
記住我
Electroencephalography (EEG) is a non-invasive neuroimaging technique that measures electrical activity in the brain. It has been extensively used in research and clinical settings to study brain function and diagnose neurological disorders. However, the analysis of EEG signals presents significant challenges due to the low signal-to-noise ratio, high dimensionality, and inter-individual variability in EEG features (Rashid et al., 2020; Alvi et al., 2022). Recently, a machine learning method called Few-Shot Learning (FSL) has become popular for improving EEG signal analysis. FSL is designed to work well even when only a small number of examples are available for training (Chen et al., 2019; Wang and Yao, 2019). This is particularly useful for EEG analysis, where collecting a lot of labeled data can be hard, expensive, and time-consuming. FSL techniques have shown that they can accurately classify and analyze EEG signals with only a few labeled samples (Bajaj et al., 2020; Dzedzickis et al., 2020; Lin et al., 2020). This makes FSL a powerful tool for EEG signal classification, helping to overcome some of the major challenges in the field. By using FSL, researchers can achieve accurate results without needing large amounts of labeled data, making it a valuable approach for EEG studies.
Furthermore, Few-Shot Learning (FSL) enhances the robustness of the model against the inherent inter-individual variability found in EEG features. By leveraging knowledge from prior tasks or datasets through transfer learning, FSL techniques can effectively identify and generalize patterns across individuals, thereby improving the performance of EEG signal classification models (Schonfeld et al., 2019; Zhuang et al., 2020). Despite its advantages, FSL encounters challenges in EEG analysis, such as limited labeled datasets, subject variations, and adaptability to new datasets (Song et al., 2022). However, recent advancements in FSL strategies, including Data Augmentation (DA), Transfer Learning (TL), and Self-Supervised Learning (SSL), exhibit promising potential in mitigating these challenges (Gidaris et al., 2019; Li et al., 2019b; Chen et al., 2021).
Having a robust model is an essential part of any Machine Learning modeling, but due to lack of data, less data diversity or overfitting leads to a poor performance of the unseen data, causing the model to be unstable and can change its predictions with slight changes in the input. All this brings to a need for a mechanism that can overcome these challenges. Data augmentation (DA) addresses these challenges of real-world problems by synthetically generating data near the real world and adding it to the training process. However, developing a robust model near the real world does not solve other practical problems, such as the evolving nature of the world yielding new unseen data characteristics and hence bringing a need to adapt the pretrained model to a new data domain; this gives rise to Transfer Learning (TL), which can transfer new knowledge acquired to the existing model without the need of training from scratch. Transfer Learning (TL) can work if the underlying model is robust and rich enough to understand the intricacies of the data; therefore, leveraging the large amount of unlabeled data becomes very important to learn a rich representation of the data to have a pre-trained model that then can be used for fine tuning, this technique is referred to as Self Supervised Learning (SSL). This paper explores the work done in these paradigms from the lens of achieving FSL.
This systematic review sets itself apart significantly from existing reviews that have delved into methodologies such as Data Augmentation (DA), Transfer Learning (TL), and Self-Supervised Learning (SSL) within the domain of EEG signal processing. Unlike previous reviews that predominantly focused on specific facets of these techniques, such as SSL in Rafiei et al. (2022), TL in Redacted (2021), and DA in He et al. (2021), this research takes a more comprehensive approach. The study introduces an innovative taxonomy integrating DA, TL and SSL, providing a holistic perspective on Few-Shot Learning (FSL) for EEG signal classification. This taxonomy meticulously categorizes and organizes these techniques, establishing a structured foundation for comprehending their applicability across a broad spectrum of EEG paradigms. Moreover, the review critically highlights the differences and shortcomings in existing research, offering insights into best practices for evaluating and selecting the most suitable FSL strategy.
This review transcends the scope of existing literature by actively examining each of these FSL techniques within the context of different EEG paradigms. Rather than focusing solely on the methodologies themselves, it investigates their performance and adaptability across a diverse spectrum of EEG paradigms, encompassing tasks such as Motor Imagery (MI), Emotion Recognition (ER), Visual Evoked Potentials (VEP), Steady-State Visually Evoked Potentials (SSVEP), Rapid Serial Visual Presentation (RSVP), Event-Related Potentials (ERP), and Mental Workload (MWD). By actively considering FSL methodologies alongside distinct EEG paradigms, this research not only bridges gaps in the existing literature but also lays the groundwork for a more comprehensive understanding of FSL's potential in EEG signal processing. This comprehensive perspective actively contributes to the academic discourse by providing a valuable reference that actively assists researchers in navigating and advancing the domain of EEG signal processing with FSL techniques. The field employs a variety of techniques and methodologies, each with its own set of acronyms and terminology. To facilitate understanding, Table 1 provides a comprehensive list of acronyms and their definitions used throughout this paper.
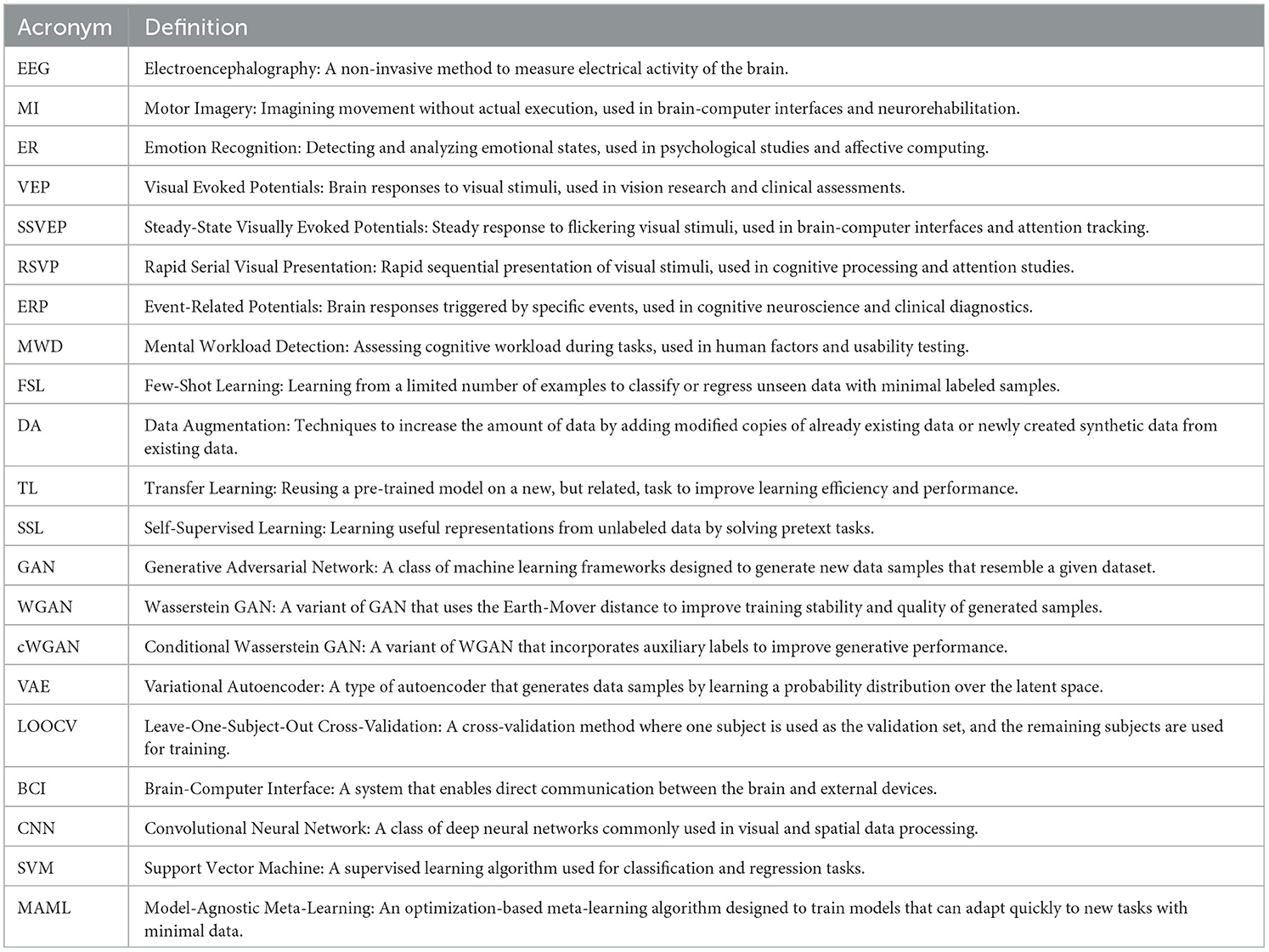
Table 1. Acronyms and definitions.
The contributions of this review paper are:
• Comprehensive analysis of existing literature: This paper rigorously examines the current literature on Few-Shot Learning (FSL) techniques tailored for EEG signal classification. Evaluating a diverse range of studies furnishes a detailed overview of the prevailing state-of-the-art FSL methodologies in EEG analysis.
• Evaluation of FSL techniques: The paper critically assesses the merits and limitations of various FSL techniques within EEG signal classification. It scrutinizes the strengths and pitfalls of DA, TL, and SSL methods, considering challenges like limited labeled data and inter-individual variability in EEG analysis.
• Identification of key findings and trends: Through an exhaustive literature analysis, this paper pinpoints key findings and emerging trends in applying FSL techniques to EEG signal classification. It underscores vital considerations, such as the influence of distinct EEG paradigms on the selection and efficacy of FSL methods.
• Highlighting research gaps: By analyzing existing literature, this paper illuminates essential research voids in the Few-Shot Learning (FSL) domain for EEG analysis. Instead of merely suggesting future directions, this study accentuates areas warranting deeper exploration. These gaps encompass addressing current limitations, innovating FSL strategies, and probing the amalgamation of diverse techniques to augment the precision and efficiency of EEG signal classification.
• Proposed the best practices for conducting FSL research: This paper points out a few best practices to conduct FSL research and guidelines on how future research should report their results for better reproducibility and clarity.
This review paper meticulously evaluates the extant literature on FSL techniques for EEG signal classification, gauges the effectiveness of different FSL methods, discerns pivotal findings and trends, and provides insights into prospective research avenues. These contributions aspire to enlighten researchers and steer further progress in employing FSL methodologies to refine EEG signal analysis and classification.
The structure of this paper unfolds as follows as in Figure 1: Section 2 delineates the methodology adopted for this review. Section 3 unveils the review's findings and proposes a taxonomy grounded in the outcomes. Section 4 delves into a comprehensive discussion of the identified challenges. After reviewing previous literature, this paper layouts some Best Practices in Section 5 and proposes Guidelines for reporting results for future work in FSL in Section 6. Conclusively, Section 6 encapsulates the salient findings, contributions, prospective research trajectories, and the relevance of Few-Shot Learning (FSL) in EEG analysis.
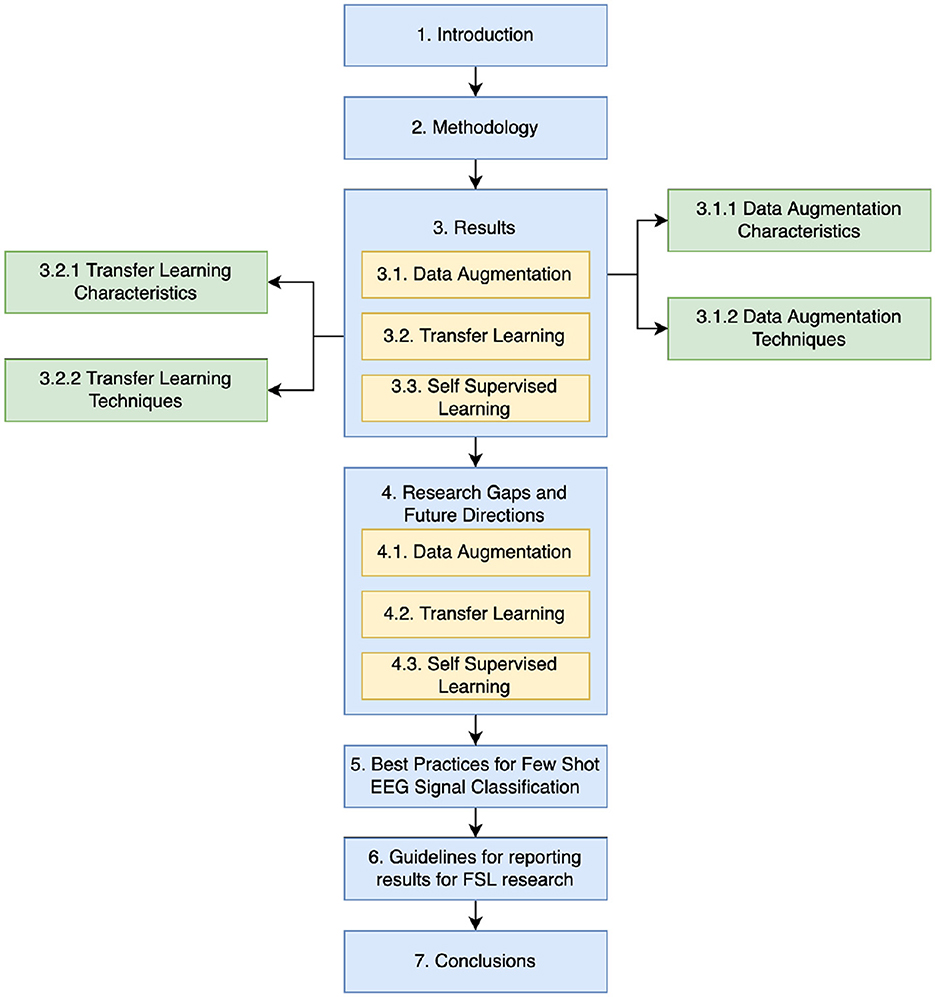
Figure 1. Structure of the paper.
2 MethodologyThis review utilizes a systematic approach to ensure the search strategy's comprehensiveness and the results' accuracy. The search spans multiple databases, including PubMed, IEEE Xplore, and Google Scholar, targeting articles published between January 2015 and March 2023. The search keywords encompass “EEG” or “electroencephalography,” combined with terms related to “signal classification,” “pattern recognition,” and specific EEG paradigms. Additionally, terms associated with data augmentation techniques, such as “GAN,” “VAE,” and “Autoencoder,” are integrated as popular generative methods for synthesizing data to augment EEG datasets.
Boolean search strings are constructed to refine the search, including combinations such as [Data Augmentation AND (EEG OR electroencephalography)], [EEG AND (GAN OR VAE OR AutoEncoders)], [Transfer Learning AND (EEG OR electroencephalography)], and [Self Supervised AND (EEG OR electroencephalography)]. Table 2 presents the common EEG paradigms used in the query search in the review. There are other paradigms, too, as the initial search started with ER and MI and then, based on results, it is fixed to a few for the focus of this study. This approach aims to yield specific, easily aggregatable results. These queries yielded many duplicate records, which were filtered out by paper name. Also, as this work focuses on exploring the impact of Data Augmentation (DA), Transfer Learning (TL) and Self Supervised Learning (SSL) therefore, only the papers showcase the improvements with either of these techniques rather than modeling algorithms or hyperparameter tuning.
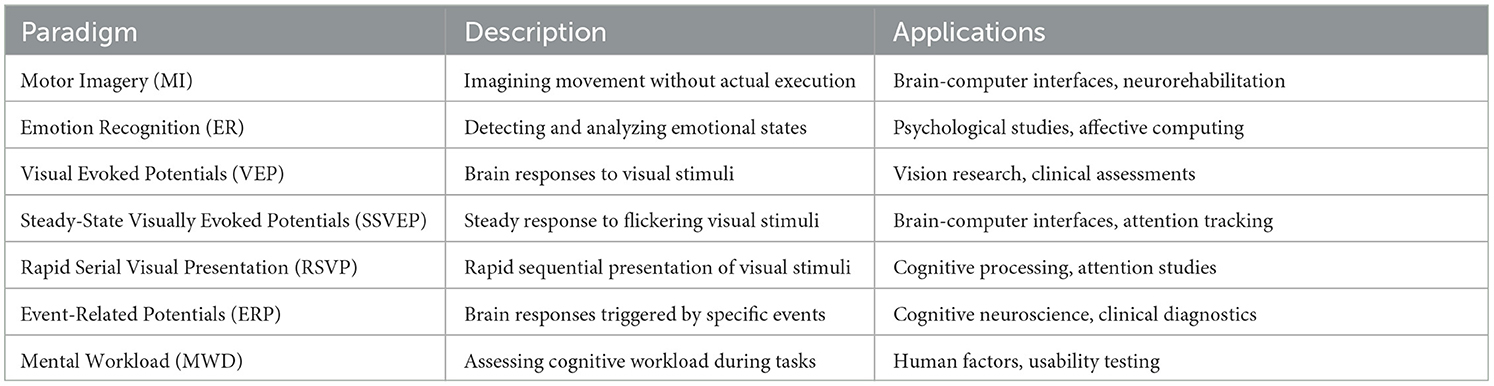
Table 2. EEG paradigms.
Articles are initially screened based on their title and abstract. Those meeting the inclusion criteria have their full text retrieved for a more detailed evaluation. The criteria for inclusion encompass articles discussing machine learning techniques, especially FSL and its associated strategies, in the context of EEG signal analysis. Exclusions are made for articles not in English, those not peer-reviewed, or those not primarily focused on EEG signal analysis. The complete results are summarized in Figure 2.
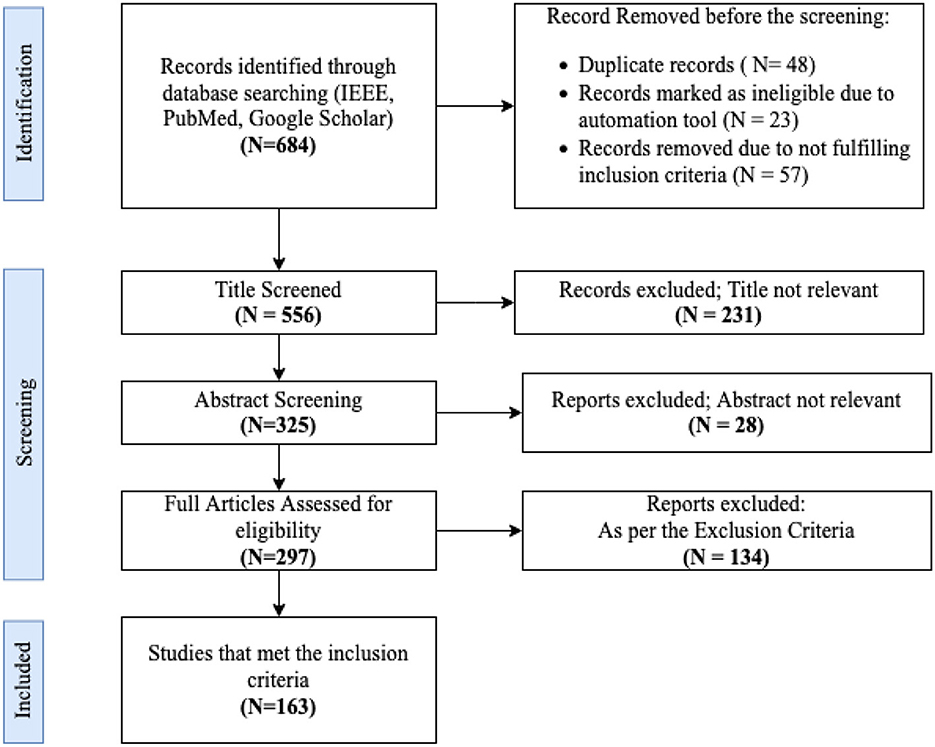
Figure 2. Flowchart illustrating the study selection process, with numbers denoting the count of studies at each phase.
The methodology adopted in this paper is outlined as follows:
• Adherence to the Preferred Reporting Items for Systematic Reviews and Meta-Analyzes (PRISMA) guidelines ensures the transparency and rigor of the search strategy, screening procedures, and data extraction (Liberati et al., 2009).
• Data extraction is executed based on predefined criteria, encompassing aspects like the publication year, study design, sample size, dataset employed, EEG feature extraction method, machine learning technique, and FSL strategy. The review assesses the maturity and applicability of each FSL strategy in EEG signal analysis, pinpointing existing challenges.
• A qualitative analysis of the extracted data offers a snapshot of the prevailing state-of-the-art in FSL and its strategies for EEG signal analysis. This review's contributions extend to discerning current trends, challenges, and potential solutions in the realm of FSL for EEG signal analysis.
The criteria guiding the inclusion and exclusion of articles in the selection process are summarized in Table 3.
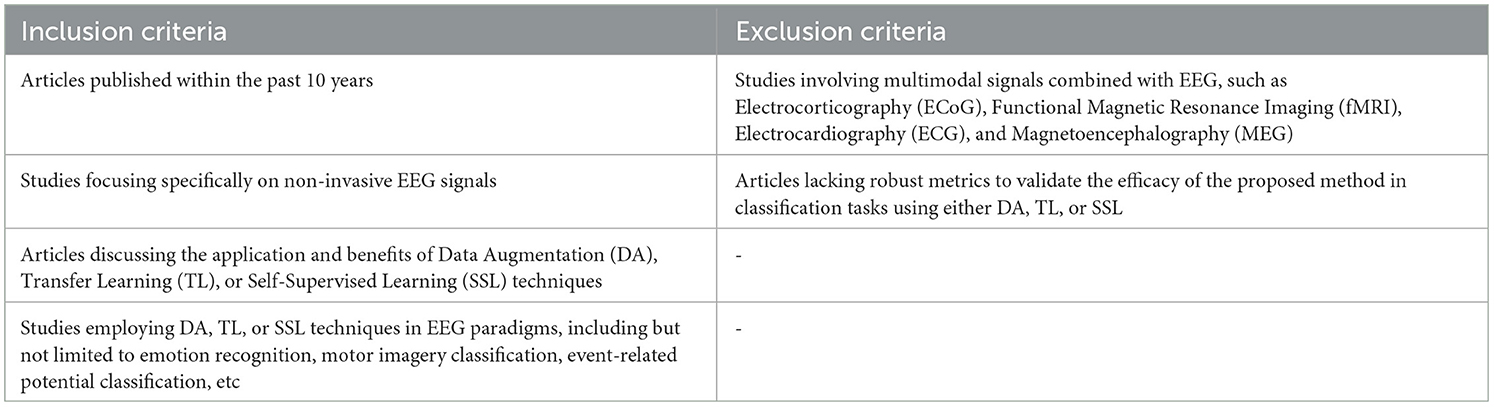
Table 3. Inclusion and exclusion criteria.
3 ResultsThis section presents the results based on the above-discussed comprehensive methodology, encompassing various techniques, including Data Augmentation (DA), Transfer Learning (TL), and Self-Supervised Learning (SSL). Collectively, these techniques form a robust framework for training models to comprehend the nuances of out-of-distribution data, enabling domain adaptation and facilitating unsupervised representation learning. The amalgamation of these methodologies not only addresses the challenges of few-shot Learning but also underscores their synergistic potential in advancing the field of EEG signal processing. Together, they pave the way for a more profound understanding of cognitive neuroscience and related domains by harnessing the power of limited data resources and extending the boundaries of knowledge acquisition.
3.1 Data augmentationData Augmentation (DA) is a technique used to create more training examples by modifying existing data. This helps solve problems like having too few examples or having data that changes a lot. Having a robust model is challenging for the following reasons that DA aims to address while generating near real-world synthetic data (Simonyan and Zisserman, 2014; He et al., 2016).
1. The datasets available in EEG are smaller and imbalanced, and hence, samples of some controlled classes would be less; for example, studying epileptic seizure detection would not have an equal distribution of subjects with seizures as subjects without subjects such as used by Andrzejak et al. (2001).
2. It is hard to acquire diverse datasets representing a large proportion of real-world human demographics. This is due to the expensive setup to acquire quality EEG signals, which requires a controlled and stable environment for EEG signal capturing using highly sophisticated EEG sensors.
3. Due to limited and less diverse data, models may overfit and yield poor performance on unseen data, especially on new subjects or sessions.
4. The model trained can also be unstable, i.e., small fluctuations in the input can yield very different predictions.
This section collectively analyzes the work done in DA for EEG signal processing while aggregating them by the techniques and the characteristics they aim to address. Figure 3 details a three-phase DA process designed to generate synthetic EEG signals with the goal of curating a diverse dataset that closely mirrors real EEG data. DA focuses on the training phase, which involves generating synthetic samples resembling the input samples by learning a generation function or manipulating existing samples.
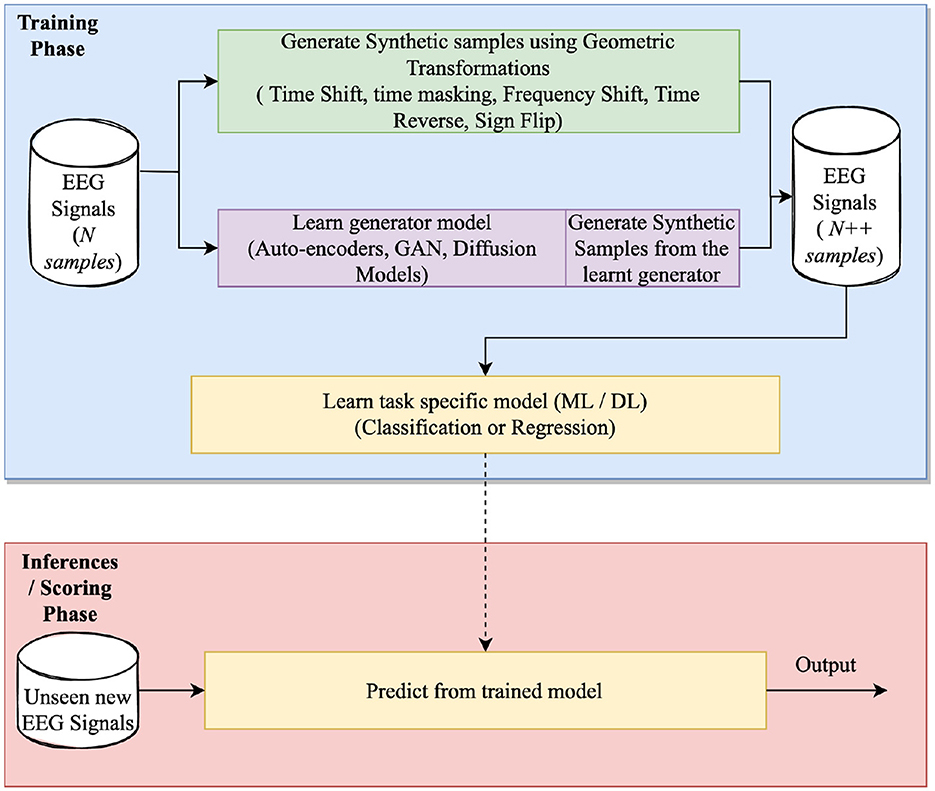
Figure 3. Schematic representation of an algorithm designed for generating synthetic EEG signals.
3.1.1 Characteristics of data augmentationThe robustness of DA can be explicated through its adept handling of diverse variances and the attributes inherent in the transformed samples. Researchers commonly focus on specific characteristics for transformation, aiming to maintain invariance to these features. In the pursuit of inferring the characteristics from the research, a meticulous set of steps was followed to discern the nuances of the methodologies employed. This process involves delineating results by subject, where the methodology is presumed to be exclusively tested for session invariance. Conversely, when results are aggregated across all subjects, it is reasonable to deduce that the methodology exhibits invariance to both session and subject. Additionally, if the methodology explicitly addresses how the class distribution is utilized for augmenting samples, whether through distribution balancing or separate augmentation per class, it implies class invariance. These characteristics are explicitly delineated in the research or inferred from the presentation of results and methodology, pertaining to Subject, Session, or Class Invariance.
1. Subject invariance: EEG signals often encapsulate features indicative of individual subjects. Consequently, a generator trained on such datasets becomes sensitive to these subject-specific features. An optimal generator, Subject Invariant Generator, should adeptly filter out these features. Both Aznan et al. (2020) and Panwar et al. (2020) proposed a Wasserstein Generative Adversarial Network (WGAN) for Rapid Serial Visual Presentation (RSVP). They used a gradient penalty to synthesize EEG data.
Aznan et al. (2020) introduced the Subject Invariant Generative Adversarial Network (SIS-GAN) to generate synthetic EEG signals. The objective was to remove subject-specific elements while preserving Steady-State Visually Evoked Potential (SSVEP) frequencies. The architecture of SIS-GAN included a generator, discriminator, auxiliary classification network, and a pre-trained subject-biometric classifier. The synthetic data improved the performance of SSVEP frequency classification models.
The study, conducted by Cimtay and Ekmekcioglu (2020), underscores the imperative of enhancing subject-independent recognition accuracy employing pre-trained Convolutional Neural Networks (CNNs). In lieu of relying on spectral band power characteristics, the authors employed windowed, adjusted, and normalized raw Electroencephalogram (EEG) data. The utilization of deep neural networks obviated the necessity for manual feature extraction, potentially revealing novel features. To mitigate false detections, a median filter was incorporated into the methodology. The proposed approach yielded mean cross-subject accuracies of 86.56 and 78.34% on the SEED dataset (Miller et al., 2014) for two and three emotion classes, respectively. Furthermore, it demonstrated a mean cross-subject accuracy of 72.81% on the DEAP dataset (Koelstra et al., 2011) and 81.8% on the LUMED dataset (Ekmekcioglu and Cimtay, 2021) for two emotion classes.
2. Session invariance: Achieving session invariance requires a generator capable of filtering out session-specific features from a signal. This generator's task is to retain only the essential information within the feature space while disregarding session-related variations.
In the realm of person identification through EEG brain activity using deep learning, challenges were encountered by Özdenizci et al. (2019a). In response to these challenges, the authors proffered a solution employing invariant representation learning. Their approach encompassed the incorporation of an adversarial inference technique, aiming to foster the development of session-invariant and subject-invariant representations endowed with longitudinal applicability. In the context of within-session person identification models, the authors documented noteworthy accuracies of 98.7% ± 0.005, 99.3% ± 0.003, and 98.6% ± 0.006 for Sessions 1, 2, and 3, respectively. These outcomes were derived from the analysis of 2,760 half-second epochs, employing a 20% test split. The evaluation metrics employed facilitated a comprehensive assessment of model performance within individual sessions. Furthermore, in the domain of across-session person identification, when subjected to evaluation on an independent session, the model exhibited notable accuracies of up to 72% for 10-class person identification. This assessment was based on the analysis of 13,800 half-second epochs, with discernible enhancements of up to 6% attributed to adversarial learning and its influence on two sessions' invariance.
3. Class invariance: In addition to filtering out subject and session-specific characteristics, achieving class invariance in classification problems requires a generator to eliminate class-related features from the signal effectively.
Rommel et al. (2021) introduced an advanced automated differentiable DA approach for EEG data, comparing class-wise augmentation to class-agnostic augmentation. Their methodology introduced novel EEG augmentations to aid model training in scenarios with limited labeled data.
3.1.2 Data augmentation techniquesIn this section, a comprehensive overview of various data augmentation techniques for EEG signals emerges from an extensive review of the selected papers. Data augmentation enhances the robustness and generalization of machine learning models by artificially expanding the training dataset. Based on the analysis, a proposed taxonomy outlines different data augmentation techniques tailored explicitly for EEG signal processing. These techniques encompass various approaches, including temporal augmentation, spatial augmentation, frequency-domain augmentation, and hybrid methods that combine multiple augmentation strategies. Each technique offers unique benefits and addresses specific challenges associated with EEG data, ultimately contributing to improved performance and adaptability of EEG-based machine learning models.
Figure 4 shows the taxonomy of DA techniques explored in the literature. All the research in EEG focuses on improving the robustness of the model on unseen data while showcasing the improvement with and without augmentation. All techniques discussed further use this mechanism only to prove the effectiveness of the augmentation technique.
1. Geometric Transformation (GT) : Flipping, rotation, and cropping were common operations that altered the shapes of images, serving as visual representations of physical information encompassing both direction and contour. These techniques found wide application in speech signal processing (Cui et al., 2015) and computer vision (Paschali et al., 2019). In the context of EEG signals, the research by Krell and Kim (2017) highlighted that standard DA approaches, specifically in geometric transformations and noise injection (NI), did not adequately address variations in the signal-to-noise ratio (SNR) observed across multiple trials involving the same subject. The discussed techniques did not explicitly address whether they were designed to be session/subject invariant or class invariant.
Table 4 outlines the typical transformations that are applied to raw time series data within the context of geometric transformations. Table 5 presents a comprehensive overview of prominent modeling techniques for EEG signal classification utilizing various geometric transformations, which have demonstrated the effectiveness of data augmentation in enhancing model generalization across sessions, subjects, and classes. While numerous studies have validated the efficacy of data augmentation and its necessity, none of these works have examined the statistical significance of the augmented signal. The techniques comparing pre- and post-augmentation (relative to the classification metric employed in the paper) demonstrate effectiveness for session and subject independence but do not assess whether the augmented session deviates from the original session or the same for the subject and class.
Shovon et al. (2019) proposed a multi-input Convolutional Neural Network (CNN) for modeling Motor Imagery (MI) classification. The method converted each signal channel into an image representation using Short Time Fourier Transform (STFT). To address the data scarcity problem, rotation, flipping, and zooming were applied to the images. Experimental results on motor imagery datasets demonstrated accuracies of around 97 and 89.19% on the test split. However, the scalability of this technique might not have been optimal with higher dimensional EEG datasets. Freer and Yang (2020) introduced different augmentation methods for Motor Imagery (MI) classification tasks using a Convolutional Long-Short Term Memory (C-LSTM) network based on filter bank common spatial patterns (FBCSP). Training the model with data augmentations such as Noise Addition, Constant Multiplication, sign flip and frequency shift improved the model without augmentation by 5.3% on “BCIC IV—dataset—2a” (Brunner et al., 2008).
2. Noise injection (NI): Gaussian white noise is added to the original signal or the generated features as a common DA technique. Since EEG signals exhibit a low signal-to-noise ratio, adding excessive noise can degrade the original signal. Therefore, applying NI requires careful consideration. Research works listed in Table 6 employ Noise Injection in training protocols and demonstrate performance improvements compared to models without noise injection. Despite the effectiveness of noise injection in data augmentation, a key open question remains: How much noise should be added, and how the efficacy of the augmented signal be intrinsically measured post adding noise?
3. Sliding window (SW) : Models typically utilize the complete signal for classification problems. When applied to small datasets, the sliding window mechanism creates multiple instances from a single sample by setting the window size to a value smaller than the original signal length. Table 7 lists studies that generate multiple instances from a single sample using SW for EEG signal classification and demonstrate performance improvements with the sliding window approach. An argument could be made that the sliding window may not be considered an effective enhancement technique because it doesn't significantly change the original signal. However, when looking at EEG data as a series of time-based signals, it's important to recognize that each segment over time may show some differences. Despite these variations, the key features used for classification remain somewhat similar across all time segments. Choosing the best window size becomes a subjective task depending on the dataset's characteristics, making it a hyperparameter that requires careful adjustment by researchers.
4. Generative models: Unlike deterministic transformation techniques, generative models learn the underlying data distribution and generate samples from this distribution, offering a more robust approach that facilitates automatic end-to-end modeling. Determining whether the generated samples remain subject or session-invariant poses a challenge. Nonetheless, Table 8 highlights the effectiveness of these models in EEG signal classification and their corresponding improvements.
a. Generative adversarial network (GAN): GANs generate artificial data through adversarial learning. In this process, two sub-networks, the Discriminator (D) and the Generator (G), strive to match the statistical distribution of the target data (Goodfellow et al., 2014). The Discriminator differentiates between genuine and artificial input samples, whereas the Generator produces realistic artificial sample distributions to deceive the Discriminator. The output from the Discriminator provides the likelihood of a sample being genuine. Probabilities near 0 or 1 denote distinct distributions, while values around 0.5 suggest challenges in discrimination. GANs effectively produce synthetic data resembling real distributions, as illustrated in Equation (1):
minGmaxDV(D,G)=?x~pdata(x)[logD(x)] +?z~pz(z)[log(1-D(G(z)))] (1)Below are prominent GAN architectures adapted for EEG-specific data generation:
(1) Deep convolutional generative adversarial network (DCGAN): DCGAN introduces a novel architecture by replacing pooling layers with fractional-strided convolutions in the generator and employing stride convolutions in the discriminator (Zhang et al., 2020b). This design, combined with adversarial training, ensures adherence to feature distribution principles. Studies have demonstrated that DCGAN produces samples that are both diverse and closely resemble real data. For instance, in epilepsy seizure detection using EEG signals from the CHB-MIT dataset (Goldberger et al., 2000), a DCGAN-based augmentation was employed, followed by classification using ResNet50. This approach achieved a 3% performance improvement over non-augmented datasets (He et al., 2016).
(2) Wasserstein generative adversarial network (WGAN): WGAN addressed the challenge of discontinuous GAN divergence for generator parameters, which could result in training instability or convergence issues (Arjovsky et al., 2017). The key innovation was the adoption of the Earth-Mover distance (Wasserstein-l), as described in Equation (2):
W(ℙr, ℙg)=infγ∈Π(ℙrℙg),E(x,y)~γ[∥x-y∥] (2)Here, πPr, Pg denoted the set of all joint distributions of (x,y) where Pr and Pg were the marginals. The joint distribution (x,y) signified the “mass” transferred from x to y to transition from the distribution Pr to Pg. The WGAN value function, based on the Kantorovich-Rubinstein duality (Villani, 2008), was given by Equation (3):
minG maxD∈D?x~ℙr[D(x)]-?x~~ℙg[D(x~)] (3)(3) Conditional Wasserstein GAN (cWGAN): In emotion recognition tasks using the SEED (Miller et al., 2014) and DEAP (Koelstra et al., 2011) datasets, combining cWGAN with manifold sampling has enhanced classifier performance by ~10% (Luo et al., 2020). cWGAN, a variant of WGAN, incorporated the auxiliary label by introducing the real label Yr to both the discriminator and generator. The generator combines the latent input Xz with Yr, while the discriminator forms a hidden representation by merging the real input Xr and generated input Xg with Yr. Equation (4) presents the objective function for cWGAN, that inferently learns latent representation Xz of the input Xr.
minθG maxθDL(Xr,Xg,Yr)= ?xr~Xr,yr~Yr[D(xr∣yr)]-?xg~Xg,yr~Yr[D(xg∣yr)]-λ?x^~X^,yr~Yr[(||∇x^∣yrD(x^∣yr)||2-1)2] (4)b. Autoencoders (AE): Autoencoder Rumelhart et al. (1985) referred to feed-forward neural networks that encoded raw data into low-dimensional vector representations through the encoder and then reconstructed these vectors back into artificial data using the other half of the network. Instead of outputting vectors in the latent space, the encoder of Variational Autoencoders (VAE; Kingma and Welling, 2013) produced parameters of a pre-defined distribution in the latent space for each input. The VAE then enforced constraints on this latent distribution, ensuring its normality. Compared with AE, VAE ensured that generated data adhered to a specific probability distribution by introducing structural constraints (Luo et al., 2020). Komolovaitė et al. (2022) introduced a synthetic data generator using VAE for Stimuli Classification employing EEG signals from healthy individuals and those with Alzheimer's disease. This technique exhibited a 2% improvement over models without non-augmented data.
c. Diffusion models: VAE constrained a specific probability distribution in the latent space. Normalizing Flows learned a tractable distribution in which both sampling and density evaluation could be efficient and precise. However, Normalizing Flows were trained in a denoizing manner to capture an underlying distribution. Ho et al. (2020) outperformed GAN while devising a denoizing model and normalizing flows for image generation. Similarly, Hajij et al. (2022) employed a diffusion model-based generator for chest X-ray images to create synthetic data.
The initial work, as illustrated above, utilized various generative models. Recent research has also shifted focus toward determining optimal tasks for training generative models, rather than exclusively focusing on signal reconstruction. It has led to developing models such as GANSER (Generative Adversarial Network-based Self-supervised Data Augmentation; Zhang et al., 2023). Unlike previous approaches that reconstructs the complete signal, GANSER emphasizes masking the data and predicting the masked part of the signal for pre-training. Subsequently, the classifier is fine-tuned over the pre-trained model to predict augmentation. In this process, 80% of the data is utilized for pre-training without labels, followed by fine tuning with all the labels. While the paper does not explicitly demonstrate improvement with and without the proposed method, it compares favorably with other state-of-the-art emotion recognition models and other generative method for DEAP Koelstra et al. (2011) and DREAMER Katsigiannis and Ramzan (2018), showcasing an improvement of ~4% across all classes compared to the respective state-of-the-art models.
5. Signal decomposition: Unlike other techniques discussed so far, DA in feature space is another technique that has shown some promising results. Generally, these techniques decompose a signal using methods such as Empirical Model Composition (EMD) or Fourier Transform (FT), transform the signal in the decomposed space, and then reconstruct the time domain signal. All the studies utilizing Signal Decomposition have augmented signals on a per-class basis, thereby establishing class invariance.
Kalaganis et al. (2020) proposed a DA method based on Graph-Empirical Mode Decomposition (Graph-EMD) to generate EEG data, which combined the advantages of the multiplex network model and the graph variant of classical empirical mode decomposition. They used a graph CNN to implement the automated identification of human states while designing a continuous attention-driving activity in a virtual reality environment. The experimental results demonstrated that investigating the EEG signal's graph structure could reflect the signal's spatial characteristics and that merging graph CNN with DA produced more reliable performance. Zhang et al. (2019) suggested a new way to classify EEG data by combining DL and DA. The classifier consisted of Morlet wavelet features as input and a two-layered CNN followed by a pooling layer NN architecture. The author used EMD on the EEG record, mixing their Intrinsic Mode Functions (IMF) to create a new synthetic EEG record.
Huang et al. (2020) proposed three different augmentation techniques: Segmentation, Time domain exchange, and Frequency domain exchange to generate more training samples. Combined with a CNN for training the classification model, these techniques yielded a gain of 5–10 % accuracy compared to pre-augmentation. Schwabedal et al. (2018) proposed a novel augmentation technique called FT Surrogates. FT Surrogates generated new samples by changing the signal phase by decomposing the signal using the Fourier Transform (FT) and then reconstructing it into the time domain using the Inverse Fourier Transform (IFT). The premise that stationary linear random process sequences are uniquely described by their Fourier amplitudes, while their Fourier phases are random values in the interval [0, 2π), drove this approach.

Figure 4. Taxonomy of Data Augmentation techniques for EEG signal processing.
留言 (0)