
記住我


For scRNA-seq, RNA degradation and incompleteness of reverse transcription (RT) are two major factors that reduce gene detection sensitivity and coverage evenness. Although adding random RT primers facilitates the coverage of long transcripts, it requires the removal of ribosomal RNA, which is incompatible with scRNA-seq [13]. Spiking template-switching oligonucleotides also provides more uniform coverage, but this strategy has limited detection sensitivity and specificity [12].
We altered various experimental parameters of the original SHERRY protocol for both bulk (Additional file 1: Fig. S1-S2, Additional files 2 and 3) and single-cell inputs (Additional file 1: Fig. S3A). To protect RNA from degradation, we lowered the concentration of free Mg2+, either by reducing the amount of total Mg2+ or adding more dNTP to chelate Mg2+ ions [14], and observed significant improvement in the coverage evenness of RNA-seq. To facilitate cDNA synthesis, we screened different reverse transcriptases and found that SuperScript IV (SSIV), working at a relatively high temperature with a low Mg2+ concentration, could better overcome the secondary structure of RNA and hence simultaneously enhanced the sensitivity and uniformity of RNA-seq.
When RNA-seq was conducted using pictogram-level RNA inputs, sufficient amount of Tn5 transposome was important for high sensitivity, and Bst 3.0 DNA polymerase filled the gap left by Tn5 tagmentation more effectively than other enzymes. The protocol was insensitive to many experimental conditions, including the usage of single-strand DNA-binding proteins [15], the Tn5 inactivation, the concentration of extension polymerase, and the usage of hot-start polymerase.
We named this optimized protocol SHERRY2. Using RNA extracted from HEK293T cells as input, we compared the performance of SHERRY2 and the original SHERRY protocol. At the 10-ng level, both protocols identified more than 11,000 genes at saturation. At the 100-pg level, SHERRY2 performed better than SHERRY and detected 5.0% more genes at 0.6 million reads (Additional file 1: Fig. S2A). In addition, SHERRY2 greatly diminished 3′-end coverage bias (Additional file 1: Fig. S2B) and increased the unique mapping rate for 10-ng and 100-pg inputs (Additional file 1: Fig. S2C). We also constructed a bias-free RNA-seq library using 200-ng total RNA input via the conventional fragmentation-and-ligation method with the NEBNext E7770 kit (NEBNext). For 100-pg input, the gene overlap between NEBNext and SHERRY2 was greater than that between NEBNext and SHERRY (81.7% vs 78.4%) (Additional file 1: Fig. S2D), and the gene expression results of NEBNext and SHERRY2 were also more closely correlated (R = 0.70 vs R = 0.65) (Additional file 1: Fig. S2E).
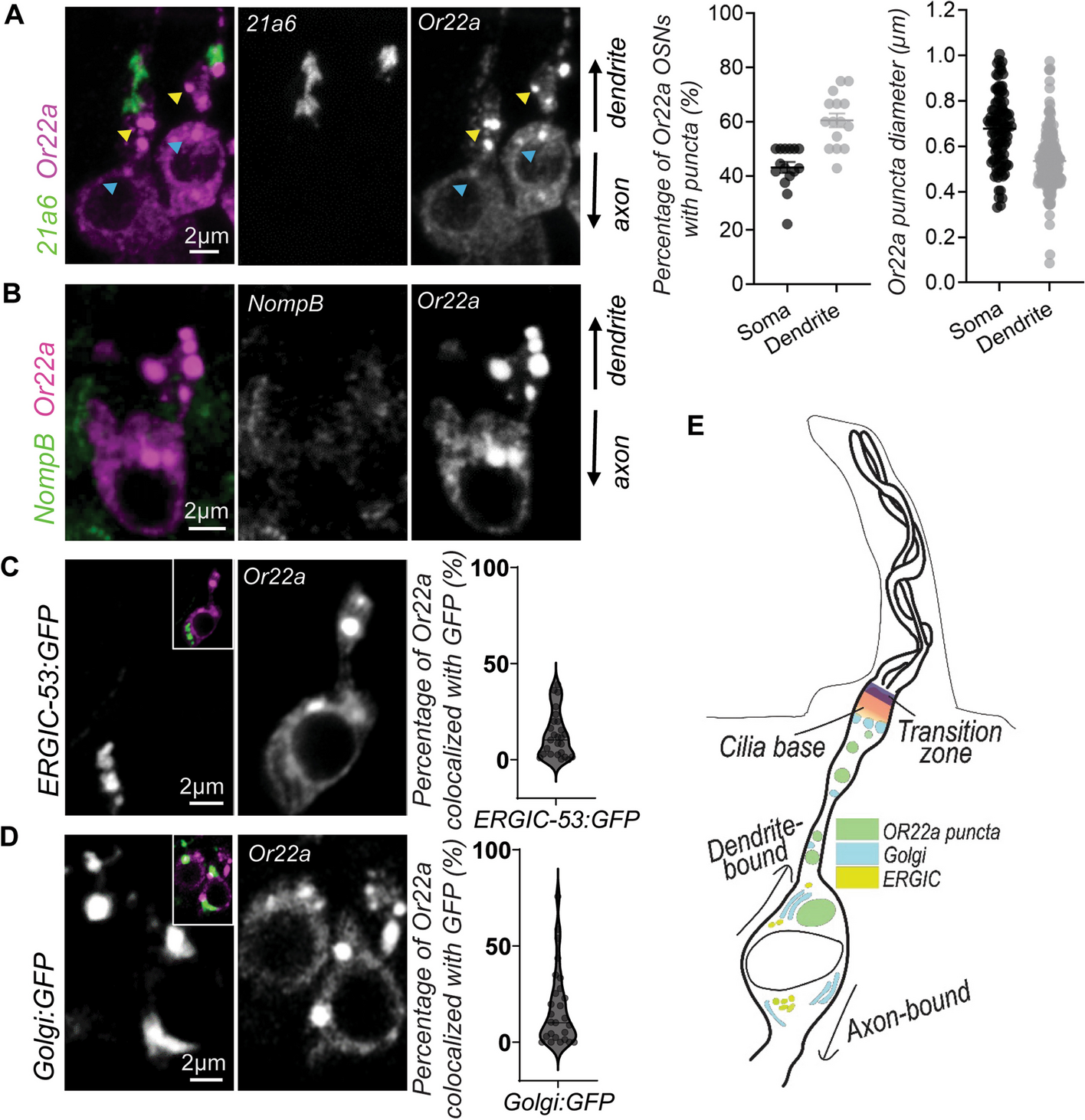
The SHERRY2 protocol for scRNA-seq contains only four steps: reverse transcription, Tn5 tagmentation, gap-filling through extension, and PCR amplification. The entire SHERRY2 protocol can be completed within 3 h, 1 h less than the original SHERRY protocol, and still held its competence in costs (Additional file 1: Fig. S3B). Other high-sensitivity scRNA-seq methods such as SmartSeq2 may require much more time and more steps to be completed [3] (Fig. 1A). The one-tube workflow of SHERRY2 is readily scalable to high-throughput applications. SHERRY2 was able to detect 10,024 genes (FPKM > 1) on average within a single HEK293T cell at 1 million reads. When subsampling to 0.2 million reads, SHERRY2 still detected 8504 genes on average, which was 1622 (23.6%) more than SHERRY and 886 (11.6%) more than SmartSeq2 (Fig. 1B). In addition, the reproducibility of SHERRY2 was significantly higher than that of SHERRY or SmartSeq2 (Fig. 1C) due to its simplified workflow and stable performance. Moreover, the evenness of gene body coverage for SHERRY2 was much higher than that of the original SHERRY protocol (0.84 vs 0.72) and was comparable to that of SmartSeq2 (0.84) (Fig. 1D). The exonic rate of SHERRY2 was also improved in comparison with that of SHERRY, likely due to the higher RT efficiency of the newly developed method (Fig. 1E).
Fig. 1
The workflow and general performance of SHERRY2 on single-cell RNA-seq. A The workflow of SHERRY2 for scRNA-seq. Poly(A) tailed RNA is firstly released from single cells and reverse transcribed. The resulting RNA/cDNA hetero-duplex is then tagmented by Tn5 transposome, followed by gap repair and indexed PCR. Optionally, chromatin can be digested during lysis. The entire protocol is performed in one tube and takes 3 h. B Gene number (FPKM > 1) with SmartSeq2, SHERRY2, and SHERRY when subsampling reads to 0.1, 0.2, 0.4, 0.6, 0.8, and 1 million reads. C Pairwise correlation of gene expression within replicates for the three scRNA-seq protocols. The correlation R-value was calculated by a linear fitting model with normalized counts of overlapped genes. D Gene body coverage detected by the three scRNA-seq protocols. The gray region represents the standard deviation of the normalized depth among replicates. E Components of reads that were mapped to different regions of the genome using the three scRNA-seq protocols. The error bars show the standard deviation. F Gene expression correlation between single HEK293T cells and 200-ng RNA extracted from HEK293T cells. Single-cell data were acquired by the three scRNA-seq protocols. Bulk RNA results were acquired by the standard NEBNext protocol. The correlation R-value was calculated by a linear fitting model with normalized gene counts. The samples in B–F are single HEK293T cells. The p-values in B, C, and F were calculated by the Mann-Whitney U test
Last but not least, scRNA-seq with SHERRY2 exhibited superior accuracy, as demonstrated by the significantly higher correlation between the SHERRY2 gene expression results and NEBNext libraries in comparison with that of SmartSeq2 (R = 0.71 vs R = 0.67) (Fig. 1F), since NEBNext fragmented mRNA before cDNA synthesis and amplified cDNA with very limited cycles which theoretically resulted in negligible bias at the transcriptome level. Especially, SHERRY2 showed high tolerance to GC content and was insensitive to the length of transcripts (Additional file 1: Fig. S4). Unlike SmartSeq2, for which the gene overlap and expression correlation with bulk RNA-seq showed clear declines when GC content was greater than 40%, SHERRY2 maintained these parameters at high and constant levels (82.6% overlap and R = 0.76) until the GC content reached 60%. Transcript length did not influence the accuracy of SHERRY2 or SmartSeq2, although SmartSeq2 exhibited a small degree of intolerance for transcripts longer than 800 bases.
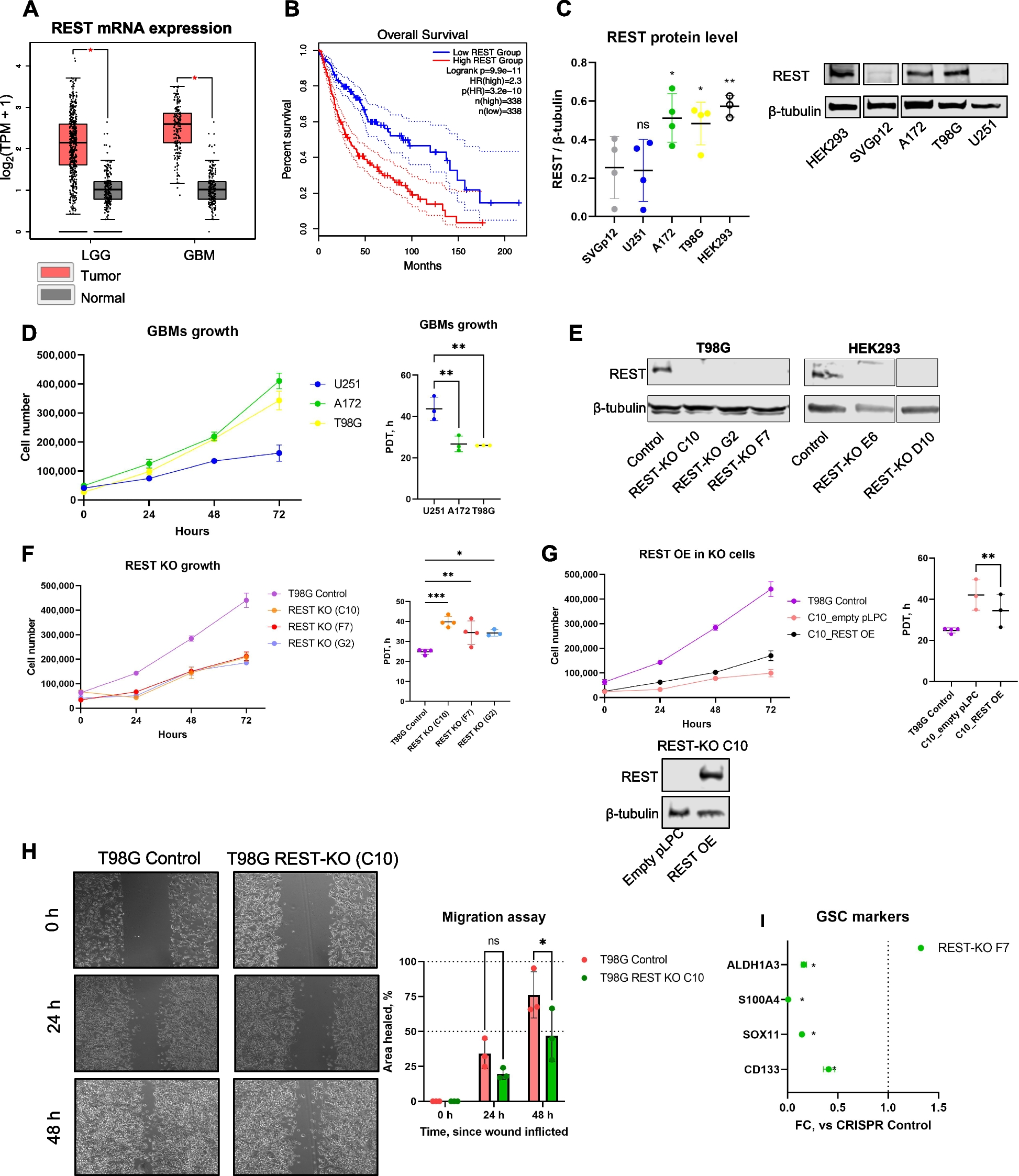
scRNA-seq for low RNA content cellsFor low RNA content cells, such as immune cells [16], we found that removal of intergenic DNA contaminations by DNase treatment was especially crucial for SHERRY2 scRNA-seq. In such cells, the open DNA regions of disassembled chromatin might be favored over RNA/DNA hybrids during Tn5 tagmentation. When DNase was omitted from the SHERRY2 protocol, more than 50% of reads sequenced from single mouse lymphocytes (Additional file 1: Fig. S5A) were mapped to intergenic regions, and only around 10% of reads were exonic reads (Fig. 2A).
Fig. 2
scRNA-seq of low RNA-content samples with SHERRY2. A Proportions of genome regions covered by reads from SHERRY2 without DNase treatment, SHERRY2 with AG DNase I addition, SHERRY2 with AG DNase I and DNA carrier addition, and SmartSeq2. B Gene number (FPKM > 1) detected by SHERRY2 with AG DNase I addition, SHERRY2 with AG DNase I and DNA carrier addition, and SmartSeq2 when subsampling to 20, 50, 100, 200, 400, and 600 thousand reads. Only samples with an intergenic rate lower than 25% were counted. Samples in A and B were single lymphocyte cells from murine eyeball blood. C Library quality of SHERRY2 tested with different DNases, including gene number (FPKM > 1) at 0.25 million reads, coverage uniformity across gene body, and percentage of reads that were mapped to intergenic regions. The labels below the figure indicate the amounts and names of the DNases, as well as the EDTA concentration that was added during DNase inactivation. SmartSeq2 was also performed as a reference. D Components of reads covering different genome regions detected by SHERRY2 without DNase treatment, SHERRY2 with optimized AG DNase I, and SmartSeq2. E Gene body coverage detected by SHERRY2 (with AG DNase I) and SmartSeq2. The gray region shows the standard deviation of the normalized depth among replicates. F Gene number (FPKM > 1) detected by SHERRY2 (with AG DNase I and DNA carrier) and SmartSeq2 when subsampling to 20, 50, 100, 200, 400, and 600 thousand reads. G Gene Ontology analysis of genes that were only detected by SHERRY2 (left) or SmartSeq2 (right). The top 20 most commonly occurred GO terms were shown. Samples in C–G were single B cells isolated from murine GC light zones. The p-values in B and F were calculated by the Mann-Whitney U test. The error bars in A and D show the standard deviation
Different DNases performed differently in SHERRY2 scRNA-seq. We tested five DNases (Additional file 1: Fig. S6A) and found three (NEB, Ambion, and TURBO DNase I) that worked and inactivated at higher temperatures increasing the intergenic rate unexpectedly, and this effect was probably due to RNA degradation at high temperatures with excess Mg2+ in the reaction buffer. In contrast, AG DNase I and gDW mix, which worked at room temperature, yielded ideal results.
We confirmed that all the five DNases could digest more than 99.5% of DNA (30 ng) by simply utilizing divalent ions of their respective storage buffer (Additional file 1: Fig. S6B, Additional file 4). Without adding extra divalent ions, the intergenic rates of single germinal center (GC) B cells for all DNases were less than 20% (Fig. 2C). Among the DNases, AG DNase I retained high sensitivity for gene detection, and more than 60% of reads were mapped to exon regions (Fig. 2D), while the evenness of coverage was not affected (Fig. 2E).
Next, dU-containing carrier DNA, which could not be amplified by dUTP-intolerant polymerase, was added to further improve the efficiency of tagmentation of RNA/DNA hybrids. With carrier DNA, SHERRY2 detected 3200 genes at saturation (0.6 million reads) for single GC B cells (Fig. 2F), and the number of detectable genes increased from 2301 to 2393 on average for single lymphocytes, with an exonic ratio comparable to that of SmartSeq2 (Fig. 2A, B). Moreover, we examined the genes that were only detected by one method for single GC B cells and found that SmartSeq2 was preferential to capture genes that participated in mitochondrial function (Fig. 2G). Based on these results, chromatin digestion and the addition of carrier DNA were included in the standard SHERRY2 protocol, and the step of chromatin digestion would consume another 20 min.
Selection dynamics in germinal centers profiled by SHERRY2SHERRY2 can be easily scaled to thousands of single cells per batch, owing to its simplified procedure. The GC is a transient structure that supports antibody affinity maturation in response to T cell-dependent antigens, and it contains diverse cell types with complex dynamics. Histologically, the GC can be separated into two micro-compartments, the dark zone and the light zone [17, 18]. By surface phenotyping, cells in the two compartments can be distinguished through CXCR4, CD83, and CD86 markers [19,20,21], with light zone cells being CXCR4loCD83+CD86+ while dark zone cells CXCR4+CD83loCD86lo. GC cell cycle between the dark zone and light zone states. Dark zone cells are highly proliferative and undergo somatic hypermutation, which generates a range of affinities against antigens. In the light zone, these B cells compete with each other for survival factors and help signals, which are mainly derived from follicular helper T cells. Those B cells that have acquired higher-affinity B cell receptors are selected to differentiate into plasma cells (PC) or memory B cells (MBC) or cycle back to the dark zone [18, 22,23,24]. Recently, a gray zone, consisting of CXCR4+CD83+ cells with distinct gene expression patterns, was discovered and found to be involved in GC recycling [25]. The complex spatiotemporal dynamics of the GC and their underlying mechanisms are incompletely understood. To this end, sensitive scRNA-seq methods that can be used to detect gene expression with less bias are highly desirable.
We profiled 1248 sorted CXCR4loCD86hi GC light zone cells with SHERRY2, and 1231 (98.6%) high-quality cells were retained for downstream analysis (Additional file 1: Fig. S5B). The gene expression levels of Cd19, Ccnd3, Fas, Cd86, and Cxcr4 were consistent with flow cytometry gating (Additional file 1: Fig. S7A), and no batch effect was observed (Additional file 1: Fig. S7B).
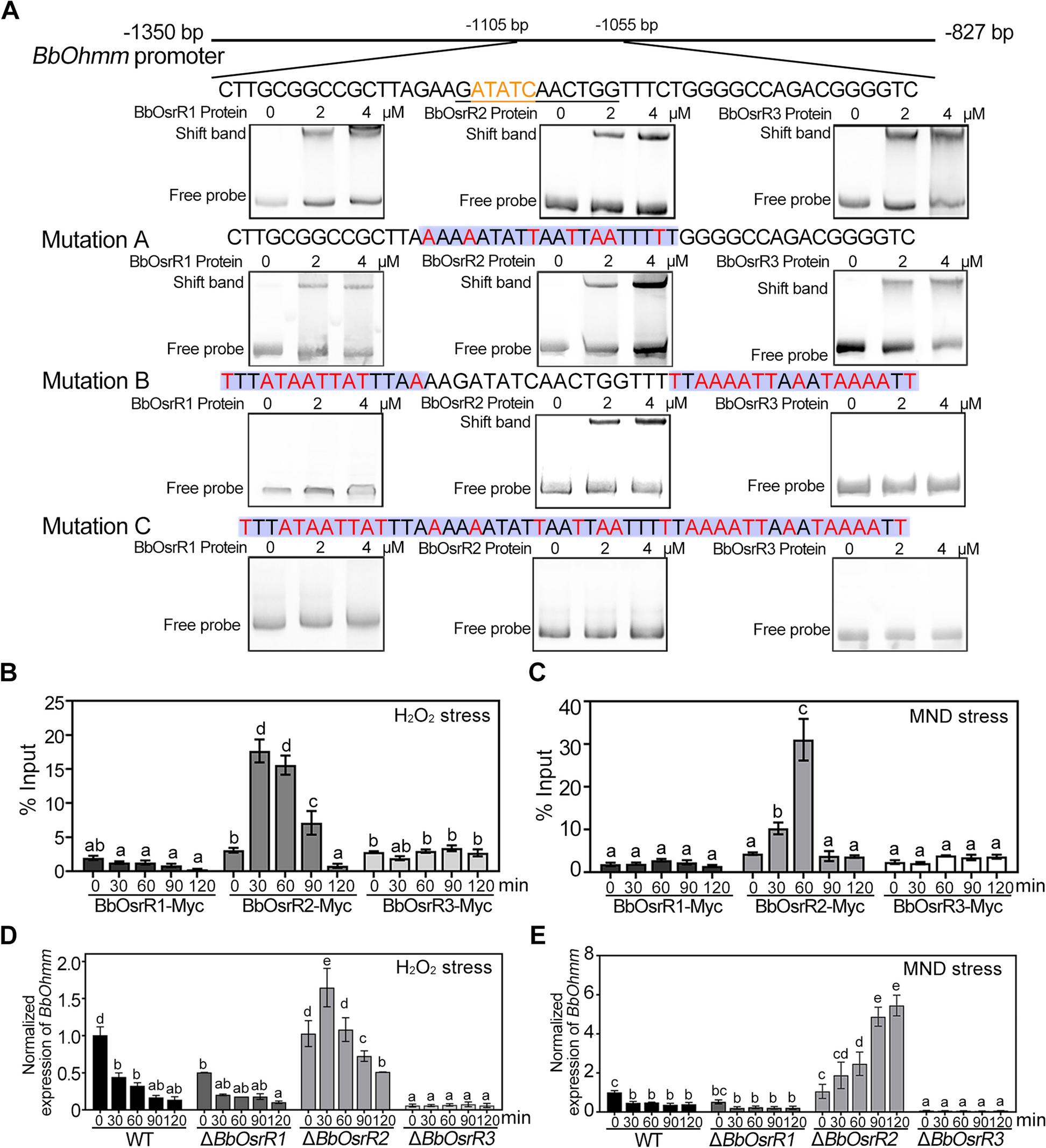
Unsupervised clustering identified seven clusters (Fig. 3A), two of which belonged to the gray zone, which was defined by co-expression of Cxcr4 and Cd83, as well as the ongoing cell division (enriched Ccnb1) [25] (Fig. 3B). We observed the expected downregulation of Bcl6 and S1pr2, the signature genes of GC B cells [26, 27], in memory B cell precursors (MPs) and plasma cell precursors (PPs). Specifically, Ccr6 was exclusively enriched in MPs [28], while Irf4 was upregulated in PPs, which was known to be mediated by the NF-κB pathway downstream of Cd40 stimulation [24]. It is worth noting that our results exhibited such Cd40 signaling effects as well (Additional file 1: Fig. S7C). Besides, Icam1 and Slam1 which were reported to be activated by Cd40 [29] were also observed (Additional file 1: Fig. S7D, Additional file 5). The relatively low expression levels of Prdm1 (not shown) and Gpr183 in PPs were consistent with the early stage of plasma cell development. In total, 1071 genes significantly up- or downregulated in specific clusters were identified.
Fig. 3
Mouse germinal center profiled by scRNA-seq through SHERRY2. A Clustering of single B cells from murine GC light zones visualized by UMAP plot. The library was prepared by SHERRY2 (with AG DNase I and DNA carrier). Different colors indicate distinct cell types. B Cell cycle and marker gene expression of different cell types marked on a UMAP plot. The gradient colors correspond to the normalized counts of a specific gene ranging from 0 (white) to 1 (blue). C Distribution of Myc gene expression in different cell types. Different colors indicate different intervals of normalized Myc counts. The percentages of cells within the clusters falling into corresponding intervals were counted. D Dynamic process of the GC light zone indicated by vector fields of RNA velocity on a UMAP plot. The expanded region shows the velocity vector of each cell. The colors correspond to the same cell types as annotated in A. E Isoforms of the Hnrnpab gene. The top two lines show isoforms from two example cells that rarely and preferentially used the highlighted exon in Hnrnpab transcripts. The bottom two lines show the isoform structures of Hnrnpab transcripts that include or exclude the exon. F Inclusion ratio distribution of the highlighted exon in E in different cell types. Only cell types represented by more than 10 cells after filtering are shown
The high sensitivity of SHERRY2 enabled the detection of Myc in 588 (47.8%) single GC light zone B cells. Using fluorescent protein reporting, Myc was found to mark light zone cells destined for dark zone re-entry [30], although Myc expression per se had been difficult to identify in specific cell types by low-sensitivity scRNA-seq approaches [31]. Consistent with previous findings [25, 29], the Myc expression was significantly higher in PPs (Fig. 3B, Additional file 1: Fig. S7E) and active in the gray zone cells (Fig. 3C). Light zone-1 also had a relatively higher portion of Myc+ cells, which are probably those destined for cyclic re-entry to the dark zone [30]. MPs also contained some cells that expressed Myc.
RNA velocity analysis (Fig. 3D) suggested that light zone-1 contained cells selected for dark zone re-entry, which were migrating to the gray zone and had Myc expression characterized by burst kinetics (Additional file 1: Fig. S7F). In addition, cells that appeared to have just entered the light zone were also identified. A few velocity vectors that moved to MPs were mixed in PPs, and these vectors were in the same direction as the downregulation of Myc. According to the velocity analysis, the aforementioned Myc-expressing MPs seemed to have a tendency to cycle back to the GC, suggesting that some MPs with Myc upregulation have the potential to re-participate in GC reactions.
We then assembled the BCR sequence for each cell to screen the usage of the Igh variable sequences, which were assigned in 1101 (89.4%) cells. As expected [32], IGHV1-72 dominated the NP-reactive GC response, and the coupled light chain was mainly IgL rather than IgK (Additional file 1: Fig. S8A, S8B). In addition, we identified CDR1 and CDR2 regions in 269 (24.4%) and 493 (44.8%) cells in which the Igh variable sequences were assigned, respectively (Additional file 1: Fig. S8C).
SHERRY2 revealed the differences in the usage frequencies of exons across cell types. The usage of a particular exon (chr11: 51,601,750–51,601,890) within the Hnrnpab transcript (Fig. 3E), which is widely expressed and encodes a protein that mainly functions in processing pre-mRNAs, was significantly biased among GC clusters. As shown in Fig. 3F, light zone-1 cells favored the inclusion of this exon.
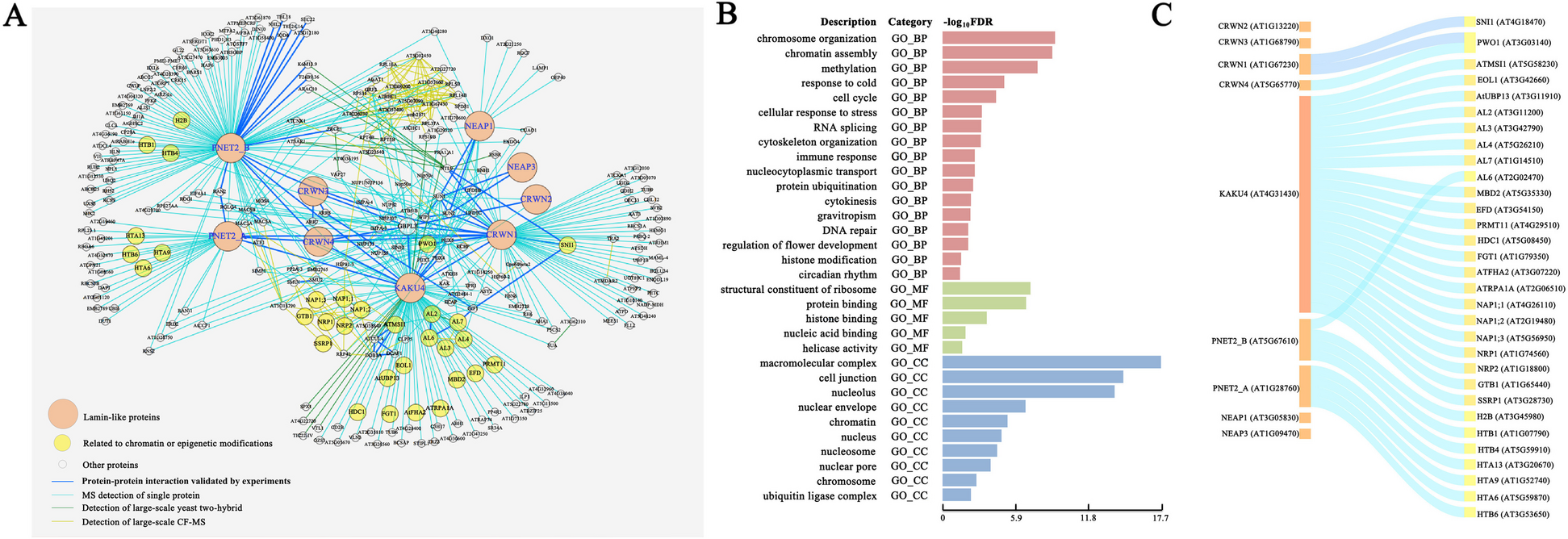
Superior performance of SHERRY2 applied in snRNA-seqSingle-nucleus RNA-seq (snRNA-seq) has gained popularity since fresh and intact single cells are challenging to obtain in many applications. Hence, we tested the performance of SHERRY2 on snRNA-seq using single nuclei isolated from HEK293T cells. SHERRY2 detected 10,137 genes (RPM > 1) on average at 1 million reads, which was 4330 (74.6%) more than SmartSeq2, demonstrating that SHERRY2 had superior sensitivity for single nuclei (Fig. 4A). SHERRY2 still exhibited superior accuracy as it was significantly more correlated with NEBNext quantification results in comparison with SmartSeq2 (R = 0.41 vs R = 0.39) (Fig. 4B).
Fig. 4
Sensitivity and accuracy of SHERRY2. A Gene number (RPM > 1) of single HEK293T nuclei detected by SHERRY2 and SmartSeq2 when subsampling reads to 0.1, 0.2, 0.4, 0.6, 0.8, and 1 million reads. B Gene expression correlation between single HEK293T nuclei and 200-ng RNA extracted from the HEK293T nuclei. Single-nucleus data were acquired by SHERRY2 and SmartSeq2. Bulk RNA results were acquired by the standard NEBNext protocol. The correlation R-value was calculated by a linear fitting model with normalized gene counts. C Clustering of HEK293T cellular and nuclear RNA-seq data from SHERRY2, SmartSeq2, and NEBNext using principal component analysis. The analysis utilized differentially expressed genes (adjusted p-value < 1e−4 and fold change > 2) between cells and nuclei detected by NEBNext. D Gene number (RPM > 1) of single neuron nuclei detected by SHERRY2 and SmartSeq2 when subsampling reads to 0.1, 0.2, 0.4, 0.6, 0.8, and 1 million reads. The nuclei were isolated from the mouse hippocampi that were freshly prepared or previously frozen at − 80 °C. E Clustering of the single hippocampal neuron nuclei visualized by UMAP plot. The snRNA-seq library was prepared by SHERRY2. The analysis utilized genes expressed (counts > 0) in more than 4 nuclei. F Marker gene expression of different cell types on UMAP plot from E. The gradient colors correspond to the normalized counts of a specific gene ranging from 0 to 1. The p-values in A, B, and D were calculated by the Mann-Whitney U test
The high accuracy and sensitivity of SHERRY2 allowed better distinction between HEK293T cells and their nuclei, which had minimal differences. We performed principal component analysis (PCA) using RNA-seq data from NEBNext, SHERRY2, and SmartSeq2 (Fig. 4C). Single cells and nuclei prepared by SHERRY2 were much closer in distance to the bulk RNA results in comparison with those prepared with SmartSeq2. In addition, the expression pattern of the differential genes identified by SHERRY2 was more similar to that of NEBNext in comparison with SmartSeq2 (Additional file 1: Fig. S9).
Furthermore, we compared the performance of these two methods with hippocampal neurons since snRNA-seq is a popular method for studies of brain tissue due to the technical challenge of isolating intact single neurons. We constructed snRNA-seq libraries of the frozen and freshly prepared hippocampus with SHERRY2 and SmartSeq2. For both samples, SHERRY2 detected significantly more genes than SmartSeq2 (6600 vs 5331 at 1 million reads for frozen samples, 6686 vs 5769 at 1 million reads for fresh samples) (Fig. 4D), and still, Smart-seq2 tended to detect genes functionized in the mitochondrion (Additional file 1: Fig. S10A). Next, we sequenced a small number of fresh hippocampal neurons (176 nuclei) (Additional file 1: Fig. S10B) with SHERRY2 and classified their cell types correctly. The nuclei were non-supervisedly clustered into 4 distinct groups (Fig. 4E), after which they were re-clustered using marker genes identified by sNuc-Seq [33] (Additional file 1: Fig. S10C). The two clustering results were highly consistent. Neurons within the dentate gyrus (DG) and CA1, which occupy large areas of the hippocampus, could be assigned to cluster 0 and cluster 1, respectively, according to the high expression of Dock10, Slc4a4, and high expression of Pex5l and Hs6st3 (Fig. 4F). However, CA3 pyramidal cells were not shown in our results, probably due to the small number of samples. Cluster 3 that was featured with enriched Arx and Lhx6 could be annotated as GABAergic cells, which migrated from medial ganglionic eminence (MGE). Except for the aforementioned markers, the expression patterns of these three clusters acquired from sNuc-seq and SHERRY2 were very similar (Additional file 1: Fig. S10D). Cluster 2 was found to consist of cells with relatively high expression of Dpp10 and Tshz2, inferring that it might be contamination of cortex neurons. Moreover, our results revealed a long non-coding RNA (lncRNA) cluster [34] containing Meg3, Rian (Meg8), and Mirg (Meg9), which showed higher density in CA1 pyramidal cells and GABAergic cells while relatively sparse in DG granule cells (Additional file 1: Fig. S10E).
留言 (0)