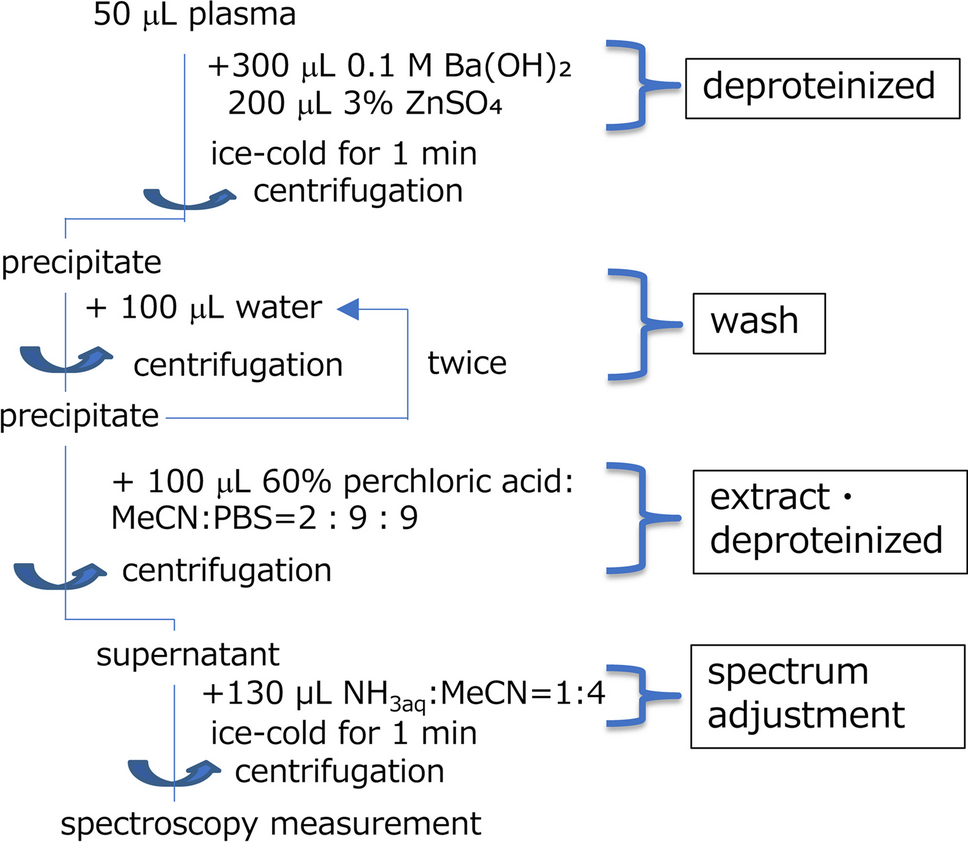
FDA encourages analysis of BE data only on the log scale and discourages testing for lognormality. FDA’s rationale (15) for this policy is that tests of lognormality in typical small samples have insufficient power to reject the hypothesis of lognormality, and failure to reject the hypothesis does not confirm that the data are approximately lognormal. However, because power is low for alternative distributions in small sample sizes (20), when (log)normality (i.e., lognormality or normality) is rejected in a small dataset, it can signal a potentially gross deviation. As noted above, an important benefit of the BEST approach is employment of a rich set of diagnostic tools that permit investigations of the distributions of BE datasets and model parameters that enable visual confirmation (or not) of lognormality of T/R distribution, and thus, validity of inference.
Inference using TOST relies on the assumption that log-transformed T/R follow a normal distribution, an assumption that is crucial in small sample sizes. Several publications have critiqued the use of a normal theory-based test such as TOST when the sample sizes are small and the data are not normal (3, 5, 9). While some may recommend sample sizes of over 30 for distributions with no extreme values and little skewness in order to provide assurance of approximate normality of the mean difference and the log-transformed GMR for the sample mean, the convergence rate of the central limit theorem is more complicated and a convergence bound based on the Berry-Esseen theorem depends on the variance, the sample size, and third absolute moment (21). In the presence of skewed distributions or very extreme values, estimated BE intervals may not be well approximated using normal theory-based procedures such as TOST, even when sample sizes are larger than 30. Beneficially, the posterior t-distribution parameter distributions and the posterior predictive distributions via the BEST procedure can be used to assess (log)normality.
BEST is an appealing alternative to TOST, by (a) accommodating a few extreme values or a heavy-tailed t-distribution and (b) providing the 90% credible interval for the mean difference, analogous to the 90% confidence interval of TOST. Importantly, Bayesian BEST procedures provide diagnostic posterior distributions for the parameters (mean, standard deviation, shape (degrees of freedom)) of the t-distribution, as well as the posterior distribution of any calculated quantities, such as the probability that the mean is in the BE acceptance region. Additionally, a value of 10 or less for the mode of posterior distribution of the shape (degrees of freedom) parameter can indicate that underlying data are not normally distributed but heavier tailed. In real BE datasets with measurement error, small sample size, and extreme values, the means of log-transformed T/R may not be well approximated by normal distributions, and hence the BEST method can be more resilient to violations of normality assumptions than TOST.
A crucial issue concerns which distribution adequately describes the T/R data for valid inference. Our simulations show that when the T/R are lognormal, TOST (absent extreme values) and BEST perform equally well. When sample sizes in BE studies are small or contain extreme values, normal-based inference such as TOST may be questionable. One alternative when data do not appear lognormal or normal would be to search for a different distribution. For instance, a Box-Cox transformation could be considered to transform data to be normally distributed (22). Other alternatives would be non-parametric methods based on the signed rank statistic (23, 24) or the bootstrap (25).
A criticism of using BEST is its reliance on broad prior distributions using current data; in particular, the prior for the mean is centered at the pooled mean from the current data and prior for the standard deviation is 1000 times its pooled standard deviation. Although not absolutely non-informative, the amount of prior information can be estimated from the effective sample size (26), which is approximately 1/1,000,000 of one observation or, to say it another way, a single observation in a bioequivalence study is five or six orders of magnitude more informative than this prior. Depending on the purpose of use, Bayesian procedures such as BEST can employ variably influential prior information that generate useful CrIs: (i) BEST with aforementioned non-influential priors depending slightly on the actual data for regulatory purpose, and (ii) BEST with more informative priors from pilot studies or the reference drug for formulation development. Since the BEST approach generally requires fewer subjects, serial BE studies in support of formulation optimization for BE may be replaced by fewer, smaller studies, especially if priors are made more informative from observations in the previous pilot studies. For example, in formulation development, extant information on the BE parameter distribution of the formulation from pilot study(ies) could be used to modify the prior distribution for BEST as described in Kruschke (12), leading to efficient formulation selection with smaller sample sizes in new drug development.
Schuirmann et al critiqued the Bayesian estimation approach using BEST (27), questioning the value of estimating the entire GMR distribution. A case can be made for estimating the entire log(T/R) distribution to assess lognormality and the effect of extreme values before making the BE determination. Challenging FDA’s admonition against testing for normality, the diagnostic evaluations by BEST of the entire GMR distributions of two real ANDA cases (Fig. 1) show lognormality in one case and not in the other, calling into question the validity of relying upon TOST in the later case. FDA guidance discourages robust inference procedures for BE assessment despite the potential biasing effect of extreme values on inference when the normality assumption of TOST is violated. In this case, the BEST procedure enables valid inference without violating the assumption that BE GMR datasets are well characterized by the t-distribution. Schuirmann et al (27) also expressed concern about how BEST sets minimally informative priors from the data; the amount of such influence is minimal as explained above.
When the underlying data are normally distributed, BEST is superior to TOST, and both are inferior to BEST AMR. However, BEST AMR does not appear to adequately control the passing rate at M=1.25, although BEST AMRmu does. Interestingly, this does not seem to be an issue at M=0.80. The behavior of BEST AMR in Fig. 2 for M=1.11 showing superiority to TOST and BEST may be in part due to its failure to control the type I error at M=1.25, a failure due to the variability introduced by dividing by the observed reference mean rather than its theoretical mean since this increases the variability of the estimated ratio. For normal data, BEST AMR using an acceptance region of [0.80, 1.22] is superior to BEST and TOST and maintains the type I error control (simulations not shown); more research is needed for the situation in which the underlying data are normally distributed.
Robustness to Extreme T/R Values
Extreme values (“outlier data”) are values that are significantly discordant with data for that subject and/or deviate from the typical trajectory of concentration-time data of the subject in a BE study (28,29,30,31). In crossover BE studies, extreme T/R values often can be observed in one or a few subjects. Extreme values can indicate either product failure, measurement errors, inherently high variability, or subject-by-formulation interactions. Inspection of scatterplots of log(T) versus log(R) can facilitate identification of the source of the extreme values as from either test or reference product. From a regulatory perspective, extreme values may only be removed from the BE statistical analysis if there is real-time documentation demonstrating a protocol violation during the clinical and/or analytical/experimental phase of the BE study (32, 33).
Our simulations demonstrate that BEST procedures yield higher BE passing rates than TOST if extreme values occur in a log-transformed data set. An extreme value can cause a larger estimated standard deviation and hence wider intervals in logged and non-logged data but both BEST procedures dampen the effect of this extreme value.
Arguably, extreme values in the reference product as opposed to the test product on the untransformed or log-transformed scale should not disadvantage the abbreviated new drug applicant. Rather than deleting such extreme reference product values, application of BEST on the log scale can decrease their influence. In typical small BE datasets (n<50), BEST robustly characterizes log(T/R) from a t-distribution. Applicants submitting non-normally distributed BE datasets and/or datasets that include one or more extreme log(T/R) values may be disadvantaged by failing BE via TOST due to forced normality, while being BE via BEST.
TOST or BEST—Which to Employ for BE?
FDA has stated that TOST is a “size-alpha test, a valid statistical test for average BE,” and that “empirical experience supports the view that normal-theory inference methods will be valid, even with the small sample sizes of typical BE studies” (1). TOST is known to be a size-alpha test if the data are lognormal or the central limit theorem provides a reasonable normal approximation of the log(GMR) for the actual sample size. Notwithstanding the fact that the long-term frequency underpinning TOST for type I error control is not assured in small BE trials, type I error control and validity of BE are not guaranteed if the mean of log ratios is not approximately normally distributed. This could occur if the underlying data are not lognormal or the sample size is inadequate to guarantee that the central limit theorem will provide a reasonable normal approximation. Despite FDA discouragement of testing of the normality of log ratios (and differences) (32), clear deviations from normality of log-transformed ratios in some real BE datasets may call into question the validity of the unexamined use of TOST for BE. Evaluation of goodness-of-fit of the normal and t-distributions can provide additional valuable information on aptness of the statistical model for inference of BE. Far from adding unnecessary “regulatory burden,” employment of the correct statistical model is crucial for valid inference of BE. The BEST procedures enable the posterior diagnostics and employ data-informed simulations for type I error control, rather than relying upon the unattainable long-term frequency assumption.
Valid inference depends upon pre-specifying the analysis method in the Statistical Analysis Plan (SAP). BE data distributions in the real world may be approximately normal, lognormal, or neither and commonly include extreme values. In the SAP, an alternative BE evaluation method different from TOST should be based on sufficient scientific justification and communicated with the agency. Pivotal BE studies, preceded by small (underpowered for BE) pilot studies comparing formulations, offer an opportunity to select the “best candidate” distribution for powering the pivotal BE study. The use of BEST approach can also be pre-specified contingent on the scatterplot identification of extreme values as demonstrated above. When extreme values occur only or more frequently in the reference product data, adopting the BEST approach to gain more power can be scientifically justifiable.
Two recent articles have used a Bayesian approach to bioequivalence on the log scale using the skew t-distribution, a four-parameter distribution which allows for non-symmetry (34, 35). Burger et al performed simulations for a crossover design with n=30 subjects and incorporated outliers by introducing contamination of 2.5 standard deviations of the lognormal with 1% probability (and 5% in the Supplemental Material). In the Supplemental Material, Burger et al reported 130 real datasets that showed outliers in 17 of the 130 data sets (13%). Among these, 17 datasets are 4 examples in which the Bayesian skew t estimator BayesT is outside the BE acceptance region [80%, 125%] but the two TOST-like estimators, Bayesian normal estimator (BayesN) and restricted maximum likelihood (REML), are not, and 5 examples in which REML and BayesN are outside but BayesT is inside. In 484 crossover studies submitted to FDA, we found that 28% rejected lognormality of T/R and 36% rejected normality of T-R by the Shapiro-Wilk test, mostly due to outliers. Additionally, in contrast to Burger et al, our study examined sample sizes from 10 to 50 and simulated outliers according to a 5% probability using a contamination standard deviation of 10 rather than 2.5, resulting in outliers more reflective of real-world data. We also examined the behavior in the realistic case in which the data are normal but not lognormal. An additional advantage is that BEST-BE provides easy access to diagnostic histograms for examining the posterior distribution of the parameters.
In this work, the extreme values were generated according to a symmetrical distribution around the underlying mean. Future work is warranted to assess methodology performance when data assume different distributions, with or without skewness after incorporating extreme values.





留言 (0)