
記住我








Over the last few decades, the exploration of genetic variance components and their intricate mechanistic roles in the genetic architecture of complex traits has expanded the view of Mendel’s theory to a holistic understanding of interaction network models, integrating multiple genetic factors and environmental exposures that contribute to phenotypic variation [7, 8]. Of particular interest was the dissection of the genetics underlying complex diseases, culminating in the elaboration of concepts and models [9,10,11,12].
The standard models of genetic architecture, rooted in the discoveries of 1900 after the rediscovery and integration of the empirical observations in Mendel’s work, follow Fisher’s model, which resolved the debate between two conflicting schools [7, 13], namely Mendelians and biometricians, postulated in Fisher’s 1918 paper ‘The correlations between relatives under suppositions of Mendelian Inheritance’. Fisher’s classical theory, known as the infinitesimal model, postulates that phenotypic variation in a quantitative trait can be partitioned into the contribution of genetic variation influenced by an infinite number of loci with small effects on total variance, as well as into the contribution of environmental variance [14]. Prior to the advent of molecular biology, Fisher’s infinitesimal model was predominantly applied to quantitative traits without the possibility of recognizing the distinct effects of genes [15]. The transition to statistical genetic tools, known as quantitative trait loci (QTL) mapping, successfully facilitated the localization of genetic signals in the genome significantly associated with variation for a quantitative trait or complex disease, followed by the identification of disease-causing variants [16, 17]. The introduction of genome-wide association studies (GWASs), a complementary method to QLT mapping, was a major stride in expanding our insights into the genetic architecture and completely changed our understanding of the polygenic nature of common and rare diseases [18, 19]. Genetic variants evaluated in GWASs are typically common genetic variants with minor allele frequencies (MAFs ≥ 5%) [20, 21]. Before the advent of GWASs, starting around 2007, the prevailing hypothesis for understanding the genetic basis of complex diseases was the common disease-common variants (CDCV) hypothesis [22], predicting that the genetic susceptibility underpinning most common traits or diseases is due to disease-causing variants with small to modest effects found at relatively high frequencies in general populations, in association with environmental factors [23]. By contrast, the alternative hypothesis, known as the common disease-rare variant (CDRV) hypothesis, posits that the summated impact of multiple rare variants (MAF < 1%), each with substantial effects, contributes to the development of diseases, as opposed to the influence of common variations [24, 25].
In this sense, the polygenic architecture of complex diseases has been demonstrated by GWASs, and to a certain degree, these two fundamental theories, the CDVC and CDVR, have been proven to be correct and do not preclude each other [26, 27]. In recent years, the emergence of next-generation technologies has extended the exploration of low-frequency and rare alleles, identifying novel genes containing rare coding variants usually observed in only one or a few individuals, which can have much larger effect sizes, translating into substantive biological changes in the clinical manifestation of diseases. Results in large-cohort whole-genome sequencing studies show that different trait-associated variants located in coding and noncoding genomic regions, including untranslated regions such as promoters, enhancers, and noncoding RNA, with cis- and trans-acting effects, have the potential to offer explanations for the missing heritability and uncover additional mechanisms underlying neurodegenerative pathogenesis.
Furthermore, biological-specific regulatory networks have become powerful computational or experimental approaches for analyzing integrative architectures, utilizing, for example, principles of guilt-by-association to integrate data from different levels of molecular interactions, such as genomic, transcriptomic, proteomic, or epigenetic networks [28, 29]. Such models, briefly discussed in the last section of this review, help to increase the ability to predict and map context-relevant molecular interactions for studying the defining features of biological and functional pathways that contribute to endophenotype biology or shared mechanisms across neurodegenerative diseases.
What is the definition of genetic architecture?Considering the aforementioned notions, typically, a comprehensive definition of the term “genetic architecture” refers to the genetic combinations of functional variants, the frequency of these variants within populations, the magnitude of effects that impact a phenotype residing in their interactions with each other and with the environmental factor, and the extent of genetic variance accounting for additive, dominant, and recessive effects, as well as in various molecular mechanistic interactions [9, 18]. In the same vein, but using an oversimplified description orbiting around the heritability of genetic variants, the term “genetic architecture” in population-based studies can be defined as the architectonic characteristics of genetic variation attributed to broad-sense heritability [30].
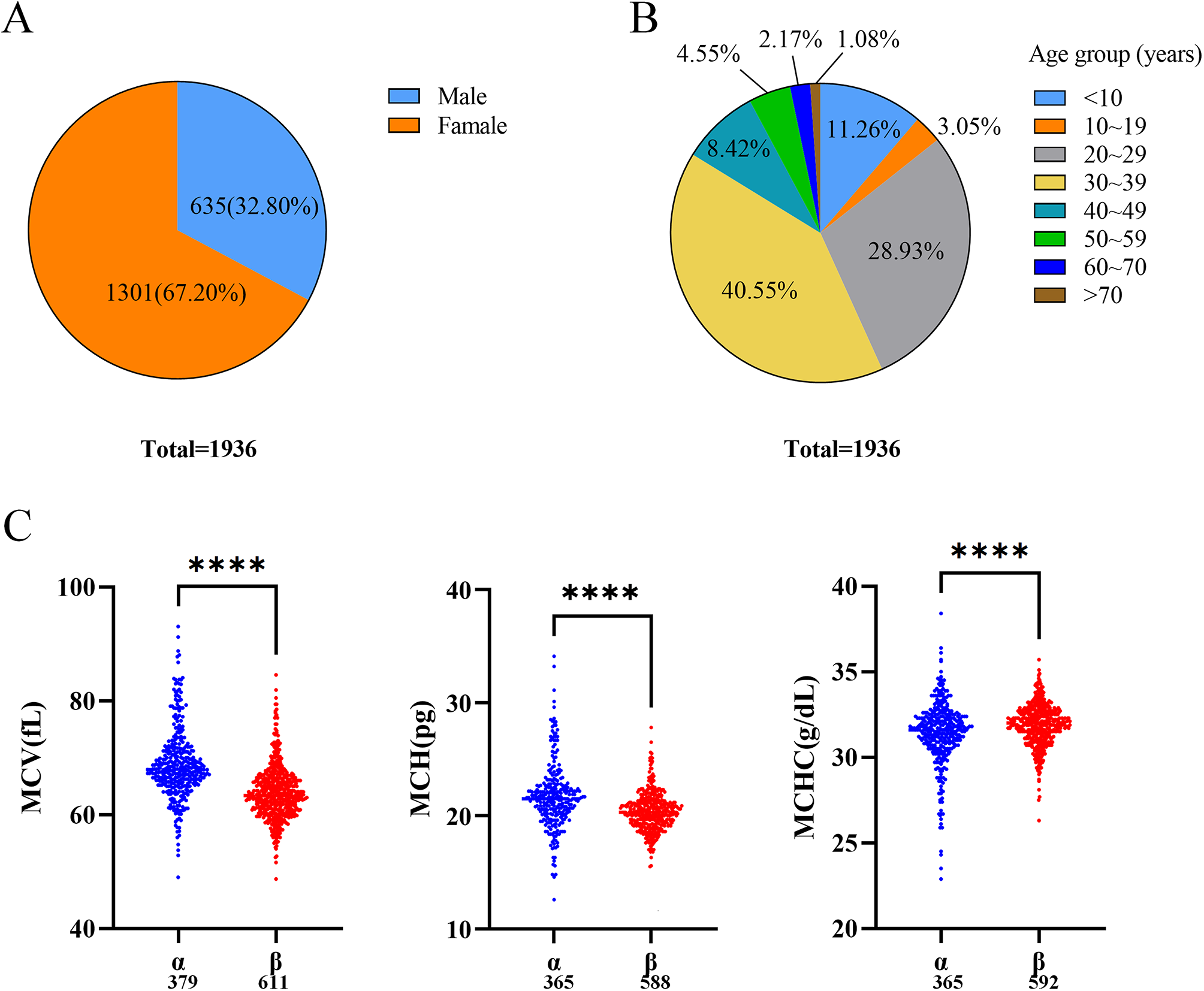
Additionally, a distinct definition of the genetic architecture of human complex traits or diseases, beyond the role of environment and other stochastic factors, derives from the patterns of inheritance grounded in the type of genetic contributors influencing disease liability of complex conditions [11]. In this sense, a way to conceptualize the complexity of a continuum of genetic architectures is by integrating them into a liability-threshold model. The model, initially presented by Carter in relation to congenital pyloric stenosis and later mathematically applied to certain diseases by Falconer [31] incorporates in its theoretical concept the additive effects of risk factors. These factors, whether singular or in combination, involve genetic variants capable of exceeding a disease burden or liability threshold, leading to disease status in monogenic, oligogenic, or polygenic architectures [32, 33]. The distribution of underlying liability in the liability-threshold model may arise from the cumulative impact of genetic variants with varying effect sizes, alongside other contributing factors in neurodegenerative diseases (Fig. 1).
Fig. 1
An illustration of the liability-threshold model and the karyotypic distribution of variants with varying effect sizes. We can conceptualize four distinct liability-threshold models: (A) characterized by the cumulative effects of a high-effect-size genetic variant (red), moderate-effect-size variants (blue, purple, and cyan), and influenced by unique sets of small-effect genetic variants (green); (B) driven by the cumulative effects of moderate-effect-size variants and unique sets of small-effect genetic variants; (C) influenced by moderate-effect-size variants, unique sets of small-effect genetic variants and environmental factors (orange); or (D) driven by the high-effect-size genetic variant alone. Each model can push the disease risk beyond the diagnostic threshold. A didactic illustration of the distribution of specific genetic variants with varying effect sizes associated with neurodegenerative diseases, namely Alzheimer’s and Parkinson’s disease, across the chromosomes, is shown (E)
Following this theoretical concept, as we will discuss, the genetic models of neurodegeneration integrate both genetic and environmental contributions alongside other factors underlying pathways of cell biology to explain the disease onset, where depending on the effect size of gene variants, coupled or not with the degree of environmental exposure, the age of onset following a gene-time-environment model could be investigated [33, 34].
We will further discuss genetic architecture as a continuum of complexities underpinning an intricate spectrum of inheritance, ranging from monogenic, where single gene variants greatly impact the heritability of diseases, towards oligogenic as an intermediate construct, or polygenic architecture where a large number of variants account for a substantial proportion of heritability.
Missing heritability in neurodegenerative diseasesAs depicted previously, akin to various complex diseases, genetic contributors to complex forms of neurodegenerative diseases could be positioned along a continuum spectrum that includes, at its ends, the extremely rare highly penetrant mutations and common alleles with small effects, respectively. However, as we elaborate later, this representation lacks universal applicability; thus, it constitutes an oversimplification in certain forms of neurodegenerative diseases where a clear distinction between familial and sporadic forms is absent, and intertwined genetic architectures impacted by mutations in identical genes could be observed. In the past decade, several methods have been employed to estimate heritability for common neurodegenerative diseases. These methods can be broadly categorized into family-based designs, such as twin and family studies that use samples of closely related individuals, and genomic approaches applied to both unrelated and related individuals. The latter includes statistical methods applied to molecular genetic data, such as GWAS-based designs in apparently unrelated individuals and, more recently, whole-genome sequencing (WGS) techniques.
Initial family linkage investigations of various forms of neurodegenerative diseases led to the discovery of penetrant rare genetic variants that drive the progression of monogenic disorders, following Mendelian patterns of inheritance and fully explaining the clinical phenotype. An exploration of the discovered genes and their individual functional implications falls outside the scope of this review.
While roughly 10% of all neurodegenerative disease patients have been discovered in familial cases in which the diseases are inherited in an autosomal-dominant pattern, showing a distribution over generations, the majority of cases are commonly identified apparently in sporadic non-familial forms following non-Mendelian patterns of inheritance, underlined by poorly understood etiology and characterized by a complex genetic architecture. The genetic contributors to sporadic late-onset forms of neurodegenerative disease are typically common variants that individually exert small effects, which have been mostly identified using GWASs. Moreover, a multitude of common neurodegenerative diseases generally present with sporadic presentation and familial forms. It should be mentioned that other familial forms of monogenic diseases could be inherited in Mendelian patterns, as well as non-familial cases of monogenic diseases for which the underlying genetic causes have not yet been identified.
One essential conclusion resulting from GWASs is that they have finite explanatory power for the detected common genetic signals, owing to the polygenic distribution of the proportion of phenotypic variance that can be explained by genetic factors (heritability) throughout the genome-manifesting into thousands or even hundreds of thousands of variants of small effect per trait or disease [19, 35,36,37,38]. This phenomenon leads to what is known as missing heritability which reflects the discrepancy between observed heritability and what can be explained by current genetic data. Broad-sense heritability refers to the fraction of phenotypic variance comprising all components of genetic variance, including the additive genetic effects of variants that reflect the fraction of phenotypic variance known as narrow-sense heritability, along with their interactions and environmental components. In this context, genome-wide association studies have been performed to search for common variant SNP-heritability contributing to neurodegenerative diseases.
Apart from the common risk variants more frequently encountered in sporadic forms of diseases, GWASs have successfully identified genetic supplementary risk signals for a few widely replicated rare variants. So that, besides the widely reviewed and new genes containing rare variants with high-risk effects, the list of neurodegeneration-related variants has steadily expanded, including hundreds of loci associated with common variants of moderate to low-risk effects [39, 40]. Notably, the investigation of the genetic landscape of neurodegenerative diseases by GWASs has demonstrated that rare variants in genes commonly present in patients with familial forms of diseases may also confer a risk for late-onset, sporadic forms of AD, PD, and ALS, exerting a moderate risk effect and demonstrating allelic heterogeneity [41, 42]. Remarkably, it has been found that multiple loci with rare high-penetrance alleles also present low-penetrance risk alleles [43], but the mutual presence of these loci, commonly referred to as pleomorphic risk loci [44], contributing to the disease risk should not be generalized. These rare disease-associated variants in the pleomorphic risk loci add an extra layer of complexity, suggesting multiple ways of action of these genes on disease susceptibility. Additionally, this picture is further complicated by the existence of heterogeneity in clinical expression among patients with identical high penetrance risk alleles. Therefore, these findings suggest a nuanced demarcation between familial and non-familial neurodegenerative diseases that could be addressed by analyzing all factors underlying genetic architectures.
Overall, the GWAS work predicted that as the sample size grows, the missing heritability gap will persistently diminish through the incorporation of novel common variants characterized by a linearly decreasing tendency, wherein each marginal effect is notably linked to a specific variant influencing the genetic predisposition to common disease [18, 45]. However, while this prediction holds in many complex diseases, in others, it is subject to diverse influences, including the peculiarities of genetic architecture, poor diagnostic accuracy, and age-dependent heritability. For example, by systematically analyzing Alzheimer’s disease genome-wide association studies, it has been observed that the exponential increase in sample size provided a slight gain in the number of new GWAS significant loci and a remarkable drop in heritability estimation [46]. By contrast, a similar metanalysis study incorporating data sets for PD has observed an increase in heritability estimation and the number of novel GWAS loci [47], with one reasonable explanation for the disparity in findings being the poorer diagnostic accuracy in AD GWAS studies due to cases with family-history-based diagnosis (proxy). Of note, subsequent work has shown that the majority of the heritability of complex diseases can be explained by the additive effect of common variants, while the large effects of rare variants, scarcely found in individuals with such diseases, cannot fully account for the still missing component of broad heritability [48]. In support of these findings, the polygenic architecture of most complex traits theoretically excludes dominance variance, as it has recently been demonstrated that common SNPs and rare variants contribute little to the dominance variance for human common complex traits, indicating that dominance variation explains only a small fraction of the missing heritability [49, 50]. Other potential explanations for missing heritability include gene-gene interactions, epigenetic variation, environmental factors, and demographic differences due to population specificity.
Contribution of rare and structural variantsAs alluded to above, genomic structural variations may elucidate a portion of the otherwise inexplicable heritability. Structural variations (SVs) are large genomic alterations (> 50 bp) classified as deletions, duplications, insertions, inversions, translocations, and other more complex classes; SVs with a size of less than 50 bp are referred to as small insertions/deletions (indels). Noncoding expression-altering structural variations exert a more pronounced influence on gene expression compared to SNVs and small indels [51]. Other common classes of structural variation include copy-number variants (CNVs), mainly represented by deletions and duplications of DNA larger than 1 kb, which occur in more than 1% of the population (rare < 1% or common > 5%), and mobile-element insertions (MEIs). The rare variants in human disease exhibit a restrictive populational distribution compared to the shared distribution of common variants across different populations, strongly influenced by recent demographic history. Moreover, they also show a more private distribution for the rare variants with stronger deleterious effects [52]. Compared to single nucleotide variants (SNVs), structural variants are estimated to contribute more to heritable differences between individuals through total nucleotide content variation and represent an important driving force of genome evolution, contributing to germline or somatic diseases [53].
The development of next-generation technologies facilitates researchers to investigate medium-to-rare penetrant variations in various novel genes associated with disease risk. Recent advances in whole-exome sequencing (WES) and whole-genome sequencing (WGS) enable the exploration of rare single-nucleotide variants in coding and non-coding elements of the genome. For example, in a family-based study conducted through WGS of 2,247 subjects from 605 multiplex AD families and a case-control cohort, emerging consistent rare variant signals from 13 novel AD candidate loci have been associated with Alzheimer’s disease [54]. It is noteworthy that the significant rare-variant signals correspond to loci previously associated with common-variant GWAS and the most significant variants associated with AD risk are in non-coding regions of the genome. Moreover, population-specific analyses using two independent WGS family datasets have identified a consistent association with two novel rare variants in DLG2 and DTNB loci [55]. Other rare damaging variants contributing to AD risk have been reported in an exome sequencing study in ATP8B4 and ABCA1 genes, which encode phospholipid transporters predominantly expressed in microglia and neurons, respectively, together with rare recurrent variations in TREM2, ABCA7, ATP8B4, and RIN3 genes [56].
In the case of PD, GBA1 and LRRK2 genes with exome-wide significance have been identified as harboring rare variants associated with PD in individuals with European ancestry and have nominated several potential novel risk variants in previously unidentified genes [57]. To date, several studies using NGS approaches have investigated patients with FTD, uncovering rare variants within known genes, and identifying novel rare variants within potential candidate genes. For instance, a rare variant within the SNCA gene was revealed in a patient diagnosed with bvFTD [58]. Additionally, a hitherto unreported rare variant in the VCP gene was observed in individuals clinically diagnosed with frontotemporal dementia [59]. Furthermore, it is noteworthy that heretofore uncharacterized variants in the CSF1R and AARS2 genes, implicated in innate immunity, inflammatory processes, and mitochondrial function, warrant consideration as novel genetic candidates contributing to the diagnostic landscape of FTD [60]. In the context of ALS, relatively few studies have undertaken whole-genome sequencing analyses to characterize the mutational landscape. These studies have identified NEK1, TBK1, and OPTN genes as harboring the most notable accumulation of novel pathogenic variants within the ALS-associated genomic repertoire [61, 62]. Similarly, a limited number of next-generation sequencing investigations have been performed on cohorts of individuals diagnosed with dementia with Lewy bodies. Two studies detected rare variants within the CHMP2B, PRKN, and VPS13C genes [63, 64], while another large exome analysis identified rare variants in APP, CHCHD2, DCTN1, MAPT, NOTCH3, SQSTM1, TBK1, and TIA1 [65] suggesting that the reduced penetrance of these associated variants may contribute to the absence of familial history in a majority of cases of dementia with Lewy bodies and pointing to the potential significance of specific novel rare variations in the genetic diagnosis of dementia with Lewy bodies.
Besides rare single nucleotide variants, rare CNVs have been demonstrated to be implicated in modulating biological processes underlying AD pathogenesis and progression. In initial studies conducted by genome-wide screen for CNVs through array CGH or SNP arrays, rare CNVs were associated with neurodegenerative diseases, including the CNVs in NIPA1 and DDP6 genes for ALS pathogenesis [66], duplications of the APP locus mapped at the chromosome 21 causing sporadic AD, partial deletion of intron 1 of the BACE2 gene, and duplications or triplications of the SNCA gene in PD [67].
In recent years, CGH and microarray studies have been complemented by WGS-based CNV detection methods, which offer much higher resolution. In a comprehensive genomic CNV study of late-onset Alzheimer’s disease, the investigation of the duplication region housing the APP gene has revealed the majority of conserved AD-specific CNVs in the studied cohorts and demonstrated the higher resolution of WGS-based CNV detection for detecting smaller, rare CNVs [68]. CNVs, such as genomic duplications involving the SNCA locus on chromosome 4q21-22, have been previously linked to familial PD, but their identification in sporadic PD has been reported much less frequently and is considered rare [69]. Nevertheless, Oh et al. recently conducted a high-resolution WGS study for patients with sporadic PD, identifying PCDH8 and SNPH as the rare missense mutation and the rare pathogenic SNVs, respectively, exhibiting the most significant association with PD, and clustered small genomic deletions located in the GPR27 region [70]. In a recent study investigating the largest genome-wide analysis of rare variants in Parkinson’s disease, long-read sequencing enables the identification of complex PRKN structural variations, commonly missed by MLPA and conventional short-read sequencing methods [71]. In the case of ALS, the analysis of structural variation in known genes, using 6,580 whole genome sequences, identified two ALS-associated structural variants—namely, an inversion in the VCP gene and an insertion in the ERBB4 gene—in apparently sporadic ALS, substantiating the idea that familial and sporadic ALS do not represent mutually exclusive categories but rather manifest along a spectrum [72]. In contrast to AD and PD, early studies of rare CNVs show no essential role in ALS. Furthermore, various studies aiming to discover other short tandem repeat alleles in amyotrophic lateral sclerosis beyond C9orf72 (GGG GCC repeat expansion) [73] have uncovered the contribution of repeat expansion in NIPA1, ATXN1, and ATXN2 to higher susceptibility to ALS [74, 75]. In the case of FTD, a large cohort of familial FTD revealed a novel homozygous OPTN variant and three novel GRN variants [76], reporting the contribution of rare single nucleotide and copy number variant
留言 (0)