
記住我



The GECKO (Groningen Expert Center for Kids with Obesity) Drenthe study is a population-based birth cohort with a focus on early risk factors for overweight and obesity. Details of the GECKO Drenthe study are described elsewhere [25]. In 2006, almost three thousand pregnant women living in the Province of Drenthe, the Netherlands, were recruited. Recruitment was carried out by obstetricians, midwives and general practitioners, supported by a media campaign. Monitoring of the children started from the last trimester of the pregnancy and is still ongoing. For the current study, we used data collected on lifestyle factors between 3 and 6 years (August 2008 to April 2014) and overweight at ages 5–6 and 10–11 (August 2016 to July 2018). Children were included if they had information on at least one lifestyle factor and had data on overweight at the age of 10–11 years. Written informed consent was obtained from parents, and the study was approved by the Medical Ethics Committee of the University Medical Center Groningen in accordance to the declaration of Helsinki of 1975 as revised in 1983. The study is registered at http://www.birthcohorts.net.
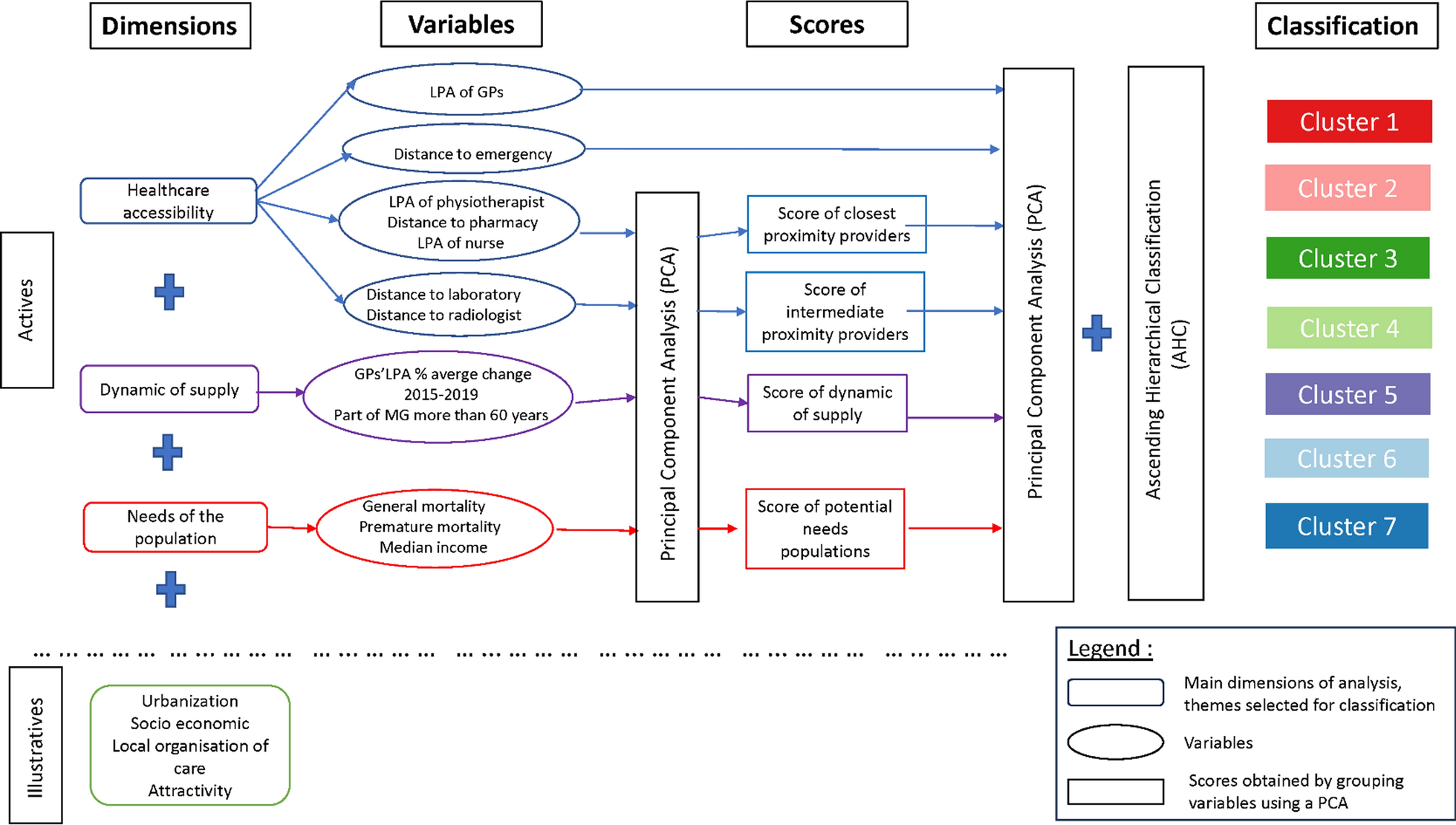
Drenthe is a province in the northern Netherlands with 12 municipalities. On January 1st 2020, the population of Drenthe was estimated at 493,682 inhabitants [26]. Drenthe is characterised by the many rural areas, and has a population density of 188 inhabitants per km2. Figure 1 gives an overview of the population density in the different areas of Drenthe. Within the Netherlands, Drenthe is the province with the highest prevalence of overweight (52.9% in 2016) [27].
Fig. 1
Population density in the province of Drenthe, The Netherlands. The darker the colour, the more inhabitants in that area. The four largest municipalities by inhabitants are labelled, from largest to smallest: Emmen, Assen, Hoogeveen, Coevorden
Lifestyle factorsWe focused on the following six lifestyle factors: diet, screen time, outdoor play, sleep, physical activity and sedentary time.
DietAt the age of 3–4 years, the parents of the children filled in a validated Food Frequency Questionnaire (FFQ) [28]. The FFQ includes questions about the intake of 71 food products. The parents reported if, and how often, their child on average consumed a product every week for the last month. In addition, the amount of intake and the composition was asked. Data for children for whom the FFQ was not filled in completely or the dietary intake was unreliable were excluded. The reliability of reported dietary intake was assessed using the Goldberg cutoff method and was based on the ratio of reported energy intake and basal metabolic rate [29]. This was calculated with the Schofield equation. [30]. Detailed information about the data processing can be found elsewhere [31]. To express the quality of children’s dietary pattern, diet scores were calculated based on the Lifelines Diet Score (LLDS) [32]. The LLDS ranks the relative intake of nine food groups with proven positive health effects and three food groups with proven negative health effects. For the positive food groups, that is, vegetables, fruit, whole-grain products, legumes and nuts, fish, oils and soft margarines, unsweetened dairy, coffee, and tea, higher scores are awarded to higher quintiles of consumption. For the negative food groups, that is red and processed meat, butter and hard margarines, and sugar-sweetened beverages, higher scores are awarded to lower quintiles of consumption. The young children in the current study did not drink coffee, therefore this item was not included. The scores per food group were accumulated, resulting in a diet score ranging from 0 to 44 points, with higher scores corresponding to better diet quality [31, 32].
Screen time and outdoor playData on screen time and outdoor play were collected using questionnaires when the children were about 3–4 years old. Parents filled in two questions about how many days per week and for how long their child watched television, played computer games or played outside. The time that children watched television and played computer games was added together into total screen time, calculated as the average minutes per day. Accordingly, the time that children played outside was calculated as the average minutes per day of outdoor play. More information about the answer options and data processing can be found elsewhere [13].
SleepData on sleep were collected around the age of 5 years. Parents reported what time children usually went to bed and what time they got up. Sleep time was calculated as the average minutes per night.
Moderate-to-vigorous physical activity and sedentary timePA and ST were measured objectively with tri-axial accelerometers (ActiGraph GT3X, ActiGraph, Pensacola, FL) when the children were approximately 4–6 years old. The accelerometer was placed on the child’s right hip with an elastic belt and worn during all waking hours for four consecutive days, except while bathing or swimming. Data was collected using a frequency of 30 Hz and analysed with 15 s epoch recordings. Non-wearing time was defined as periods of at least 90 min with zero counts [33]. A valid measurement was defined as having at least three days with a weartime of more than 600 min per day. More information about the data processing can be found elsewhere [34]. Minutes per day spent in MVPA (≥ 3908 cpm) or ST (≤ 819 cpm) were assessed using cut-off points developed by Butte and colleagues [35].
OverweightHeight and weight at the age of 5–6 and 10–11 years were measured by trained Preventive Child Healthcare nurses according to standardized protocols. Weight was measured in light clothing using an electronic scale with digital reading, and recorded to the nearest 0.1 kg. Height was assessed using a stadiometer and recorded to the nearest 0.1 cm. Accordingly, BMI was calculated as weight/height2. BMI was transformed into age- and sex-specific standardized z-scores, using Dutch growth analyser software (Growth Analyzer 3.5; Dutch Growth Research Foundation, Rotterdam, The Netherlands) with population data from 1997 as the ref. [36]. Children were classified as affected by underweight, normal weight, overweight, or obesity using the age- and sex-specific cut-offs for children based on Cole et al. [37].
Confounding variablesFor SES, a recently developed indicator for standardized household income, the Equivalized Household Income Indicator (EHII), was used. This cohort-specific household income indicator is specifically developed for European birth cohort studies [38]. The household disposable income is potentially one of the most important single indicators of SES, as it is a direct measure of material resources [38]. External data from the pan-European Union Statistics on Income and Living Conditions (EUSILC) surveys and data from the GECKO cohort were used. Within the GECKO cohort, the following predictors for the EHII were available: parental age, education level, occupational status and country of birth, cohabitation status (living with/without a partner), dwelling type and family size. A prediction model was constructed using EUSILC data of the Netherlands from 2011 and validated with data from 2015. The prediction model, resulting in regression coefficients needed to derive the EHII, had a good overall performance (R2 = 0.455). The currency of the EHII was EURO. As income is not a linear variable, the EHII was scaled (mean = 0, standard deviation = 1). The predictors used to estimate the EHII and smoking during pregnancy were self-reported by the parents when the child was born. For descriptive purposes, maternal education level was divided in the following three groups: (1) no education—lower general secondary education, (2) senior secondary vocational education—higher general secondary education/pre-university education, and (3) higher vocational education—university.
Geographical informationAddresses of the participants around the age of 5–6 were used. The addresses included are postcodes (four digits and two letters), house numbers, and house number sub-specification (e.g., a, b, or − 1, − 2) where relevant. We combined this data with the Dutch Building Registry (Basisadministratie Gebouwen, BAG) [39]. From the BAG, we obtained all residential properties in Drenthe, their xy-coordinates (projected in Amersfoort EPSG:28992, unit of distance: metres), and addresses. We found a one-to-one match with 2815 out of 2906 observations with address information (96.9%).
For completeness, we approximately matched the remainder of the dataset based on their six digit postcodes. To do so, we calculated the centroid (median) xy-coordinate for all residential properties in each respective six-digit postcode based on the BAG dataset, and assigned this to the observations.
Statistical analysisAll statistical analyses were performed using R version 4.0 and IBM SPSS Statistics version 23. The R-packages used for the analyses were tidyverse, tmap, sf, kableExtra, spatialreg, GWmodel, mice, osmdata, raster, and sp. Differences in lifestyle, overweight and maternal education level between tertiles of the EHII were assessed using One-Way ANOVA tests and χ2-tests.
Multiple imputationThe data on lifestyle factors and overweight were collected at different time points, which has resulted in missing data. Most data were missing for practical reasons, mainly due to logistical problems with the distribution of the questionnaires. Therefore, we assumed that the data was missing at random. For the multiple imputation the mice package was used [40]. The minimum required number of imputed datasets was based on the missing data rate and calculated as the number of cases with missing data divided by the total number of cases. A separate univariate imputation model was specified for each variable. Bayesian linear regression (norm) and predictive mean matching (pmm) were used for normally and non-normally distributed continuous data, respectively. For categorical variables, proportional odds models (polr) were used for ordered data and polytomous logistic regression (polyreg) for unordered data. Logistic regression (logreg) was used for binomial data. We created a predictor matrix to specify which variables should be used as predictors in which imputation model. Variables were ordered according to the amount of missing data. Convergence was monitored by visual diagnosis and by comparing the observed and imputed values using independent t-tests.
Principal component analysisTo identify different lifestyle patterns, principal component analysis (PCA) was performed using IBM SPSS Statistics version 23. The lifestyle factors were scaled before the analysis. Within the PCA, oblique rotation was used because the lifestyle factors are likely to correlate. The number of components was determined based on visual inspection of the scree plot and an eigenvalue > 1. The scores for each lifestyle pattern were calculated by summing the six lifestyle factors weighted by their factor loadings. PCA was performed in each imputed dataset separately. Subsequently, factor loadings were pooled using Generalized Procrustes Analysis [41]. The overall explained variance was estimated by taking the mean of the percentages of explained variance in each imputed dataset.
Spatial clusteringTo get a visual impression of the spatial clustering of children’s lifestyle patterns and overweight without compromising the anonymity of the participants, geographically weighted summary statistics were calculated using GWmodel and plotted [42, 43]. The geographically weighted statistics were calculated for a grid imposed on the province of Drenthe (cell size 1000 m with an adaptive bandwidth of 20 neighbours). The distribution of the geographically weighted mean and the local variation (geographically weighted standard deviation) in the province of Drenthe are shown. To further explore the spatial clustering of the lifestyle patterns and overweight the Global Moran’s I statistic was calculated using spdep [44, 45]. The Global Moran’s I returns the probability of finding the observed spatial distribution of values (e.g., zBMI) under the assumption of a random spatial distribution. The Global Moran’s I was calculated for both the lifestyle patterns and zBMI at 10–11 years. The level set for significance was p < 0.05.
Regression models and spatial analysisLinear regression models were performed to examine the association between the lifestyle patterns and overweight. Outcomes for overweight included overweight or obesity at 10–11 years (yes/no) and zBMI at 10–11 years. In regression model 1 we adjusted for sex, age, smoking during pregnancy, accelerometer weartime, energy intake and zBMI at 5–6 years. In model 2, we studied the influence of SES by adding standardized EHII as a confounder. If SES was significant, an interaction term for SES and lifestyle was added. Subsequently, spatial analyses were performed for the continuous outcome zBMI at 10–11 years.
The spatial analyses were initiated by adding spatial terms to model 2 following a conventional spatial econometric framework. A detailed description of the spatial analysis can be found in Additional file 1. In short, we followed convention by first estimating a general nesting spatial model (for a full description of the eight possible models see Halleck-Vega and Elhorst [24]. This model includes spatial autocorrelation of the dependent variable (neighbours’ zBMI at 10–11 years affect zBMI at 10–11 years), spatial spillovers of the independent variables (neighbours’ lifestyles affect zBMI at 10–11 years), and spatial autocorrelation of the error term (corrects for errors that are not independent and identically distributed). We subsequently excluded insignificant spatial terms and fit a spatial autoregressive combined model, a spatial durbin error model and spatial error model. For this study, the spatial weights matrix was constructed using the 10 nearest neighbours (where neighbours refer to participants) to ensure an equal number of neighbours for each individual (more detail on the structure of the spatial weights matrix can be found in Additional file 1). All regression models were performed using spatialreg in each imputed dataset separately, and combined using Rubin’s rules [44,45,46]. As sensitivity analyses, we also performed the analyses with one pattern at a time and performed the analyses on the subset of children with complete information. Spatial regressions were performed for the dependent variable zBMI at 10–11 years. At present there is no equivalent maximum likelihood method for imputed data for these regressions with a binary outcome variable. Therefore, it was not possible to perform the spatial analyses for the dichotomous outcome overweight or obesity.
留言 (0)