
記住我



Available online 28 August 2022, 104163
 Highlights•
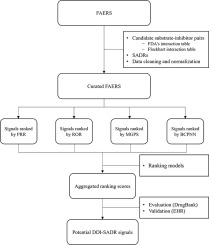
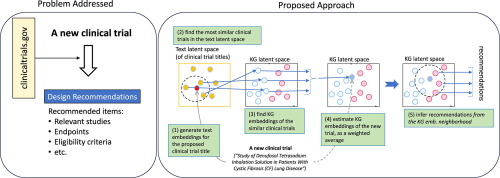
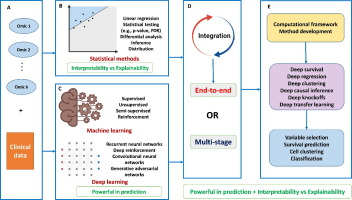
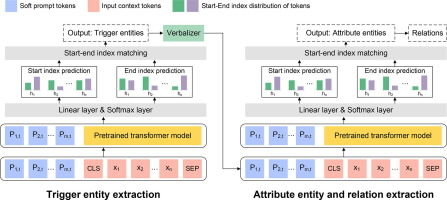
Highlights•We develop a probabilistic unsupervised model for multiple sequences contained in electronic health record data.
•The model structure contains subgroups and sub-models for each data element that is tailored to its sampling characteristics.
•Data from the Kaiser Permanente Northern California is used to train the model.
•Resulting subgroupings of the data elements are presented in the trained model, and described with respect to mortality risk.
AbstractWe develop an unsupervised probabilistic model for heterogeneous Electronic Health Record (EHR) data. Utilizing a mixture model formulation, our approach directly models sequences of arbitrary length, such as medications and laboratory results. This allows for subgrouping and incorporation of the dynamics underlying heterogeneous data types. The model consists of a layered set of latent variables that encode underlying structure in the data. These variables represent subject subgroups at the top layer, and unobserved states for sequences in the second layer. We train this model on episodic data from subjects receiving medical care in the Kaiser Permanente Northern California integrated healthcare delivery system. The resulting properties of the trained model generate novel insight from these complex and multifaceted data. In addition, we show how the model can be used to analyze sequences that contribute to assessment of mortality likelihood.
KeywordsUnsupervised learning
EHR data
Mixture modeling
Subgroup analysis
View full text© 2022 Elsevier Inc. All rights reserved.
留言 (0)