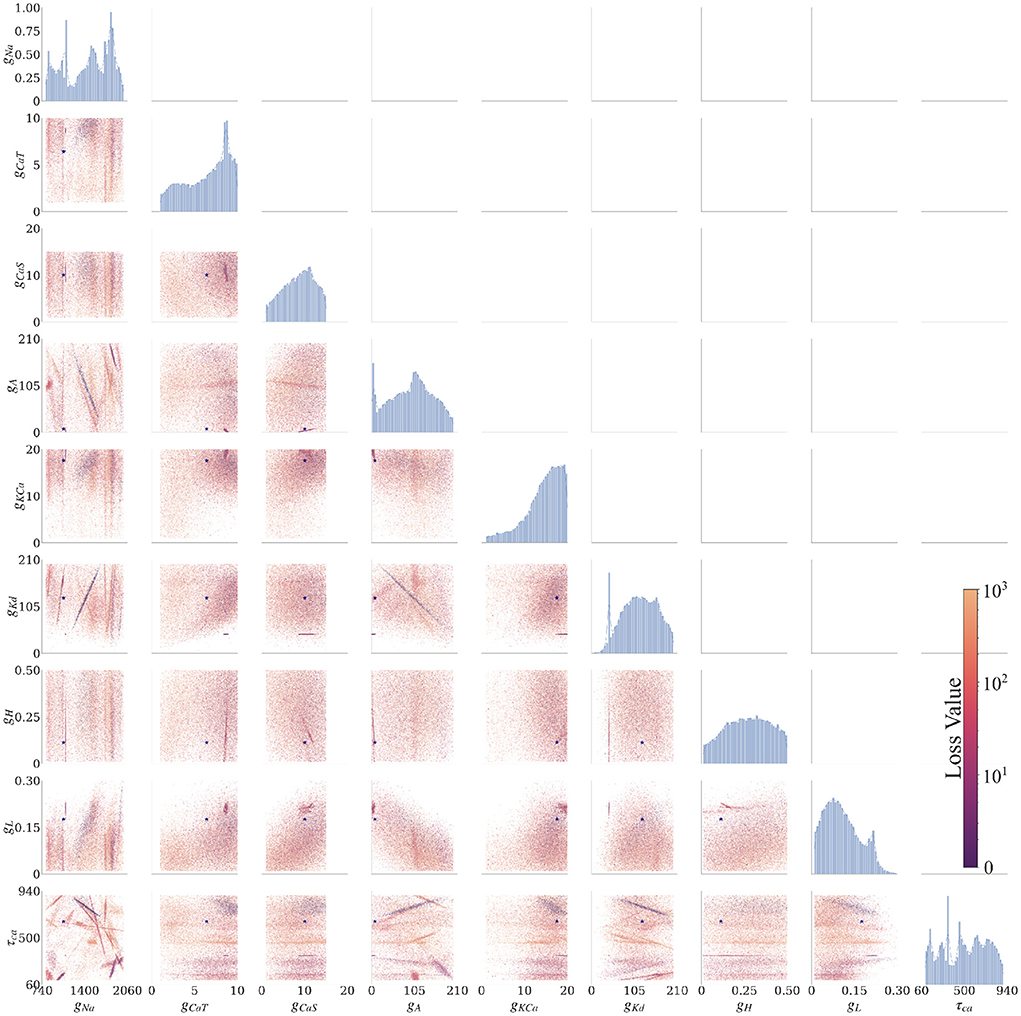
3.2. Inference with the complex eight-channel Alonso–Marder (AM) model 3.2.1. AM model—Posterior distributionThe AM model has nine uncertain parameters that we want to infer; therefore, the posterior is a distribution in a nine-dimensional space. To visualize the nine-dimensional space, we consider one or two parameters at a time, where the remaining parameter dimensions are marginalized (i.e., summed up). The plots in Figure 3 show the solution maps that visualize the posterior. The denser regions within Figure 3 are parameter value sets that return lower loss function values; therefore they represent better fits between data and model outputs.
Figure 3. Final solution map of the posterior for the 9 parameters of the AM model for the individual constraint of the 0.0 nA injected current. The diagonal plots show the 1D marginals of each parameter, where the x-axis is the search range of the parameter, and the y-axis is the normalized distribution. The remaining plots are the 2D marginals of pairs of parameters, where x- and y-axes are the range of the pairs of parameters. Each point within each plot is a sample found by the MCMC algorithm. The colors indicate the associated loss value of this sample, where the purple color indicates a lower loss value and the yellow color indicates a higher loss value. Density of points will contribute to the darkness of an area. The more pronounced a color signifies that more points are overlaid on top of each other. For example, in the top left 2D marginal [gCaT, gNa] the dark purple area around [gCaT, gNa]~[9, 1200] is an accumulation of many overlaid points. This density can also be traced back to the 1D marginals to the top and the left side. The ground truth values are plotted as a purple asterisk for comparison to low loss modes of the parameter spaces.
Along the diagonal of Figure 3 are the histograms for the (1D marginal) distribution for each parameter. For the 2D marginals in the lower triangle of Figure 3, the points have the opacity set to darker where their density is higher. This setup allows for easier visualization of trends within the posterior distribution with regard to parameter values. Note that the denser points for a particular parameter (gNa, for example) are not necessarily in the denser regions for another parameter (gKd, for example), if one considers different plots. Such links between two parameters can be established only when gNa, gKd are plotted along the two axes of the same 2D marginal. In other words, a solution set containing parameter values selected from the densest distributions of each parameter will not necessarily yield a good solution.
3.2.2. AM model—Individual constraintWe ran MCMC sampling on the AM model using individualized currents (0.0–0.4 nA at increments of 0.1 nA). This dataset is called the “Individual Constraint.” We also ran the MCMC search as a single aggregated search with all currents at once, which is discussed in a subsequent section. Below we present results from the individual constraints.
MCMC sampling produced solution maps of the posteriors for each of the individual currents (see Figure 3 for current 0.0 nA and the Supplementary Figures for all other currents). Within each of the maps one can search for the parameter set (i.e., a sample of MCMC) with the lowest loss value. Table 2 presents the results of such a search and one can consider the values listed in this table to be the optimal parameters, as recovered by MCMC. However, in addition to producing parameter sets with low loss values, the MCMC algorithm is able to recover the posterior distribution for all 9 parameters of the model within the search range for each injected current (0.0 to 0.4 nA, 0.1 nA increments).
Table 2. Parameter sets for the lowest loss values calculated by the MCMC algorithm.
We summarized these findings in an arrangement of plots in Figure 3 for 0.0 nA injected current and for currents 0.1–0.4 nA in the Supplementary material. The rows and columns of subplots are each associated with one of the parameters (gNa, gCaT, gCaS, gA, gKCa, gKd, gH, gL, and τCa). The interpretations of each of the plotted marginal types are explained in the following:
3.2.2.1. 1D marginalsThe diagonal portion of the subplot matrix shows the one-dimensional (1D) marginals (distribution histograms) of the solutions for each of the individual parameters. The x-axis represents the range of values, and the y-axis represents the probability of that value producing a good fit between data and model outputs. These distributions provide both the likeliest solutions (i.e., the peaks) as well as their uncertainty (distribution around the peaks). For example, the top left 1D marginal of the sodium conductance gNa has 4 peaks, and the width of these peaks allows to assess the uncertainty (or sensitivity) of the sodium conductance gNa.
3.2.2.2. 2D marginalsThe remaining subplots are the two-dimensional (2D) marginals of the posterior distributions. Each row and column represent a parameter θ of the model, and each of the points within the subfigure is a solution found by the MCMC algorithm. To show the probability distribution within the solution space, we set the alpha value (the transparency of the color) of each solution to α = 10−3 (where opaque is α = 1). A highly probable region has many more points and therefore will appear more opaque. The color of each point represents the loss value ranging from blue to yellow (low to high, respectively). These plots show the dependence of each parameter on another. Some of these dependencies are linear (for example, [row, col]: [gKd, gNa]), and some are non-linear (for example, [row, col]: [gKd, gCaT]). Some of the linear dependencies are vertical and horizontal, signifying that one parameter is independent from the other (for example, vertical [gH, gCaT], [gH, gNa] and horizontal [τCa, gCas]).
3.2.3. AM model—Aggregate constraintTo test the versatility of the MCMC algorithm at solving the inverse problem for HH-type equations, we combined all the input currents into a single analysis called “aggregate constraint” (more details given in Section methods).
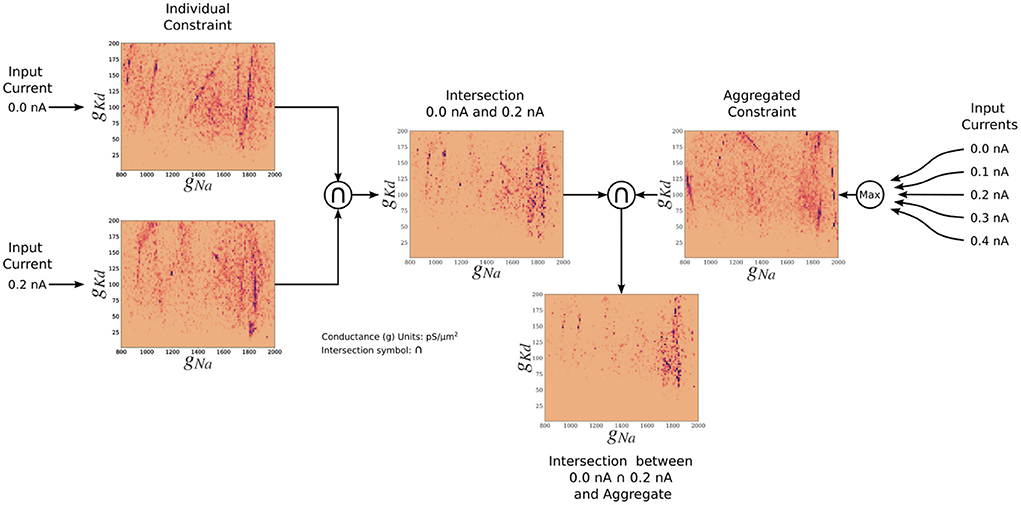
The posterior resulting from the aggregate constraint analysis is visualized as a solution map in Figure 4. The same analysis as for the individual constrained can be performed to determine the peaks and variations of individual parameters using the 1D marginals and the dependence of two parameters using the 2D marginals. Compared with the individual constraint, the loss values are higher; hence the yellow colors dominate in these maps. The aggregate constraint solution map encompasses a subset of the individual constraint solution maps. To illustrate this in Figure 5, we show the intersection (multiplication of the posterior) of the kernel density estimates (KDEs) of the solution maps from the aggregate constraint and the two individual constraints 0.0 and 0.2 nA, as an example. Figure 5 first depicts the intersection between the individual constraints 0.0 and 0.2 nA, and compares it to the aggregate constraint via an additional intersection (elementwise multiplication) to extract their commonalities. The distinctive features (in dark blue/purple color) found in the individual constraints are found in the intersection (bottom) even though they were not prominent in the aggregate constraint results. In the next section we formalize the commonalities between solution maps, which we hinted at with intersections, using a metric called the Wasserstein distance.
Figure 4. Solution maps of the posterior for the 9 parameters of the AM model for the aggregate constraint. The diagonal plots show the 1D marginals of each parameter. The x-axis is the search range of the parameter, and the y-axis is the normalized distribution. The remaining plots are the 2D marginals of pairs of parameters. The x- and y-axes are the range of the pairs of parameters. Each point within each plot is a sample found by the MCMC algorithm. The colors indicate the associated loss value of this sample, where purple color indicates a lower loss value and yellow color indicates a higher loss value. The density of the points will contribute to the darkness of an area. More pronounced color signifies that more points are overlaid on top of each other. This density can also be traced back to the 1D marginals to the top and the left side. The ground truth values are plotted as a purple asterisk for comparison to low loss modes of the parameter spaces.
Figure 5. Two-dimensional (gNa and gKd) kernel density estimates (KDEs) of the solution maps of different cases, for visualization of the relationship between the aggregate constraint and the individual constraints. The arrows indicate the flow of the operation. The KDEs of the 0.0 and 0.2 nA individual constraints are on the left. The KDE of the aggregate constraint is shown on the right. The intersection is the elementwise multiplication of two or more KDEs. The final intersection between 0.0, 0.2 nA, and aggregate constraint shows the contribution of the 0.0 and 0.2 nA individual constraints to the aggregate constraint. The colormap scales have been adjusted so that values are visible.
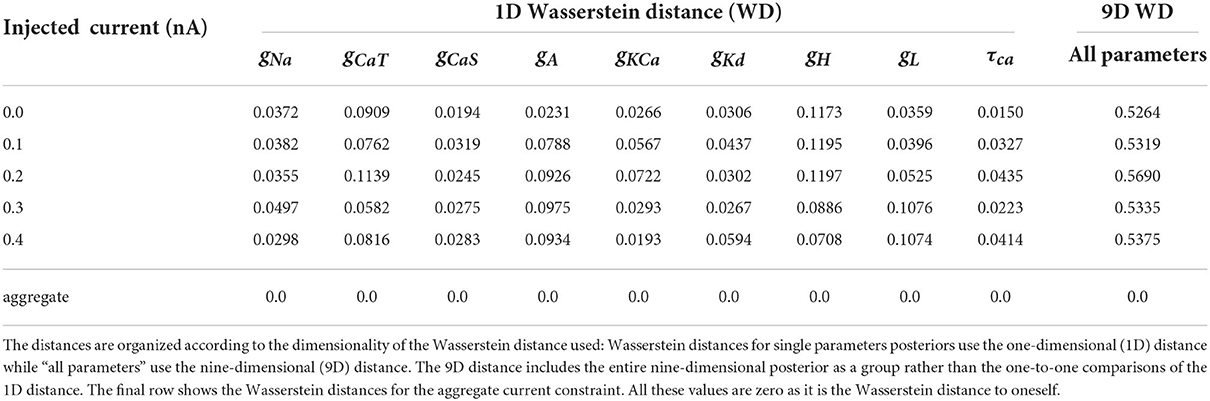
3.2.4. AM model—Distances between posterior distributionsTo demonstrate the differences between the posterior distributions of the AM model between an individual constraint and the aggregate constraint, we computed the approximate Wasserstein distance for each individual injected current's posterior distribution against the aggregate constraint's posterior distribution. We carried this out for the posteriors with respect to all nine parameters as well as individual parameters (via marginals as depicted along the diagonals of Figures 3, 4). The approximate Wasserstein distance provides a quantitative metric of the total cost required to transform one probability distribution to another probability distribution (Givens and Shortt, 1984). The results are displayed in Table 3, with the rightmost column showing the Wasserstein distance of the entire posterior distribution (all nine parameters used) for a specific injected current. Overall, the posterior distribution of no injected current (0.0 nA) yields the closest (by Wasserstein distance) posterior distribution to the aggregate constraint, followed by 0.2 nA, then 0.1 and 0.3 nA.
Table 3. Normalized (using the chosen bounds of each parameter) Wasserstein distances for each posterior of individually injected currents against the aggregated constraint's posterior.
The parameter's posterior distributions that are the most different between an individual constraint and the aggregate constraint are the distributions for the parameter gH and to a lesser extent for gCaT, gA, gL. This observation for the Wasserstein distances is consistent with the 1D marginal solution maps of the posterior when comparing the aggregate constraint in Figure 4 with Figure 3 and the additional solution maps of the posterior for other individual currents in the Supplementary material.
4. DiscussionAlonso and Marder (2019) presented a complex and realistic neurological model and proposed visualization techniques in order to help understand how different parameter sets can have similar model outputs. As did, Van Geit et al. (2007), Druckmann et al. (2007), and Prinz et al. (2003), they identified the challenge to find multiple parameter sets that are optimal in the sense that they generate good fits between data and model outputs. Consequently, this raised the need to develop algorithmic approaches in order to find these multiple sets.
In the present work, we design the inverse problem in a Bayesian framework, where multiple optimal parameter sets are part of a single multimodal posterior distribution. Furthermore, we utilize parallel tempering MCMC in order to recover the multiple modes in the posterior and visualize them in the solution maps. As a result, we have filled an important need in the field of neuroscience.
4.1. Interpreting solution maps and choosing parameter setsThe solution space that the MCMC algorithm provides (the solution maps) can be overwhelming especially when one is familiar with the classical gradient/optimization approach to an inverse problem (i.e., a single solution). Instead, our Bayesian framework provides continuous ranges of solutions from which one can select individual parameter value sets. We present two viewpoints as methods to interpret these results, the single-solution viewpoint, and the multimodal viewpoint.
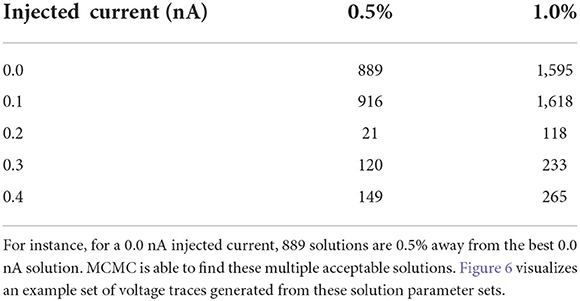
4.1.1. Single-solution viewpointAs detailed in the Section results, one parameter set amongst all the posterior samples produces the lowest loss value (see Table 2). At the simplest interpretation, one could choose this parameter set as the solution to use. However, the Section results demonstrates that there are many parameter sets that provide low loss values which are close to the lowest value. For instance, we found, for the injected current of 0.0 nA, a total of 889 parameters are within 0.5% of the best parameter set and a total of 1,595 parameter samples are within 1% of the lowest loss (see Table 4). Of course, the precise numbers are dependent upon the number of MCMC iterations, but it shows that vast amounts of parameters are able to reproduce a given observational data as it is scored by the loss function. It is important to note that the loss function plays a crucial role here in measuring the fitness between data and model outputs (for more details, see Section impact of loss function on recovered parameters).
Table 4. Number of solutions given the injected current as a function of percentage difference from the best solution.
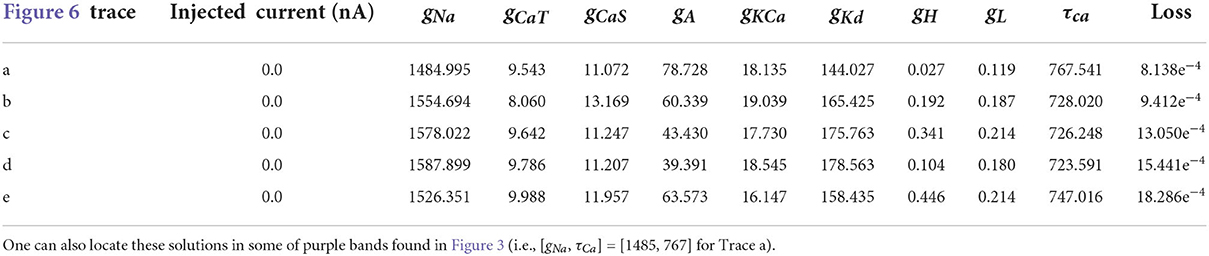
Table 5. Parameters for the first 5 solutions for the injected current 0.0 nA. The voltage traces for each of these parameters sets are shown in Figure 6.
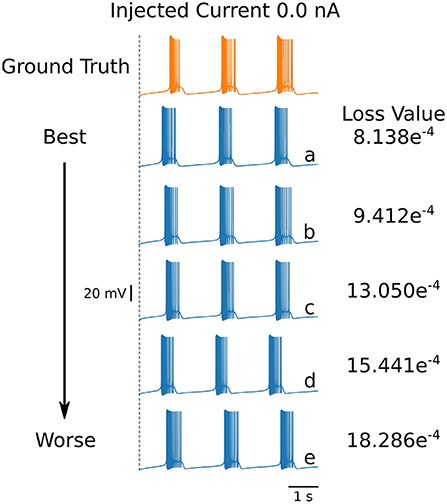
Even though the loss values are small for the parameters in Table 4, the voltage traces produced by these sets are slightly different. To illustrate these differences, we plot in Figure 6 the first five voltage traces in the order of the loss value from best to (slightly) worse with respect to the ground truth shown (shown in orange color). The change in loss value is smaller than 10−2 and nearly identical for the last two traces (d) and (e). However, these traces visually appear to be somewhat different, thus illustrating that different parameter sets may yield similar loss values while producing potentially different traces when inspected by eye. It highlights the crucial role of the loss function, and it shows that it is important for physiologist to inspect the solution maps, visualizing the posterior, to further investigate or constrain parameter ranges.
Figure 6. First 5 solutions for the injected current of 0 nA. These solutions are ranked from “best” to “worse” (A–E) according to their loss. Even a nearly-identical loss can produce a qualitatively different voltage trace, as shown by traces (D,E). The values for the parameters sets for each of the voltage traces can be found in Table 5.
4.1.2. Multimodal viewpointBecause of the preceding observations, it is beneficial to look for multiple modes or parameter value regions (rather than a single point) in the posterior: this is illustrated in the 1D and 2D marginals described in the Section results. In the 1D marginals, one can assess important parameter values within a range by the different peaks observed within the distribution as well as its sensitivity by the width/spread under peaks. Furthermore, the limitation of parameter bounds defined by the prior can be determined, if distributions appear to abruptly stop at the boundaries. For instance, in the 1D marginal for parameter gKCa found in Figure 3, it appears that the limits of the range for gKCa values may have been too small as the distribution begins a descent at the upper bound. Such insight can lead the modeler to reconsider or investigate the range of the parameters. The 2D marginals help to determine which parameters are correlated (i.e., trade-off between each other). Taken together, one can begin to look at solution areas that previously were left unexplored, perhaps opening new avenues for investigation. This possibility allows for investigators to be able to examine a selection of parameter value set solutions found, rather than just utilizing the parameter value set of the lowest loss solution.
We now recall the ground truth values of the parameters that we used in the numerical experiments (see Section methods) and compare them to the plots of the posteriors in Figures 3, 4. We note that the parameter values used to generate the ground truth do not always correspond to the areas under the peaks in the marginals of the plotted solution maps of the posterior. For instance, the parameter values of gNa, gH, and gL used for the ground truth do not correspond to areas of high density in the solution maps. We believe one possible reason for this is that some of the ground truth parameter values give rise to models that are less robust compared with the parameter values where peaks in the posterior are higher and/or wider as recovered by MCMC. Since the presented algorithm provides parameter sensitivities and the solution maps of the posterior enable to interpret these sensitivities, an evaluation of the robustness of estimated parameters is possible. This can lead to potentially important insights toward understanding neuron models.
4.2. Impact of loss function on recovered parametersThe impact of the choice of loss function becomes apparent in Figure 7, which shows the ground truth voltage trace generated from the AM model with the ground truth set of parameters (orange color). This trace serves as the data in our inverse problem. To measure the fit between data and model outputs, we consider a particular loss function that is derived from the loss function employed by Alonso and Marder (2019). Comparing the orange (ground truth) and the blue trace graphs, we observe discrepancies between the traces that may appear as inadequate fits from a physiological perspective. These discrepancies are caused by the loss function, which defines a distance metric between traces. In essence, a possible limitation of the chosen loss function is that it quantifies disparate voltage traces as too similar by giving it a low loss value. This demonstrates the difficulty of finding appropr
留言 (0)