
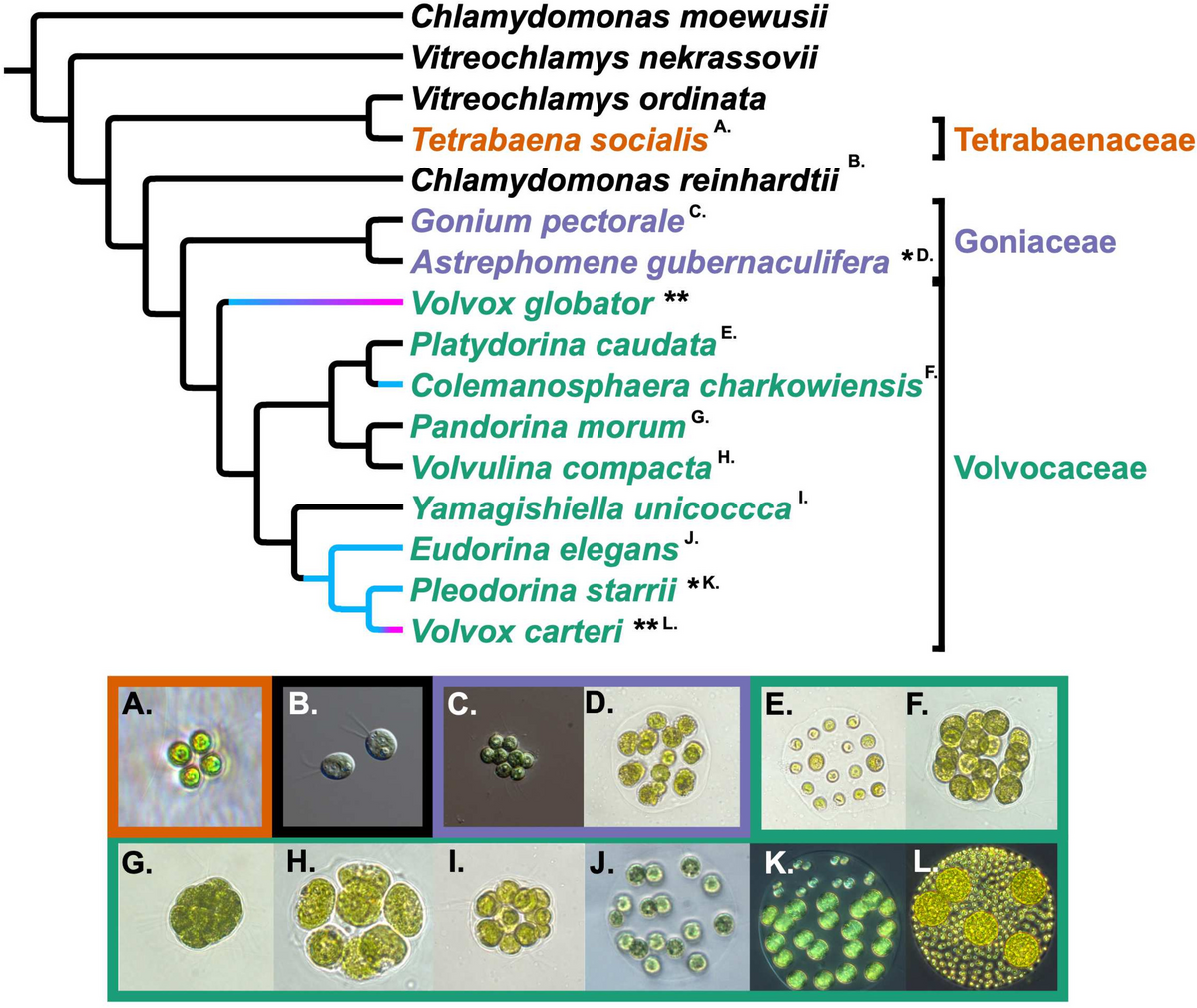
記住我


Classical short-read sequencing techniques are not suited to generate full-length transcriptomes with reliable sequence information, which is necessary for detection of diverse splice variants. Thus, high accuracy on sequence level is crucial for downstream experiments. We generated a comprehensive full-length transcriptome map using mRNA long-read sequencing (Fig. 1A). In murine wildtype heart, we identified 58440 unique isoforms with 99% predicted accuracy, originating from 12,789 genes (Fig. 2A–C). Exploring the underlying mechanism of transcript formation, we identified 117,182 known canonical (92.04%), 57 known non-canonical (0.04%), 6306 novel canonical (4.95%) and 3768 novel non-canonical (2.96%) splice junctions.
Fig. 1
Workflow overview. A Strategy for detection and validation of PGC-1α isoforms by SMRT sequencing in mice. Starting from raw data from SMRT sequencing, primary and secondary analyses were performed, resulting in full-length non-concatemers (FLNC). Then, a similarity search against PGC-1α was performed, yielding in 18 potential novel PGC-1α transcripts, resulting in 12 high-fidelity novel PGC-1α isoforms after quality control. B Strategy for investigating into differential expression of PGC-1α isoforms by diet-induced obesity and ischemia/reperfusion (I/R) injury in mice followed by qPCR. Mice fed either a standard chow or high-fat diet underwent I/R or sham surgery. Then, tissue from the infarct area and the remote area (distant from the infarcted area) as baseline as well as 3 and 16 days post I/R was collected and used for expression analysis using qPCR
Fig. 2
Analysis of SMRT sequencing in murine and human heart. Unique genes and isoforms and their characterization from automated analysis of murine (A–C) and human (D–F) datasets. Shown is the numeric classification of found genes and isoforms (A and D), number of isoforms per gene (B and E) and length-distribution of transcripts (C and F). Details see text
The majority of all found isoforms (n = 22,186) used junctions and corresponding exons matching the annotation (‘Full-Splice-Match’, FSM). Respectively, 16,579 isoforms used known splice junctions in consecutive order with some parts missing (e.g. last part of a transcript; ‘Incomplete Splice Match’, ISM). The minority of all isoforms were either novel in catalogue (NIC, n = 8466), using known splice junctions, but resulting in different transcripts, or novel not in catalogue (NNC, n = 9009), using new splice junctions and resulting in previously not annotated transcripts. The overall quality of the dataset was excellent (see Additional file 1: Figure S1).
Deciphering novel full-length transcriptome in human heart by long-read sequencingAs knowledge on human data is even more limited, we aimed to unravel the human heart transcriptome by means of the same approach. Thus, we created a transcriptomic map using mRNA derived from left ventricle from one patient undergoing LVAD-Implantation. In human heart, we identified 66,096 unique isoforms originating from 15,062 genes (Fig. 2D–F). Here, 120,036 known canonical (92.45%), 191 known non-canonical (0.15%), 6989 novel canonical (5.38) and 2616 novel non-canonical (2.01%) splice junctions were detected. The majority of all found isoforms (n = 24649) was categorized as FSM, 17,320 isoforms as ISM. A substantial part of all isoforms was either NIC (n = 12820) or NNC (n = 7255). The overall quality of the transcriptomic data was also very good and comparable to the murine dataset (Additional file 1: Figure S1).
Detection of 12 novel PGC-1α isoforms within the full-length-transcriptome of the murine heartWithin our novel and complete cardiac transcriptome, we further evaluated expression of PGC-1α as an example for a complex genomic region/structure yielding highly diverse isoforms. These isoforms derive from multiple splice events as well as different promoter sites and regulate diverse biological functions in vivo [1,2,3]. Two approaches were performed (see also workflow in Fig. 1A): First, we used our high-quality, full-length, clustered transcripts after mapping to reference genome and filtered for those with potential open reading frame (ORF). Due to a potential loss of isoforms during filtering steps of the automated pipeline, we further performed a similarity search against PGC-1α within reads without previous clustering and mapping (full-length, non-concatemers; FLNC). As these reads are non-polished and therefore not error-corrected, manual curation was necessary. This led not only to the identification of six known but also remarkably 18 potentially novel PGC-1α transcript variants with valid ORF prediction (Fig. 1A). We confirmed cardiac expression of 12 of the predicted novel transcripts using qPCR (Fig. 3 and Additional file 1: Figure S2).
Fig. 3
Overview over PGC-1α isoforms in murine heart (passed QC). PGC-1α isoforms (mRNA) after SMRT sequencing which passed QC filtering (Fig. 1): Differing starting exons 1a, b, b’ or c (blue boxes), canonical main exons (orange boxes), novel/altered exons (red boxes) and functional domains (green boxes, details see text). Length of boxes indicates relative length of nucleotides (true to scale, with exception of exon 8: shortened bp marked), asterisks and red background layer indicating novel isoforms. A Isoforms consisting of either exon 1a, b, b’ or the novel exon 1c followed by only canonical main exons. B Isoforms starting with exon 1a or b followed by canonical exon 2 to exon 12 and then followed by a novel exon 13b and novel exon 14 (new C-terminal end). C Isoforms with starting exon 1a or b and novel exon 6b, ending in the canonical C-terminal end (two isoforms) or with a novel exon 13c (one isoform). D N-terminal isoforms (known), with either starting with exon 1a, b or b’ and ending preliminary due to an alternative exon 7b. E Novel N-terminal isoform, shorter than the known (see D; therefore prefixed with ‘s’), ending in a novel exon 3b / exon 4b. This isoform is the shortest isoform in the overall pattern. F Novel isoform group consisting of different splicing events upstream exon 3, resulting in a shift of the start codon inside exon 3 with valid open reading frame. Three variants exist, differing in the 5′-end (either canonical C-, novel C- or N-terminal end)
Annotation and prediction of functional domains in known and novel transcriptsAfter identification of 12 novel and 6 known PGC-1α isoforms, we classified and annotated those also with known functional protein domains. We assigned known functional protein domains to the known isoforms and extrapolated those also on the potential novel transcript variants using motif annotation and prediction tools (detailed search strategy and references see methods) revealing existence of six main protein domains: Two transcription activation domains (AD1, residues 30–40 and AD2, residues 82–95), a protein-recognition motif involved in transcriptional regulatory processes (LLXXLL-motif, residues 141–147), the PDB domain 3D24|D involved in binding of the oestrogen-related receptor-alpha (ERRalpha, residues 198–218), a binding domain for interaction with the interaction partner PPARγ (residues 292–338) and finally a RNA-Binding-motif, possibly involved in splicing processes of downstream mRNA targets (residues 677–746).
Integrating the structural differences on mRNA sequence level as well as annotation of functional domains led to separation of 6 groups of isoforms:
The first group characterized by a differing starting exon in each isoform is built of 13 exons, encoding all known protein domains, and leading to protein lengths between 793 and 802 amino acids (aa) (Fig. 3A). This group includes the ‘reference’ long canonical isoform PGC-1α-a as well as two more known (PGC-1α-b and PGC-1α-c) and a novel isoform (named PGC1 α-d). The latter contains a novel starting exon which we denominate exon 1c, according to the known starting exons 1a, 1b and 1b’).
The second group of two novel isoforms (CT-PGC-1α-a and CT-PGC-1α-b) includes transcripts encoding all known PGC-1α protein domains (810 and 814 aa) and can be classified by a novel C-terminal end, built by alternative splicing events in exon 13 and the former 3′-UTR (Fig. 3B). They consist of either exon 1a or 1b followed by canonical exons 2–12 and end with two novel exons (exon 13b and exon 14, Additional file 1: Figure S3, A).
The third group consisting of three novel isoforms, which contain an alternative (shorter) exon 6b with preserved open reading frame (Fig. 3C and Additional file 1: Figure S3, C). In this group, no known protein domains are affected. Two isoforms end at the canonical C-terminus (PGC-1α-trE6-a and PGC-1α-trE6-b, 785 and 781 aa) and include a novel exon 13c (see also Additional file 1: Figure S3, B), resulting from a splice event between exon 13 and the 3′-UTR (PGC-1α-trE6-E13c, 783 aa).
The fourth group consists of the known N-terminal isoforms with premature stop within a truncated exon 7 (NT-PGC-1α-a, NT-PGC-1α-b and NT-PGC-1α-c; 257-270aa, see Additional file 1: Figure S3, D), missing the PPARγ-binding domain as well as the RNA recognition motif (Fig. 3D).
A fifth group with a short single isoform (sNT-PGC-1α, 117 aa), built up by exon 1a, exon 2 and two novel exons (Figs. 3B and 4B, see Additional file 1: Figure S3, E), only contains the two activation domains AD1 and AD2 but is missing all other functional domains (Fig. 3E).
Fig. 4
Organ-specific expression profile of E1c-transcript (exon 1c). A Graphical illustration of PGC-1α-promoters and corresponding starting exons. The canonical promoter, responsible for exon 1a, lies between the alternative (known) promoter (regulating exons 1b and b’) and the new putative promoter site controlling novel exon 1c. B Novel predicted promoter site associated to exon 1c. Prediction (using ‘ElemeNT’57) of mammalian initiator element (Inr) and corresponding downstream promoter element (DPE) around the transcription start site (marked in grey) of exon 1c. C Expression data of DNA samples derived from qPCR with primers targeting new Exon1c-Exon2-Junction in heart, skeletal muscle (SkM), brown adipose tissue (BAT), white adipose tissue (WAT), kidney, spleen, liver, pancreas, mid-brain and telencephalon (Telenc.), normalized to housekeeper (NUDC) and factorized by 1000 for better visualization. Highest expression can be observed in BAT and muscle tissue (heart, SkM); lower, but detectable, expression levels in kidney, WAT and brain. No detection (n.d.) of the new junction could be seen in liver, pancreas and spleen
Finally, the last group of (novel) isoforms is characterized by splicing events upstream of exon 3, resulting in a shift of the start codon inside exon 3 with a valid open reading frame (Fig. 3F and Additional file 1: Figure S3, F). Here, three variants exist (PGC-1α-E3c, CT-PGC-1α-E3c and NT-PGC-1α-E3c), differing in the 5′-end (either canonical C-, novel C- or N-terminal end; see also Additional file 1: Figure S3, A and D, resp.). While all of them lost the activation domains AD1 and AD2, only the NT-PGC-1α-E3c misses also the PPARγ-binding domain as well as the RNA recognition motif.
Discovery of a novel promoter region of PGC-1α with high conservation in murine and human heartThe novel transcript PGC1a-d in the murine dataset contains a new starting exon (exon 1c; Fig. 3A), yet otherwise exhibits the same sequence as the known PGC-1α-a (Fig. 3A), which is the major and most abundant isoform in our and in all published datasets. Exon 1c originates downstream of the known promoter region for exon 1a (Fig. 4A). This finding suggests, particularly considering the known mechanisms of transcription initiation within this gene locus, identification of a new promoter site. Using promoter prediction tools, we identified a transcription initiator as well as a promoter element preceding the novel exon 1c, both necessary elements for mammalian transcription start sites (Fig. 4B). Remarkably, we found a homologous transcript with the new exon 1c in multiple full-length reads within the human SMRT dataset as well including hints for conservation across species by sharing most of the predicted amino acids (Additional file 1: Figure S4). For analysis of tissue-specific expression of the Exon1c-transcript, we designed primers covering the exon 1c–exon2 junction and confirmed sequence identity of the amplified PCR fragment by direct sequencing (Additional file 1: Figure S2, F and Additional file 1: Figure S5). This novel Exon1c transcript is expressed in different murine organs, with highest expression in brown adipose tissue and skeletal muscle (Fig. 4C).
Diet-induced obesity (DIO) leads to lowered alternative promoter-driven expressionGene regulation is accomplished by a variety of mechanisms including differential promoter usage. Thus, we analysed to what extent the different promoters were used for expression of PGC-1α using qPCR primer sets covering specifically each starting exon (Additional file 1: Table S1). Additionally, we were interested in metabolic effects on expression of PGC-1α. Thus, we investigated expression PGC-1α in metabolically dysregulated/challenged mice that were fed a high-fat, high-sucrose diet, leading to diet-induced obesity (DIO) and a pre-diabetic state (Additional file 1: Figure S6).
Notably, for exon 1a (under the control of the canonical promoter) as well as exon 1c (under the control of the novel promoter), comparison of direct expression levels between DIO and lean mice was not showing differences (Fig. 5A). On the other hand, exon 1b and exon 1b’, originating both from the alternative promoter, were significantly lower expressed in DIO compared to lean mice (fold-changes: exon 1b 0.71, exon 1b’ 0.36 with corresponding p-values of 0.03 and 0.04, resp.).
Fig. 5
PGC-1α isoform expression in heart in lean or diet-induced obesity (DIO) mice. Housekeeper-normalized expression levels at baseline for either lean mice (black bars) or mice with diet-induced obesity (DIO, grey bars). Shown is isoform expression for PGC-1α starting exons (A), for the four group-wise testable isoforms (B) and for the four single-detectable isoforms (C). A Isoform expression by promoter usage. While expression levels for exon 1a and exon 1c are similar between both conditions, transcripts containing exon 1b and exon 1b’ are significantly lower expressed in DIO. B Expression of group-wise detectable isoforms. While isoforms with novel C-terminal end are unchanged between both diets, the other group-wise detectable isoforms show significantly lower expression in DIO. C Expression for isoforms which are single-detectable through PCR. While CT-PGC-1α-E3c is equally expressed under both conditions, the other single-detectable isoforms show significantly reduced expression in DIO. Data acquired by qPCR using cDNA using primers covering specific starting exon 1 (a, b, b’ or c) and exon 2 resp. using primers covering specific exon-exon junctions. Expression values are normalized to housekeeper NUDC. n = 4 each, bars depict mean values, error bars represent SD. Significance calculated by unpaired Student’s t test (ns p > 0.05, *p ≤ 0.05, **p ≤ 0.01, ***p ≤ 0.001)
PGC-1α expression is reduced in DIO except for novel C-terminal isoforms, CT-PGC-1α-E3c and sNT-PGC-1αNext, we investigated the influence of high-fat diet on expression levels of the different isoforms. Those isoforms which can be detected solely by covering common junctions (canonical C-terminus, novel C-terminus, shorter N-terminus, truncated exon 6b’, see also Additional file 1: Figure S7) showed significantly lowered expression under DIO with fold-changes in between 0.47 and 0.6 (Fig. 5B), p-values between 0.02 and 0.05, resp.), with exception of the novel C-terminal isoforms (p-value 0.97). Second, in those isoforms with ability to be detected uniquely by PCR (Fig. 5C), a more heterogenous pattern can be observed: PGC-1α-trE6-Ex13c as well as PGC-1α-E3c are also significantly lower expressed in DIO (fold-changes 0.36 and 0.53, p-values 0.006 and 0.02, resp.). CT-PGC-1α-E3c on the other hand is equally expressed under both conditions, and sNT-PGC-1α shows slightly but significantly higher expression in DIO compared to lean mice (fold-change 1.9, p-value 0.006).
Expression of PGC-1α is reduced 3 days but partially recovers 16 days after I/R in the infarcted areaAfter providing evidence for DIO-associated differential PGC-1α isoform expression, we aimed to analyse potential (dys-)functional regulation of the PGC-1α transcriptome in cardiac ischemia/reperfusion (I/R) injury serving as experimental model for myocardial infarction. We used a well-established protocol and compared samples at baseline as well as 3 and 16 days post I/R from the infarcted area and remote area to sham-operated controls (workflow see Fig. 1B).
Under basal conditions without intervention, no differences in expression dependent on localization within the heart (corresponding areas to the infarcted and remote myocardium) could be observed (Fig. 6A–D, black bars in upper versus bottom row). I/R injury leads to downregulation of all starting exons 3 days post intervention in the infarcted area compared to sham control (0.32- to 0.38-fold, *p < 0.05 for exons 1a, 1b’ and c and ***p < 0.001 for exon 1b). In contrast, in the remote area the expression levels between sham and I/R are equal.
Fig. 6
PGC-1α isoform expression in heart at baseline and 3- and 16 days post I/R. Expression levels at baseline (black bars) and 3 or 16 days post sham surgery (sham, white bars) or ischemia / reperfusion injury (I/R, striped bars) for different PGC-1α starting exons (A–D), for the four group-wise testable isoforms (E–H) and for the four single-detectable isoforms (I–L). Housekeeper-normalized expression values in infarct area (upper row) and remote area (bottom row). A Exon 1a, originating from the canonical promoter. B, C Exons 1b and 1b’, under control of the alternative (known) promoter. D Novel exon 1c, originating from a new promoter site. E Isoforms with canonical C-terminal ending. F Isoforms with novel C-terminal ending. G N-terminal isoforms. H Isoforms with the novel exon 6b. I PGC-1α-trE6-Ex13c. J sNT-PGC-1α. K PGC-1α-E3c. L CT-PGC-1α-E3c. I/R leads to downregulation of canonical and novel PGC-1α starting exons as well as most of the single- and group-wise-detectable PGC-1α isoforms 3 days post I/R, suggesting a general downregulation of PGC-1α in infarct area 3 days post I/R. At 16 days post I/R, a recovery can be observed. Moreover, PGC-1α-trE6-Ex13c is showing ‘overcompensative’ behaviour in infarcted and remote area. In all other isoforms, the expression in the remote area is not affected, neither at day 3 nor 16 days post infarction. Detailed description, see text. Data acquired by qPCR using cDNA using primers covering specific starting exon 1 (a, b, b’ or c) and exon 2 resp. using primers covering specific exon-exon junctions. Expression values are normalized to housekeeper NUDC. n = 4 each, bars depict mean values, error bars represent SD. Significance calculated by unpaired Student’s t test (ns p > 0.05, *p ≤ 0.05, **p ≤ 0.01, ***p ≤ 0.001)
During recovery, 16 days post I/R, almost no difference is observed between I/R and sham (Fig. 6A–D). This is due to a significant increase of expression in the infarcted area from 3 to 16 days post I/R (upper rows; fold-change exon 1a 4.73, exon 1b 5.85, exon 1b’ 12.88, exon 1c 5.56; corresponding p-values exon 1a 0.013, exon 1b 0.016, exon 1b’ 0.04, exon 1c 0.02). In contrast to that, the expression in the remote area over time stays unchanged (bottom rows).
Additionally, we were also interested if changes in expression also occur in the group-wise or single-detectable isoforms. Here, a similar pattern as for the promoter variants was observed also for most of the splice variants: When compared to sham, I/R induces a transient decline of transcripts in the infarcted area on day 3 post I/R, which was followed by recovered expression on day 16. Expression in the remote myocardium was not altered except for the C-terminal isoforms and PGC-1α-trE6-Ex13c (Fig. 6E–L; fold-changes for the infarcted area ranging from 3.08 to 8.13, p-values from 0.0001 to 0.03).
I/R in DIO leads to heterogenous pattern of PGC-1α expressionAs both DIO and I/R individually changed PGC-1α expression in cardiac tissue, we were curious if combining both hits would have an additional effect. Therefore, I/R was repeated in mice fed 10 weeks with high-fat diet, using the same protocol which was used for each modality separately before (see scheme in Fig. 1B). At baseline, the majority of all PGC-1α transcripts exhibit lower expression levels in DIO than lean mice (colour-coded Fig. 7A, Fig. 5 and Additional file 1: Figure S8). Exceptions are CT-PGC-1α-E3c (Additional file 1: Figure S8, horizontally half-filled diamond-shape) and isoforms with the novel C-Terminus (Additional file 1: Figure S8, empty square), which are equally expressed, and transcripts with exon 1b’, which are higher expressed in DIO. Three days post I/R (colour-coded Fig. 7B, and Additional file 1: Figure S8), in the infarcted area this changes as, beside low absolute expression values in both groups, all transcripts are either equally or higher expressed in DIO. This effect appears transient, since 16 days post I/R (Additional file 1: Figure S8, C) a similar pattern to baseline can be observed for most transcripts. However, transcripts starting with exon 1a (filled circle) and exon 1b’ (empty circle) show higher expression in DIO than lean mice at this time point, while isoforms with the N-terminal end (vertically half-filled square) are even lower expressed than before (see also Fig. 7). Thus, expression distribution at 3 days post I/R seems altered by combination of metabolic and ischemic hit, with incomplete recovery over time in the infarcted area.
Fig. 7
Impact of high-fat diet on promoter-specific expression. Expression levels for diet-induced obesity at baseline (Ctrl) and 3 or 16 days post ischemia / reperfusion injury (I/R) for different PGC-1α starting exons (A–D), for the four group-wise testable isoforms (E–H) and for the four single-detectable isoforms (I–L). Housekeeper-normalized expression values in area-at-risk (upper row) and remote area (bottom row). Colours of bars represent fold-change difference between high-fat (HFD) compared to standard chow (SD) diet, colour scheme likewise to heat map illustrations (i.e. dark green means higher, dark red means lesser expression in HFD compared to SD). A Exon 1a, originating from the canonical promoter. B, C Exons 1b and 1b’, under control by the alternative (known) promoter. D Novel exon 1c, originating from a new promoter site. E Isoforms with canonical C-terminal ending. F Isoforms with novel C-terminal ending. G Isoforms with N-terminal isoforms. H Isoforms with the novel exon 6b. I PGC-1α-trE6-Ex13c. J sNT-PGC-1α. K PGC-1α-E3c. L CT-PGC-1α-E3c. The recovery of expression in the infarct zone after 16 days (ratio between 3 and 16 days) under high-fat diet is impaired, leading to a continuing downregulation of exon 1a and b. For the group-wise detectable isoforms, the downregulation is dominant in the infarct zone and less in the remote area in direct comparison of expression values. Most of the isoforms recover expression values compared over time with exception of the N-terminal isoforms in infarct area. Data acquired by qPCR using primers covering specific exon-exon junctions. Expression values are normalized to housekeeper NUDC. n = 4 each, bars depict mean values, error bars represent SD. Significance calculated by unpaired Student’s t test (ns p ≤ 0.05, *p ≤ 0.05, **p ≤ 0.01, ***p ≤ 0.001)
The remote area shows also lower expression of all isoforms in DIO than lean mice at baseline (Figs. 7D, 5 and Additional file 1: Figure S8). Three days as well as 16 days post I/R in the remote area, expression in transcripts with exon 1a (Additional file 1: Figure S8, filled circle) and exon 1b’ (Additional file 1: Figure S8, horizontally half-filled circle) are significantly higher in DIO than lean mice (Fig. 7E, F; Additional file 1: Figure S8), while all other transcripts resemble baseline expression values.
留言 (0)