
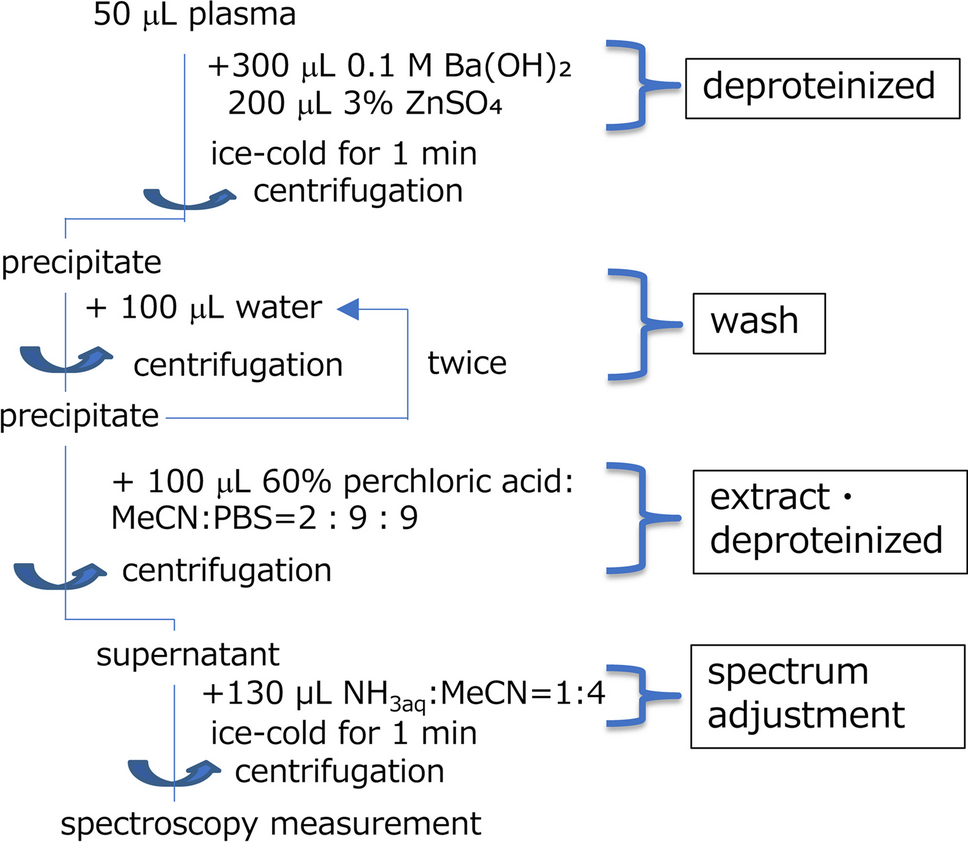
記住我





By reviewing these five well-performed compartmental models, we identified two categories for modeling enhancement such as (i) structure modification of the compartmental model, and (ii) parameter estimation enhancement. Table II summarizes the observed enhancement strategies.
Table II Modeling Enhancement Strategies Summarized from the Five Selected Compartmental Model-Based ForecastsStructure Modifications of the Compartment modelIn the basic compartmental model in epidemiology, the total population can be assigned to compartments labeled such as S (susceptible), E (exposed), I (infectious), or R (removed/recovered). The susceptible compartment includes the population susceptible to the disease. The exposed compartment comprises the population infected by the disease but not yet infectious to others. The infectious compartment consists of the population that can infect those in the susceptible compartment. Finally, the removed compartment includes the population removed from the system either because of recovering or death. Notably, the death/deceased compartment (labeled as D) is another commonly used compartment when the disease can be fatal for the population. Thus, the R compartment can also be interpreted as a recovered compartment, especially in case a separated death compartment is included, or the immunity is not lifelong. Under this framework, the number of deaths can be predicted using the death compartment (if existing) or by multiplying the population in each of the compartments with their corresponding death rates. The latter can be inferred by multiple methods, for example by using data from clinical reports or by dividing the reported number of deaths by the reported number of infection cases. Population assigned to different compartments can be updated dynamically with inter-compartmental transitions. Depending on the disease, different combinations of the above-mentioned compartments or even additional ones can be included in compartmental models.
A basic susceptible-infectious-removed (SIR) model (Fig. 3a) can be formulated as follows (Eqs. 3–5):
$$\frac=\frac-\gamma I,$$
(4)
where N is the total number of populations which equals S + I + R, β is the transmission rate and γ is the inverse of recovering time.
Fig. 3
Graphical representation of the basic SIR (Susceptible-Infectious-Removed, panel a) and SEIR (Susceptible-Exposed-Infectious-Recovered, panel b) compartmental models. β: the transmission rate; γ: the inverse of recovering time; σ: the inverse of incubation period. Dotted lines represent transmission
Similarly, a susceptible-exposed-infectious-recovered (SEIR) model (Fig. 3b) can be formulated by adding an exposed compartment to account for the incubation period (Eqs. 6–9)
$$\frac=\frac-\sigma E,$$
(7)
$$\frac=\sigma E-\gamma I,$$
(8)
where σ is the inverse of the incubation period.
SuEIR Model: a Modified SEIR Model with Unreported CompartmentIn classic SIR and SEIR models, only the number of reported infectious cases is used for model estimation. While asymptomatic infections have been reported during the COVID-19 pandemic (46), their exact number is hard to determine. The performance of the classic SIR/SEIR model may be weakened by a mismatch between the reported cases and the actual number of infectious cases defined in the model, due to the missing asymptomatic cases. To address this problem, Zou et al. proposed a susceptible-unreported-exposed-infectious-recovered (SuEIR) model (Fig. 4a) (33). The equations for the SuEIR model are listed as follows:
$$\frac=\frac-\sigma E,$$
(11)
$$\frac=\mu \sigma E-\gamma I,$$
(12)
where β is the transmission rate between the susceptible and “infected” groups (the latter including both exposed and infectious compartments), σ is the rate of exposed cases that are either confirmed as infectious or dead/recovered without confirmation, μ is the discovery rate (a parameter between 0 and 1) which reflects unreported and undiscovered cases, and γ represents the transition rate between the I and R compartments. This model addresses the mismatch between the reported cases and the actual number of infections. The estimation of the discovery rate (μ) can provide predictions on cases of asymptomatic infections.
Fig. 4
Graphical representation of the SuEIR model (Zou et al., 2020) with unreported state (panel a), and SI-kJα model (Prasanna, 2020a; Prasanna, 2020b) with infection caused by infectious individuals from other regions (panel b). μ: the discovery rate
SI-kJα Model: Heterogeneous Susceptible-Infected Model with Human MobilitySince classic SIR or SEIR models assume a closed population without contact with other populations, Srivastava et al. proposed a heterogeneous susceptible-infectious (SI) model with human mobility, named SI-kJα model (43, 44) (Fig. 4b). The SI-kJα model can simulate disease transmission between regions. In the SI-kJα model, an individual in a specific region (i.e., hospital/city/state/country) can be in either a susceptible or an infectious compartment. A susceptible individual can be infected by others from the same region or from other regions (known as a “moving state”). Due to the complexity caused by the sub-states design of the infectious state, this model uses a new fitting method differing from the traditional approach, as discussed later in the section “Estimating Parameters Using the Linearized System.”
Improving Parameter EstimationResearchers have used the following four approaches to improve parameter estimation (Table II): (i) Bayesian inference, (ii) fitting with incidence-cumulative cases (ICC) curve, (iii) using the linearized system, and (iv) incorporating real-world data in the model estimation.
Bayesian InferenceBayesian inference is a well-known data-driven method that uses Bayes’ theorem to update the parameter values when new data is available. The Bayesian inference model estimates the values of the parameters using previous knowledge and observation data. In Bayesian theory, the posterior distribution is proportional to prior distribution and likelihood distribution which can be formulated as Eq. 14.
$$P\left(\theta |Y\right)\propto L\left(Y|\theta \right)P\left(\theta \right)$$
(14)
where P(θ| Y) is the posterior distribution, L(Y| θ) is the likelihood distribution, and P(θ) is the prior distribution.
When estimating an interested parameter θ in the epidemic model, knowledge about the epidemic can be used and translated into the prior distribution while the likelihood distribution can be inferred from the observed data. Therefore, the posterior distribution can be estimated using approaches such as the Markov chain Monte Carlo (MCMC) method or the Hamiltonian Monte Carlo (HMC) method. This estimated posterior distribution can be used to provide the estimate of θ given the available data. When a new observation becomes available, the previously estimated posterior distribution can be used as a new prior distribution. Then, this new prior distribution along with the new likelihood distribution derived from the newly observed data can be used to estimate a new posterior distribution, which will then provide the updated estimate for θ. A strong prior can originate from known information and previous experience, thus leading to better control over parameters estimation. However, a relatively weak prior can still be implemented if a parameter is believed to be highly relevant to random or indescribable factors.
Depending on the situation, both strong and weak prior information in Bayesian inference can be used in parameter estimation for modeling the COVID-19 pandemic. Most of the essential parameters (e.g., length of the incubation period and days of recovery) in the compartment model can be assigned with strong priors obtained from clinical research. In contrast, the value of the transmission coefficient in SIR and SEIR models can be highly affected by external situations such as evolving public health guidance, and social or weather events, and as such can be assigned as a weak prior. The Umass-MechBayes model (30) implemented both strong and weak Bayesian priors and, as a result, gained a high level of accuracy for model prediction in the complex pandemic situation.
Fitting with Incidence-Cumulative Cases CurveNormally, when modeling a disease outbreak, the epidemic models aim to characterize and fit the curve of the observed daily infectious cases. In 2016, a novel approach was developed in the compartmental model by fitting the incidence of cumulative cases (ICC), in addition to the observed daily infectious cases (32). The EpiGro tool was developed based on this concept for disease outbreak forecasting (45).
This method first smooths and interpolates the epidemiological time curve. Then, an ICC curve is generated from this converted smooth curve. Next, an inverted parabola is fitted by minimizing the root mean square error to the ICC curve. Finally, the parameters in the fitted parabola can then identify the corresponding epidemic model. This approach was mainly designed to model a single peak of an outbreak, especially when available data is limited. Nonetheless, its performance is reported to be robust over multiple systems and noisy datasets (32).
Estimating Parameters Using the Linearized SystemIn the SI-kJα model, the states in the compartmental model are further divided into multiple sub-states by different time points with varying transmission rates (Fig. 4b). The model assumes that the infection occurring at time point t can only be caused by the infectious population between t and an earlier time point (t − k), indicating that a patient is infectious to others only for a certain period of time after being infected. In addition, following a similar dynamic, the local population can also be infected by the moving population from adjacent areas.
Developed from the basic compartmental model of SI components, a model for region p can be written as Eqs. 15–16.
$$\Delta _t^p=-\frac^p}_^k_i^p\Delta _^p,$$
(15)
$$\Delta _t^p=\frac^p}_^k_i^p\Delta _^p+\delta _q\frac_^k_i^q\Delta _^q,$$
(16)
where p is the target region, q represents regions connected to the target region p, F(q, p) is the moving population from q to p, \(_i^p\) and \(_i^q\) are the transmission coefficients in infectious sub-states (t − i) in the corresponding region p or q, δ is the transmission rate between the local and moving population, and k is the total number of infectious sub-states related to the infections occurring at time t.
To train the model, the system can be linearized by setting \(\delta _i^q\)equal to a new variable \(_i^p\) and fitting it as an independent parameter. This modification enables the model to use different infection rates for the moving population in different sub-states, which can capture the rapidly changing trends of the epidemic. When using βp to represent the vector containing \(_i^p\)’s and \(_i^p\)’s, the increasing cases in each sub-state can be simplified to Eq. 17.
$$\Delta _t^p=^p}_t^p,$$
(17)
where \(}_t^p\) contains the local and moving population in the corresponding sub-states. This linearized equation can then be solved using a constrained linear solver.
To train the interested parameters in βp, the following weighted least square function is used as an objective function for data fitting.
$$\mathrm=_=1}^}^-\mathrm}}}_}^}-^p}_t^p\right)}^2$$
(18)
where \(\Delta }_t^p\)is the actual reported number of cases and α is the forgetting factor with a value less or equal to 1, which gives more weight to more recently reported data.
By modifying the model structure and linearizing the system, the SI-kJα model can be used to forecast the spread of the virus while accounting for human mobility at the state- and country-levels. Since there are no assumptions on transmission coefficients, the model can adapt to real-life situations in a rapidly changing environment. However, adding these sub-states/transit compartments increases the number of parameters to be estimated and may potentially lead to over-parameterization.
Incorporating Real-World Data for Parameter Estimation (e.g., Social Mobility and Distancing)Since the spreading of an infectious disease is highly related to the extent of social interaction between people, multiple real-world datasets, such as social mobility, age structure, and number of tests versus population, have the potential to be useful in parameter estimation.
Mobility data is an example of a useful dataset to estimate the transmission coefficient (35, 47). Companies such as Apple (https://covid19.apple.com/mobility) and Google (https://www.google.com/covid19/mobility), publicly shared mobility data collected by cell phone GPS, thus providing high-quality mobility datasets for model building. Figure 5 shows the Apple mobility score versus the proportional daily increasing positive cases (https://covidtracking.com) from June 1, 2020, to January 18, 2021. We calculated the proportional daily increasing positive cases with the following equation:
$$D(t)=\left(N(t)-N\left(t-1\right)\right)/N\left(t-1\right)$$
(19)
where D(t) is the proportional daily increasing positive cases on day t and N(t) is the reported positive cases on day t. To account for the incubation period, we aligned the mobility scores from a specific day to the proportional daily increasing positive cases with an 8-day delay, i.e. D(t) was aligned to the mobility scores for day t − 8. For example, the mobility score for June 2 was aligned to the proportional daily increasing positive cases for June 10.
Fig. 5
Mobility scores from Apple Transit (https://covid19.apple.com/mobility) aligned to proportional daily increasing positive cases (https://covidtracking.com). Mobility from day 1 is aligned to the number of cases from day 8 to account for the SARS-CoV-2 incubation period
Mobility data is a good resource for modeling as indicated by the similar trends between the two curves (i.e., mobility and the delayed proportional daily increasing positive cases) (Fig. 5). In addition to the mobility data, other datasets (such as social distancing, weather information, and turnaround time of COVID-19 testing) can also be applied to compartmental modeling (35, 47, 48).
Another example of using real-world data can be found in the OliverWyman-Navigator model, in which time-dependent transmission coefficients are deduced from the existing datasets. The predicted transmission coefficient values for forecasting are then estimated by fitting a function to the historical transmission coefficient value in their modified SIR-based model. The function can be written as:
$$\beta (t)=_0\times T^x\times E^y\times F^z$$
(20)
which includes the information of an initial value (β0), the moving average of a mobility index from 8 days prior (T(t − 8)), number of tests per 1K of population (Et), speed of testing vs. recent new cases (F(t − 1)), and three fitted function parameters (x, y, and z) (35).
Although not included in the five well-performed models, the IHME model notably uses another interesting approach to handle real-world datasets. The model established by the IHME COVID-19 Forecasting Team incorporates real-world datasets as the covariates in a mixed effect model, instead of using a self-defined function (49). The mixed-effect model can be described as follows:
$$\mathit\left(\beta \right)=\boldsymbol\boldsymbol +_0$$
(21)
where X is a matrix containing all the covariates, α is the corresponding coefficients, and α0 is the random intercept. The covariates used in the model include both time-related features (such as social distance and mobility) and time-invariant features (such as population density and adult age-standardized tobacco smoking prevalence). After training the model, with the fitted α and predicted/given covariates, the future transmission coefficient values can be estimated and then used for case forecasting.
留言 (0)