
記住我


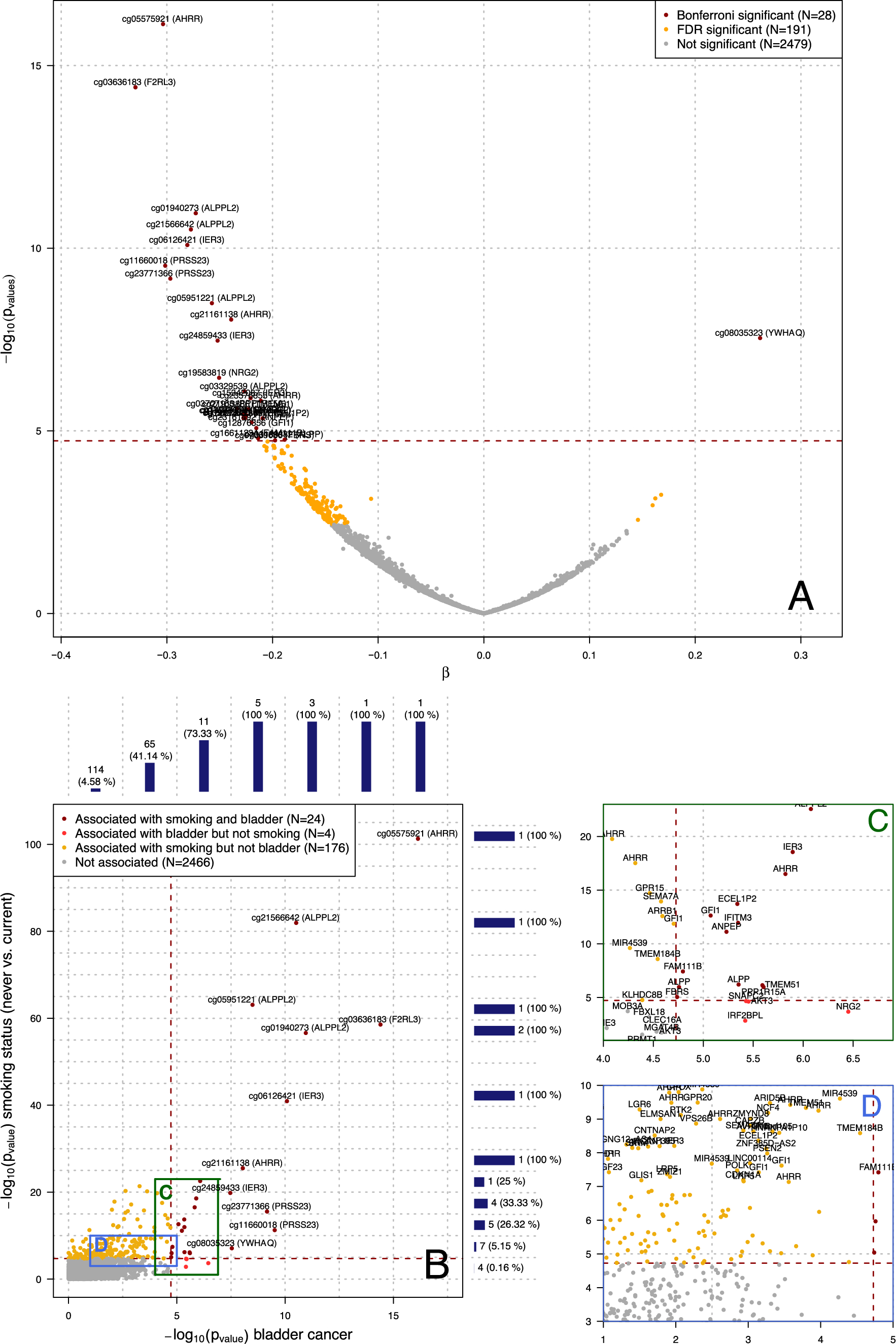
We conducted a systematic database search for peer-reviewed research articles from January 1, 2020 up to January 12, 2021 (see “Methods” section). Figure 1 shows the PRISMA flow diagram of our identification process. The search yielded 2,929 unique records of studies for screening. Through title and abstract screening, we identified 411 studies as potentially relevant and evaluated their full texts. Of these, we excluded 163 studies that did not meet the eligibility criteria. The most frequent reasons for exclusion were that (1) studies primarily simulated the effects of interventions in hypothetical scenarios rather than making inferences from observational data; (2) studies had a different objective than assessing the effectiveness of interventions, and (3) studies only assessed the association of health-related outcomes with population behavior (most often mobility), but not with interventions. The remaining n = 248 studies met our eligibility criteria and were included for subsequent data extraction. Importantly, 35 studies in our review sample contained multiple (i. e. up to three) analyses, e. g. with different methodological approaches, leading to 285 different analyses included. If not indicated otherwise, our results are presented at the level of individual analyses (and not at the level of studies).
We characterized the analyses along five dimensions (online Appendix D): study setting (D.1), outcome (D.2), intervention (D.3), methodological approach (D.4), and effectiveness assessment (D.5). In the Results section, if not stated otherwise, we use the term interventions to refer to non-pharmaceutical interventions. Where appropriate, we also point to exemplary studies of specific characteristics. Due to the large size of our review sample, however, we refrain from referencing all studies in the main manuscript and instead refer to our complete data extraction report in online Appendix E.
Fig. 1
PRISMA flow diagram. Overall, n = 248 studies were included. Some studies contain multiple analyses, such that the number of analyses included in the review is 285
Study settingThe analyses vary in their scope across populations, geographic areas, and study period. A systematic classification of the study setting is shown in Table 1.
Table 1 Systematic classification and frequency of the study setting (D.1)PopulationMore than half of the analyses studied multiple populations, i. e. multiple countries or subnational regions (e. g. states or cities). The remainder focused on a single population, i. e. a single country or subnational region. The analyses were performed at the national level, the subnational level, or both. If both levels were studied, the country and all its subnational regions were oftentimes considered, e. g. all states of the United States. Geographically, some regions and countries were more frequently studied than others, probably due to an earlier start of the pandemic or particularly high incidence and mortality during the first epidemic wave.
Study periodTypically, the study period covered both a rise and decline in new cases of the first epidemic wave in the analyzed population, and started before and ended after the analyzed interventions were implemented. However, many analyses also deviated from this pattern in one or several aspects (Table 1, D.1.5). Notably, in some analyses, the end date of the study period was still within the epidemic growth phase for some populations but already in the control phase for other populations.
OutcomeThe studies in our review sample used different types of health-related outcomes or surrogates. For every analysis, we identified the “raw outcome”, i. e. the outcome data which were self-collected or obtained from external sources and used as input for the analysis. In around half of the analyses, the raw outcome was analyzed directly to assess the effectiveness of interventions. The other half of analyses, however, involved an intermediate step, in which another outcome was computed from the raw outcome. This “computed outcome” was then analyzed instead of the raw outcome, or sometimes in addition to it. A systematic classification of the outcomes are shown in Table 2.
Raw outcomeWe identified three main types of raw outcome data used, namely (1) epidemiological population-level data, (1) epidemiological individual-level data, and (3) behavioral data.
(1) Epidemiological population-level data
The majority of analyses used population-level data on epidemiological outcomes, e. g. confirmed cases and deaths. The most frequent types were surveillance data, mainly the number of confirmed cases, but also deaths, hospitalizations, recovered cases, and, less frequently, intensive care unit (ICU) admissions. Importantly, some outcomes, such as recovered cases, were predominantly used to fit transmission models, in which case the effectiveness of interventions was rather measured in terms of a different latent outcome (see D.5 Methodological approach, Sect. 3.4). Frequently, authors also included several types of data (e. g. both cases and deaths), either to perform a separate analysis for each (e. g. as a robustness check) or to combine them in a joint model (e. g. a transmission model). Some analyses used surveillance data on other diseases than COVID-19, with influenza being the most popular choice. Such surrogate diseases have often been monitored over an extended period of time, which allows comparing their spread during the COVID-19 pandemic to earlier years. Notably, we found only three analyses that used external data on latent epidemiological population-level outcomes (e. g. the reproduction number). All other analyses using a latent outcome self-computed it from raw data in an intermediate step (see D.2.2 Computed outcome, Sect. 3.2.2).
(2) Epidemiological individual-level data
Instead of population-level data, some analyses also used individual-level epidemiological data. These were in particular data about individual cases with case ID, demographics, and epidemiological characteristics (e. g. the date of symptom onset or travel history). In some instances, this included contact tracing data with links between index and secondary cases, allowing the reconstruction of transmission chains. Two analyses also used genome sequence data of clinical SARS-CoV-2 samples [23, 24].
(3) Behavioral data
In addition to epidemiological data, a relevant share of analyses employed data on population behavior, mainly mobility data. These data were usually obtained through tracking of mobile phone movements and provided as aggregates at the population level, based on summary statistics such as the daily number of trips made, time spent at certain locations, or population flow between regions. Another, less frequently used source of information on human behavior were surveys regarding social distancing practices, such as adherence to interventions, face mask usage, or daily face-to-face contacts.
Table 2 Systematic classification and frequency of the outcome (D.2)Computed outcomeAround half of the analyses involved an intermediate step in which the raw outcome was used to compute another outcome, and the effectiveness of interventions were subsequently assessed using this “computed outcome”. Typically, the rationale of such analyses was to conduct the assessment on an outcome with clearer epidemiological interpretation and relevance to policy-making. At the same time, the methodological separation of outcome computation and effectiveness assessment into distinct steps allowed the authors to limit the complexity of their models. In our review sample, we identified four main types of computed outcomes:
(1)Measures of epidemic trend were computed to describe the overall trend of the epidemic, e. g. through the growth rate or doubling time of confirmed cases or hospitalizations. These measures were often interpreted as crude estimates of the infection dynamics in a population, and authors used them to achieve better comparability of outcomes across different populations.
(2)Epidemiological parameters were computed to measure specific infection dynamics, most often in terms of the reproduction number. That is, studies typically used the time series of confirmed cases in a population to compute the effective reproduction number over time and then assessed whether it decreased during interventions. A few analyses also used individual-level epidemiological data to compute and assess changes in epidemiologically relevant time spans such as the serial interval or the time from symptom onset to isolation.
(3)Summary statistics were typically used to aggregate the raw outcome of a population over time into a single figure describing the progression of the epidemic in the population. For example, authors computed the time until a certain number of documented cumulative cases was reached, or the time until the reproduction number first fell below one.
(4)Change points in the outcome were computed with the aim to find time points of presumably structural changes in epidemic dynamics and compare them with implementation dates of interventions in the subsequent analysis [10, 25, 26]. Typically, change points were computed for the time series of confirmed cases or mobility.
Of note, the raw outcome was not always used only for obtaining the computed outcome, e. g. changes both in the number of new confirmed cases (raw outcome) and in the reproduction number (computed outcome) were sometimes analyzed.
Method to obtain the computed outcome (1)Measures of epidemic trend were often obtained through simple computation (e. g. growth rate as percentage change in confirmed cases). Other analyses used simple modeling approaches, e. g. fitting an exponential growth model to the time series and extracting the exponential growth rate or doubling time from the estimated parameters.
(2)Epidemiological parameters were mostly estimated from confirmed cases or deaths. Some approaches fitted a compartmental transmission model to the raw epidemiological outcome. For this, the parameter of interest was either allowed to vary over time, or the model was fitted independently on different time periods. Other approaches employed a statistical method to directly estimate reproduction numbers from the observed outcome. Here, the method by Cori et al. [27] as implemented in the popular software package “EpiEstim” [28] for estimation of the instantaneous effective reproduction number was used in a large number of analyses. However, we found that statistical methods were not always applied correctly, which could have led to bias in the inferred transmission dynamics (see online Appendix A). Sometimes, authors also used methods to estimate reproduction numbers from contact matrices [29] (derived from surveys on personal contacts) or from transmission chains [30, 31] (derived from contact tracing data).
(3)Summary statistics were typically obtained through simple computation.
(4)Change points in the outcome were obtained by fitting a compartmental transmission model with special parameters representing points in time when the transmission rate changes [26]. Other analyses used special change point detection algorithms [25].
Data sourceThe majority of authors directly accessed surveillance data from national health authorities or other governmental bodies. In the case of individual-level data, which may be subject to privacy regulations, authors were often themselves affiliated to the relevant health authority. To obtain population-level data, a considerable share of analyses also used publicly available data from cross-country selections, e. g. the European Centre for Disease Prevention and Control (ECDC) [32], the Johns Hopkins University (JHU) [33], or Worldometer [34], which offer aggregated surveillance data internationally from various sources for the pandemic. Mobile phone tracking data were usually provided by corporate organizations such as Google [35], Apple [36], or Baidu [37]. A few analyses were also based on data collected by the authors, e. g. survey data on behavioral outcomes, seroprevalence studies, or data collected at a local facility such as a hospital.
Data availabilityData for the raw outcome was usually publicly available, in particular for epidemiological population-level outcomes such as cases and deaths because such data could oftentimes be accessed via the source that is documented in the manuscript. In several cases, the data was made publicly available by the study authors, e. g. by depositing the analyzed data in a public repository. For a small, yet considerable number of analyses, data was not accessible as the data was neither made publicly available nor the source of the data could be identified. Of note, data on epidemiological individual-level data was typically not available due to privacy concerns. Furthermore, corporate mobility data was widely available in the past, but access has recently been restricted by many providers.
InterventionThe analyses vary in the types of exposures and non-pharmaceutical interventions. A systematic classification is shown in Table 3.
Terminology for non-pharmaceutical interventionsVarying terminology was used by the literature to refer to non-pharmaceutical interventions (Table 3, D.3.1 and D.3.2). This is reflected in our search string, where we used a large set of terms in order to capture a broad range of relevant studies. While terminology sometimes reflected the specific types of non-pharmaceutical interventions that were analyzed, differences in terminology may also be the result of different research backgrounds of the study authors.
Table 3 Systematic classification and frequency of the interventions (D.3)Exposure types and types of single interventionsA considerable number of analyses examined one single [5, 38] or multiple interventions separately [2, 7]. Among these analyses, school closures and stay-at-home orders were examined most frequently, which may be due to these interventions being particularly controversial in the public discourse [39, 40]. The majority of analyses, however, did not examine multiple interventions separately but rather analyzed the a combination of multiple interventions jointly [41,42,43], which is often the case when multiple interventions were implemented on the same day and when thus the separate associations of the outcome with interventions could not be disentangled. A considerable number of analyses were even less specific by only analyzing whether interventions were altogether effective but without attributing changes in the outcome to specific interventions [44, 45]. Other ways to assess the effectiveness of interventions were: examining the start time of interventions [26, 46], e. g. to compare different delays with which governments responded to the pandemic [46]; dividing the public health response into different periods [47, 48]; dividing interventions into different categories [49, 50]; or summarizing the stringency of interventions to a numerical index at a specific time point [51, 52].
Of note, analyses that examined a combination of interventions often referred to this combination as “lockdown”. In the underlying analyses, such lockdowns typically included multiple interventions implemented on the same day [42, 53]. However, the specific interventions included in lockdowns varied considerably between populations. We therefore considered “lockdown” as an umbrella term for different combinations of interventions rather than as a specific type of intervention. Furthermore, some studies did not only assess the relationship between mobility and non-pharmaceutical interventions, but also between changes in mobility and population-level epidemiological outcomes. In these analyses, human mobility was typically defined as a continuous exposure. We extracted information on such complementary analyses of mobility as an addendum to the main review (see online Appendix E).
Coding of interventionsWhen multiple populations were jointly analyzed, coding of interventions may have been necessary in order to reconcile differences in the definitions of interventions between populations. For instance, the term “school closures” could refer to the closure of primary or secondary schools or universities. Differences across populations are thus reconciled during coding by deciding upon the type of intervention and providing a common name and definition that is then applied to all populations. As a result, such coding can be subjective and thus needs to be carefully documented and evaluated (see online Appendix A). Coding of interventions was necessary in around a quarter of analyses.
Source of intervention data and availability of data on exposureIf coding of interventions was not necessary, authors often obtained intervention data (i. e. the date of interventions) from a government or news website. Unfortunately however, the data source was often not provided by the authors and could thus not be evaluated. If coding of interventions was necessary, then study authors either coded the data themselves, i. e. collected the data from government or news websites and systematically categorized them or, more frequently, used externally coded data. The most popular choices for externally coded data were the Oxford Government Response Tracker [1] and, for the United States, the New York Times [54].
Methodological approachA variety of methodological approaches were used to assess the effectiveness of interventions. The methodological approaches extracted here describe the actual stage of estimating the associations of health-related outcomes with interventions. A systematic classification of the methodological approaches is shown in Table 4. An additional analysis of the average citation count per category is presented in online Appendix C.
Table 4 Systematic classification and frequency of the methodological approach (D.4)Empirical approachWe distinguished three general empirical approaches for assessing the effectiveness of interventions, namely (D) descriptive, (P) parametric, and (C) counterfactual approaches.
(D) Descriptive approaches were used by the majority of analyses: These approaches provided descriptive summaries of the outcome over time or between populations, and related variation in these summaries to the presence or absence of different interventions. For example, some analyses compared changes in the growth rate of observed cases before and after interventions were implemented [55, 56]. Of note, descriptive approaches could involve modeling as part of an intermediate step, where a latent outcome was computed from the raw outcome (see Computed outcome), while, afterward, a descriptive approach was used to the link the latent outcome to interventions. For example, some analyses used a single-population compartmental transmission model to estimate the time-varying reproduction number and then compared the reproduction number before and after interventions were implemented [57,58,59].
(P) Parametric approaches were used by a third of analysis: These approaches formulated an explicit link between intervention and outcome, where the association was quantified via a parameter in a model. Most frequently these were regression-like links between interventions and the reproduction number [2, 8].
(C) Counterfactual approaches were least frequently used: These approaches assessed the effectiveness of interventions by comparing the observed outcome with a counterfactual outcome based on an explicit scenario in which the interventions were not implemented. For example, the observed number of cases was compared with the number of cases that would have been observed if the exponential growth in cases had continued as before the implementation of interventions [60, 61].
Use of exposure variationEffectiveness of interventions were assessed by exploiting variation in the exposure to the intervention over time, between populations, or both. Assessments exploiting exposure variation over time contrasted the outcome in time periods when specific measures were in place with the outcome in time periods when they were not in place. In contrast, assessments exploiting exposure variation between populations were based on a comparison of the outcome between populations that were subject to specific measures with populations that were not. Only a small share of analyses exploited variation between populations or both between populations and over time.
MethodWe grouped the different methods used into (1) description of change over time, (2) comparison of populations, (3) comparison of change points with intervention dates, (4) non-mechanistic model, (5) mechanistic model, and (6) synthetic controls. We review these in the following.
(1) Description of change over time
The large majority of analyses following a descriptive approach examined the change of the outcome over time to assess the effectiveness of interventions. In some of these analyses, the focus was on the course of the outcome over time, typically by attributing the observed change (e. g. a reduction in new cases over time) to the analyzed interventions. For example, the outcome was assessed at regular or irregular intervals, which were not necessarily aligned with the implementation dates of interventions [44, 45, 62]. The majority of analyses, however, followed the logic of an interrupted time series analysis, i. e. the outcome was explicitly compared between time periods before and after interventions [63,64,65,66].
(2) Comparison of populations
A few descriptive analyses compared outcomes via summary statistics only between populations (i. e. without considering variation over time) to assess the effectiveness of interventions. In such analyses, the outcomes were compared between populations that were stratified by different exposure to interventions (e. g. populations that implemented a certain intervention and populations that did not) [67,68,69].
(3) Comparison of change points with intervention dates
Some descriptive analyses checked whether the dates of estimated change points in outcomes and the implementation dates of interventions coincide [10, 25, 70]. If both dates were more or less in agreement, this was taken as evidence confirming the effectiveness of the intervention. However, change point detection methods could also yield change points prior to the implementation of interventions, which was sometimes interpreted as a sign of additional factors influencing the outcome (e. g. proactive social distancing) [25].
(4) Non-mechanistic model
Non-mechanistic models are statistical models that typically make no explicit assumptions about the mechanisms that drive infection dynamics. Such models were used in both parametric and counterfactual approaches by a quarter of analyses.
In parametric approaches, non-mechanistic models—almost always (generalized) linear regression models—were used to model a direct link between interventions and outcome. Typically, dummy variables were used to indicate when (variation over time) [9, 71, 72] or where (variation between populations) [73,74,75] interventions were implemented. Analyses exploiting both variation over time and between populations typically used panel regression methods [5, 76, 77].
In counterfactual approaches, the non-mechanistic models used were mostly exponential growth models, and sometimes time series models (e. g. AR(I)MA or exponential smoothing) [41, 47, 61]. These models were fitted using data prior to when an intervention was implemented and then extrapolated the outcome afterwards.
(5) Mechanistic model
Mechanistic models have a structure that makes, to some extent, explicit assumptions about the mechanisms that drive infection dynamics. They were used in both parametric and counterfactual approaches by slightly more than ten percent of analyses.
In parametric approaches, the association of an outcome with an intervention was represented via a parameter that was functionally linked to the disease dynamics (i. e. via a latent variable) of the model. This was typically achieved by parameterizing the transmission rate or reproduction number as a function of binary variables, indicating whether interventions were implemented or not [
留言 (0)