

記住我


In the cognitive and neural sciences, Bayes-optimal decision-making models have advanced over the last few decades to one of the dominant formal approaches to understand reasoning and acting in humans, animals, and machines (Doya et al., 2007). These models have strong theoretical appeal due to their axiomatic simplicity and elegance that allow for a normative interpretation of how decisions should be taken optimally by rational actors (von Neumann and Morgenstern, 1944; Savage, 1954). Bayes-optimal models typically consist of two distinct components: first a model of beliefs that represent the states of unobserved variables taking into account the subjective uncertainty which is updated with new incoming data, and second an optimal decision-making scheme that selects actions in a way that maximizes the expected utility of the decision-maker given the current beliefs. Although it has been noted early on in the economic sciences that human decision-makers can substantially deviate from Bayes-optimality (Allais, 1953; Ellsberg, 1961), there is an extensive body of literature that has applied Bayesian modeling successfully not only to describe economic decision-making, but also to capture basic sensorimotor behavior like cue integration, perceptual categorization, visuomotor adaptation, and movement control in both humans and animals (van Beers et al., 1999; Ernst and Banks, 2002; Knill and Pouget, 2004; Körding and Wolpert, 2004; Körding and Wolpert, 2006; Braun et al., 2009).
Nevertheless, Bayesian models have been criticized on several grounds, foremost for their computational intractability, in particular in complex environments, their assumption of perfect rationality, their disregard for model mis-specification as well as their explanatory flexibility when allowing for arbitrary prior beliefs, likelihood models, or cost functions (Jones and Love, 2011). An alternative view to Bayes-optimal decision-making that does not assume an overarching optimization process or principle is sometimes called the Adaptive Toolbox approach to the mind based on many different specialized decision heuristics that are adapted to various environmental contexts (Gigerenzer and Gaissmaier, 2011; Gigerenzer et al., 2011). A key feature of heuristic strategies is that they are fast to apply and that they ignore a large part of the information at hand. Well-known heuristic strategies include the recognition heuristic (Goldstein and Gigerenzer, 2002)—assuming a higher value for an option whose name is recognized—, the take-the-best-heuristic (Gigerenzer and Goldstein, 1996a)—compare two options by their most important criterion and ignore other criteria—and elimination by aspects (Tversky, 1972) that gets rid of alternatives that do not meet the criteria of a certain aspect. Over the years a considerable body of evidence has built up in the literature showing how human decision-makers rely on heuristic decision-making in many real-world scenarios, for example in the financial and medical professions (Julian and Gerd, 2012; Forbes et al., 2015).
Usually, Bayes-optimal decision strategies that integrate all the available information into an optimal decision are regarded as incompatible with the idea of having multiple heuristics that ignore large amounts of information and that are not optimal in any particular sense, even though such heuristic strategies have been shown to work well in practical scenarios where exact models are unavailable or misspecified. Recently, however, there have been several proposals that suggest that heuristics can be regarded as Bayes-optimal strategies under certain constraints. Parpart et al. (2018), for example, have proposed that ignoring certain aspects of data in a heuristic decision-making scheme could be enforced within a Bayesian linear regression framework by putting a high weight on the corresponding prior over regression parameters. In another study (Belousov et al., 2016), Belousov and colleagues have suggested that different reactive and predictive strategies of catching a ball that were previously suggested as heuristic strategies can arise from an optimal stochastic controller when varying the level of observation noise and reaction time. While such adaptive changes in strategy selection depending on task constraints are well-known in the psychological literature (Svenson and Edland, 1987; Payne et al., 1988; Rieskamp and Hoffrage, 2008; Pachur and Bröder, 2013), a general mathematical formalization in terms of a single framework that explains both heuristic and Bayes-optimal decision-making poses an ongoing research problem. Such a framework might not only elucidate the mathematical principles underlying heuristic decision-making, but also shed further light on the question of how heuristics may be learned.
Here, we test an information-theoretic bounded rationality model (Braun et al., 2011; Ortega and Braun, 2011, 2013) for its ability to capture both Bayes-optimal and heuristic decision strategies in human subjects when varying the available information-processing resources in a binary classification task. In this model, limited information-processing capabilities are formalized abstractly by information constraints that quantify how much decision-makers can deviate from a given prior strategy when they face a decision task that is represented abstractly by a utility function. Decision-makers with more resources will be able to deviate more from their priors and adapt to the utility function, whereas decision-makers with limited resources will have to stick more to their prior strategy. The basic rationale is that any kind of resource constraint (e.g., time, memory, money, effort,...) will ultimately translate into a reduced ability for uncertainty reduction (Gottwald and Braun, 2019), which can be considered as an application of the rate-distortion principle of information theory (Cover and Thomas, 2006; Tishby and Polani, 2011). Previously, we have used such information-theoretic bounded rationality models to study effects of resource limitations in motor planning (Schach et al., 2018), absolute identification (Lindig-León et al., 2019), and sensorimotor interactions (Lindig-León et al., 2021).
In our study, we expose human subjects to a binary classification task by two-alternative forced choice, where a stimulus (here: a panel of abstract symbols) has to be assigned to one of two classes based on three different stimulus features (here: certain symbol arrangements)—compare Figures 1A,B. The features have different probabilities for the two stimulus classes and are independent, that means given the class membership the presence of a feature has no information about any other feature. The optimal decision-maker in such a scenario is the Naive Bayes classifier that provides the performance baseline irrespective of the available information-processing resources. This is in contrast to bounded rational decision-makers that optimize performance under given constraints on resources. In particular, we investigate the hypothesis that subjects behave like bounded rational decision-makers that focus on the most informative features under time pressure, thus, ignoring other stimulus information, which corresponds to some kind of Take-the-Best decision heuristic (Gigerenzer and Goldstein, 1996b). To this end, we measure the amount of information subjects extract from the different features and compare that to the information reduction expected by different bounded rationality models—compare. We find that subjects' behavior is best captured by an information-theoretic bounded rationality model that optimizes performance assuming capacity constraints on three separate information channels representing the three features, accounting for the fact that feature information is processed in separate chunks.
FIGURE 1
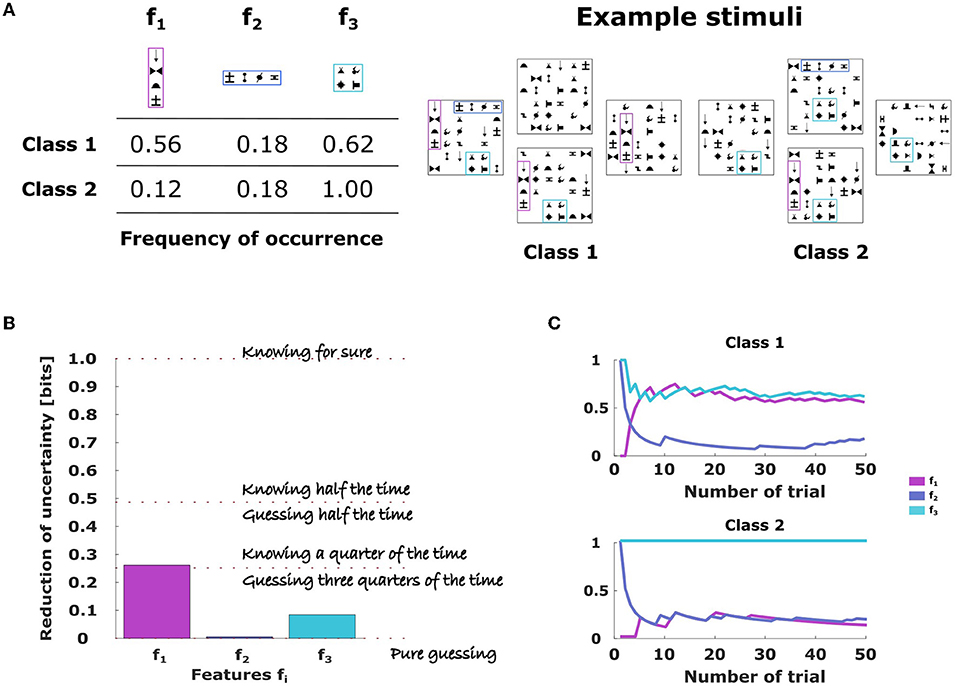
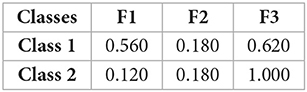
Figure 1. Binary classification task with three features. (A) Each feature is given by a symbol arrangement labeled f1, f2, and f3 and occurs with a certain probability for stimuli of each stimulus class, shown in the Table 1. Examples of combined stimulus pattern belonging to class 1 or class 2 are shown on the right. Crucially, subjects did not know the class membership, but had to infer it from the presence and absence of stimulus features. (B) The amount of information the different features carry about the stimulus class is measured by the mutual information: a value of 1 bit implies that class membership can be surely inferred, a value of 0 means that the feature provides no information and the decision-maker has to guess. A value in between implies that the feature provides some information and the subject can engage in some educated guessing. (C) Temporal evolution of the empirical frequencies of the different stimulus features. Empirical frequencies can be reliably estimated after less than 10 trials.
2. Methods ParticipantsThere were a total of 16 participants. They belonged to the age group 20–50, 11 of them conducted the task using remote access. The study was approved by the Ethics Committee of Ulm University. Subjects were informed about the purpose and method of the experiment as well as the ensuing data handling, and that they could withdraw from the study any time. During the initial familiarization phase of the experiment, subjects were explicitly instructed that stimuli were composed of three different features that could occur in isolation or in combination with each other along with distractor symbols. They were shown the three features which were each made up of four abstract symbols inspired by a previous study (Orbán et al., 2008). Subjects were told that they have to classify the stimulus patterns that they will observe into one of two classes and that they can learn this classification from feedback after each trial.
Experimental designTrial design. In each trial subjects were shown a 6 × 6 square panel (ca. 15 × 15 cm) made of 36 tiles full of blanks and symbols and they were required to press the keys 1 and 2 on the keyboard to indicate whether they believed that the presented stimulus belonged either to class 1 or 2, respectively. The key press had to occur within a given time window depending on the condition (fast condition 1s, medium condition 3s, slow condition 5s, otherwise the trial was counted as a missed trial. After each trial a dialogue box at the center of the screen would indicate to subjects whether the trial was correct, incorrect, or missed. Subjects could have breaks after every block of 50 consecutive trials with the same time constraint (fast, medium, or slow). In total, there were six blocks, that is 300 trials altogether per session, and two sessions per subject. The first three blocks of 50 trials in the first session were executed in the order slow, medium, fast, in the ensuing blocks the order was randomized. Each session lasted approximately half an hour. All evaluations in the paper are based on data from the second session.
Stimulus classes. There were two equiprobable classes of stimuli, where each class is defined like a bag-of-words model based on three independent features. In a bag-of-words model such features typically are given by characteristic words whose frequency of occurrence distinguishes, for example, spam from non-spam email. Similarly, in our task, the class-specific occurrence probabilities of specified visual features, each of which could either be present or absent, allows for the classification of stimuli into two separate classes. Based on the three features, we can distinguish eight different stimulus types that can be denoted by a binary vector x and that are associated with the two classes with different probabilities. In our experiment we used the following feature probabilities to generate 50 stimuli for each class and condition as a random template:
When subsequently counting the occurrences of features in this template, the empirical frequencies with which features occur did not exactly match the aforementioned probabilities due to the finite amount of stimulus samples. Instead, the empirical frequencies were given by:
We used the same random trial sequence template for all subjects, so we could ensure that each subject experienced exactly the same empirical frequencies. It should also be noted that the empirical frequencies of the trial sequence template could not be known immediately by subjects, but had to be learned. However, as can be seen from Figure 1C, the empirical estimates of the feature frequencies stabilizes already after 10 trials around their final values.
Stimulus design. The stimulus design shown in Figure 1 was inspired by a previous study (Orbán et al., 2008). Each stimulus was a 6 × 6 square panel, where each square could contain a symbol or a blank. To balance stimuli in terms of luminosity, each stimulus contained exactly 25 symbols and 11 blanks. The stimuli were characterized by three independent visual features where each feature corresponds to a spatially order chunk of four symbols. The chunks appeared in a fixed part of the panel, but their exact position could vary by two squares at most. Depending on the number of chunks present, more or less randomly placed distractor symbols were used to arrive at the total number of 25 symbols. There was an inventory of 20 different symbols out of which 10 were used to define the three chunks and all of them could be used as distractor symbols.
ModelsThe eight possible stimulus pattern can be described by a binary input vector x ∈ 3, for example for the first stimulus pattern with all cues present it would be x = (111). The distribution P(x) over stimulus pattern is given by P(x)=∑y∈P(x|y)π(y), where π(y)=12 is the equal prior probability of presenting a stimulus from either class, and P(x|y) is the generative model of the stimulus pattern in each class y. For our task, the generative model is given by
P(x|y=1)=∏j=13μjxj(1-μj)1-xjP(x|y=2)=∏j=13νjxj(1-νj)1-xjwhere μj and νj are the probabilities of the features occurring in class 1 and class 2, respectively, as determined from the experiment. The decision-maker's choice can be described by a binary output variable a ∈ corresponding to a selection of class 1 and class 2, respectively. A choice strategy then corresponds to a conditional distribution P(a|x) detailing the probability of selection class a given the stimulus pattern x. For example, if x = (111), the choice strategy is to assign x to class 1 with a probability p and to class 2 with probability 1 − p.
Naive bayes model. The Bayes-posterior for our task is given by the sigmoid P(y=1|x)=σ(wTx+w0) and P(y = 2|x) = 1 − P(y = 1|x) with the weight parameters
wj=logμj1-μj-logνj1-νjw0=∑j=13log1-μj1-νjAssuming a 0/1-utility of U(y, a) = δy,a with the Kronecker delta δy,a = 1 if y = a and δy,a = 0 otherwise, we can then define the optimal choice strategy P(a|x)=δa,a*(x) that maximizes the expected utility according to
a*(x)=argmaxa∑yP(y|x)U(y,a)Bounded rational model with a single information channel for action. Assuming the same expected utility as above given by EU(x,a)=∑y∈P(y|x)U(y,a), the bounded rational decision-maker with a single information channel for action seeks to find the optimal strategy P*(a|x) that maximizes the expected utility
P*(a|x)=argmaxP(a|x)∑x∑aP(x)P(a|x)EU(x,a)subject to the information constraint
I(X;A)=∑x∑aP(x)P(a|x)logP(a|x)P(a)≤Kwhere the prior is given by P(a)=∑xP(x)P(a|x) and K is a positive real-valued bound. The optimization problem is equivalent to the unconstrained optimization problem
P*(a|x)=argmaxP(a|x)∑x∑aP(x)P(a|x)EU(x,a)-1βI(X;A)where the precision parameter β is chosen to match the information bound K. The optimal strategy is given by
P*(a|x)=1Z(x)P*(a)exp[βEU(x,a)]with the optimal prior P*(a)=∑xP(x)P*(a|x) and the normalization constant Z(x)=∑aP*(a)exp(βEU(x,a)).
Bounded rational model with multiple information channels for action and perception. Assuming an internal state s = (s1s2s3) for perceptual processing and feature-specific information channels P(sj|xj) with j = 1, 2, 3 that learn to specialize in processing the three different symbol arrangements serving as features, the bounded rational decision problem with multiple information channels for both perception and action can be stated as a joint optimization problem, that does not only seek to optimize the choice strategy p(a|s) given the perceptual information s, but also learns to co-optimize the perceptual filters P(sj|xj), yielding:
argmaxP(s1|x1)P(s2|x2)P(s3|x3)P(a|s)Ex,s,a EU(x,a) -1β∑j=13I(Xj;Sj)-1βUI(A;S)where
I(Xj;Sj)=∑xj∑sjP(xj)P(sj|xj)logP(sj|xj)P(sj) I(A;S)=Ex,s,a[logP(a|s)P(a)]with the expectation
Ex,s,a[f(·)]=∑x1x2x3∑s1s2s3∑aP(x)P(s1|x1)P(s2|x2)P(s3|x3)P(a|s)f(·)The optimal information channels for perceptual processing of the features are given by
P*(s1|x1)=1Z(x1)P*(s1) exp (β∑x2x3∑s2s3P(s2|x2)P(s3|x3) ×P(x2x3|x1)F(x,s))P*(s2|x2)=1Z(x2)P*(s2) exp (β∑x1x3∑s1s3P(s1|x1)P(s3|x3) ×P(x
留言 (0)