
記住我
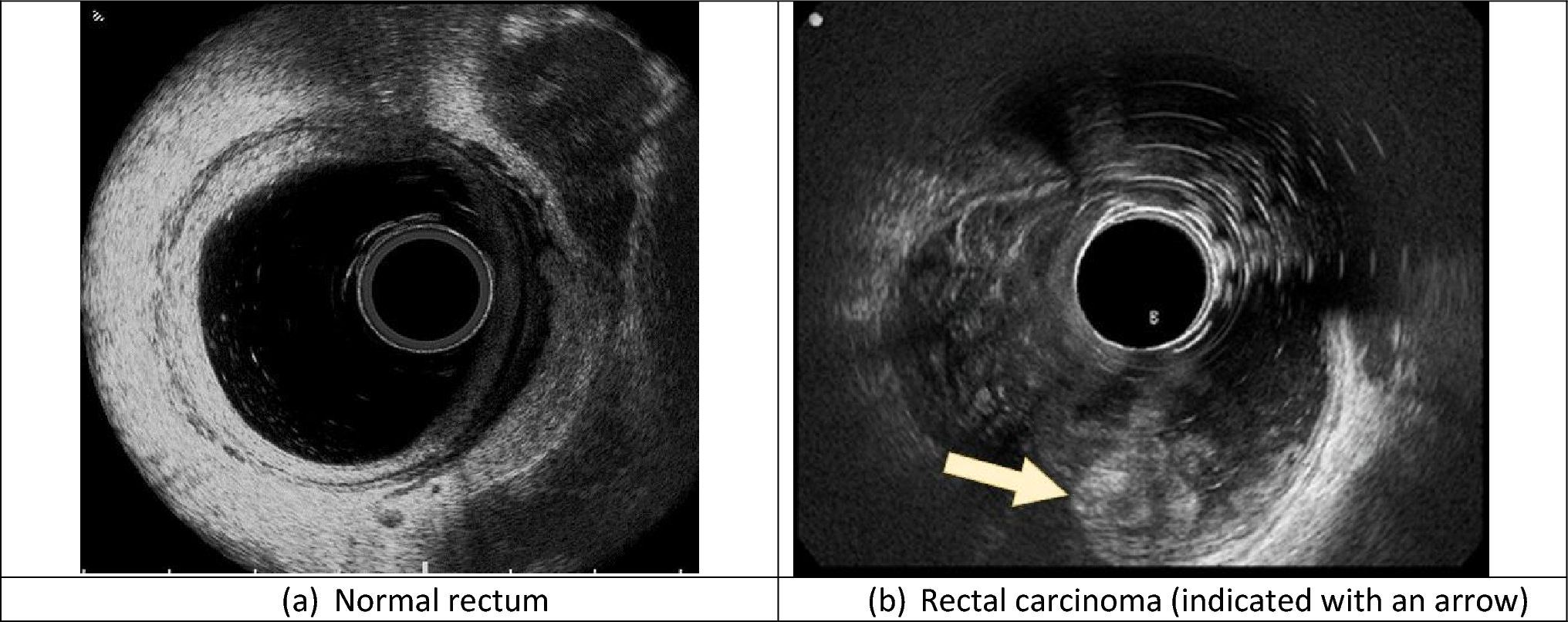
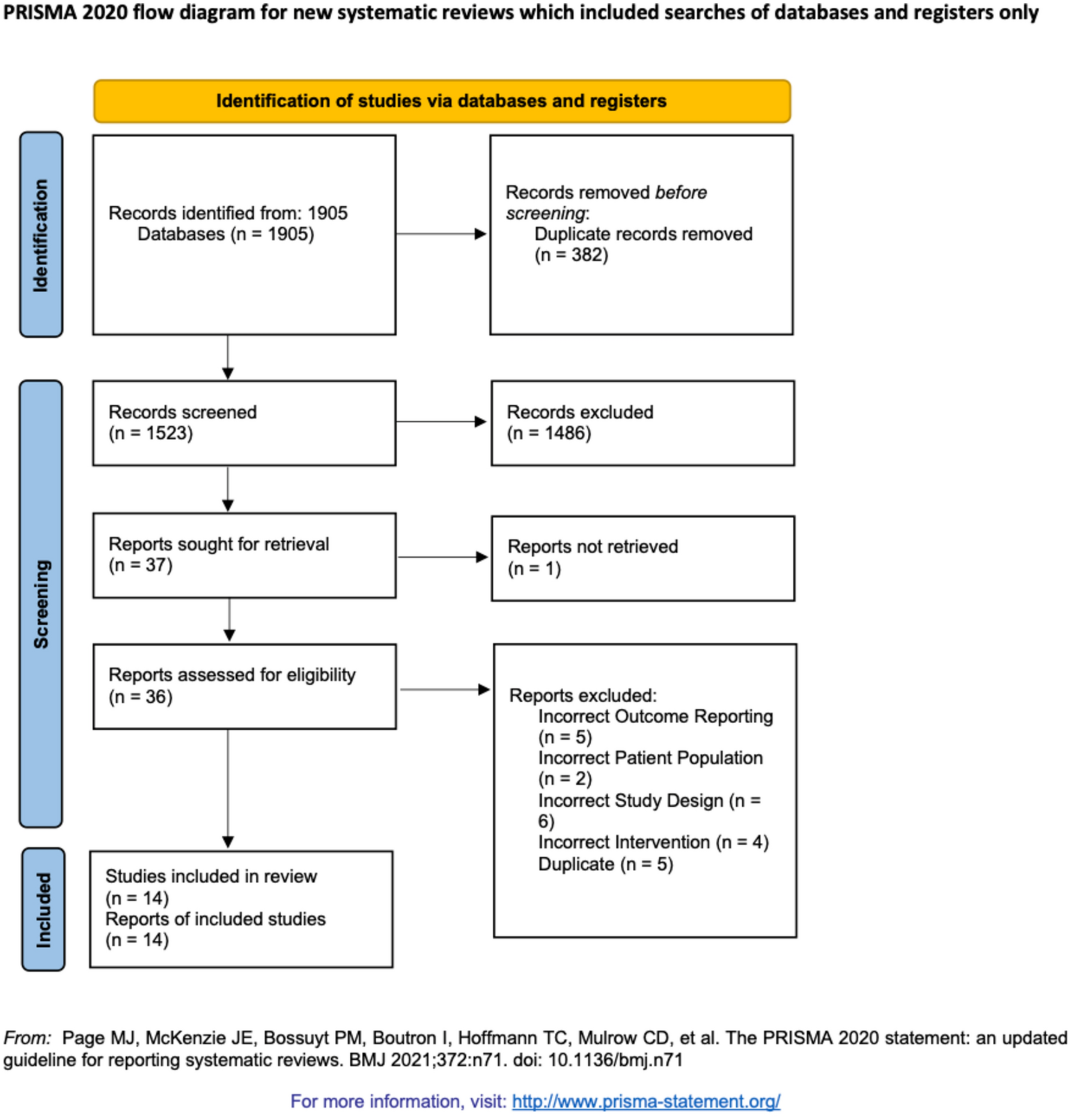
The initial database search yielded 116 articles with 75 unique articles remaining after the removal of duplicates. A further eight articles were retrieved through citation searching. After initial and full-text screening against eligibility criteria, nine studies were included in this review. Reasons for exclusion were the sole use of APMs, CPMs, subjective measures of performance, and utilising non-soft tissue robotics (see Fig. 1).
Fig. 1
PRISMA diagram of the systematic search strategy
Individual study characteristics are summarised in Table 1. Included studies covered the specialities of urology (n = 5), coloproctology (n = 2), gastroenterology (n = 1) and the basic skills of robotic suturing and knot-tying (n = 1). Publication dates spanned the years 2017 to 2022. Together, their description of metrics included CRPMs, CROMs, PBP metrics, and reference-procedure metrics. Countries of publication included Germany [11, 12], England [13,14,15,16,17], and the USA [6, 18].
Table 1 Study characteristicsDefinition of clinically relevant performance metricsThroughout the articles, there was a lack of a clear consensus or homogenous definition for clinically relevant performance metrics in robotic surgery. As a result, this explicit terminology was utilised in only three of the included papers. Witthaus et al., introduced CRPMs as “concepts to design a conceptual framework for incorporating measures pertinent to a surgical task within a high-fidelity procedural simulation construct” [17]. Ghazi et al., defined CROMs as measures that “extend beyond basic robotic skills training into procedure-specific training” and provide tailored feedback to allow surgeons to progress based on individualised capabilities [15]. Ma et al., stated that CRPMs were those utilized to provide procedure-tailored feedback for surgical training and therefore “expedite the acquisition of robotic suturing skills” for each individual surgeon [18]. Other terminology utilised in the included publications were “procedure specific assessment tools” that provided an objective assessment of robotic intraoperative performance and enabled tailored training feedback to achieve competency [6, 12]. A further 4 articles used the term proficiency-based progression (PBP) metrics [11, 13, 14, 16].
Development of clinically relevant performance metricsIndividual details and the specific metrics assessed by each study are represented in Table 1. Witthaus et al., and Ghazi et al., took a similar approach in defining their metrics. They used hydrogel models in conjunction with the Da Vinci Surgical System to develop anatomically and mechanically validated simulation models [15, 17]. This enabled the incorporation of tailored clinically relevant performance metrics in training for nerve-sparing robot-assisted radical prostatectomy (NS-RARP) and Robot-assisted partial nephrectomy (RAPN). The metrics included: applied force to the neurovascular bundle during dissection, post-simulation margin status, UVA integrity, task-specific operating tasks, estimated blood loss [17] as well as console time, warm ischemia time (WIT), and positive surgical margins (PSMs) [15], respectively.
Methodology for developing clinically relevant metrics for UVA utilised pre-existing validated metrics including APMs and RACE score [18]. The remaining 6 articles used a modified Delphi process, to identify and describe specific metrics for a reference procedure. These reference procedures included RARP [6, 14], robot-assisted low anterior resection (RA-LAR) [13, 16], robotic suturing and knot tying anastomosis [12], and intestinal anastomosis [11]. To create the reference metrics, a modified Delphi methodology using a panel of experts, outlined a combination of domains, procedure phases, steps, errors and critical errors. The metrics were edited, and a level of consensus was established before the final metrics were voted upon and finalised [14]. This is the only example in the literature of a structured approach to the development of clinically relevant performance metrics.
Validation of clinically relevant performance metricsContent validationContent validity is defined as “the degree to which elements of an assessment instrument are relevant to a representative of the targeted construct for a particular assessment purpose” [19]. For clinically relevant metrics, this refers to how accurately they reflect performance in the clinical context they were intended to measure. CRPMs for NS-RARP were content validated by performing nerve sensor calibration, surgical margin verification and using the standard 180 ml UVA leak test [17]. An iterative development process was used to assess feedback and the feasibility of the CROMs in relation to the RAPN [15]. APMs related to UVA steps were collated from data from the Da Vinci robotic system, and combined with technical skill scores from RACE, which was previously validated [18]. Considering the articles that utilised a Delphi panel to create their reference metrics, content validation was achieved by voting upon each metric, and ensuring high-level consensus was achieved before the metrics were accepted and included as part of the finalised reference metrics [6, 11,12,13,14, 16]. Content validation measures for each study is represented in Table 2.
Table 2 Validity of metricsConstruct validation (response process evidence)Construct validation refers to the ability of CRPMs to differentiate between surgical skill, such as novices, intermediates and experts. All studies demonstrated that their metrics were able to distinguish between skill levels, though not all reached statistical significance (see Table 2).
Witthaus et al. showed that experts outperformed novices on all NS-RARP CRPMs including reduced nerve forces applied and total energy, superior margin results (p = 0.011), UVA integrity and all task-specific operating times except seminal vesicle dissection. Although not statistically significant, experts had a reduced EBL [17]. Similarly, Ghazi and colleagues demonstrated construct validity of their RAPN CROMs whereby experts significantly outperformed novices in all metrics, except for positive surgical margins [15]. Ma et al. found the feedback group, which received tailored feedback based on the CRPMs from UVA training tasks, outperformed the control group across all metrics except the needle entry score [18]. In addition to this, the effect size was measured to detect which metrics were more sensitive in detecting differences between the control and feedback group. For the UVA task, needle positioning, tissue approximation, and master clutch usage were found to have a higher effect size [18]. PACE was also found to have construct validity for RARP with the expert group outperforming the novices across all seven domains [6]. Puliatti et al. demonstrated construct validity for the reference approach to suturing and knot tying in anastomotic models, where novices had an increased mean task completion time, mean number of errors, and anastomotic leakage in comparison to experts [12]. Novices were also 12.5 times more likely to fail to progress throughout the task [12].
All the above studies used a caseload of procedures to differentiate between novice, intermediate and expert surgeons. Mottrie et al. and Gómez et al., however, found that within their expert surgeon groups, there existed two distinct populations: experienced surgeons with few errors and experienced surgeons with high errors [13, 14]. Those with the most errors demonstrated considerable performance variability, some performing worse than the weakest performing novice [13, 14]. To account for this variability, both studies considered two distinct populations. They found that experienced surgeons with the fewest errors performed significantly better across the metrics than those with high errors and novices, confirming construct validity [13, 14]. The neurovascular bundle dissection phase of the RARP and the rectal dissection in RA-LAR discriminated best between the total experienced surgeons and novices [13, 14]. Lastly, Schmidt et al. found that both the weighted and unweighted forms of the A-OSATS metric were unable to distinguish between surgical skill level according to caseload alone but achieved construct validity when participants were assigned to each skill level according to the OSATS global rating score (GRS) [11].
Criterion validityCriterion validity refers to the relationship of CRPMs with other variables such as the validated semi-objective scoring systems, GEARS and RACE. Three studies examined the criterion validity of their metrics (Table 2). Witthaus et al. found that reduced force to neurovascular bundle during dissection correlated to higher force sensitivity (p = 0.019)) and total GEARS score (p = 0.000) [17]. UVA leak rate was also found to correlate with the total RACE score (p = 0.000) [17]. Ghazi and colleagues also found similar correlations between their CROMs and total GEARS score including console time, WIT, EBL and PSMs [15]. Gómez et al. found that GEARS had poor inter-rater reliability (IRR) for video scoring and weaker discrimination between surgical skill groups [13]. They concluded that PBP binary metrics demonstrated superior IRR than GEARS and robust discrimination amongst skill level, especially for total errors [13].
Clinical contextSchmidt et al. constructed weighted A-OSATS scores which highlighted steps pertinent for patient outcomes but did not explore its predictive capabilities in comparison to the unweighted score [11]. Collectively, no study investigated the correlation between clinically relevant performance metrics and patient outcomes, though was highlighted as a point for future research.
留言 (0)