Data source
This cross-sectional study queried the Healthcare Cost and Utilization Project’s National Inpatient Sample [11]. The Healthcare Cost and Utilization Project is the United States health service data platform that is supported by the Agency for Healthcare Research and Quality, one of the twelve federal agencies within the United States Department of Health and Human Service.
The National Inpatient Sample approximates a stratified sample of 20% of discharges in each center from all the participating hospitals across 48 states and the District of Columbia. Every year, the dataset captures more than 7 million inpatient admissions. In 2020, a total of 4580 hospitals participated in the program. In each encounter, the program captures a maximum of 40 diagnoses and 25 procedures during the index hospitalization. When weighted for national survey estimates, it covers more than 97% of the U.S. population. The University of Southern California Institutional Review Board exempted this study due to the use of publicly available, deidentified data.
Study eligibility
The study population included patients who had a hospital delivery from 2017 to 2020. Identification of hospital delivery was based on the World Health Organization’s International Classification of Disease, 10th revision (ICD-10) Clinical Modification and Procedural Coding Schema codes and Disease-Related Group codes that followed prior investigations (Table S1) [12, 13]. Patient age was restricted to 15–54 years as per prior studies [13, 14]. The starting point of 2017 was chosen due to the introduction of the ICD-10 Clinical Modification code for GC.
Exposure
The eligible cases were grouped based on the diagnosis of GC, identified according to the ICD-10 Clinical Modification code (Table S1). Specifically, patients who had the ICD-10 code for GC were classified as the GC group, and those who did not have the code were classified as the non-GC group.
Outcome measures
Obstetric characteristics including pregnancy complications and delivery outcomes were evaluated as the main outcomes in this study. The ICD-10 Clinical Modification and Procedural Classification System codes were used to identify the measured outcomes that followed prior coding schemas (Table S1). [12, 13, 15]
Pregnancy factors evaluated included maternal factors (gestational diabetes, gestational hypertension, pre-eclampsia, excess weight gain during pregnancy), fetal factors (multifetal gestations including triplet pregnancy, intrauterine growth restriction, large for gestational age, fetal anomaly, fetal malpresentation, and intrauterine fetal demise), placental factors (placental abruption, placenta previa, low-lying placenta, placenta accreta spectrum, placental malformation, and vasa previa), membranous/fluid factors (premature rupture of membrane [preterm and term], chorioamnionitis, oligohydramnios, and polyhydramnios), umbilical cord factor (umbilical cord prolapse), and utero-cervical factors (uterine rupture and cervical insufficiency).
Delivery outcomes evaluated included gestational age at delivery, cesarean delivery, operative delivery, postpartum hemorrhage, blood product transfusion, and severe maternal morbidity (SMM). These measured indicators followed the Center for Disease Control and Prevention definition [16]: acute myocardial infarction, acute renal failure, adult respiratory distress syndrome, air and thrombotic embolism, amniotic fluid embolism, aneurysm, cardiac arrest/ventricular fibrillation, cardiac rhythm conversion, disseminated intravascular coagulation, eclampsia, heart failure/arrest during surgery or procedure, hysterectomy, puerperal cerebrovascular disorders, pulmonary edema/acute heart failure, severe anesthesia complications, sepsis, shock, sickle cell disease with crisis, temporary tracheostomy, and ventilation.
Study variables
Baseline non-pregnancy demographics evaluated included patient age (< 25, 25–29, 30–34, 35–39, and ≥ 40 years), year (2017, 2018, 2019, and 2020), race and ethnicity (Asian, Black, Hispanic, Native American, Other, and White) determined by the program, primary payer (Medicaid, private insurance including health maintenance organization, self-pay, and other), census-level median household income (every quarter), patient location (large central metropolitan, large fringe metropolitan, medium metropolitan, small metropolitan, micropolitan, and not metropolitan or micropolitan counties), and housing status. Race and ethnicity were included in a view of relevance to pregnancy characteristics and outcomes.
Hospital parameters included regions of the United States (Northeast, Midwest, South, and West), facility relative bed capacity (small, mid, and large), and facility location and teaching status (rural, urban non-teaching, and teaching). These hospital parameters were determined by the program.
Medical comorbidities included obesity, pregestational hypertension, pregestational diabetes mellitus, and asthma. Gynecological factors included uterine factors (prior uterine scar, uterine myoma, uterine adenomyosis, uterine anomaly), endometriosis, cervical carcinoma in situ, and polycystic ovary syndrome. Substance factors included tobacco use, alcohol use, and illicit drug use. Mental health conditions included anxiety, depressive, bipolar, and schizophrenia disorders. Infectious disease factors included gonorrhea, syphilis, hepatitis virus, and anogenital herpes. Past pregnancy factors included grand multiparity and pregnancy loss.
Statistical analysis
Prevalence rates of GC were aggregated in each year, and the temporal trend was assessed with the Cochran-Armitage test. Independent baseline demographics associated with GC compared to non-GC were assessed with a multivariable binary logistic regression model. Conditional backward selection was fitted due to the assumption of the rarity of GCs, to avoid overfitting [17]. Initial covariate selection was set as the P < 0.05 level in the univariable analysis. The least significant covariate was then removed from the model sequentially until all the covariates retained P < 0.05 in the final model. Multicollinearity was assessed among the study covariates. The effect size for GC vs non-GC was expressed with adjusted odds ratio (aOR) and a corresponding 95% confidence interval (CI).
Inverse probability of treatment weighting (IPTW) propensity scoring was used to mitigate the difference in baseline pre-pregnant demographics between the GC and non-GC groups [18]. Independent characteristics between the two exposure groups determined by the prior step analysis were considered to create the IPTW cohort. The IPTW propensity score method assigned patients in the GC group a weight of 1/(propensity score) and those in the non-GC group a weight of 1/(1-propensity score). Stabilized weights and threshold technique at 10 were used. Standardized difference between the two exposure groups was assessed, and a value of > 0.20 was informed for model adjusting. Pregnancy characteristics were then assessed in the ITPW cohort. Delivery outcomes were also assessed in the IPTW cohort, further adjusting for pregnancy confounders between the two exposure groups. This analytic approach was based on the rationale that pregnancy events chronologically followed pre-pregnant conditions.
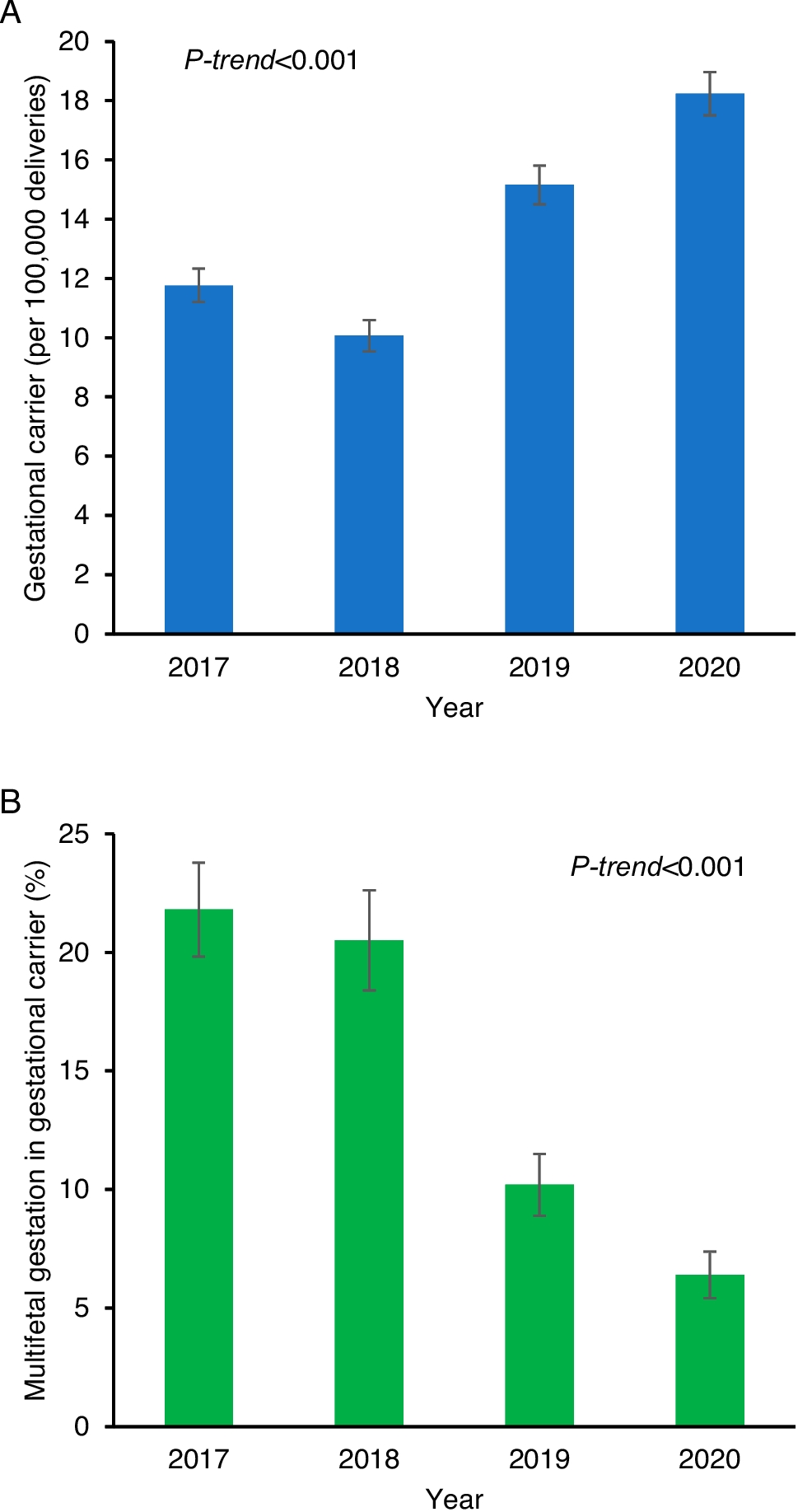
Various sensitivity analyses were conducted to assess the robustness of the study findings. First, the temporal trend of the multifetal gestation rate was assessed among pregnant patients with GC labeling. Second, cesarean delivery rate was assessed among those who did not have a prior cesarean section. Third, the vaginal birth rate among the patients with a history of cesarean delivery was evaluated. Fourth, SMM was assessed per the extent of gestation or per past uterine scar status. Last, the study cohort was stratified by the number of fetuses (singleton or multi-fetal gestations).
All statistical analyses were based on two-tailed hypotheses, and a P < 0.05 was considered statistically significant. The weighted values for national estimates provided by the programs were used for the analysis. Missing values in each study covariate were grouped for analysis. Statistical Package for Social Sciences (IBM SPSS, version 28.0, Armonk, NY, USA) and R statistics (version 3.5.3, R foundation for Statistical Computing, Vienna, Austria) were used for the analysis. The STROBE guidelines were consulted for the performance of this study.




留言 (0)