
記住我




To study the characteristics of different cell groups of CRC, we collected the scRNA-seq profiles of 43,851 cells. As shown in the tsne map of 13 samples (Fig. 1A), the samples were mixed together. The tsne diagram of four patients (Fig. 1B) and tumour types (Fig. 1C) were also mixed together. Furthermore, the FindCluster () function was used to cluster cells and obtain 20 clusters (Fig. 1D). Next, we annotated the 20 clusters by ssGSEA (Table 1) to 7 cell types (Fig. 1E) (CD14 + + CD16- monocytes, CD14 + CD16 + monocytes, fibroblasts, memory B cells, memory T cells, red blood cells (erythrocytes) and thymic embryonic cells). The logfc = 0.35, Minpct = 0.15 and padj < 0.05 of FindAllMarkers were set to screen marker genes of the 20 clusters. The expression levels of the top five marker genes with the most prominence in each subgroup are shown in Fig. 1F, and the results of the marker genes are shown in Supplementary Table S1.
Fig. 1
The characteristics of different cell groups of CRC. A The tsne map of 13 mixed samples. B The tsne diagram of four patients and C tumor types are also mixed together. D The FindCluster () function was used to obtain 20 clusters. E Twenty clusters annotated to 7-cell types by ssGSEA. F The expression of the top five marker genes with the most prominence in each subgroup
Table 1 Clusters annotateTo better interpret and distinguish these 20 clusters, we analysed the cell types of the cluster marker genes. The results show the following: 1. Five clusters (C7, C9, C11, C13 and C17) were annotated as CD14 + + CD16- monocyte cells. We selected the first three marker genes to draw a violin diagram (Fig. 2A). At the same time, we performed KEGG annotation through the WebGestaltR package and screened the key pathways by FDR < 0.05 in these 5 clusters (Fig. 2B). 2. Two clusters (C5 and C19) were annotated as CD14 + CD16 + monocyte cells (Fig. S2 A-B). 3. Three clusters (C1, C8 and C10) were annotated as memory T cells (Fig. S2 C-D). 4. Seven clusters (C0, C2, C3, C4, C6, C15 and C16) were annotated as red blood cells (erythrocytes) (Fig. S3 A-B). 5. C14 were annotated as fibroblast cells, C12 were annotated as memory B cells and C18 were annotated as thymic emigrant cells (Fig. S4). The results of the 20-cluster enrichment analysis are shown in Supplementary Table S2.
Fig. 2
The cell types of the cluster marker genes. A The first three marker genes to draw a violin diagram and B We screened the key pathways by FDR < 0.05 in these 5 clusters (C7, C9, C11, C13 and C17)
Prediction and analysis of cellular cluster abundance based on TCGA databasesCIBERSORT was used to analyse the abundances of the 20 clusters in TCGA-CRC databases. We found that the abundances of 13 clusters were significantly different between CRC tumour and normal tissues. The abundances of C1, C2, C4, C5, C15, C16 and C19 were high and the abundances of C7, C10, C11, C13, C14 and C17 were low in CRC tumour tissues (Fig. 3A). Meanwhile, the results of survival analysis showed that high abundances of C4, C11 and C13 and low abundances of C5 and C14 were associated with better survival (Fig. 3B). At the same time, we found a significant correlation between C14 and patient prognosis.
Fig. 3
The abundance of 20 clusters in TCGA-CRC databases. A The abundance of C1, C2, C4, C5, C15, C16 and C19 was high, and the abundance of C7, C10, C11, C13, C14 and C17 was low in CRC tumor tissues. B The results of survival analysis showed that high abundances of C4, C11 and C13 and low abundances of C5 and C14 were associated with better survival
We applied WGCNA with the expression profile using the R package “WGCNA” to construct the gene coexpression networks of CRC patients. Pearson’s correlations were performed for all pairwise genes, and WGCNA was used to build a weighted coexpression network (Fig. 4A). We next calculated 5 as the optimal soft threshold for the adjacency computation. In the present study, the coexpression network conformed to the scale-free network, and we chose β = 12 to ensure that the network was scale-free (Fig. 4B).
Fig. 4
We applied WGCNA to construct the gene coexpression networks of CRC patients. A A weighted coexpression network. B β = 12 to ensure that the network is scale-free. C A total of 12 modules were obtained. D The red module is most related to the tumor and C14 cluster
Next, the expression matrix was transformed into an adjacency matrix, and then the adjacency matrix was transformed into a topology matrix. Based on TOM, we used the average-linkage clustering method to cluster genes and set 100 as the minimum number of genes in each module according to the standard of the hybrid dynamic clipped tree. We performed cluster analysis on the modules and merged the modules with closer distances into a new module (set height = 0.25, deepSplit = 3, minModuleSize = 100), and a total of 12 modules were obtained (Fig. 4C). In cluster analysis, the grey module represented a gene set that could not be aggregated into other modules. We further analysed the correlation between each module and the abundances of C4, C5, C11, C13 and C14 (Fig. 4D). The results showed that the red module was most related to the tumour and the C14 cluster. The red module contains 615 genes and is shown in Supplementary Table S3.
We chose the red module for more detailed analysis, and the R software package “WebGestaltR” was used for GO functional enrichment and KEGG pathway analysis (Supplementary Table S4). For the GO functional enrichment: 1. A total of 237 gene ontologies were annotated with significant differences in biological process (BP) (FDR < 0.05), and the top 10 are shown in Fig. 5A. 2. A total of 122 genes were annotated with significant differences in cellular components (CCs) (FDR < 0.05), and the top 10 are shown in Fig. 5B. 3. Fifty-nine gene ontologies were annotated with significant differences in molecular function (MF) (FDR < 0.05), and the top 10 are shown in Fig. 5C. For KEGG pathway enrichment of marker genes, a total of 28 pathways were significantly annotated (FDR < 0.05), and the results of the first 10 pathways are shown in Fig. 5D. These annotation results showed that these genes were closely related to tumorigenesis.
Fig. 5
GO functional enrichment and KEGG pathway analysis in the red module. A The top 10 significant differences in Biological Process. B The top 10 significant differences in cellular components. C The top 10 significant differences in Molecular Function. D The results of the first 10 pathways
Cell communication analysis of key clustersIn multicellular organisms, the basic process of cell life activities depends on cell–cell interactions, and the communication between cells is mostly mediated by multisubunit protein complexes. Based on the above analysis results, we found that the C14 cluster plays an important role in the tumorigenesis of CRC and analysed the cellular communication between C14 and other clusters. We used CellCharts to analyse the cell communication among the 20 cell clusters, and the results are shown in Supplementary Table S5. Among the 20 clusters, there were high cell-to-cell correlations in terms of the number and intensity of ligand–receptor interactions (Fig. 6A). By extracting the ligand–receptor information of each cluster, we found that C14 affects other clusters through ligand receptors; for example, C14 affects the C1 cluster through HLA-C-CD8A and clusters C2, C7, C12, and C19 by APP-CD74. The effects were also found in C14 clusters by others, such as C13 and C16 clusters affecting C14 via MDK-SDC2 (Fig. 6B).
Fig. 6
The cellular communication between C14 and other clusters. A Among the 20 clusters, there were high cell-to-cell correlations in terms of the number and intensity of ligand–receptor interactions. B The effects were also found in C14 clusters by others, such as C13 and C16 clusters affecting C14 via MDK-SDC2
Construction and evaluation of a prognostic risk modelNext, we performed Cox regression analyses among the 615 candidate genes in the red module above. The R-package survival Cox function was used to carry out a univariate Cox proportional hazards regression model, and 10 genes were obtained (p < 0.001) (Supplementary Table S6). Then, Lasso regression was used to solve the multicollinearity problem during regression analysis and reduce the number of genes in the risk model. We used the glmnet package to perform Lasso Cox regression analysis and the change trajectory of each independent variable (Fig. 7A). As lambda gradually increases, the number of independent variable coefficients tends to gradually increase. Next, we used a tenfold cross test to construct the model and confidence interval under each lambda (Fig. 7B). The model was optimal when lambda = 0.0175, and 8 genes were chosen to construct a risk model.
Fig. 7
Construction and evaluation of a prognostic risk model. A-B The model was optimal when lambda = 0.0175, and 8 genes were chosen to construct a risk model. C The AUCs of the risk model for predicting 1-, 3- and 5-year survival were 0.72, 0.70 and 0.65, respectively, and D patients with a high risk score presented significantly worse OS than those with a low risk score in TCGA databases. E The AUCs of the risk model for predicting 1-, 3- and 5-year survival were 0.79, 0.83 and 0.69, respectively, and F the prognosis of the high-risk group was worse in GSE17537 datasets. G The model could significantly distinguish high- and low-risk groups by T stage, M stage, N stage, stage, age and cancer status
The final 8-gene model is as follows:
$$\mathrm=0.225*\mathrm1+0.311*\mathrm+0.065*\mathrm3-0.212*\mathrm+0.136*\mathrm+0.158*\mathrm2+0.024*\mathrm1\mathrm-0.004*\mathrm.$$
The patients were stratified into high- and low-risk groups according to the best cut-off value of the risk score in TCGA-CRC databases. To investigate the diagnostic accuracy of the prognostic risk model, the areas under the time-dependent ROC curves (AUCs) were computed. The AUCs of the risk model for predicting 1-, 3- and 5-year survival were 0.72, 0.70 and 0.65, respectively (Fig. 7C). In addition, patients with a high risk score presented significantly worse OS than those with a low risk score (Fig. 7D). To determine the accuracy and robustness of the model, we used the GSE17537 dataset as the training set. The AUCs of the risk model for predicting 1-, 3- and 5-year survival were 0.79, 0.83 and 0.69, respectively (Fig. 7E). The prognosis of the high-risk group was worse (Fig. 7F). We further performed correlation analysis of the 8-gene model among clinical factors and found that the model could significantly distinguish high- and low-risk groups by T stage, M stage, N stage, stage, age and cancer status (p < 0.05, Fig. 7G). These findings further show that our model has good predictive ability for some different clinical factors.
GSVA and TMB analysis between the low- and high-risk groupsTo explore the relationship between the risk score and biological function in different samples, we performed ssGSEA using the “GSVA” R package. We calculated the scores on different features and obtained the corresponding ssGSEA score of each sample (Supplementary Table S7). The correlations between biological function and risk scores were further calculated (Supplementary Table S8), and functions with correlations greater than 0.4 were selected as shown in Fig. 8A. Enrichment analysis of risk score groups revealed that 8 pathways were negatively correlated and 32 pathways were positively correlated with sample risk scores. In addition, cluster analysis of enrichment scores was carried out based on 40 KEGG pathways. The results showed that RENAL_CELL_CARCINOMA and other related pathways increased with the risk score (Fig. 8B).
Fig. 8
The relationship between the risk score and clinical application. A The correlations between biological function and functions with a correlation greater than 0.4 were selected. B The results showed that RENAL_CELL_CARCINOMA and other related pathways increased with the risk score. The results of C univariate and D multivariate Cox regression indicated that the risk score was an independent prognostic factor for OS. E The risk score features have the greatest impact on survival prediction in the nomogram model. F The calibration curves for the nomogram for 1-, 3- and 5-year survival were almost identical to the standard curve. G The results of the DCA diagram show that the nomogram has a better evaluation effect than the others
We used mutect2 software to process the TCGA mutation data and calculate the tumour mutation load (TMB) of patients. There was no difference in TMB between the different molecular subtypes (Fig. S5A). In addition, we quantified the difference in the number of mutant genes (Fig. S5B), and there was no difference. Furthermore, we screened 12,489 genes with mutation frequencies greater than 3 (Supplementary Table S9) and screened genes with significant high-frequency mutations in each subtype by the chi square test, and the selection threshold was p < 0.05. Finally, 464 genes (Supplementary Table S10) were obtained. The mutation characteristics of the top 15 genes in each subtype are shown in Fig. S5C.
Construction of a nomogram integrating the risk score and clinical featuresTo assess the independence of the 8-gene model for clinical application, we used univariate (Fig. 8C) and multivariate (Fig. 8D) Cox regression to analyse the clinical information and risk score. The results indicated that the risk score was an independent prognostic factor for OS (HR = 2.68, 95% CI = 1.63–4.41, p < 0.05) in the TCGA-CRC database. According to the results of univariate and multivariate analyses, we constructed a nomogram model with clinical features (M stage and risk score) (Fig. 8E). In the model, the risk score features have the greatest impact on survival prediction, which indicates that the 8-gene risk model can better predict prognosis. As shown in Fig. 8F, the calibration curves for the nomogram for 1-, 3- and 5-year survival were almost identical to the standard curve. In addition, we used decision curve analysis (DCA) to evaluate the reliability of the model. The results of the DCA diagram showed that the nomogram had a better evaluation effect than the others (Fig. 8G). Furthermore, we performed Kaplan‒Meier survival analysis according to age, male sex, female sex, T stage, N stage, M stage and stage in the TCGA-CRC databases. Patients were stratified into the following subgroups: age > 65 or < = 65, male, female, T1-2 stage, T3-4 stage, N1-3 stage, N0 stage, M0 stage, M1 stage, MI-II stage, and MIII-IV stage. The OS of patients in the high-risk group was significantly shorter than that of patients in the low-risk group in the age > 65 or < = 65, male, female, T3-4 stage, N1-3 stage, N0 stage, M0 stage subgroup and MI-II stage subgroups. The above findings further showed that our risk model still has good predictive ability in different clinical clusters (Fig. S6).
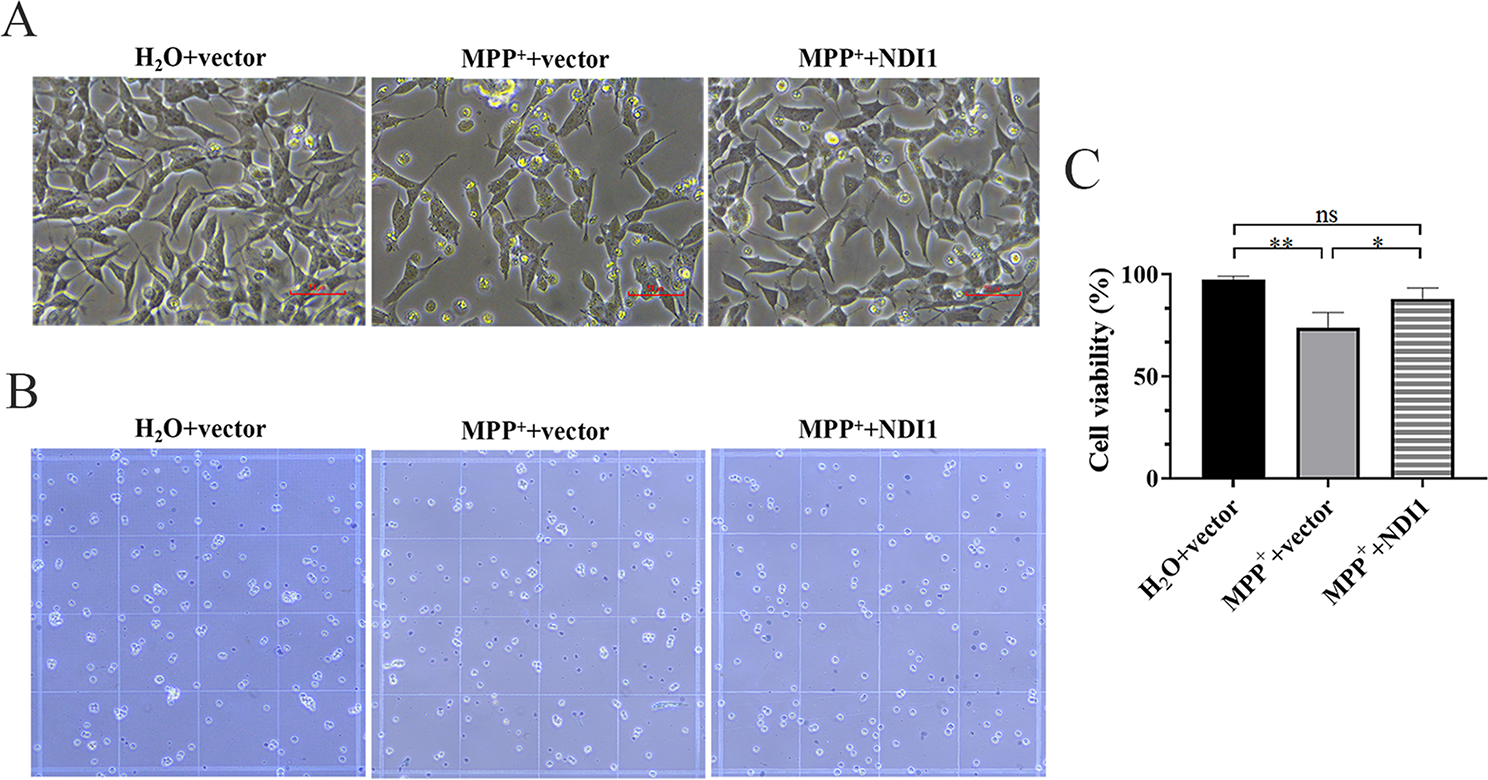
Expression and function analysis of the previously unreported model genes MPZ, SCARA3, MPP2 and PBXIP1 in CRCFurthermore, we examined the expression profiles of previously unreported model genes (MPZ, SCARA3, MPP2 and PBXIP1) in clinical samples from CRC patients by qPCR (Fig. 9A-D) and IHC (Fig. 9E-H) analysis and found that the expression levels of MPZ, SCARA3, MPP2 and PBXIP1 were high in CRC tissues.
Fig. 9
The expression of the unreported model genes. The results of A-D qPCR and E–H IHC analysis showed that the expression of MPZ, SCARA3, MPP2 and PBXIP1 was high in CRC tissues
To clarify the functional roles of MPZ, SCARA3, MPP2 and PBXIP1 in CRC cells, a clone formation assay and orthotopic colorectal tumour model were applied to detect the regulatory roles of these previously unreported model genes. Lentiviral expression vectors (pLKO.1-NC-GFP, pLKO.1-MPZ-GFP, pLKO.1-SCARA3-GFP, pLKO.1-MPP2-GFP or pLKO.1-PBXIP1-GFP) were used to construct MPZ (sh-NC and sh-MPZ), SCARA3 (sh-NC and sh-SCARA3), MPP2 (sh-NC and sh-MPP2) or PBXIP1 (sh-NC and sh-PBXIP1) interference cell lines in SW620 cells, and SW620 cells transfected with sh-NC were considered the control. Western blots were used to validate the cell transfection efficiency and the results are presented in Fig. S7A. Lentiviral expression vectors (pLVX-IRES-Neo-3xFlag, pLVX-MPZ-IRES-Neo-3xFlag, pLVX-SCARA3-IRES-Neo-3xFlag, pLVX-MPP2-IRES-Neo-3xFlag or pLVX-PBXIP1-IRES-Neo-3xFlag) were used to over-express MPZ (vector and MPZ), SCARA3 (vector and SCARA3), MPP2 (vector and MPP2) or PBXIP1 (vector and PBXIP1) in the CRC cell line SW480, and SW480 cells transfected with vector were considered the control. The results indicated that the inhibition of MPZ, SCARA3, MPP2 and PBXIP1 expression inhibited the colony formation ability of SW620 cells in vitro (Fig. 10 A) and tumorigenicity in vivo (Fig. 10 B-C), while overexpression of MPZ, SCARA3, MPP2 and PBXIP1 promoted the colony formation ability of SW480 cells in vitro (Fig. S7B) and tumorigenicity in vivo (Fig. S7C). IHC analysis of xenografted tumour tissues revealed that MPZ, SCARA3, MPP2 and PBXIP1 expression levels were low in the SW620/sh-MPZ, SW620/sh-SCARA3, SW620/sh-MPP2 and SW620/sh-PBXIP1 groups (Fig. 10D).
Fig. 10
The functional role of MPZ, SCARA3, MPP2 and PBXIP1 in CRC cells. The results indicated that the inhibition of MPZ, SCARA3, MPP2 and PBXIP1 expression inhibited the colony formation ability of SW620 cells A in vitro and B-C tumorigenicity in vivo. D IHC analysis of xenografted tumour tissues revealed that MPZ, SCARA3, MPP2 and PBXIP1 expression was low in the SW620/sh-MPZ, SW620/sh-SCARA3, SW620/sh-MPP2 and SW620/sh-PBXIP1 groups
留言 (0)