
記住我




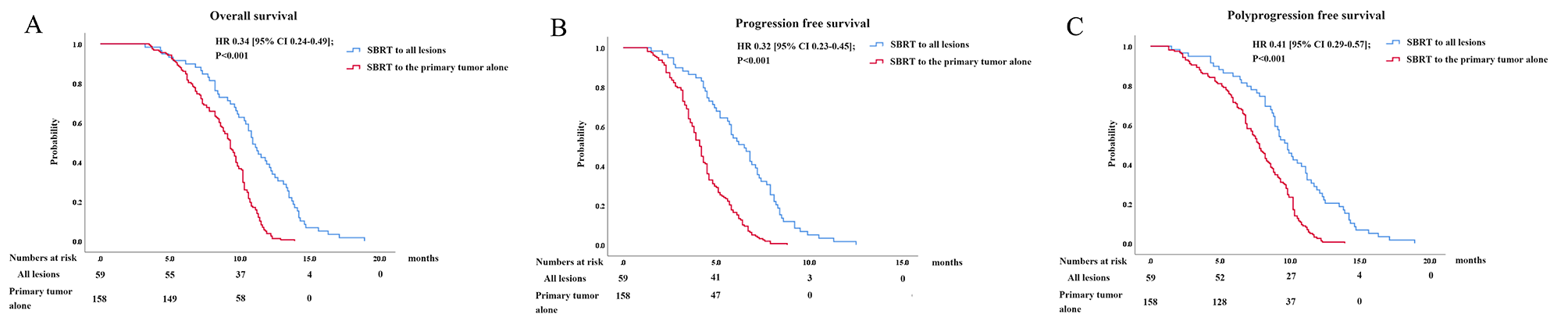
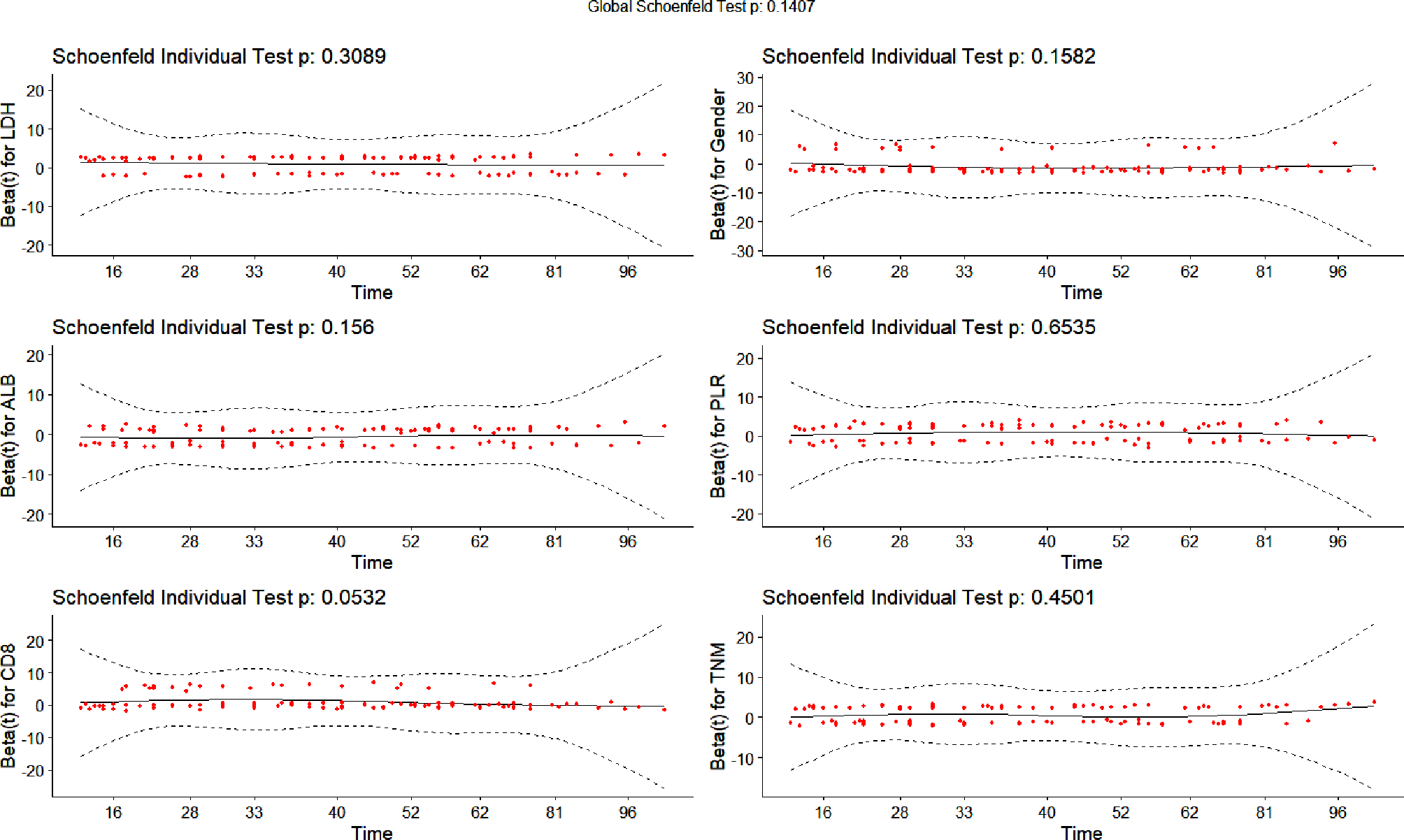
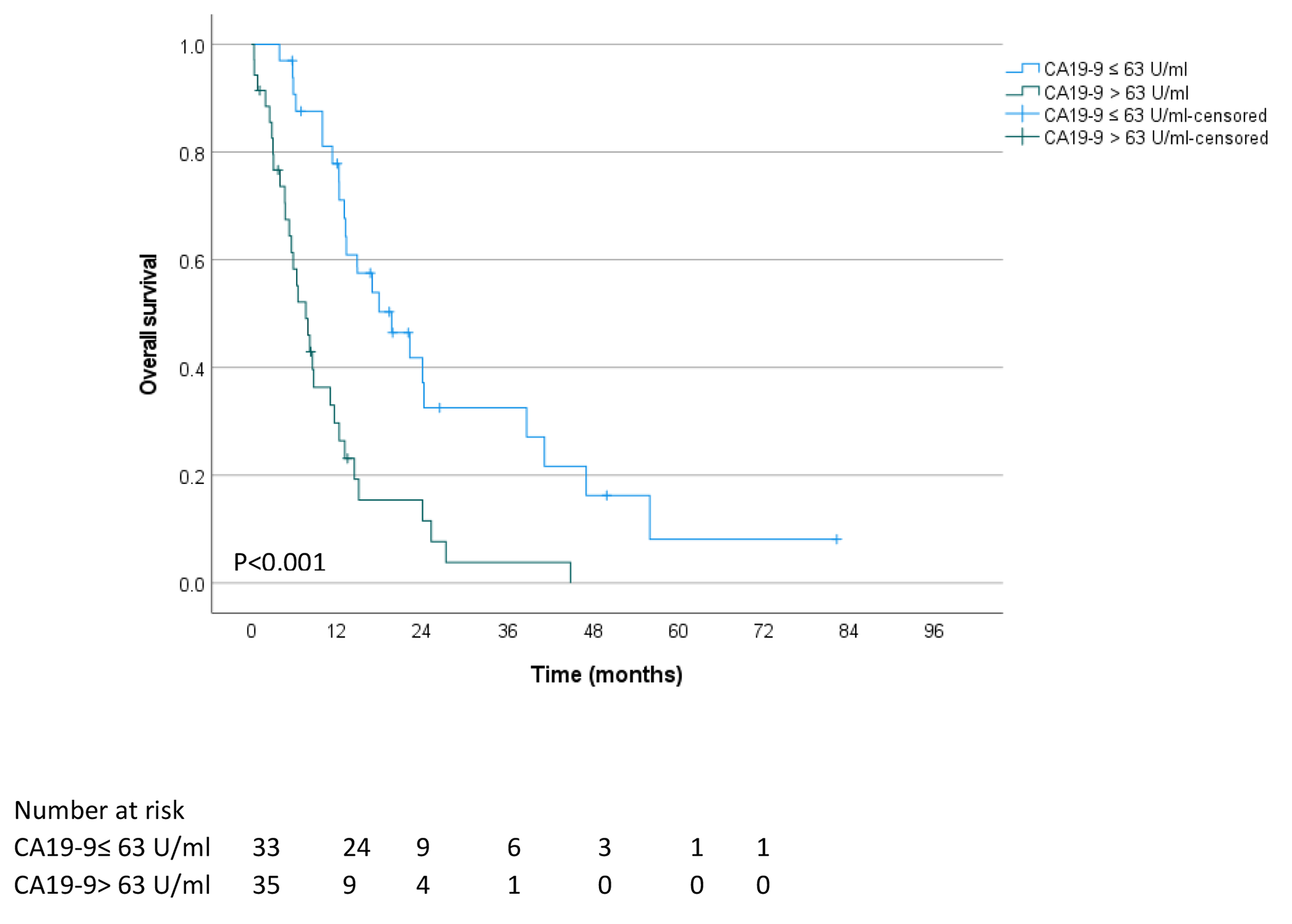

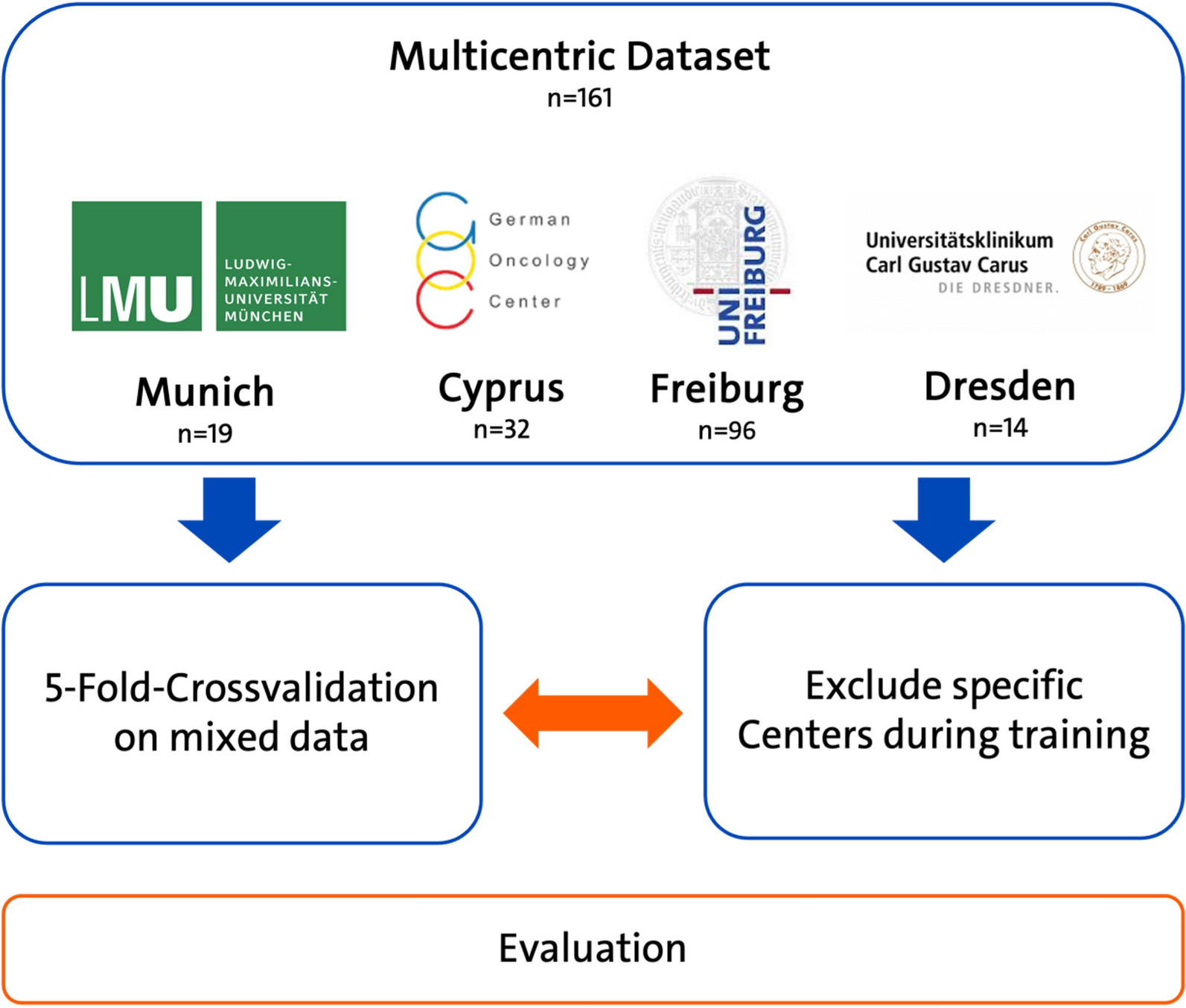
The study cohort consisted of 90 patients diagnosed with rectal cancer from April 2018 to March 2021 at Peking University People’s Hospital (PUPH) and 19 patients diagnosed with rectal or prostate cancer in public datasets from three different Swedish radiotherapy departments [28]. Enough patient data of rectal cancer with consistent standards can be provided in this center. One of the aim of this work is to build an MR-only workflow for rectal cancer treatment. The data acquisition parameters are shown in Table 1.
Table 1 The dataset acquisition parametersThe age distribution of patients was 43–83 years in PUPH cohort. CT scanning was performed with a Philips 16-row large-aperture analog positioning machine with a flat table top. Scan parameters: 140 kV, 280 mAs, layer thickness 3 mm. MRI of the pelvis was performed using a GE Discovery MR750 3.0T MR scanner with the curved table top. The scanning sequence and parameters are as follows: High-resolution non-fat-suppressed fast recovery fast spin-echo (FRFSE) T2-weighted imaging sequence, TR 3 200 ms, TE 85 ms, slice thickness 3 mm, slice interval 0.5 mm, a field of view 32 cm×26 cm.
T2-weighted MR and CT data were collected for 19 patients at three different sites in public datasets. All patients were scanned using a coil setup that not affects the outline of the patient in the radiotherapy treatment position with a flat table top.
PreprocessingExternal contours of CT and MR images were generated in Treatment Planning System (TPS) (UIH, Shanghai United Imaging Healthcare Co., Ltd.). All CT and MR voxels outside the external contour were assigned to intensity of -1024 and 0, respectively. The intensities of CT images were linearly mapped from [-1024; 1500] to [-1; 1]. The intensities of MR images were clipped beyond the 95th percentile, and then the intensities were also linearly mapped to [-1; 1]. Deformable registration was performed on MR and CT images by NiftyReg open-source software [29], and the registration results were revised by an experienced physician.
The three-fold cross-validation was used in this study. The specific division of data is as follows: 30 cases were randomly selected from PUPH cohort and one center was picked from public datasets as test datasets and the rest data served as train datasets in each fold.
Network architecturesAs shown in Fig. 1(a), the proposed CRGAN (Consistency Regularization Generative Adversarial Network) contained two generators and discriminators. Wherein the generator GCT provides MR to CT mapping, the generator GMR provides CT to MR mapping. Furthermore, the discriminator DMR and DCT were used to distinguish between real images and synthetic images [13].
Fig. 1
Illustration of architecture of CRGAN. (a) and (b) are the training phase of CRGAN, (c) is the inference phase of CRGAN
Figure 1a) and b) show the training phase of CRGAN. In order to improve the generalization of the model, consistency regularization similar to Flexmatch was employed to optimize the GCT [26], as shown in Fig. 1b). The weak and strong data augmentation was performed in the same MR image to obtain the MRw and MRs. In weak data augmentation, operations such as like flipping along the vertical direction, scaling and clip to certain size, random clip and resize, and rotation with random degree between 0 ~ 360° were applied without changing the value distribution of the image. In strong data augmentation, MR images were further operated with color augmentation, includes the methods that will change the voxel values of images, such as altering the brightness using gamma changes, applying Gaussian filtering to the image. Then the consistency regularization loss was added to ensure that the weak and strong augmentation MR images would generate similar sCT. Figure 1c) show the inference phase of the model.
A 2.5D image was token as input of CRGAN, which contains 3 adjacent layers is extract from a 3D image. The ADAM optimization was used to minimize the loss function [30]. CRGAN was initialized using the He_normal initialization method [31].
GeneratorThe Transformer module was employed in the generator of CRGAN, as shown in Fig. 2. The Transformer module can pay attention to the global connection of features compared with the convolution module [32]. There are tremendous work including imaging segmentation and translation adopting transformer structures and obtain promising performance. It is generally believed that the Transformer module is more effective than the convolution module in extracting deep features [33], so we put the Transformer module on the last layer of the encoder of the generator.
Fig. 2
Illustration of architecture of generator of CRGAN. IN: Instance Norm, LRelu: LeakyRelu, LN: Layer norm, FFN: Feed Forward Network
DiscriminatorAll the discriminator networks in CRGAN shared the same architecture, obtained by spectral normalization of the discriminator in the plain CycleGAN [13]. Spectral normalization introduces regularity constraints from the perspective of the spectral norm of the parameter matrix of each layer of the neural network [34], so that the neural network has better insensitivity to input disturbances, thus making the training process more stable and easier to converge.
Loss functionIn this study, a mixed loss function including adversarial loss, cycle consistency loss, consistency regularization loss and contrastive learning loss was used as the objective function, which is defined as follows:
$$\begin Loss&=_+_+_\\ &\quad +_\end$$
The adversarial loss (shown as LGAN in Fig. 1) function optimized the generator and discriminator. For the generator GCT and its discriminator DCT, the adversarial loss function is defined as
$$_\left(_, _\right)=_\left(_\left(_\right)\right)+(1-_(_\left)\right)$$
Where ICT and IMR represent unpaired input CT and MR images. In the training phase, GCT generates a synthetic CT image GCT(IMR) that is close to the real CT image, while DCT is to distinguish the synthetic CT image GCT(IMR) from a real image ICT. Likewise, the adversarial loss functions for GMR and DMR are defined as
$$_\left(_, _\right)=_\left(_\left(_\right)\right)+(1-_(_\left)\right)$$
The cycle-consistent loss function optimized the GCT and GMR, forcing the reconstructed images GCT (GMR(ICT)) and GMR (GCT(IMR)) to be the same as their input ICT and IMR. This loss function is defined as
$$\begin _\left(_, _\right)&=\Vert_\left(_\left(_\right)\right)-_\Vert\\ &\quad+\Vert_\left(_\left(_\right)\right)-_\Vert\end$$
The consistency regularization loss (shown as LCycle in Fig. 1. (a)) function optimized the GCT, ensuring MR images enhanced by weak and strong augmentation would generate similar sCT. This loss function is defined as
$$_\left(_\right)=\Vert_\left(_\right)-_\left(_\right)\Vert$$
Contrastive learning lossThe CL loss (shown as LCons in Fig. 1. (b)) optimized the generator GCT and GMR. The semantic relation consistency (SRC) regularization with the decoupled contrastive learning was used [15]. SRC utilizes the semantics feature by focusing on the semantic relation between the image patches from a single image. In addition, the hard negative mining strategy is explored by exploiting the semantic relation [15]. This loss function is defined as
$$\begin_&=_\sum _^JSD\left(\frac\left(_^_\right)}_^\text\left(_^_\right)}\right|\left|\frac\left(_^_\right)}_^\text\left(_^_\right)}\right)\\ &+_}__}[-log\frac\text\text(^z/\tau )}}_^\sim_^}}[\text\text\text(^^/\tau \left)\right]}] \end$$
where \(_\) and \(_\) are weighting parameters; JSD represents Jensen-Shannon Divergence; zk and zi are the corresponding embedding vectors of k-th location and i-th location patches of the input image; wk and wi are the corresponding embedding vectors of k-th location and i-th location patches of the synthetic image; the negative sampling is modeled by von Mises-Fisher distribution:
$$^\sim}_^}(^;z, \gamma )=\frac_}\text\text\text\left\^^\left)\right\}_\left(^\right)$$
where Nq is a normalization constant;γ is a hyper-parameter determining the hardness of the negative samples.
Evaluation metricsReferring to the main stream articles of imaging translation, MAE, SNRpeak and SSIM are three commonly used metrics to measure the quality of images. MAE evaluates the voxel-vise similarity between images, SNRpeak evaluates the image quality, and the SSIM evaluates the structure similarity between two images. To evaluate the generalization performance across multi-center data, we proposed a new metric GP (Generalization Performance) based on the above metrics. To evaluating the similarity between a sCT image and real CT, their image quality, HU values, and anatomical structures similarity are most important aspects, and the metrics mentioned above can evaluate the performance from these aspects.
MAE (mean absolute error)MAE can be used to evaluate the difference in HU values between sCT and CT images as follows:
$$\text\text\text=\frac\sum _^\left|_-_\right|$$
Where the index i represents each voxel of the image.
SNRpeak (Peak Signal-to-noise ratio)SNRpeak provides an objective measure of image distortion or noise level, as follows:
$$\text\text\text\text\text\text\text=10\text_\left(\frac_^}\right)$$
SSIM (Structural Similarity index)SSIM analyzes the similarity between images in terms of brightness, contrast, and structure, as follows: C1 and C2 are constants.
$$\text\text\text\text=\frac__+_)(2_+_)}_}^+_}^+_)(_}^+_}^+_)}$$
Model’s generalization analysisWe proposed a new metric GP (Generalization Performance) to assess the generalization of model on unseen datasets. It is computed as follows:
$$\text\text=\frac_}_}*\frac_}_}*\frac_}_}$$
GP is composed of three parts, each of which reflects the model’s generalization in MAE, SNRpeak and SSIM, respectively. Therefore, this indicator can comprehensively reflect the generalization performance on unseen datasets. The seen and unseen datasets are defined as the datasets trained on and test on, respectively. In such definition, seen and unseen datasets are whole datasets, not the training or testing splits from one dataset or mixed multi-datasets. The larger the indicator is, the better the generalization performance is. When the indicator value is close to 1, it indicates that the performance of the model on unseen datasets is equal to that on the seen datasets, indicating excellent model generalization.
Dosimetric analysisDosimetric accuracy of sCT images were evaluated by clinical rectal cancer treatment planning. A dose of 5000 cGy was prescribed for the primary tumor target and the photon plan was designed for each test data using real CT images (TPS, UIH). Then the segmentation and plan of real CT image were copied to the sCT image. The dose distribution of the plan generated on real CT was recalculated on the sCT to investigate the gap between them. The dose matrix has a resolution of 3 × 3 × 3 mm3 and covers the main region of interest (ROI).
留言 (0)