
記住我
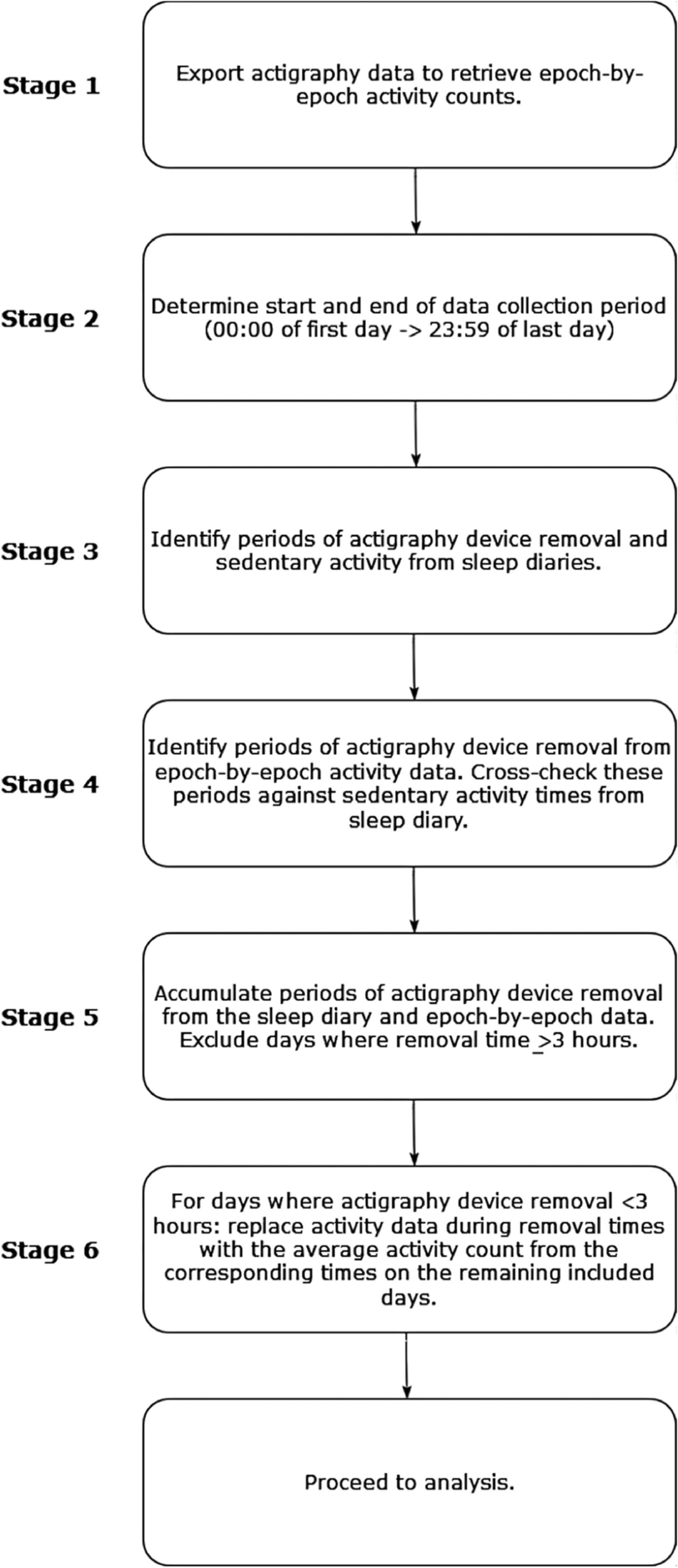
We estimated unrestricted means LPA models with pooled variances, specifying 1–8 classes with all seven neuropsychological indicator variables. The one-class LPA had unacceptable fit statistics, as indicated by substantially higher AIC and BIC values, compared with larger models. This was an important result in our small sample size, because if the data were insufficiently powered to reject a model of independence, then we could not justify testing more complex models. The two-class LPA solution had a single mode (i.e., convergence on a single solution) that indicated low average (40%) and high average (60%) classes (Fig. 2a), the former of which we hypothesized was dominated by individuals with ADHD.
Fig. 2
Plots of means for unrestricted models with 2–4 classes. The two-class solution converged on a single mode, while the three- and four-class models converged on multiple modes. The two best modes (i.e., with the highest loglikelihoods) are depicted. Profile means (y-axis) are standardized within the sample. SSRT stop-signal reaction time, VRT go-reaction time variability, FSIQ full-scale IQ, Digit Span Fwd digit span forward, Digit Span Bkwd digit span backward. Note recurring features in the data, such as the shape of class 1 (“low average”) across models, the shape of class 3 (“low control/high memory”) in the top three- and four-class models, and the shape of class 4 (“high FSIQ”) in the two best four-class models
In contrast, the three-class loglikelihood function had four modes. All four of these three-class solutions included the low average and high average classes found in the two-class solution, indicating stability. However, the third class varied across modes. The solution corresponding to the best-fitting mode (i.e., with greatest −LL, Fig. 2b) included a third class with a relative weakness on measures of inhibitory and response control (SSRT and VRT) and a relative strength on measures of memory (digit span forward and picture span). This low control/high memory class comprised about 9% of the sample, an indication of internal validity. The second highest −LL three-class solution had a less extreme pattern but still captured individuals with relatively low SSRT and VRT (Fig. 2c). Next, we fit the four-class model, which had 11 modes, In the best-fitting four-class model, the low control/high memory class was retained, in addition to a fourth class with another interesting pattern that captured about 5% of the sample (Fig. 2d) and was characterized by the combination of above average FSIQ and coding, with low SSRT; we called this group “high FSIQ.” The next best four-class model included the three classes seen in the second-best three-class solution (low average, high average, and low SSRT/VRT) as well as the high FSIQ class from the best-fitting four-class model (Fig. 2e).
Compared to three- and four-class models, the five-class model had the most sets of random start values go to the best mode (Table 1); thus, it exhibited better convergence. The best-fitting five-class model included profile patterns corresponding to most of the classes discussed above in the best and second best three- and four-class models, indicating stability and lending credibility to the idea that these groups correspond to real subgroups in the data. Specifically, the five-class solution specified the low average, high average, low control/high memory, and high FSIQ classes. The new fifth class, which we called “below average,” was characterized by below average performance across all indicators except SSRT. The pooled residual variances for the indicators ranged from 44% for digit span forward to 86% for coding, indicating modest internal validity. The next best-fitting five-class model had substantially poorer fit (−LL = −1066.56) and was not considered.
Table 1 Fit statistics: unrestricted models with 1–8 classesThe six-, seven-, and eight-class models were not well estimated. Start values went to many more modes (≥ 50) with only minimally different loglikelihoods and fewer than 10% of the start values converging on the top mode. Investigation of the structures of the solutions revealed highly variable patterns of means. The six-class solutions included classes with variability in the low-performance end of the distribution, which is theoretically interesting; however, the exact patterns of means varied across the solutions, indicating poor estimation of these classes. Additionally, the seven- and eight-class models included classes comprised of a single individual in the sample (i.e., class prevalence ~1%), indicating poor external validity.
Altogether, we observed consistent features throughout the 2–5 class models. We closely examined shifts in class proportions as new classes were added and observed a high degree of stability. Specifically, as new classes were added, individuals tended to move out of the high average class into a new class with more variability across neuropsychological indicators (Table 2). As a result, the high average class developed a flatter profile as model complexity increased (i.e., as more classes were added). This consistency of class membership was another positive indicator of stability and possible validity of our models.
Table 2 Class proportions in recurrent classes across best-fitting 2–5 class modelsStep 2: Single-method LPA with restrictionsEquality restrictionsHaving concluded that the three-, four-, and five-class models had the best model fit indices, we next imposed equality restrictions on indicator means across classes within each model. The goals of this step were to determine whether we could improve model fit by conserving statistical power, as well as to test stability of the classes. We began with the three-class model; based on estimates from the unrestricted three-class models, we restricted the means of VRT and coding to be equal across the low average and third classes (note, means of each indicator were equated across classes, not across all indicators). Likewise, we restricted the means of digit span forward, FSIQ, and picture span to be equal across the high average and third classes (again, means were equated only across classes, not indicators). This worked well in the three-class model, but the four- and five-class models showed poor estimation and stability. Thus, we decided to move forward without equality restrictions in our models.
Fixed parametersAn alternative to equality restrictions is to fix class item mean or variance parameters to a specific value. Based on results of the unrestricted models and our hypothesis that there would be a low-performing ADHD class and a higher performing control class, we added two sets of parameter restrictions. We specified two reference classes, with the first having means equal to −0.5 (i.e., one-half standard deviation below average) and the second having means equal to +0.5. By adding these restrictions, we reduced the number of parameters to be freely estimated by the models, thus increasing power to explain the remaining variance. At this stage, we examined models specifying 2–7 classes, based on favorable results returned for this range in the unrestricted models.
The models with two fixed classes (i.e., one class with means fixed to +0.5 and one with means fixed to −0.5) showed improved estimability over the unrestricted models. The two- through four-class models had good convergence, with only one or two modes. Interestingly, both of the four-class modes were variations of means patterns that had emerged in the unrestricted models, increasing confidence that these were true features in the data and supporting use of a model that had greater than three classes. The five-class model had worse convergence, with six total modes, but a clear best solution (best solution, 567/1000 start values; substantially worse fitting solution, 418/1000 start values). In the best-fitting five-class model, the three freely estimated classes showed the same features seen in the unrestricted five class LPA (i.e., classes characterized by low control/high memory, high FSIQ, and below average; Fig. 3). Class distributions ranged from 5 to 42%, suggesting at least six individuals sharing a common item profile, even in the smallest class. Error variances were slightly worse in this model, ranging from 50% for digit span forward to 86% for coding. This was unsurprising, in that we were limiting the flexibility of the model to fit the data. Posterior membership probabilities were reasonably good in this model, with 74% of individuals with their highest class membership probability above 0.8.
Fig. 3
Plots of means and 95% confidence intervals for the unrestricted means (left) and fixed parameter (right) 5-class models. The fixed parameter model specifies a class with means of −0.5 (Low Average) and +0.5 (High Average). Numbers in parentheses are estimated proportions for each class (unrestricted/restricted). Note these values generally do not shift much, implying stability of the models. Profile means (y-axis) are standardized within the sample. SSRT stop-signal reaction time, VRT go-reaction time variability, FSIQ full-scale IQ, Digit Span Fwd digit span forward, Digit Span Bkwd digit span backward. Class proportions are depicted in parentheses (unrestricted model/restricted model)
The six-class LPA with two restricted classes was better estimated than the unrestricted six-class model, with 794/1000 start values going to the best solution. The best-fitting six-class model replicated results of the five-class model, with a sixth class characterized by indicator means falling approximately in the average range, between the two fixed classes, which was not theoretically interesting. In contrast, the next best six-class solution specified a sixth class that described approximately a single individual. Entropy for the best-fitting six-class model was poor, while AIC was lower and BIC higher than the five-class model. Finally, the seven-class model with two fixed classes was again poorly estimated and not considered.
Altogether, the five-class model with fixed parameters demonstrated a good balance across AIC, BIC, and entropy; the top mode fits considerably better than the second best mode, and the classes were both stable and theoretically interesting (Table 3). Thus, we opted to move forward with the fixed class five-class model in subsequent analyses.
Table 3 Fit statistics: 2–7 class models with parameter restrictions specifying means of 0.5 and −0.5Sensitivity analysesAs part of the second step in Fig. 1, we sought to further probe the stability of the results of the −0.5/+0.5 restricted five-class model by changing the means values for the reference classes. First, we tried shifting the reference means only slightly, to 0 and 1, respectively. The 0/1 restricted model had worse fit than the −0.5/+0.5 model; however, both models had structural features similar to those seen in the unrestricted five-class model, supporting stability of the −0.5/+0.5 solution. The only notable change was that the extremity of the difference in means between the low average and below average classes was attenuated relative to the unrestricted model.
A concern when using latent variable models with small samples is that there may be insufficient statistical power to reject a bad model [41]. Thus, we next examined the fits of two alternative restricted five-class models with extreme (and thus unlikely) reference classes: −1/+1, −2/+2, and −1/−2. In support of our ability to reject a bad model even with our relatively small sample size, estimability of these extreme fixed models was substantially worse. There were frequent estimation problems and failures to converge, which did not occur in the previous models. Additionally, fit statistics were far worse, and several classes had estimated proportions near zero. Thus, despite having a small sample, our ability to see differences in fit statistics across models suggested there was sufficient statistical power to capture reliable features of the data and unlikely to simply be modeling noise. As seen in Table 4, relying simply on AIC, BIC, or entropy is not sufficient. AIC and BIC values both favored the restricted −0.5/+0.5 model; however, we were not able to reject the extreme restricted models in favor of the unrestricted model using BIC alone. Likewise, entropy values were high for the extreme −2/+2 restricted model, because most individuals were captured in the freely estimated classes, with the reference class proportions nearing zero.
Table 4 Fit statistics: five-class model with fixed parameter restrictionsEquality restrictions repeatedHaving identified a relatively stable five-class model with two fixed classes (means = −0.5 and +0.5), we revisited the possibility of further conserving statistical power through equality restrictions. This time, we equated means of the VRT and coding indicators across the low control/high memory and high FSIQ classes. This model converged on two top modes (148/1000 and 143/1000 start values, respectively) which had comparable fit statistics. However, introduction of these equality restrictions resulted in significant shifts in means for these indicators, suggesting the models were contorting the solution to accommodate the equality restrictions. Thus, we did not include equality restrictions in future models.
InterpretationTo examine whether differences among the five latent classes were meaningful, we back-transformed the standardized indicator variables. Indeed, we found that differences among the classes were clinically interpretable. For example, the below average class scored at approximately the 9th–25th percentiles on tests of memory and processing speed. The high FSIQ class had a mean IQ at the 98th percentile but average performance (~50th percentile) on tests of memory and processing speed. The low average class had notably slower performance on the coding test of processing speed (16th percentile), with performance on other tests ranging from approximately the 25th to 50th percentiles. Finally, the low control/high memory class performed well above average on tests of memory (~91st percentile) but had relatively weaker performance on a test of processing speed (25th percentile). As depicted in Fig. 3, the 95% confidence intervals were largely nonoverlapping.
Step 3: Add additional indicators to the modelNext, we aimed to go beyond the existing research by adding a second set of indicators to the model. In the current example, we added spectral power gathered during resting EEG, across five frequency ranges: delta, theta, alpha, low beta, and high beta. We hypothesized that by adding these lesser-understood indicators (i.e., brain data that do not have population normative values) to a model defined by indicators that were relatively well understood (i.e., neuropsychological test performance), we would increase the probability of identifying multi-method classes that were stable and theoretically meaningful.
Unrestricted multimethod modelFirst, we estimated a multimethod five-class model that included all seven neuropsychological and five EEG indicators. Parameter and equality restrictions were lifted, so that equal weight was allocated to all indicators. Results indicated that this unrestricted multimethod model was not well estimated; moreover, the EEG indicators overpowered the neuropsychological indicators, such that classes represented low to high EEG power and the structure of the five-class single-method model was entirely lost.
Restricted multimethod modelNext, we added restrictions so that we could estimate patterns of EEG indicator means corresponding to the five classes identified by the best-fitting neuropsychological model. We did not fix the means and variances of the neuropsychological indicators to match those identified in the final model because this would lead to improperly small standard errors and erroneous confidence in the model outcomes. Instead, we used multiple imputation with 20 imputed data sets. Individuals were randomly assigned to classes based on the posterior membership probabilities from the final neuropsychological model. For example, an individual with posterior probability of 0.90 for membership in the low average class would be included in that class during approximately 90% of the iterations; if this same individual had a posterior probability of 0.10 for the below average class, then their EEG values would be included in the below average class in about 10% of the iterations. Thus, the final estimate of means and variances for EEG powers within each latent class accounted for both class uncertainty and standard error of the sample means [42].
The resulting EEG patterns are illustrated in Fig. 4. There was significant variability in EEG indicators for these classes. The low control/high memory and below average classes demonstrated elevated theta:beta ratio, which has previously been described as a potential neural signature of ADHD [43], while theta:beta ratio was low for the high FSIQ class (Table 5).
Fig. 4
EEG spectral power profiles by neuropsychological latent class. Y-axis values are log-transformed absolute spectral power
Table 5 Theta-beta ratio estimates by latent classStep 4: Examine distributions of external variables across classesTo test the external validity and/or potential clinical utility of the multimethod model, the last step was to estimate counts, means, and variances of external variables of interest across classes, using latent class regression. First, we modeled sex and age as predictors simultaneously, because we did not have any a priori hypotheses about their association with the five latent classes. Sex was not significantly associated with any of the five classes (ps > 0.210). Older age was more strongly associated with the high average than the low average class (B = 0.48, SE = 0.24, p = .047, 95% CI = 0.01–0.95). No other effects of age were found (ps > 0.350).
We hypothesized that higher rates of ADHD participants in certain classes would add additional evidence of external validity for the model. Latent class regression failed because every member of the below average class was expected to be in the ADHD group. Thus, we again used multiple imputation with 20 iterations to estimate the proportion of ADHD versus control subjects in each class. ADHD diagnosis was highly probable in low average (88%), low control/high memory (70%), and below average (97%) classes and slightly less probable in the high FSIQ (34%) and high average (65%) classes.
留言 (0)