
記住我

We recruited adult dental patients from HealthPartners dental clinics in Minnesota (N = 2,115). Removing individuals who did not respond to the OES items leaves N = 2,078. Details about data collection and recruitment have also been provided in previous research papers [4, 16]. Our sample size satisfied sample size recommendations (of 500 or greater) for the Item Response Theory (IRT) model that we used in our analysis [22].
Measure: orofacial esthetic scaleDetails of the OES development have been published elsewhere [3] and are briefly summarized here. The OES consists of seven items addressing specific esthetic components (face, facial profile, mouth, rows of teeth, tooth shape/form, tooth color, gums) and one item assessing the overall impression (Table 1). Originally, the response format was a 0 to 10 numeric rating scale, anchored only with “very dissatisfied” and “very satisfied” (with appearance) at the extremes of 0 and 10, respectively. Scores of items 1 through 7 can be summed up to form an OES summary score that can range from 0 through 70, with higher scores representing less impaired esthetics [3, 16]. The eighth item represents an overall impression of OA and no specific esthetic component, so it is not included in any of the subscale scores. The OES was initially tested among Swedish prosthodontic patients [3]. Since then, the validity of OES scores has been assessed for other dental patients [4, 16], and general populations [23] in several other countries.
Table 1 OES and OHIP itemsAdditional measure: oral health impact profileDetails of OHIP development have been published elsewhere [24] and are briefly summarized here. The OHIP is the most widely used instrument to measure OHRQoL in adults with oral conditions [6]. It is a more comprehensive instrument than the OES. While the OES only measures OA, the OHIP measures seven conceptual dimensions of impact corresponding to Locker’s model of Oral Health [25], which is based on the World Health Organization’s (WHO’s) s International Classification of Impairments, Disabilities, and Handicaps from 1980 [26]. The dimensions of impact are functional limitation, physical pain, psychological discomfort, physical disability, psychological disability, social disability, and handicap. Originally, the OHIP questionnaire had 49 items [24] organized into the seven dimensions. Later, researchers developed 14- and 5-item versions [27, 28]. Based on previous exploratory [29] and confirmatory [30] factor analysis results from previous studies, there are six items (3, 14, 19, 20, 22, 31) that capture OA as an underlying factor or dimension in the 49-item OHIP (see Table 1). We used the six-item indicators of the OA OHIP scale in our analysis.
For each question, respondents are asked to indicate on a 5-point Likert scale (0- never, 1- hardly ever, 2-occassionally, 3-fairly often, and 4-very often) according to how frequently they experienced each problem within the past twelve months. Respondents may also be offered a "don't know" option for each question. All impacts in the OHIP are conceptualized as adverse outcomes, thus, a higher score indicates more negative impacts of oral health problems. Overall OHIP scores are computed in two ways. The simpler scoring method is to sum all 49 unweighted items. The second method is to standardize the seven subscale scores and then sum those standard scores.
Statistical analysisThe hypothesis of our study was-when a 11-point response format is collapsed to a 5-point response format, psychometric properties of OES scores will not be compromised. Multiple options for the 5-point response format exist if the study is designed to compare the 11-point response format with a "derived" 5-point response format. Thus, as the first step, we defined several “plausible” 5-point response formats to be investigated in the study, each created by a different method of collapsing the 11-point response format. A challenge was that the 11 points be assigned relatively evenly among five categories. Hence, we set up two simple principles for grouping categories within the 11-point response format: Rule 1 was to disallow 4-category grouping, and Rule 2 was to disallow 1-category grouping with Exception (1-category is allowed) at the beginning and the end of the response format. Rules 1 and 2 yielded balanced response groups, meaning that only groupings of 2- and 3-categories existed. Note that Exception corresponds to Patient-Reported Outcomes Measurement Information System (PROMIS) guidelines [31]. Following Rules 1 and 2 coupled with Exception, we obtained the six “derived” 5-point response formats (see Fig. 1). Response options of the 11-point response format were collapsed into fewer response options in a manner that any imbalance could be avoided. Our approach was in line with how response options are grouped together for the pain rating scales [32].
Fig. 1
The six derived 5-point response formats
Descriptive analysisFor the 11-point response format, we plotted histograms for Item 1–8 to examine the frequencies in each response option.
Classical test theory (CTT)Reliability analysis (Internal consistency)We computed Cronbach’s alpha [33] for the 11-point response format and six derived 5-point response formats to assess any changes in OES reliability. Also, we used a Bootstrap confidence interval for Cronbach’s alpha because the distribution of item scores could not be well approximated by a normal distribution.
Validity analysis (Correlation analysis based on sum scores)We computed Spearman’s rank correlation coefficients between the 11-point response format and the six derived 5-point response formats based on the observed scores (raw scores) for the seven items addressing specific esthetic components as well as the summary score. If the correlation is high (r > 0.95), then we can infer that there is a close similarity in the scores between the two response formats. Also, within each response format, we computed the correlation between the aggregated seven items and a global item assessing overall impression. If these correlations were similar in size, indicating a similar relationship to overall OA, we could assume the scores based on the different response formats have a similar interpretation and so are measuring the same “construct.” Furthermore, we computed correlations between summed scores of the 11-point and 5-point response formats of the OES, and that of the OA indicators from the OHIP to determine whether the relationship of the scores to the external criterion was invariant across the two response formats.
Confirmatory factor analysis (CFA)Reliability analysis (Internal consistency)We also derived the composite reliability estimate or Mcdonald's omega coefficient [34], which is an “indicator of the shared variance among the observed variables used as an indicator of a latent construct” [35].
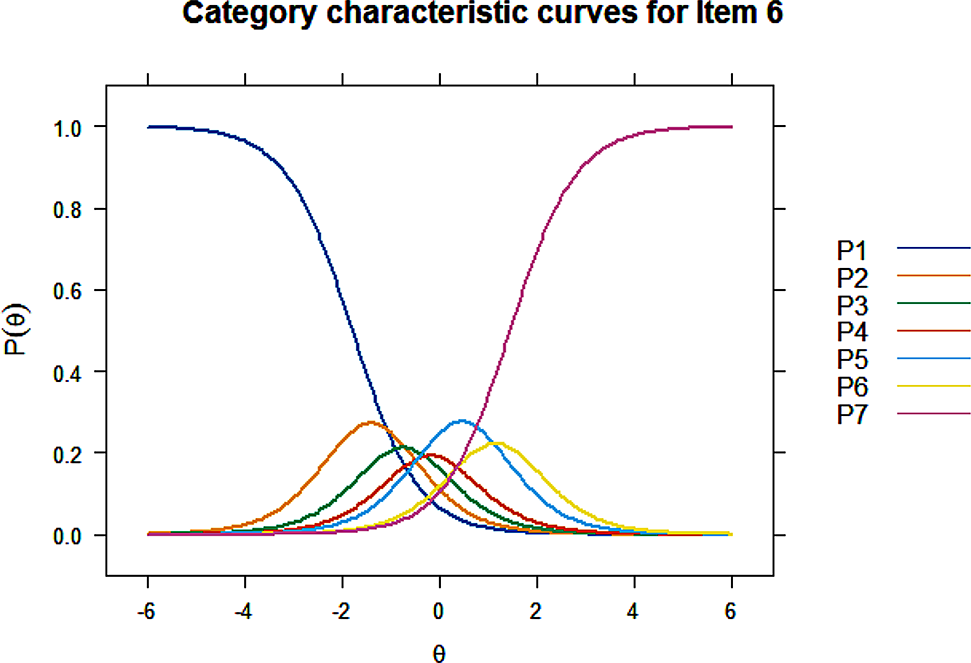
Item response theory (IRT)Item Response Theory (IRT) is a psychometric theory that refers to a family of associated statistical models that predict responses to a given set of items based on each item’s properties and the respondent’s position on continuum of latent trait of interest (OA) measured by the scale (OES) [36]. Unidimensionality of the scale is required in order to perform IRT based analysis. Previous studies have supported unidimensionality of the OES [3, 16]. Samejima’s graded response model (GRM) was used for calibration of our items [37]. This model is suitable for ordered scoring categories, which is the case for the OES. GRM specifies the probability of responding to a particular category or higher, versus responding to lower categories for each value of latent variable (trait)\(\theta\), which is (perceived) OA in our study. In GRM, each item is characterized by one slope parameter, and category threshold or location parameters at which the probability of responding to a particular category or higher is 0.5. Note that the number of category threshold parameters for an item equals one less than the number of categories. GRM is considered an extension of the two-parameter logistic (2PL) model for binary data, which is characterized by two parameters, i.e., slope and location parameters. While other models can be used for polytomous items with ordinal data, GRM is a popular model in research with health-related outcomes [38]. Also, we thought GRM is more appropriate than other models extending one-parameter logistic (1PL) model to ordinal data, which assumes equal slope parameters across items, because the slope parameter estimates were varying across items for the OES. With the GRM parameters, we can derive category response curves (CRCs). A CRC represents the probability of responding in a particular category as a function of trait level\(\theta\). We fitted a GRM to the 11-point response format (0 = very dissatisfied, 10 = very satisfied) and the six derived 5-point response formats.
Reliability analysis (Item/Test information)Information is analogous to reliability of measurement, and it is provided both at item and test (scale) level. An item information function or curve shows the amount of (Fisher) information an item contains along the continuum of a latent trait, i.e., OA [39]. CRCs from GRM can be transformed into an item information function. Multiple factors contribute to item information for polytomous models. For GRM, magnitude of the slope parameter, and the distance between the category thresholds or location parameters determine the amount of information. The test (or scale) information curve is obtained by simply summing the item information curves. Also note that the information function is related to measurement precision. Specifically, (conditional) information is inversely related to standard error of measurement (SEM) [40].
Furthermore, we computed the total information area (TIA), which represents the area under the test (or scale) information. To account for differential contribution due to unequal number of respondents along the latent trait continuum, we weighted the TIA with the proportion of respondents in each interval of the latent trait. Specifically, we divided the latent trait ranging from − 4 to 4 into 8 intervals with equal length and then obtained the proportion of the total respondents within each interval. This served as a “weight” to be multiplied by the average information within the corresponding interval. We will term this index “weighted total information area (TIA).”
Validity analysis (Correlation analysis based on IRT scale scores)We estimated the IRT scores using the GRM for each response format. The IRT scores refer to person location estimates from an IRT model. In IRT scoring, a respondent’s location on the OA continuum is obtained by utilizing the respondent’s item response pattern coupled with estimated item parameters [39]. Specifically, we obtained the expected a posteriori (EAP) scores [41]. EAP uses the mean of the posterior distribution as the latent traits. Then, we calculated the correlation between the IRT scores based on the 11-point response format and each of the six derived 5-point response formats. Furthermore, we computed correlations between the EAP scores from the 11-point response format and the derived 5-point response formats of the OES and those from the OA indicators of the OHIP. Note that the analysis is identical to what we described above for the CTT framework, but now the correlation analysis was performed using the scores from IRT analysis instead of sum scores. All analyses were performed using the mirt package in R [42].
留言 (0)