
記住我
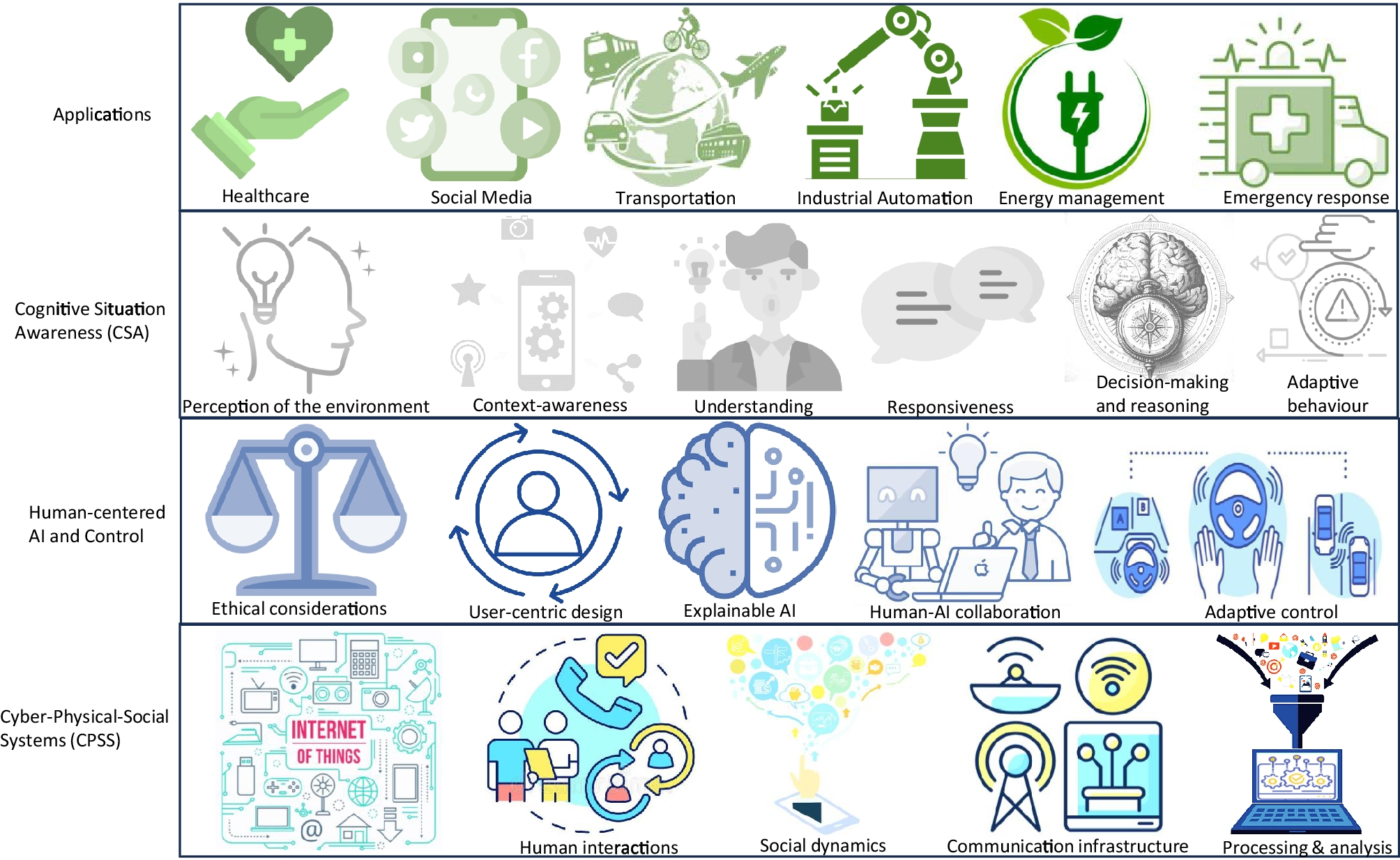



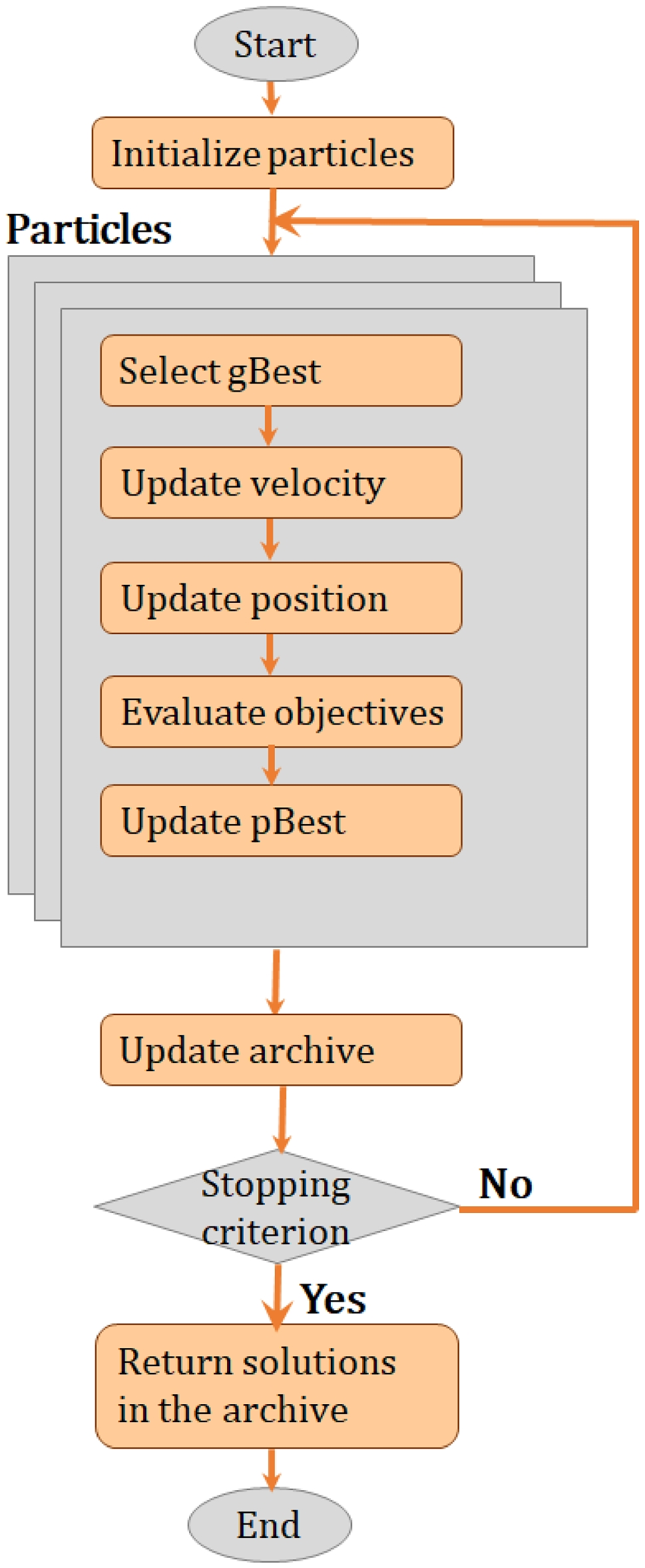
In this study, we conducted multiple sets of experiments to identify the optimal setup to conduct dysarthric intelligibility assessment and then verify the optimal setup against all dysarthric subjects in Table 2 and deliver per-speaker results in addition to results per intelligibility class.
We considered speech features presented as both MFCCs and spectrograms for the optimal setup identification since they both delivered significant results in the previous studies. While MFCCs have been widely studied in the literature, spectrograms do not appear to be thoroughly investigated in the context of intelligibility assessment, although they have outperformed other feature extraction approaches in ASR tasks [18]. We experimented with different configurations by selecting different MFCC parameters and spectrogram setups explained below.
Our evaluation method differed from those shown in Table 1 by using held-out speakers to measure how well our models generalize to unseen speakers. In particular, no speech sample from the testing speakers was among the training set in any of the experiment sets explained below. Additionally, accuracy was measured in all experiments.
Additionally, in the remaining of this paper, we refer to configurations (confs) as experiments with different MFCC feature extraction parameters, such as different number of MFCC features and frame lengths. On the other hand, setups refer to different spectrogram experiments to identify optimal utterance length and whether common UA-Speech words were included. We opted to select different terms (configurations vs setups) to indicate that the latter was not experiments with different spectrogram configurations.
Experiment Set 1: Identifying the Best MFCC-Based Feature SetIn experiment sets 1 and 2, all models were tested on speakers M01 (low intelligibility), M05 (moderate intelligibility), and M09 (high intelligibility) utterances while the rest of the utterances from the other 13 speakers were used for training. All available words from UA-Speech were utilized in training and testing, but only M5 microphone data was used. The number of audio samples per participant was highly varied concerning the available microphone data, but the M5 microphone had the highest number of collected utterances across all microphones. Table 3 summarizes the speakers used in training and evaluating the models during set 1 and 2 experiments.
Table 3 Experiment 1 and 2 train/test dysarthric speakersIn order to design the network architecture for this set of experiments, we employed Keras Tuner [22] applying Hyperband [23] to automatically identify the CNN configuration and architecture shown in Fig. 1. This was done by configuring a search space with different number of neurons in each layer, convolutional filters, batch sizes, dropout values, optimizers, etc. Then, the hyperband optimization algorithm employed an adaptive approach to allocate resources paired with early stopping, trained a large number of models with different architectures and hyperparameters defined in the search space in a few epochs, and proceeded with further training with the models that delivered the best performances. This process iterated until the best performing models were identified and reported.
Fig. 1
Experiment set 1 CNN architecture
Identifying the best MFCC configuration, we explored different MFCC frame and sliding window rates, and whether to include the MFCC delta coefficients. For each setup, we retrained the CNN with the training subjects of Table 3 and measured its performance on the testing subjects. This process was repeated ten times in each configuration while the testing accuracies were recorded and averaged. The results of this experiment are presented in Table 4. As can be seen, the best performance was achieved when the first 13 MFCCs (i.e., mel cepstrum with 12 coefficients plus the energy information) were used with relatively long frames of 256 ms sliding each 128 ms. The inclusion of MFCC first and second derivatives degraded the model performance. Likewise, results demonstrate that longer frames achieved higher performance. Although this is contrary to typical usage of MFCCs in healthy speech processing when short frames of 20–30 ms are commonly used, it was not unexpected and is consistent with our previous findings for dysarthric ASR [24].
Table 4 Experiment set 1 resultsExperiment Set 2: Identify the Best Spectrogram SetupIn the second set of experiments, mel-spectrograms were created using a decibel scale on the frequency axis to emphasize the frequency ranges relevant to human speech. Librosa mel-spectrograms [25] with default parameters were used to generate the spectrograms. The default parameters were FFT window length of 2048, 512 samples between successive frames (hop length), and window function was set to Hann.
Generally, the utterance length of the high intelligibility speakers in the dataset was shorter than 5 s, while low intelligibility speakers had a longer average length, typically exceeding 7 s. A trade-off between not using excessively longer utterances that were mostly empty while still long enough to capture low intelligibility speech was difficult to determine. Hence, we consider the optimal length of the utterance as one of the parameters to investigate during this experiment set. To do so, we conducted multiple experiments retraining the model using 5-, 7-, and 10-s audio lengths. Audio files that were longer than 2 s over the predetermined audio length were excluded from both training and evaluation to ensure consistency among the generated spectrograms. From our observations, spectrograms from longer UA-Speech utterances mostly consist of silence or background noise and did not include useful speech data.
Moreover, in our early experiments, we noticed that models trained only on uncommon UA-Speech words performed better — this seemed counterintuitive to exclude data, especially when the dysarthria acoustic data is scarce, but the difference in results was significant enough to be a consideration. However, it was unclear whether changing the spectrogram length and the inclusion/exclusion of the common words would impact the model performance. Hence, we built several models trained on all words and only the uncommon words to investigate this effect. Overall, six setups were configured and evaluated for this experimental set using audio length values of 5, 7, and 10 s, and the two different word selection schemes (uncommon words only or all words). The same three subjects from Table 3 were considered for model evaluation.
Similar to experiment 1, Keras Tuner was used to identify the best CNN architecture depicted in Fig. 2. The spectrograms’ resolution was 128 × 157 pixels for experiments with 5-s audios, 128 × 219 pixels for 7-s audio experiments, and 128 × 313 pixels for 10-s audio experiments.
Fig. 2
Experiment 2 CNN architecture
In each experiment, we retrained the model five times for 30 epochs with early stopping if the validation loss did not decrease in at least five epochs. Adam optimizer with an initial learning rate of 0.0003 and a batch size of 16 was used. Table 5 shows the mean classification accuracy of the models under each of the audio length and training word setups and the maximum classification accuracies achieved.
Table 5 Experiment set 2 resultsBased on the results obtained, the best performing setup was the 5-s spectrogram length using only the uncommon words that achieved the maximum of 81% accuracy on the three unseen speakers. Interestingly, the models trained only on the uncommon words outperformed all those trained on both the common and uncommon words. It appears that the addition of the common words may not be beneficial in an intelligibility classification setting. We assume that the common words may not contain enough discriminatory information for the model to learn intelligibility assessment. On the other hand, there may be more stark differences between speakers of different intelligibility classes when using only uncommon words, which may help the model generalizes more successfully. Given that setup #1 delivered the best results, it can be concluded that 5-s audios uttering uncommon words are the optimal setup to conduct dysarthria intelligibility classification, considering generalizability to unseen speakers, when features are presented via spectrograms.
As for the optimal length, the longer utterances appear to reduce performance, at least when using uncommon words only, which is consistent with previous findings reported in the literature [26]. The 5-s length performs the best on average and has the highest maximum accuracy. However, one additional consideration is that the shorter audio length reduces the number of utterances used in the training since some low intelligibility utterances may get excluded. Nonetheless, this can be remedied by trimming longer utterances to 5 s. However, this requires an automated audio segmentation technique in case the content of the audio files is skewed towards the beginning or end of the file.
Figure 3 shows the confusion matrix delivered by setup #1 model in terms of performance per intelligibility class. It can be noted that the misclassifications were not spread evenly among the three intelligibility classes. Particularly, the low intelligibility speaker was most frequently misclassified (34%), in which the model considered his speech samples as high intelligibility 22% of the time. Moderate intelligibility was most accurately classified (90%), followed by high intelligibility with an 80% classification rate. Similar to the low intelligibility misclassification rate, the high intelligibility subject was misclassified more often as low intelligibility (15%) than moderate (4%).
Fig. 3
Confusion matrix for spectrogram setup #1 (5-s audio length, uncommon words only) tested on speakers M01 (low), M05 (moderate), and M09 (high)
Experiment Set 3: Verification of the Optimal Setup with All UA-Speech Dysarthric SpeakersBetween experiment sets 1 and 2, the CNN trained with spectrograms of 5-s utterances with uncommon words delivered a 12.05% better average classification rate over the best MFCC configuration for M01, M05, and M09 dysarthric subjects, and, as such, was selected as the optimal setup. The next step was to confirm how this setup performs for the remaining participants, which was done by conducting two more sets of experiments.
In the first set, 5-fold cross-validation was employed where different combinations of held-out speakers were used for evaluation purposes. In each fold, utterances of different speakers were entirely held-out during training. For example, we held out F02, M06, and M08 utterances in the second fold, trained the model with the rest of the speakers’ data, and then tested the model on the speakers mentioned above. In the next fold, we selected F03, M11, and M14 for testing and the rest of the speakers for training. Each fold contained testing speakers from all three dysarthric intelligibility classes and used the optimal 5-s utterances of only uncommon words during training and evaluation with the CNN shown in Fig. 2. Additionally, the CNN in each fold was retrained five times, as explained in the “Experiment Set 1: Identifying the Best MFCC-Based Feature Set” section. It is pertinent to note that the first fold results are from Table 5. Figure 4 depicts the results of these experiments.
Fig. 4
5-fold cross-validation results
In the second set of these experiments, we conducted leave-one-speaker-out approach [27] with 16 folds to verify the performance against each individual UA-Speech speaker. This was done by holding out a speaker in each fold for testing and training the CNN with the remaining 15 speakers based on the optimal setup. The process was repeated in the next fold with another speaker selected to held-out. These experiments were important to identify if particular speakers were skewing the performance. The same setup of 30 epochs with early stopping if validation loss does not decrease was used in each fold. The results of these experiments are illustrated in Fig. 5.
Fig. 5
16-fold leave-one speaker-out classification accuracy results
留言 (0)