
記住我



In recent decades, early reperfusion therapy and adjunctive pharmacotherapy have improved the outcomes of acute myocardial infarction (AMI) (1). Globally, in-hospital mortality has decreased from 29% in 1969 (2) to approximately 5% today (3, 4). However, the contemporary in-hospital mortality varies substantially across patients in different risk groups. Risk stratification in patients with AMI is important for clinical decision-making. Traditional risk score systems mostly derive from ideal clinical trials with stringent patient cohort selection (5–7). We aimed to develop and assess a risk prediction model in a real-world cohort.
The complete blood count with differential (CBC w/diff) test provide a wealth of information on the inflammatory state, oxygen-carrying capacity, and coagulation state. Many indices are accepted prognostic markers for short- and long-term outcomes following AMI, such as white blood cell count (WBC) (8), neutrophil to lymphocyte ratio (NLR) (9), platelet to lymphocyte ratio (PLR) (10), systemic immune-inflammation index (SII, calculated as P × N/L, where P and N/L are the absolute platelet count (PLT) and the NLR, respectively) (11), and red cell distribution width (RDW) (12). The CBC w/diff indices have drawn strong interest because of their low-cost and easy availability in clinical practice. However, existing cardiovascular prognostic scoring systems do not include predictors derived from the CBC w/diff indices. Moreover, it is unclear whether a comprehensive model incorporating all of these indices would have better predictive ability, and which index is the most powerful predictor among them has yet to be identified. Hence, we used all of these indices to create a prediction model and ranked the predictive values in order of importance to the model.
Traditional regression models are constrained by a failure to account for non-linear effects and complex interactions among predictor variables (3). In this study, we developed a prediction model based on the neural network method. Our model’s prediction performance was then compared to other models developed using the most recently published classical machine learning methods, including traditional logistic regression (LR), k-nearest neighbor (KNN), support vector machine (SVM), Gaussian naive Bayes (GNB), adaptive boosting (AdaBoost), decision tree (DT), and random forest (RF).
We aimed to develop a CBC w/diff-based neural network prediction model for in-hospital mortality among patients with severe AMI in the CCU, as well as to identify the most important predictor variable in the CBC w/diff test.
Materials and methods Design, data source, and ethical statementThis current study was a single-center retrospective study. We used the clinical information of patients from a public database to develop a prediction model for in-hospital mortality.
We obtained data from a freely available public database called the Medical Information Mart for Intensive Care-IV (MIMIC-IV, Published: March 16th, 2021. Version: 1.0)1 (13). This database contains de-identified clinical data of a large number of patients admitted to the Beth Israel Deaconess Medical Center (BIDMC, Boston, MA, USA) from 2008 to 2019 (inclusive). One of the authors gained access to the dataset by completing the Collaborative Institutional Training Initiative program course (Certificate Record ID: 39690061).
Informed consent was waived for this study because of the perfect anonymous data. We conducted this study in accordance with the Declaration of Helsinki. We report this study according to the Transparent Reporting of multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD) guidelines (14).
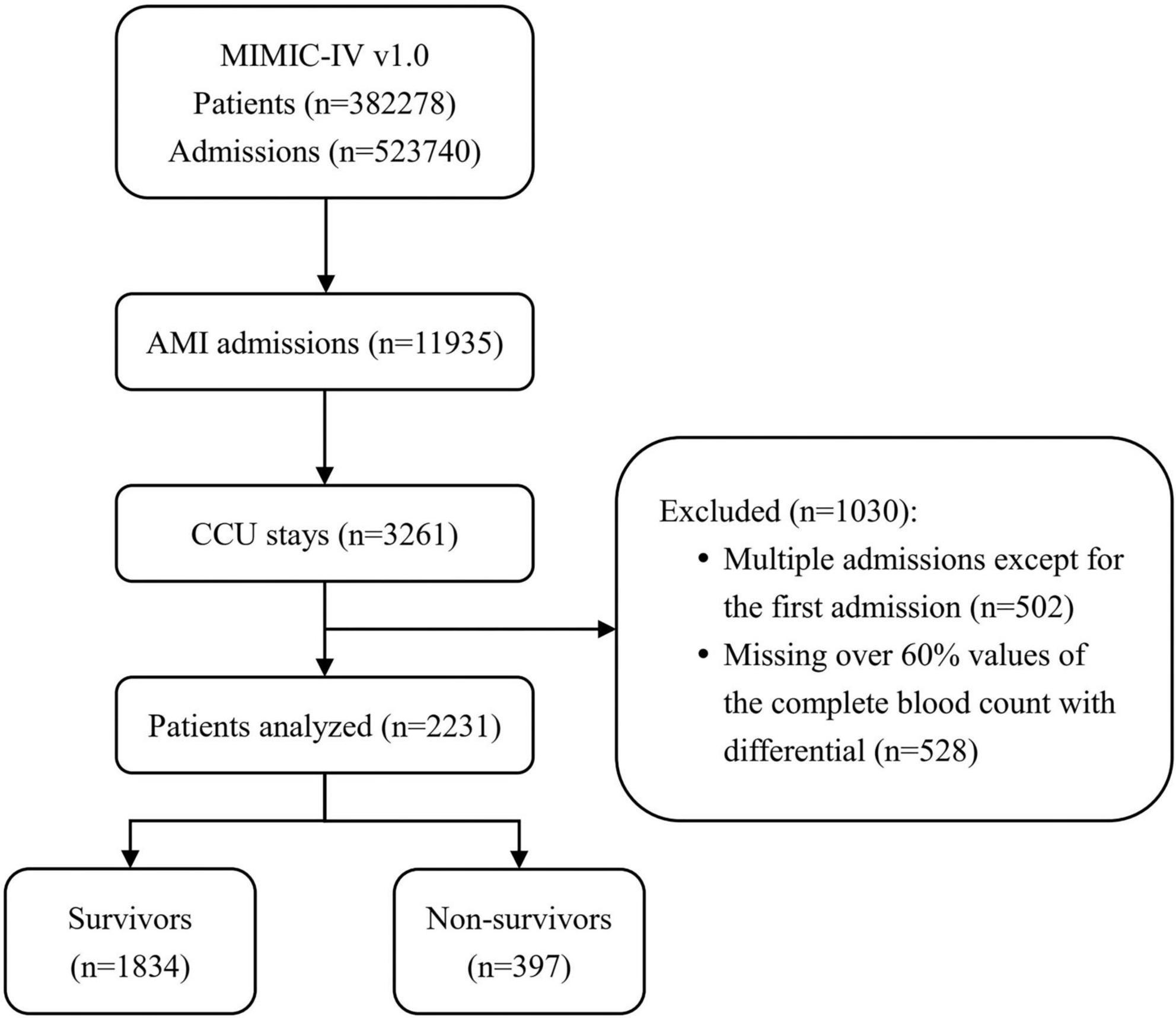
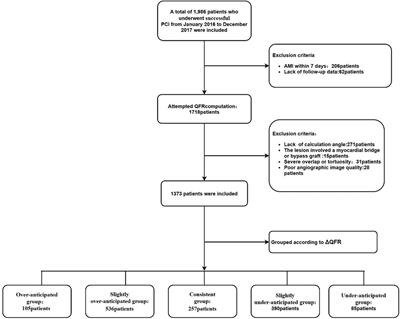
Patient selectionIn the initial inclusion cohort, all patients with International Classification of Diseases, 9th revision (ICD - 9) codes of the 410 groups or ICD, 10th revision (ICD-10) codes of the I21 groups (the ICD codes of AMI) were included on discharge. Then, those admitted to the CCU were chosen from these patients. To improve comparability among patients, only initial admission data were used for patients admitted to the hospital more than once. Finally, patients who had a CBC w/diff test with more than 60% missing values were excluded. Figure 1 shows the details of the selection process used in this study.
FIGURE 1
Figure 1. Flowchart of patient inclusion. The medical information mart for intensive care IV (MIMIC-IV) (version 1.0) database includes medical records of 5,23,740 admissions from 3,82,278 patients. In total, 11,935 admissions had a discharge diagnosis of acute myocardial infarction (AMI), of which 3,261 were admitted to the coronary care unit (CCU). After excluding 502 multiple admissions except for the first admission and 528 patients missing over 60% values of the complete blood count with differential (CBC w/diff) test, 2,231 patients were ultimately included in this study, of whom 397 died. MIMIC, medical information mart for intensive care; AMI, acute myocardial infarction; CCU, coronary care unit; CBC w/diff, complete blood count with differential.
Data extractionWe extracted the data using structure query language (SQL) with PostgreSQL software (version 13) and Navicat Premium software (version 15). The code that supports the MIMIC-IV is publicly available.2 In addition to the parameters in CBC w/diff at admission, we also extracted the baseline characteristics related to patients’ cardiovascular risks, including demographics, comorbidities, laboratory values, and other clinical parameters. The outcome of interest was all-cause in-hospital death marked in the electronic medical record system on discharge. We did not calculate the sample size because all selected data in the database were used to maximize the generalizability and power of the findings.
Missing valuesMissing values were imputed by the missForest method (15), which has been proven to outperform all other algorithms. After completing the missing values, we normalized the 19 variables by column to facilitate subsequent data analysis.
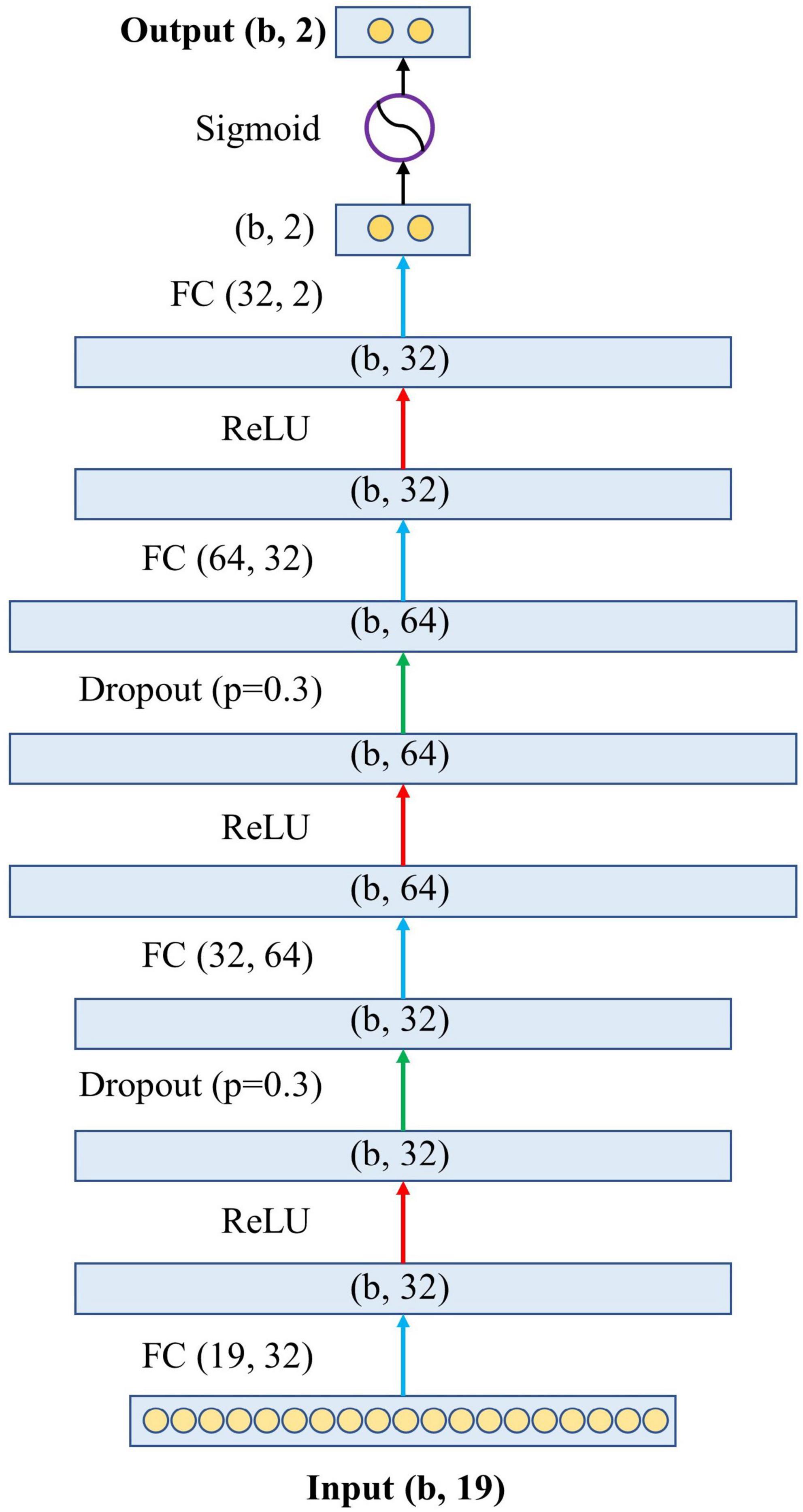
Model developmentFigure 2 shows the architecture of the proposed model. Specifically, the proposed model has one input layer, one output layer, and four hidden layers in between. The input layer contains 19 neurons, representing the 19 variables in the blood test. The output layer contains two neurons representing the predicted probabilities of the model for survival and death, and the sum of these two probabilities is 1. The four hidden layers have feature dimensions of 32, 64, 32, and 2. This design simulates the complex relationship between variables and outcomes by allowing the 19 variables to undergo sufficient non-linear transformation. The hidden layers are connected by the activation function Rectified Linear Unit (ReLU) (16) and the dropout layer (17). Finally, before the output layer, there is a Sigmoid function (18) to generate the final association outcome. The Sigmoid function was chosen because it shrank the final output values into an S-shaped curve ranging from 0 to 1, representing the probability value predicted by the model.
FIGURE 2
Figure 2. The architecture of the proposed neural network. The letter “b” in the figure represents the batch size of the model, which is the number of samples used to train a single forward and backward pass. FC, fully connected layer; ReLU, rectified linear unit.
Our neural network was built using PyTorch (version 1.1.2). We chose stochastic gradient descent (19) as the optimizer. The weighted cross-entropy (20) was used as the loss function, where the weight of negative samples was set to 0.2, and the weight of positive samples was set to 0.8. This weight set was created because the number of negative samples is roughly four times that of positive samples. In addition, the relevant hyperparameter settings were as follows: epoch was set to 200, batch size was 32, learning rate was 0.001, and momentum was 0.9.
The model’s final performance was determined by taking the average of the results of the 5-fold cross-validation, which is currently a preferred technique in computer science.
Statistical analysisTwo-sided P-values ≤ 0.05 were considered statistically significant. Baseline characteristics analyses were conducted using SPSS software (version 23). Other statistical analyses were calculated and plotted using Python (version 3.7.5).
Comparison of baseline characteristicsThe baseline characteristics of patients were compared between survivors and non-survivors. The Kolmogorov–Smirnov test was used to assess the normality of the distribution. Data are presented as the mean with standard deviation for normally distributed continuous variables or median with interquartile range for skewed data. Independent sample t-tests or Mann–Whitney U tests were used as appropriate. Categorical variables are presented as absolute numbers with percentages and were compared by using the chi-square test.
Model assessmentThe performance of our newly developed model was evaluated using discrimination and calibration on the testing set in accordance with the guidelines of the Discrimination and Calibration of Clinical Prediction Models (21). Our model’s discrimination performance was compared to seven classical machine learning models (including LR, KNN, SVM, GNB, AdaBoost, DT, and RF) and five well-studied CBC w/diff clinical indicators (including WBC, RDW-CV, NLR, PLR, and SII). WBC was the whole white blood cell count. RDW-CV was the red blood cell distribution width-coefficient of variation in this study. The NLR was the ratio of the absolute count or percentage of neutrophils to lymphocytes. The PLR was the absolute platelet to lymphocyte count ratio. The SII was calculated as P × N/L, where P was the absolute PLT and N/L was the NLR. To evaluate discrimination performance, receiver operating characteristic (ROC) curves were plotted. The area under the curve (AUC) with 95% confidence interval (CI), sensitivity, specificity, accuracy (ACC), precision, and F1-score were all calculated. DeLong’s test was used to assess the difference in AUC between our model and another model or index. To demonstrate the calibration performance, a calibration curve was constructed. Given that the visual representation of the correlation between predicted and observed values is sufficient to evaluate calibration performance and that statistical tests such as the Hosmer–Lemeshow test have limitations (21), we did not test for significant differences. We also calculated the Brier score. The Brier score offers a more comprehensive assessment of model performance, combining model discrimination and calibration. The Brier score represents the mean squared difference between the predictions and the observed outcome. When two models are compared, a smaller Brier score indicates better model performance.
Feature importance rankThis study applied a permutation test to evaluate the importance rank of features (22). According to permutation test theory, a feature is considered important if the model’s prediction error increases after permuting its values, indicating that the model’s predictive capability is heavily reliant on that feature. The importance of a feature in our model was determined by its effect on ACC and AUC. A feature was considered important if the sum of ACC and AUC deteriorated significantly as a result of the permuting process.
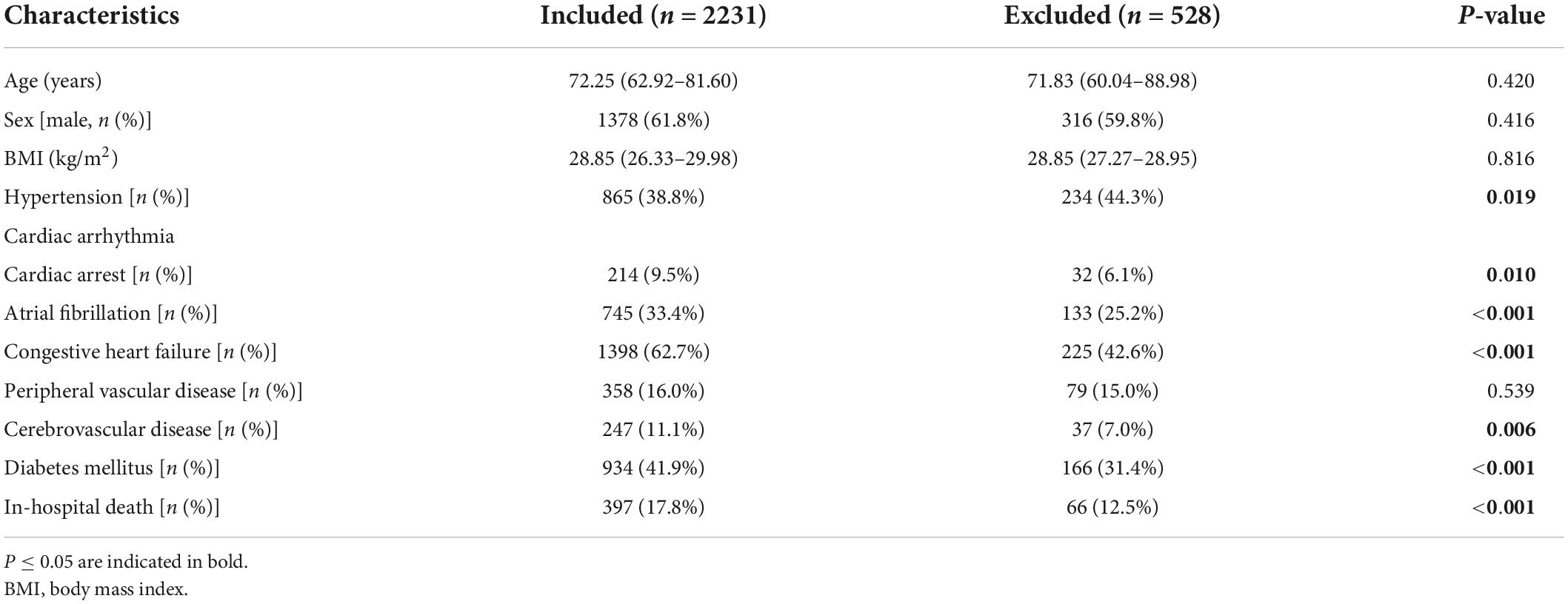
Results Baseline characteristics of the study populationAccording to the study objective, we included medical records from the MIMIC-IV database of patients diagnosed with AMI who were admitted to the CCU for the first time. After the selection process, 2,759 records were found to be eligible, but 528 of them had incomplete data, with more than 60% of the CBC w/diff values missing. Ultimately, a total of 2,231 medical records were included in this study. We compared the baseline characteristics of patients who were included and those who were excluded due to missing data (Table 1). There was no statistically significant difference between the two groups in terms of age, sex, or body mass index (BMI). Notably, patients in the included group had a higher rate of comorbidities and in-hospital mortality than patients in the excluded group. This study aimed to mine data from the severe population in the intensive care records database, so mortality was markedly higher than in other studies in general medical centers.
TABLE 1
Table 1. Comparison of baseline clinical characteristics between included and excluded patients.
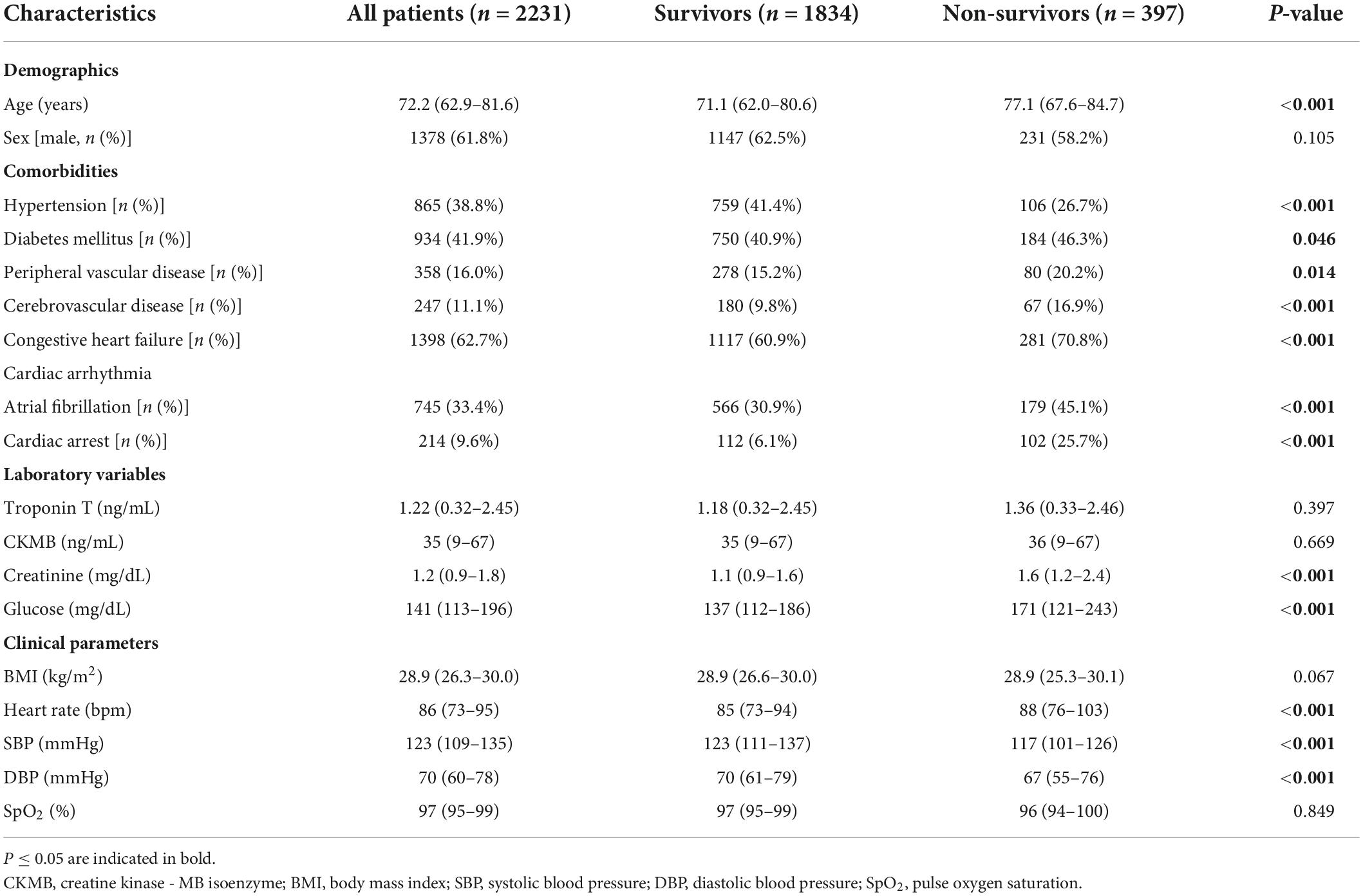
Table 2 shows the baseline characteristics of the 2,231 patients who were included in the study. Among the 2,231 patients (median age, 72.2 [62.9–81.6] years; sex, 1,378 [61.8%] male), 397 [17.8%] died in the hospital. The characteristics of survivors and non-survivors were compared. The non-survival group had a higher age, more comorbidities, higher blood creatinine, higher blood glucose, a faster heart rate, and lower blood pressure than the survival group.
TABLE 2
Table 2. Comparison of baseline clinical characteristics between survivors and non-survivors in the included cohort.
The majority of predictor variables in the CBC w/diff test at admission were included in our newly developed model. Table 3 shows the levels of each variable in all patients, as well as in the survival and non-survival groups. The values of the majority of variables differed significantly between the survival and non-survival groups.
TABLE 3
Table 3. Comparison of baseline complete blood count with differential characteristics between survivors and non-survivors in the included cohort.
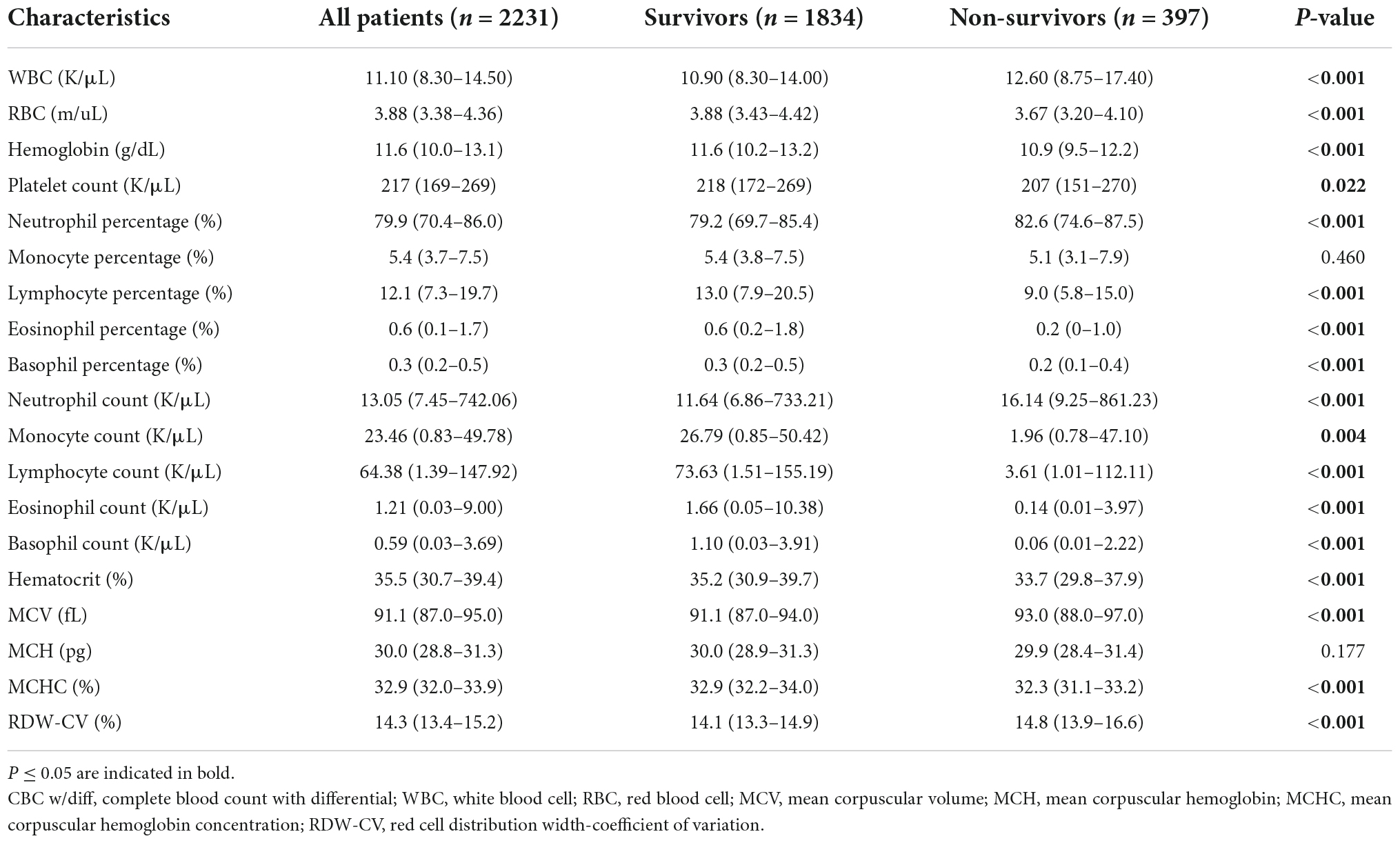
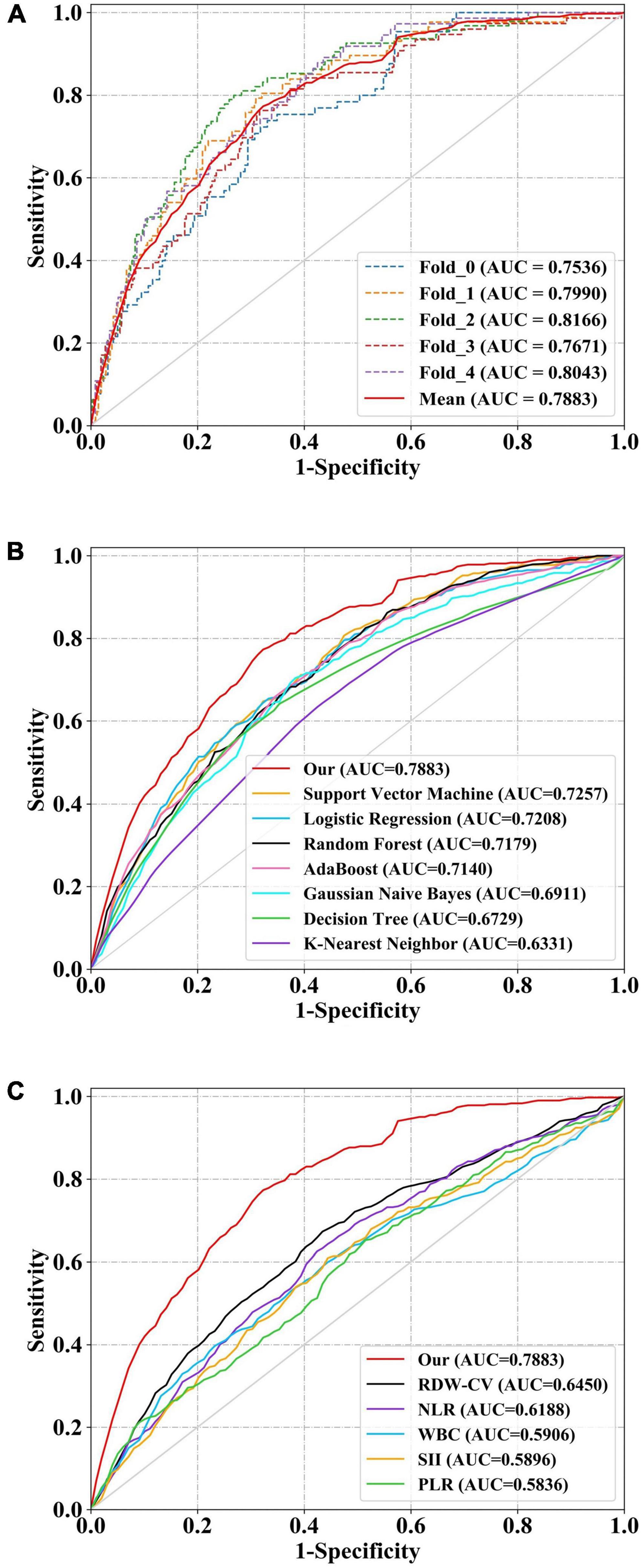
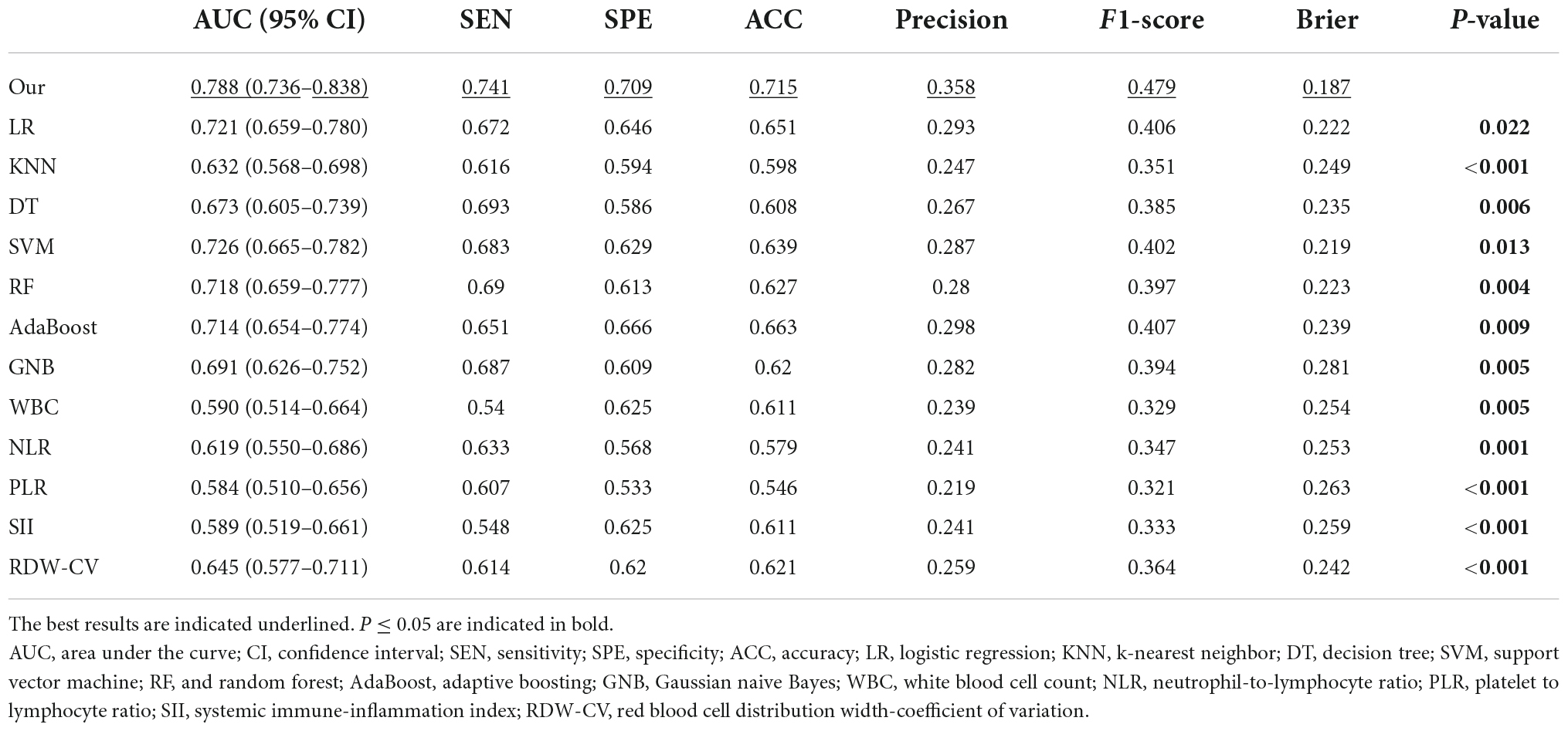
The discrimination performance of models and clinical indicesAll model discrimination performance results reported were from the best-performing models with optimized hyper parameters. As shown in Figures 3A,B and Table 4, our model had relatively ideal discrimination performance with a mean AUC of 0.788 (95% CI, 0.736–0.838), sensitivity of 0.741, specificity of 0.709, ACC of 0.715, precision of 0.358, and F1-score of 0.479. DeLong’s test revealed that our model’s AUC was significantly higher than that of the other models (P < 0.05). Furthermore, in terms of sensitivity, specificity, ACC, precision, and F1-score, our model outperformed all other models. Overall, our model had better discrimination performance than other models.
FIGURE 3
Figure 3. Receiver operator characteristic (ROC) curves of models and indices for predicting in-hospital mortality. The solid red line indicates the mean ROC curve of our neural network model. (A) The solid red line indicates the average result of the 5-fold cross-validation. The other five dotted lines represent the result of each fold. (B) Our model had a significantly higher mean area under the curve (AUC) of 0.788 (95% CI, 0.736–0.838) than other models [including logistic regression (LR), k-nearest neighbor (KNN), support vector machine (SVM), Gaussian naive Bayes (GNB), adaptive boosting (AdaBoost), decision tree (DT), and random forest (RF)] (P < 0.05). (C) The AUC of our model also outperformed that of other indices [includingwhite blood cell count (WBC), neutrophil-to-lymphocyte ratio (NLR), platelet to lymphocyte ratio (PLR), systemic immune-inflammation index (SII), and red blood cell distribution width-coefficient of variation (RDW-CV)] (P < 0.05). ROC, receiver operator characteristic; AUC, area under the curve; CI, confidence interval; LR, logistic regression; KNN, k-nearest neighbor; DT, decision tree; SVM, support vector machine; RF, and random forest; AdaBoost, adaptive boosting; GNB, Gaussian naive Bayes; WBC, white blood cell count; NLR, neutrophil-to-lymphocyte ratio; PLR, platelet to lymphocyte ratio; SII, systemic immune-inflammation index; RDW-CV, red blood cell distribution width-coefficient of variation.
TABLE 4
Table 4. Discrimination performance of all models and indices.
Our model’s discrimination performance was also superior to that of some well-studied CBC w/diff-derived clinical indices, such as WBC, RDW-CV, NLR, PLR, and SII. As shown in Figure 3C and Table 4, our model’s AUC was significantly higher than that of other indices (P < 0.05). In addition, when sensitivity, specificity, ACC, precision, and F1-score were all considered, our model outperformed all other clinical indices.
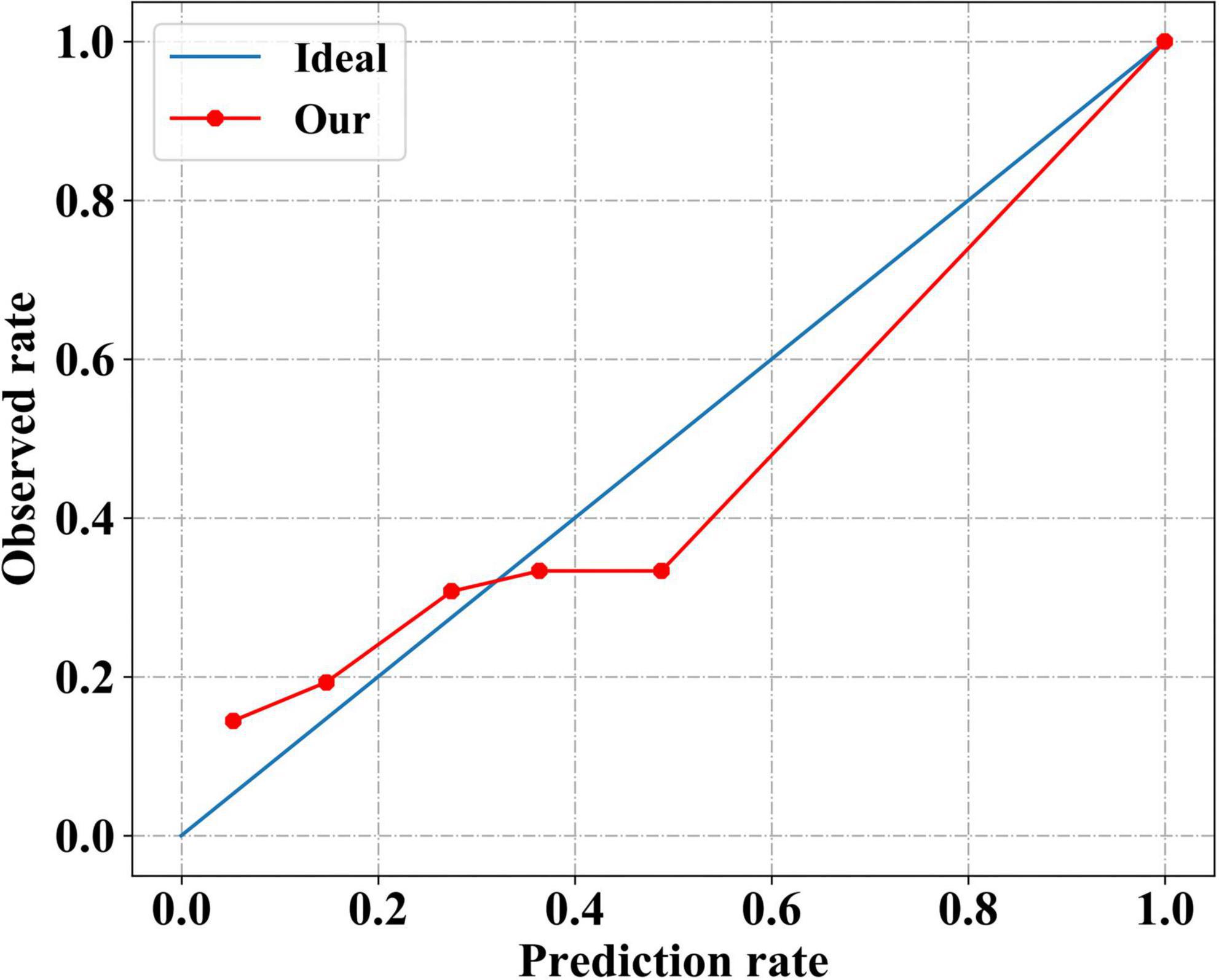
The calibration performance of our modelThe calibration curve of our model was plotted to evaluate the calibration performance (Figure 4). The death risk predicted by our model agreed with the observed death rate to some extent, indicating that our model performed well in estimating the absolute risk. Intuitively, among patients with an actual mortality risk of less than 30%, our model slightly underestimated the mortality risk. In contrast, among patients with a higher actual mortality risk, our model overestimated the mortality risk slightly. As a more comprehensive assessment index of model performance, the Brier scores are shown in Table 4. Our model had a small Brier score, indicating it had good performance in both discrimination and calibration.
FIGURE 4
Figure 4. Calibration performance of our neural network model. The solid red line indicates the calibration curve of our neural network model, which closely matches the blue ideal calibration curve.
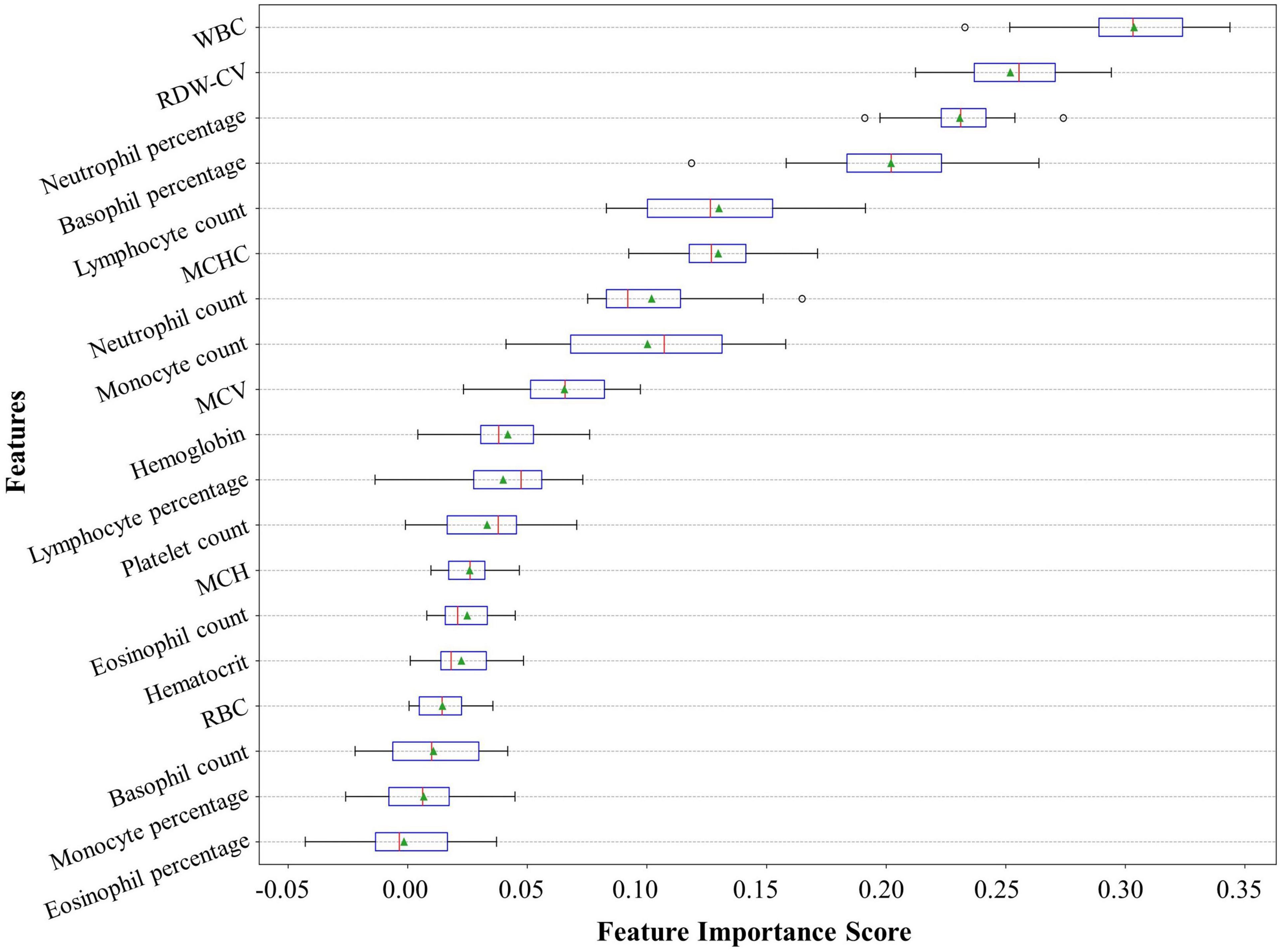
Feature importanceThese predictors ranked in descending order of importance were WBC, RDW-CV, neutrophil percentage, basophil percentage, lymphocyte count, mean corpuscular hemoglobin concentration (MCHC), neutrophil count, monocyte count, mean corpuscular volume (MCV), hemoglobin, lymphocyte percentage, PLT, mean corpuscular hemoglobin (MCH), eosinophil count, hematocrit, red blood cell count (RBC), basophil count, monocyte percentage, and eosinophil percentage (Figure 5).
FIGURE 5
Figure 5. Feature importance ranking of our neural network model. The feature importance rank denotes how heavily our model relies on a predictor variable. The relative importance rank of the 19 predictor variables from the complete blood count with differential (CBC w/diff) test in our model is shown. CBC w/diff, complete blood count with differential; WBC, white blood cell; RDW-CV, red cell distribution width-coefficient of variation; MCHC, mean corpuscular hemoglobin concentration; MCV, mean corpuscular volume; MCH, mean corpuscular hemoglobin; RBC, red blood cell.
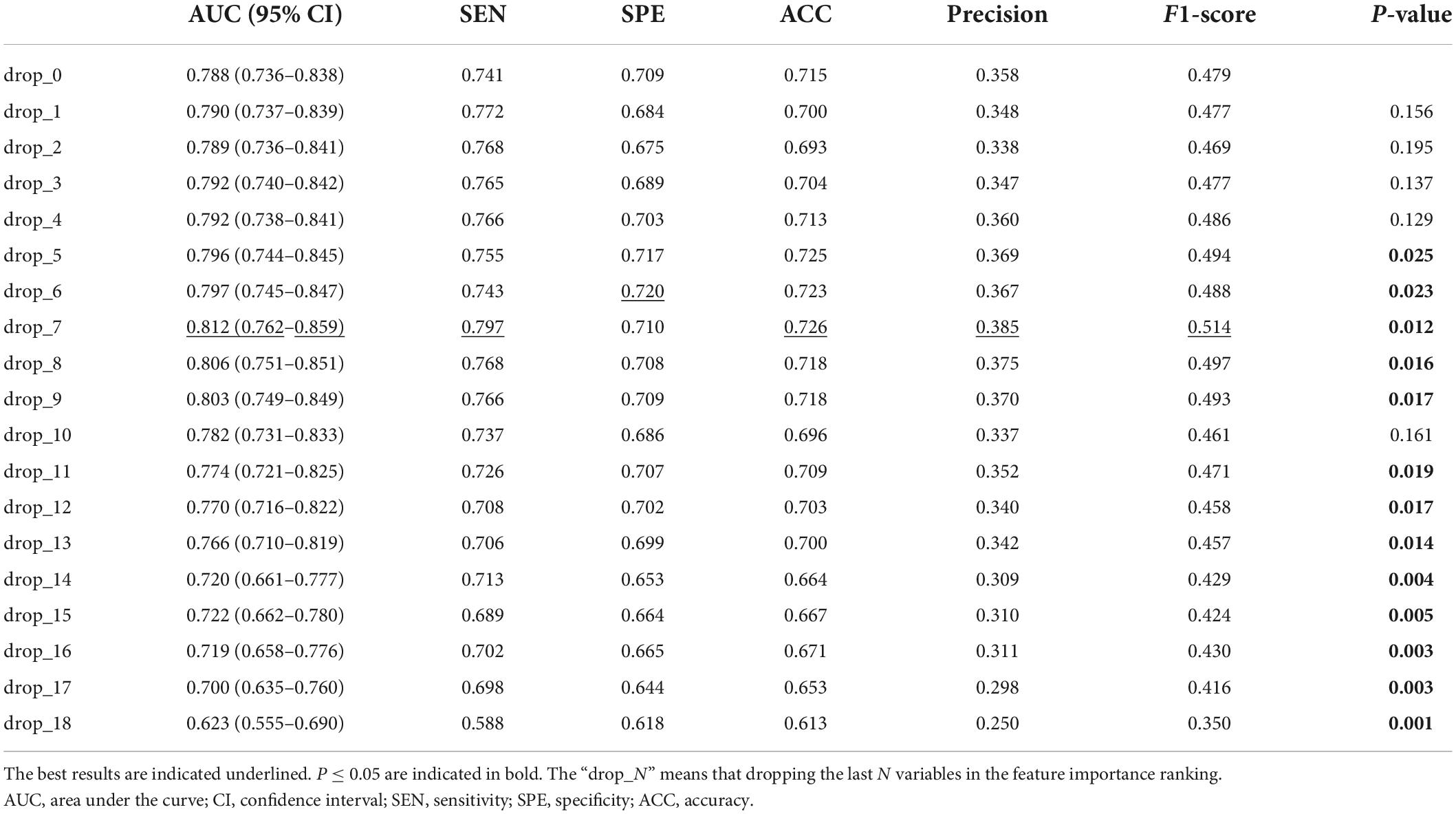
It can be seen that some variables played weak roles in improving the discrimination performance of the model. So, we dropped one to N variables with poor prediction values step by step and observed the change in the discrimination performance of our model. As shown in Table 5, we can see that: (1) dropping several variables with poor prediction values could help the model to improve its discrimination performance; (2) when seven variables were dropped, the discrimination performance of the model was the largest with an AUC of 0.812 (95% CI, 0.762–0.859) (P < 0.05); (3) the AUC of our model was decreasing significantly as more than ten variables were dropped.
TABLE 5
Table 5. Discrimination performance of our model after dropping variables with poor prediction values.
DiscussionEarly clinical decision-making is crucial for patients suffering from severe AMI. Thus, in the present study, we developed a convenient and rapid risk stratification model for in-hospital mortality. This model consisted of 19 predictor variables from the CBC w/diff test and was built with a neural network algorithm. The discrimination performance of the model was superior to that of clinical indices derived from the CBC w/diff test and models built based on seven other classical machine learning algorithms. Moreover, as shown in the calibration curve, the model exhibited good performance in estimating the absolute risk. Finally, after using a permutation test to rank the 19 predictor variables in order of importance for the model, the top three important predictors were WBC, RDW-CV, and neutrophil percentage. Then, by dropping several variables with poor prediction values, we surprisingly got better discrimination performance of the model.
To further explore the clinical application of our model, we examined its performance in subgroups with different myocardial infarction types and demographics. We extracted subgroups of the ST-elevation myocardial infarction (STEMI) and the non-ST-elevation myocardial infarction (NSTEMI) patients according to the ICD codes from the discharge diagnosis list. Of the total 2,231 patients, 319 had a definite diagnosis of STEMI, and 442 had a definite diagnosis of NSTMI. After predicting the in-hospital mortality risk for two subgroups separately, we found that our model outperformed other clinical indicators in both subgroups (Supplementary Tables 1, 2). Additionally, as shown in Supplementary Table 3, our model performed well in both male and female subgroups, as well as in young (≤65 years) and old (>65 years) subgroups.
Prognostic value of complete blood count with differential indices in acute myocardial infarctionComplete blood count with differential is commonly performed today because of its low cost and ease of availability in clinical practice. In recent years, the CBC w/diff indices have piqued the interest of researchers since they have been verified to provide a wealth of independent information on pathophysiology and risk stratification. The red blood cell indices provide information about the oxygen-carrying capacity. Elevated RDW (12) and decreased MCHC (23) have been linked to higher in-hospital and long-term mortality in patients with AMI. The white blood cell indices provide information about the inflammatory and immune systems. Leukocytes play important roles in the development and progression of AMI because they not only permeate the endothelial layer and induce formation of microvessels in the tunica intima, resulting in plaque rupture (24), but they also amplify the inflammatory cascade after AMI (25). The elevated WBC count was found to be connected to congestive heart failure, shock, and increased mortality among patients with AMI (8, 26). Furthermore, the prognostic value of the count and percentage of neutrophils in AMI has also been confirmed (27, 28). Platelet indices indicate thrombotic risk and inflammatory activation to some extent, since platelets participate in thrombogenesis and interact with leukocytes (29). Mean platelet volume (MPV) and platelet distribution width (PDW) are important markers of platelet activation (30), as well as strong and independent predictors of mortality in patients with AMI (31, 32). Given that oxygen-carrying capacity, inflammatory and immune status, and thrombotic risk all play key roles or may have interacted in the pathophysiology of AMI, several composite indices were developed and proved to be strong predictors of adverse outcomes following AMI. These composite indices include the NLR (9), PLR (33), WBC/MPV ratio (34, 35), and SII (11). The newly developed model in this study integrated all available indices in the CBC w/diff test reported by the MIMIC-IV database, and was supposed to have more substantial predictive power than other indices. In contrast to other machine-learning models and clinical indices, the excellent discrimination performance of our model was ultimately confirmed.
We ranked the predictors using a permutation test. The top three predictors were WBC, RDW-CV, and neutrophil percentage. The prognostic value and pathophysiological significance of these three predictors have been well studied, which partly confirmed the practical application value of our model. However, it is important to note that the high performance of the neural network-based algorithm comes at the sacrifice of the interpretability of the relationship between predictive factors and the outcome of interest. Although some blood components seem to have poor prediction values, which does not mean that they are of poor pathophysiological significance. The rank result can only be a hint, but not the evidence.
In this study, for the purpose of aiding in early clinical decision-making, we used the first CBC w/diff test result immediately after admission to create our model. Nevertheless, there is indisputable that the dynamic change of the blood cells has significant prognostic value in AMI. Foy et al. (36) have identified a universal recovery trajectory defined by exponential WBC decay and delayed linear growth of PLT, which provides a generic approach for identifying high-risk patients with acute inflammatory diseases, including AMI. It means that the CBC w/diff test has more prognostic value to be developed in the future.
Machine learning algorithms in the prediction modelMost traditional risk models for cardiovascular disease are based on regression methods. While robust and useful, these methods are limited to using a small number of predictors and presupposing the linear and homogeneous effects of the predictors on the outcome. New methods for developing risk models are urgently needed because of the increasing ubiquity of large datasets, such as Electronic Health Records. Since machine learning algorithmic models can include more variables and produce more flexible relationships between predictors and outcomes, they have shown significant value in risk model development. For patients with AMI, state-of-the-art machine learning models have steadily improved the discrimination performance of risk stratification (3, 4, 37).
As canonical “black box” algorithms, neural networks apply the non-linear transformation to the predictor variables, hence being able to model many heterogeneous and non-linear effects (3). However, due to those multiple hidden layers in the transformation process, the interpretability of causal relationships between predictor variables and outcomes of interest can be challenging. Of note, interpretability is not necessary for the development of prediction models, where the focus is on the prediction performance instead of the predictors.
Strengths and limitationsThere are several strengths of the newly developed model. First, it is a well-performing CBC w/diff-based neural network model derived from a real-world cohort aiming at risk stratification purposes among patients with AMI in the CCU, making it suitable for severely ill patients diagnosed with AMI in the CCU. Of note, this model needs to be recalibrated and updated appropriately when used in other medical centers, which means that the hyper-parameters need to be slightly optimized. Second, the CBC w/diff test’s low cost and easy availability promotes clinical application and facilitates rapid clinical decision-making. Third, as intuitively demonstrated by the calibration curve, the new model slightly underestimated the mortality risk among patients with an actual mortality risk of less than 30% and overestimated the mortality risk among patients with a higher actual mortality risk, thereby avoiding unnecessary and excessive tests in low-risk patients, and, more importantly, avoiding treatment delays in high-risk patients. Fourth, the neural network algorithm used in the new model showed competence in prediction and can be applied to develop other prediction models.
However, the new model has several limitations. First, the retrospective study design makes the data susceptible to selection and measurement biases. Yet, the cohort analyzed in this study was collected prospectively and reflected real-world data, which may convey more practical significance. Second, causal relationships between predictors and the outcome cannot be established due to limited interpretability. This is a commonly recognized shortcoming of neural network models. All causal inferences require further experimental verification. Third, the model has not been externally validated. However, iterated cross-validation enhances the strength of the results. Fourth, missing data may lead to potential bias. But, the proportion of missing values was very low (less than 7.4%) in the study cohort. Moreover, for missing data imputation, we adopted the missForest method, an excellent machine learning-based data imputation algorithm. Fifth, the predictor variable list lacks platelet indices, including PDW and MPV, as they are unavailable in the database. Finally, although the newly developed CBC w/diff-based model has excellent performance in predicting in-hospital mortality among patients with AMI in the CCU, it is obvious that the comprehensive risk of these patients cannot be assessed solely based on this laboratory test. The additional value of the CBC w/diff variables to other existing risk scores, such as the thrombolysis in myocardial infarction (TIMI) or global registry of acute coronary events (GRACE) scores, was not determined, as most components of these scores were not available in this public database. According to the original publication of the GRACE model (38), it’s AUC in the derivation, the internal validation, and the external validation datasets were 0.83, 0.85, and 0.79, respectively. It seems that the predictive ACC of the CBC w/diff-based model is close to that of the GRACE model. In the future, this model should strive to validate its prognostic value in the combined analysis with conventional scores, such as the GRACE and TIMI scores.
ConclusionWe developed a risk prediction model based on the neural network algorithm for in-hospital mortality among patients with AMI in the CCU. The top three important predictors in this model were WBC, RDW-CV, and neutrophil percentage. The model is simple and easy to use. After entering 19 variables from the CBC w/diff test, the final prediction result can be easily obtained with just one click on a Python command. The relevant codes are available on the GitHub website.3 We believe the proposed method can be used as a quick and easy risk assessment tool for clinical decision-making.
Data availability statementPublicly available datasets were analyzed in this study. This data can be found here: MIMIC-IV repository, https://doi.org/10.13026/s6n6-xd98.
Ethics statementEthical review and approval was not required for this study on human participants in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Author contributionsYW, CFL, DG, and FR: conceptualization and project administration. CFL, MY, and BR: data curation and analysis. CL, JZ, and ZL: methodology. YW and CFL: writing and editing. All authors read and approved the final manuscript.
FundingThis research was supported by the National Natural Science Foundation of China (grant number: 81872563).
AcknowledgmentsWe thank the staff for MIMIC public database development and maintenance.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary materialThe Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcvm.2022.1001356/full#supplementary-material
AbbreviationsACC, accuracy; AMI, acute myocardial infarction; AdaBoost, adaptive boosting; AUC, area under the curve; BIDMC, Beth Israel Deaconess Medical Center; BMI, body mass index; CBC w/diff, complete blood count with differential; CKMB, creatine kinase - MB isoenzyme; CI, confidence interval; CCU, coronary care unit; DBP, diastolic blood pressure; DT, decision tree; FC, fully connected layer; GNB, Gaussian naive Bayes; GRACE, Global registry of acute coronary events; ICD, International classification of diseases; KNN, k-nearest neighbor; LR, logistic regression; MCH, mean corpuscular hemoglobin; MCHC, mean corpuscular hemoglobin concentration; MCV, mean corpuscular volume; MPV, mean platelet volume; MIMIC, Medical Information Mart for Intensive Care; NLR, neutrophil-to-lymphocyte ratio; NSTEMI, non-ST-elevation myocardial infarction; PDW, platelet distribution width; PLR, platelet to lymphocyte ratio; RF, random forest; RBC, red blood cell; ROC, receiver operating characteristic; ReLU, rectified linear unit; RDW-CV, red blood cell distribution width-coefficient of variation; SBP, systolic blood pressure; SEN, sensitivity; SII, systemic immune-inflammation index; SPE, specificity; SpO2, pulse oxygen saturation; SQL, structure query language; STEMI, ST-elevation myocardial infarction; SVM, support vector machine; TIMI, thrombolysis in myocardial infarction; TRIPOD, transparent reporting of multivariable prediction model for individual prognosis or diagnosis; WBC, white blood cell count.
Footnotes ^ https://doi.org/10.13026/s6n6-xd98 ^ https://github.com/MIT-LCP/mimic-code ^ https://github.com/duweidai/CBC2AMI References1. Rahimi K, Duncan M, Pitcher A, Emdin CA, Goldacre MJ. Mortality from heart failure, acute myocardial infarction and other ischaemic heart disease in England and Oxford: a trend study of multiple-cause-coded death certification. J Epidemiol Community Health. (2015) 69:1000–5. doi: 10.1136/jech-2015-205689
PubMed Abstract | CrossRef Full Text | Google Scholar
2. de Vreede JJ, Gorgels AP, Verstraaten GM, Vermeer F, Dassen WR, Wellens HJ. Did prognosis after acute myocardial infarction change during the past 30 years? A meta-analysis. J Am Coll Cardiol. (1991) 18:698–706. doi: 10.1016/0735-1097(91)90792-8
CrossRef Full Text | Google Scholar
3. Goldstein BA, Navar AM, Carter RE. Moving beyond regression techniques in cardiovascular risk prediction: applying machine learning to address analytic challenges. Eur Heart J. (2017) 38:1805–14. doi: 10.1093/eurheartj/ehw302
PubMed Abstract | CrossRef Full Text | Google Scholar
4. Kwon JM, Jeon KH, Kim HM, Kim MJ, Lim S, Kim KH, et al. Deep-learning-based risk stratification for mortality of patients with acute myocardial infarction. PLoS One. (2019) 14:e0224502. doi: 10.1371/journal.pone.0224502
PubMed Abstract | CrossRef Full Text | Google Scholar
5. Fox KA, Dabbous OH, Goldberg RJ, Pieper KS, Eagle KA, Van de Werf F, et al. Prediction of risk of death and myocardial infarction in the six months after presentation with acute coronary syndrome: prospective multinational observational study (GRACE). BMJ. (2006) 333:1091. doi: 10.1136/bmj.38985.646481.55
PubMed Abstract | CrossRef Full Text | Google Scholar
6. Addala S, Grines CL, Dixon SR, Stone GW, Boura JA, Ochoa AB, et al. Predicting mortality in patients with ST-elevation myocardial infarction treated with primary percutaneous coronary intervention (PAMI risk score). Am J Cardiol. (2004) 93:629–32. doi: 10.1016/j.amjcard.2003.11.036
PubMed Abstract | CrossRef Full Text | Google Scholar
7. Morrow DA, Antman EM, Charlesworth A, Cairns R, Murphy SA, de Lemos JA, et al. TIMI risk score for ST-elevation myocardial infarction: a convenient, bedside, clinical score for risk assessment at presentation: an intravenous NPA for treatment of infarcting myocardium early II trial substudy. Circulation. (2000) 102:2031–7. doi: 10.1161/01.cir.102.17.2031
CrossRef Full Text | Google Scholar
8. Sabatine MS, Morrow DA, Cannon CP, Murphy SA, Demopoulos LA, DiBattiste PM, et al. Relationship between baseline white blood cell count and degree of coronary artery disease and mortality in patients with acute coronary syndromes: a tactics-TIMI 18 (treat angina with aggrastat and determine cost of therapy with an invasive or conservative strategy- thrombolysis in myocardial infarction 18 trial)substudy. J Am Coll Cardiol. (2002) 40:1761–8. doi: 10.1016/s0735-1097(02)02484-1
CrossRef Full Text | Google Scholar
9. Azab B, Zaher M, Weiserbs KF, Torbey E, Lacossiere K, Gaddam S, et al. Usefulness of neutrophil to lymphocyte ratio in predicting short- and long-term mortality after non-ST-elevation myocardial infarction. Am J Cardiol. (2010) 106:470–6. doi: 10.1016/j.amjcard.2010.03.062
PubMed Abstract | CrossRef Full Text | Google Scholar
10. Azab B, Shah N, Akerman M, McGinn JT Jr. Value of platelet/lymphocyte ratio as a predictor of all-cause mortality after non-ST-elevation myocardial infarction. J Thromb Thrombolysis. (2012) 34:326–34. doi: 10.1007/s11239-012-0718-6
PubMed Abstract | CrossRef Full Text | Google Scholar
11. Öcal L, Keskin M, Cerşit S, Eren H, Özgün Çakmak E, Karagöz A, et al. Systemic immune-inflammation index predicts in-hospital and long-term outcomes in patients with ST-segment elevation myocardial infarction. Coron Artery Dis. (2022) 33:251–60. doi: 10.1097/mca.0000000000001117
PubMed Abstract | CrossRef Full Text | Google Scholar
12. Dabbah S, Hammerman H, Markiewicz W, Aronson D. Relation between red cell distribution width and clinical outcomes after acute myocardial infarction. Am J Cardiol. (2010) 105:312–7. doi: 10.1016/j.amjcard.2009.09.027
PubMed Abstract | CrossRef Full Text | Google Scholar
13. Goldberger AL, Amaral LA, Glass L, Hausdorff JM, Ivanov PC, Mark RG, et al. Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals. Circulation. (2000) 101:E215–20. doi: 10.1161/01.cir.101.23.e215
CrossRef Full Text | Google Scholar
14. Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. The TRIPOD group. Circulation. (2015) 131:211–9. doi: 10.1161/circulationaha.114.014508
PubMed Abstract | CrossRef Full Text | Google Scholar
16. Nair V, Hinton GE editors. Rectified linear units improve restricted boltzmann machines Vinod Nair. In: Proceedings of the International Conference on International Conference on Machine Learning. Haifa (2010).
17. Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. J Machine Learn Res. (2014) 15:1929–58. doi: 10.1109/TCYB.2020.3035282
PubMed Abstract | CrossRef Full Text | Google Scholar
18. Han J, Moraga C editors. The influence of the sigmoid function parameters on the speed of backpropagation learning. In: Proceedings of the International Workshop on Artificial Neural Networks: From Natural to Artificial Neural Computation. Torremolinos (1995).
19. Amari S. Backpropagation and stochastic gradient descent method. Neurocomputing. (1993) 5:185–96. doi: 10.1016/0925-2312(93)90006-O
CrossRef Full Text | Google Scholar
20. Ho Y, Wookey S. The real-world-weight cross-entropy loss function: modeling the costs of mislabeling. IEEE Access. (2020) 8:4806–13. doi: 10.1109/ACCESS.2019.2962617
CrossRef Full Text | Google Scholar
21. Alba AC, Agoritsas T, Walsh M, Hanna S, Iorio A, Devereaux PJ, et al. Discrimination and calibration of clinical prediction models: users’ guides to the medical literature. JAMA. (2017) 318:1377–84. doi: 10.1001/jama.2017.12126
PubMed Abstract | CrossRef Full Text | Google Scholar
22. Ojala M, Garriga GC. Permutation tests for studying classifier performance. J Machine Learn Res. (2010) 11:1833–63.
23. Huang YL, Hu ZD. Lower mean corpuscular hemoglobin concentration is associated with poorer outcomes in intensive care unit admitted patients with acute myocardial infarction. Ann Transl Med. (2016) 4:190. doi: 10.21037/atm.2016.03.42
PubMed Abstract | CrossRef Full Text | Google Scholar
24. Madjid M, Awan I, Willerson JT, Casscells SW. Leukocyte count and coronary heart disease: implications for risk assessment. J Am Coll Cardiol. (2004) 44:1945–56. doi: 10.1016/j.jacc.2004.07.056
PubMed Abstract | CrossRef Full Text | Google Scholar
25. Yan X, Anzai A, Katsumata Y, Matsuhashi T, Ito K, Endo J, et al. Temporal dynamics of cardiac immune cell accumulation following acute myocardial infarction. J Mol Cell Cardiol. (2013) 62:24–35. doi: 10.1016/j.yjmcc.2013.04.023
PubMed Abstract | CrossRef Full Text | Google Scholar
26. Barron HV, Cannon CP, Murphy SA, Braunwald E, Gibson CM. Association between white blood cell count, epicardial blood flow, myocardial perfusion, and clinical outcomes in the setting of acute myocardial infarction: a thrombolysis in myocardial infarction 10 substudy. Circulation. (2000) 102:2329–34. doi: 10.1161/01.cir.102.19.2329
留言 (0)